我正在為我的碩士論文處理一個非常混亂的資料集,我需要一些幫助來將值從一列復制到其他列。
我需要做的是以下幾點:
- 我需要將第 1 行的值復制到同一行的 price_close 列。
- 我需要將第 2 行的值復制到第 1 行的 price_high 列
- 我需要將第 3 行的值復制到第 1 行的 price_low 列
- 我需要將第 4 行的值復制到第 1 行的 price_open 列
- 我需要將第 5 行的值復制到第 1 行的列 share_outstanding
這需要為所有公司和所有日期完成。因此,我需要為下一家公司做同樣的程式。意義:
- 我需要將 row 5 中的值復制到同一行中的 price_close 列。
- 我需要將第 6 行的值復制到第 5 行的 price_high 列
- 我需要將第 7 行的值復制到第 5 行的 price_low 列
- 我需要將第 8 行的值復制到第 5 行的 price_open 列
- 我需要將第 9 行的值復制到第 5 行的 share_outstanding 列
資料集太大,無法手動完成。但是,我想這可以在 R 中使用回圈,因為“復制”在整個資料集中遵循相同的模式。如果是這樣的話,我真的很感激一些指導來解決這個問題。謝謝!
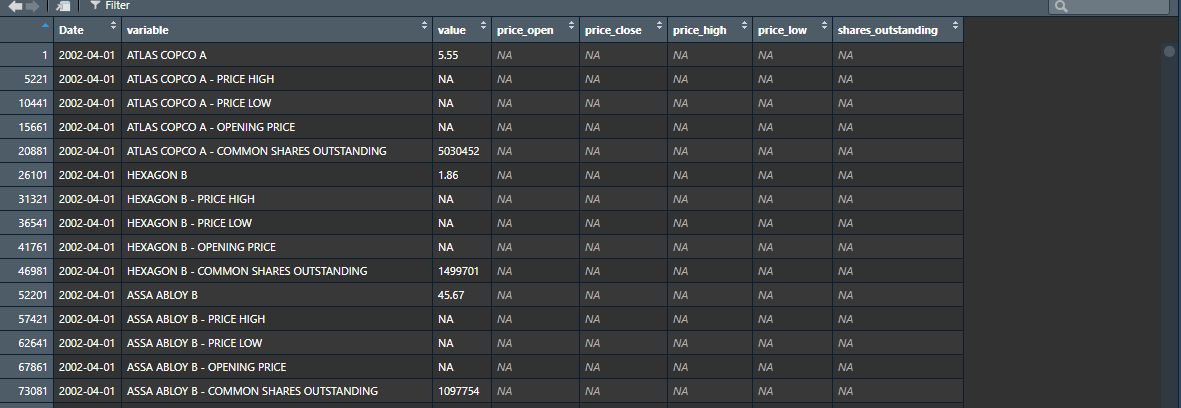
在附圖中,您可以看到我的資料的樣子。
uj5u.com熱心網友回復:
您所描述的是將您的資料從“長格式轉換為寬格式”。搜索該短語將在 R 中找到很多方法來完成此操作。這是一種,您可以pivot_wider()從 tidyr 中使用,如下所示:
(編輯以separate()按照@Axeman 的建議使用)
library(dplyr)
library(tidyr)
df %>%
separate(col = "variable", into = c("company", "metric"), sep = " - ") %>%
pivot_wider(id_cols = c("company", "date"), names_from = "metric", values_from = "value")
#> company date Price Close High Price Price Low Opening price
#> 1 Company 1 2022-01-01 5.5 6.0 5.0 5.0
#> 2 Company 2 2022-01-01 3.5 7.0 8.0 1.0
#> 3 Company 1 2022-01-02 5.4 5.9 4.9 4.8
#> Common Shares Outstanding
#> 1 1000
#> 2 5000
#> 3 1000
資料:
df <- data.frame(variable = c("Company 1 - Price Close",
"Company 1 - High Price",
"Company 1 - Price Low",
"Company 1 - Opening price",
"Company 1 - Common Shares Outstanding",
"Company 2 - Price Close",
"Company 2 - High Price",
"Company 2 - Price Low",
"Company 2 - Opening price",
"Company 2 - Common Shares Outstanding",
"Company 1 - Price Close",
"Company 1 - High Price",
"Company 1 - Price Low",
"Company 1 - Opening price",
"Company 1 - Common Shares Outstanding"),
date = c(rep("2022-01-01", 10), rep("2022-01-02", 5)),
value = c(5.5, 6, 5, 5, 1000,
3.5, 7, 8, 1, 5000,
5.4, 5.9, 4.9, 4.8, 1000))
由 reprex 包于 2022-05-23 創建 (v2.0.1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/480954.html