我對網站的所有可見文本感興趣。
唯一的事情是:我想排除超鏈接文本。因此,我可以排除選單欄中的文本,因為它們通常包含鏈接。在影像中,您可以看到選單欄中的所有內容都可以被排除(例如“Wohnen & Bauen”)。
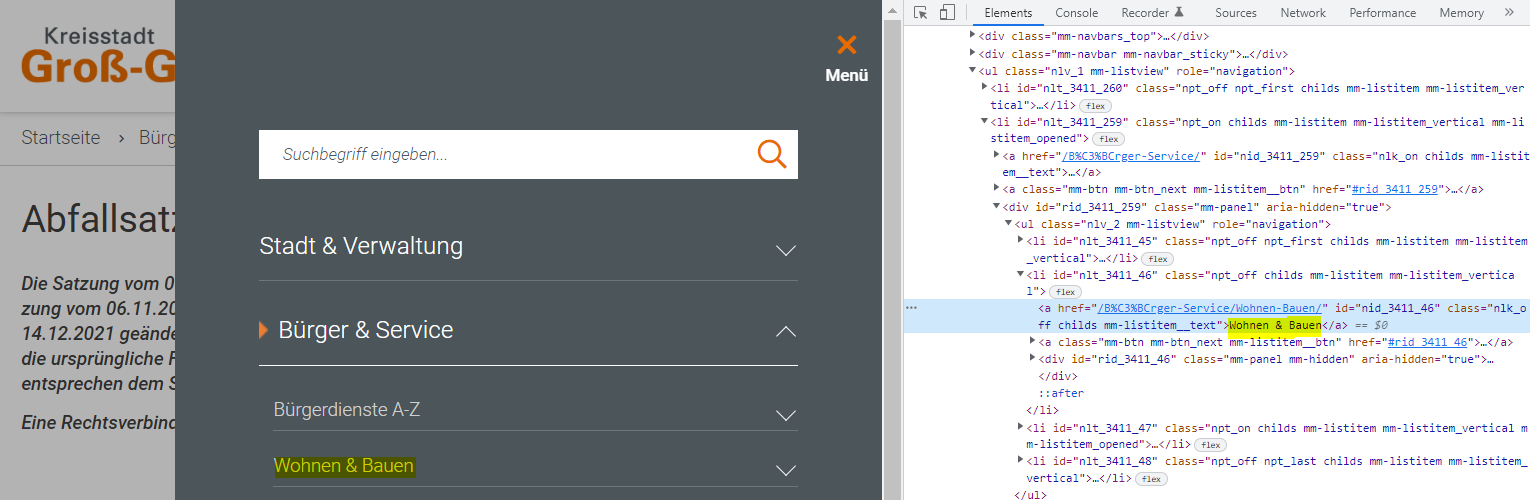 https://www.gross-gerau.de/Bürger-Service/Ver-und-Entsorgung/Abfallinformationen/index.php?object=tx,2289.12976.1&NavID=3411.60&La=1
https://www.gross-gerau.de/Bürger-Service/Ver-und-Entsorgung/Abfallinformationen/index.php?object=tx,2289.12976.1&NavID=3411.60&La=1
總而言之,我的蜘蛛看起來像這樣:
class MySpider(CrawlSpider):
name = 'my_spider'
start_urls = ['https://www.gross-gerau.de/Bürger-Service/Wohnen-Bauen/']
rules = (
Rule(LinkExtractor(allow="Bürger-Service", deny=deny_list_sm),
callback='parse', follow=True),
)
def parse(self, response):
item = {}
item['scrape_date'] = int(time.time())
item['response_url'] = response.url
# old approach
# item["text"] = " ".join([x.strip() for x in response.xpath("//text()").getall()]).strip()
# exclude at least javascript code snippets and stuff
item["text"] = " ".join([x.strip() for x in response.xpath("//*[name(.)!='head' and name(.)!='script']/text()").getall()]).strip()
yield item
該解決方案也適用于其他網站。有人知道如何解決這個挑戰嗎?歡迎任何想法!
uj5u.com熱心網友回復:
您可以將謂詞擴展為
[name()!='head' and name()!='script' and name()!='a']
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/465110.html