我想根據比較時間的邏輯組合兩個熊貓資料集。我有以下兩個資料集。
df1
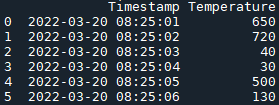
df1 = pd.DataFrame({'Timestamp': ['2022-03-20 08:25:01', '2022-03-20 08:25:02', '2022-03-20 08:25:03', '2022-03-20 08:25:04', '2022-03-20 08:25:05', '2022-03-20 08:25:06'],
'Temperature': ['650', '720', '40', '30', '500', '130']})
df2

df2 = pd.DataFrame({'Testphase': ['A1', 'A2', 'A3'],
'Begin_time': ['2022-03-20 08:25:01', '2022-03-20 08:25:04', '2022-03-20 08:25:30'],
'End_time': ['2022-03-20 08:25:03', '2022-03-20 08:25:05' , '2022-03-20 08:25:35']})
所需的df
現在我想根據 df2 的“Begin_time”和“End_time”將 Testphase 添加到 df1。如果時間在這些時間之間或之間,我想添加“Testphase”的值。這是期望的結果:
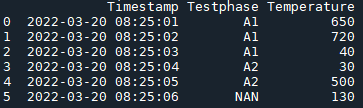
df_desired = pd.DataFrame({'Timestamp': ['2022-03-20 08:25:01', '2022-03-20 08:25:02', '2022-03-20 08:25:03', '2022-03-20 08:25:04', '2022-03-20 08:25:05', '2022-03-20 08:25:06'],
'Testphase': ['A1', 'A1', 'A1', 'A2', 'A2', 'NAN'],
'Temperature': ['650', '720', '40', '30', '500', '130']})
我有兩個想法
- 在 df1 的行上迭代邏輯 Begin_time<Timestamp<End_time 并在 True 時添加“Testphase”
- 創建一個新的資料框,它是 df2 的爆炸版本,每秒有行,然后使用時間戳將新的日期框與 pandas.DataFrame.join 合并到 df1。
但我無法弄清楚如何實際編碼它。
uj5u.com熱心網友回復:
你可以試試pd.IntervalIndex
#df2.Begin_time = pd.to_datetime(df2.Begin_time)
#df2.End_time = pd.to_datetime(df2.End_time)
df2.index = pd.IntervalIndex.from_arrays(left = df2.Begin_time,right = df2.End_time,closed='both')
df1['new'] = df2.Testphase.reindex(pd.to_datetime(df1.Timestamp)).tolist()
df1
Out[209]:
Timestamp Temperature new
0 2022-03-20 08:25:01 650 A1
1 2022-03-20 08:25:02 720 A1
2 2022-03-20 08:25:03 40 A1
3 2022-03-20 08:25:04 30 A2
4 2022-03-20 08:25:05 500 A2
5 2022-03-20 08:25:06 130 NaN
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/487180.html
下一篇:將字串轉換為時間c#