我有以下資料框:
d = {'col1': [1, 2, 3, 4, 5], 'col2': ["Q2", "Q3", "Q1", "Q2", "Q3"]}
df = pd.DataFrame(data=d)
df
col1 col2
0 1 Q2
1 2 Q3
2 3 Q1
3 4 Q2
4 5 Q3
我實際上有幾個這樣的資料框。我需要做的是我需要從資料框中洗掉前 1 或 2 行,以便col2的第一行值始終具有值 Q1。
進行更改后,資料框應如下所示:
col1 col2
2 3 Q1
3 4 Q2
4 5 Q3
col2 總是像 Q1 Q2 Q3 Q1 Q2 Q3 Q1 Q2 Q3 ... 但它最初可能從 Q1、Q2 或 Q3 開始。但我需要確保資料框始終以 Q1 開頭,以便我可能需要從資料框中洗掉 1 或 2 行。
請注意,我不想在洗掉前 N 行后重置索引。
此外,一些第一行可能是空字串,如“”,它可能如下所示:
“”、“Q3”、“Q1”、“Q2”、...
邏輯還應考慮空字串值,如果值為空字串,則甚至洗掉此類行。而且這些空字串只能在資料框的開頭,不能在后面的行中......
如何通過不在 Python 中使用 for 回圈以優雅的方式做到這一點?
uj5u.com熱心網友回復:
我們首先選擇具有指定值的行,然后保持第一個索引。采用:
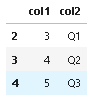
ind = df[df['col2']=='Q1'].index[0]
df.loc[ind:,:]
輸出:
uj5u.com熱心網友回復:
布爾選擇 Q1,獲取它的索引并在 loc 訪問器中輸入以切片 df 想要的部分。
df.loc[df['col2'].eq('Q1').idxmax():,:]
col1 col2
2 3 Q1
3 4 Q2
4 5 Q3
uj5u.com熱心網友回復:
Q1如果沒有匹配項,解決方案將在此處按值比較值Series.cummax:
df = df[df['col2'].eq('Q1').cummax()]
print (df)
col1 col2
2 3 Q1
3 4 Q2
4 5 Q3
如果值不存在,則與另一種解決方案進行比較,這里Q4:
#Q4 not exist, but wrongly all rows are selected
print (df.loc[df['col2'].eq('Q4').idxmax():,:])
col1 col2
0 1 Q2
1 2 Q3
2 3 Q1
3 4 Q2
4 5 Q3
#correct, no rows are selected
print (df[df['col2'].eq('Q4').cummax()])
Empty DataFrame
Columns: [col1, col2]
Index: []
#raise error, because not exist first value in empty DataFrame
ind = df[df['col2']=='Q4'].index[0]
print (df.loc[ind:,:])
IndexError:索引 0 超出軸 0 的范圍,大小為 0
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/465574.html
標籤:Python python-3.x 熊猫 数据框
上一篇:如何在資料框中集成字典串列?
下一篇:如何創建按組匯總行的列