我有以下熊貓資料框

也可以使用以下字典串列生成:
list_of_dictionaries = [
{'Project': 'A', 'Hours': 2, 'people_ids': [16986725, 17612732]},
{'Project': 'B', 'Hours': 2, 'people_ids': [17254707, 17567393, 17571668, 17613773]},
{'Project': 'C', 'Hours': 3, 'people_ids': [17097009, 17530240, 17530242, 17543865, 17584457, 17595079]},
{'Project': 'D', 'Hours': 2, 'people_ids': [17097009, 17584457, 17702185]}]
我已經實作了我需要的東西,但是垂直添加了列:
df['people_id1']=[x[0] for x in df['people_ids'].tolist()]
df['people_id2']=[x[1] for x in df['people_ids'].tolist()]
然后我得到每個people_id的不同列,直到第二個元素,因為當我在第三列上添加提取的第三個元素時,它崩潰了,因為沒有從第一行中提取第三個元素。
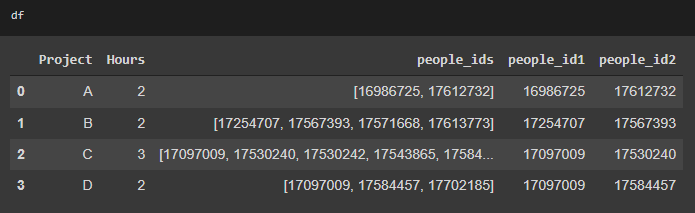
盡管如此,我想做的是從people_ids列中提取每個people_id,然后每個人都會從Project和Hours列中獲得相關值,所以我得到了一個像這樣的資料集:
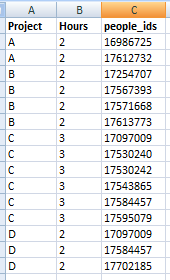
關于如何獲得此輸出的任何想法?
uj5u.com熱心網友回復:
我認為您正在尋找的是explode“people_ids”列。
df = df.explode('people_ids', ignore_index=True)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/465582.html
上一篇:熊貓按列上的多個條件選擇行