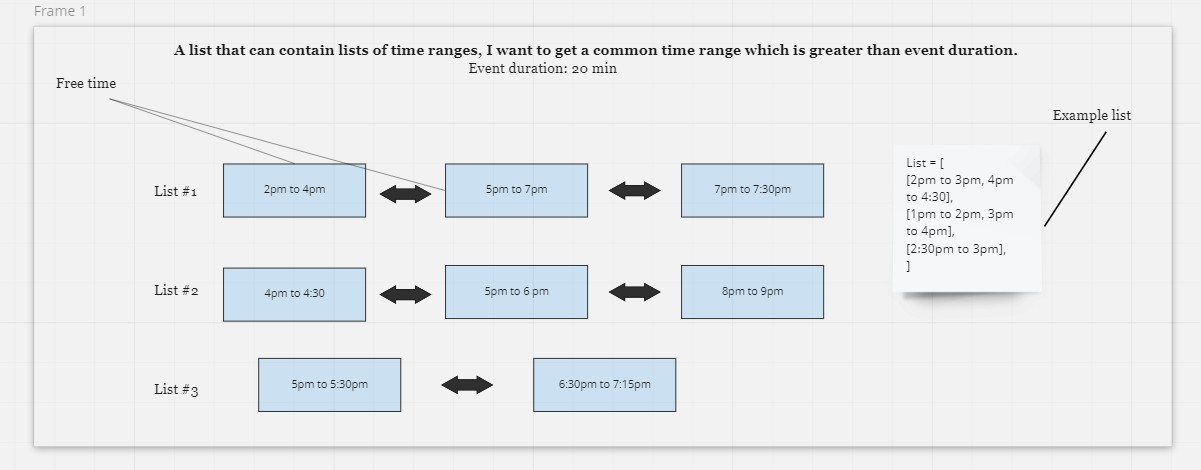
我正在努力實作這種演算法,從給定的子串列串列中找到一個公共時隙,該串列可以有超過 1 個子串列,最多 4 個,而且我的事件持續時間為 20 分鐘,我想找到一個 20 分鐘的公共時間段,以滿足所有存在的子串列。樣本資料如下:
ranges = [
[(datetime.datetime(2022, 6, 2, 9, 0), datetime.datetime(2022, 6, 2, 9, 30)), (datetime.datetime(2022, 6, 2, 11, 0), datetime.datetime(2022, 6, 2, 12, 10))],
[(datetime.datetime(2022, 6, 2, 5, 9), datetime.datetime(2022, 6, 2, 6, 56)), (datetime.datetime(2022, 6, 2, 15, 37), datetime.datetime(2022, 6, 2, 17, 24))],
[(datetime.datetime(2022, 6, 2, 4, 41, 3), datetime.datetime(2022, 6, 2, 6, 33, 3))],
[(datetime.datetime(2022, 6, 2, 20, 0), datetime.datetime(2022, 6, 2, 20, 23, 24))]
]
在每個子串列中,對范圍進行了排序,沒有重疊,我有這個流程圖,你可以使用:
我對此的看法是:
我將一個接一個地與前一個進行比較,并獲得匹配的日期,將它們存盤在一個串列中,然后在進行比較的產品上再次進行,
例如:
如果有4個子串列,我將比較1、2和3、4,將兩種產品的共同時間分別存盤到串列a和b中,然后在串列a和b上再做一次,但是出現qs如何比較,
到目前為止我嘗試過的是:
def compare_lists(list1, list2):
gap_list = []
for x in list1:
for y in list2:
if (y[0] < x[0] and y[1] < x[1]):
if y[1] - y[0] > duration:
gap_list.append(y)
if (x[0] < y[0] and x[1] < y[1]):
if x[1] - x[0] > duration:
gap_list.append(x)
return gap_list
duration = timedelta(minutes=20)
ranges = [
[(datetime.datetime(2022, 6, 2, 9, 0), datetime.datetime(2022, 6, 2, 9, 30)), (datetime.datetime(2022, 6, 2, 11, 0), datetime.datetime(2022, 6, 2, 12, 10))],
[(datetime.datetime(2022, 6, 2, 5, 9), datetime.datetime(2022, 6, 2, 6, 56)), (datetime.datetime(2022, 6, 2, 15, 37), datetime.datetime(2022, 6, 2, 17, 24))],
[(datetime.datetime(2022, 6, 2, 4, 41, 3), datetime.datetime(2022, 6, 2, 6, 33, 3))],
[(datetime.datetime(2022, 6, 2, 20, 0), datetime.datetime(2022, 6, 2, 20, 23, 24))]
]
product_lists = []
for x, y in zip(ranges, ranges[1:]):
product = compare_lists(x, y)
product_lists.append(product)
print(product_lists)
我不知道下一步該怎么做,一團糟,列印結果是這樣的
[
[
(datetime.datetime(2022, 6, 2, 5, 9), datetime.datetime(2022, 6, 2, 6, 56)), (datetime.datetime(2022, 6, 2, 9, 0), datetime.datetime(2022, 6, 2, 9, 30)),
(datetime.datetime(2022, 6, 2, 5, 9), datetime.datetime(2022, 6, 2, 6, 56)), (datetime.datetime(2022, 6, 2, 11, 0), datetime.datetime(2022, 6, 2, 12, 10))
],
[
(datetime.datetime(2022, 6, 2, 4, 41, 3), datetime.datetime(2022, 6, 2, 6, 33, 3)),
(datetime.datetime(2022, 6, 2, 4, 41, 3), datetime.datetime(2022, 6, 2, 6, 33, 3))
],
[
(datetime.datetime(2022, 6, 2, 4, 41, 3), datetime.datetime(2022, 6, 2, 6, 33, 3))
]
]
任何一點幫助將不勝感激,謝謝!
uj5u.com熱心網友回復:
如果這行得通,因為您的示例資料沒有任何有效時間,但這是我的想法
from datetime import datetime, timedelta
"""
Using two lists of time ranges, finds all ranges for which they overlap.
"""
def findCommon(list1, list2, minLength=timedelta(minutes=0)):
newList = []
for range1 in list1:
for range2 in list2:
overlapStart = max(range1[0], range2[0]) # the latest start time
overlapEnd = min(range1[1], range2[1]) # the earliest end time
if overlapEnd - overlapStart >= minLength:
newList.append((overlapStart, overlapEnd))
return newList
"""
Recursively finds the common times in several lists by taking the first two
items and finding their common ranges and then taking that new set of ranges
and applying it to the next item and so on.
"""
def reduce(listOfLists, minLength=timedelta(minutes=0)):
if len(listOfLists) > 2:
return reduce([findCommon(listOfLists[0], listOfLists[1], minLength)] listOfLists[2:], minLength)
else:
return findCommon(listOfLists[0], listOfLists[1], minLength)
duration = timedelta(minutes=20)
ranges = [
[(datetime(1,1,1,1,0), datetime(1,1,1,2,0)), (datetime(1,1,1,2,30), datetime(1,1,1,3,0))],
[(datetime(1,1,1,1,40), datetime(1,1,1,3,0))],
[(datetime(1,1,1,1,20), datetime(1,1,1,2,50))]
]
print(reduce(ranges, duration))
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/486310.html