- 核心組件
- 任務和實體
- 時間序列
- PromQL
核心組件
Prometheus是一個開源的監控告警系統,它支持按多個維度存盤監控資料,配套的PromQL可以對資料進行靈活的查詢,
下圖為其整體的架構:
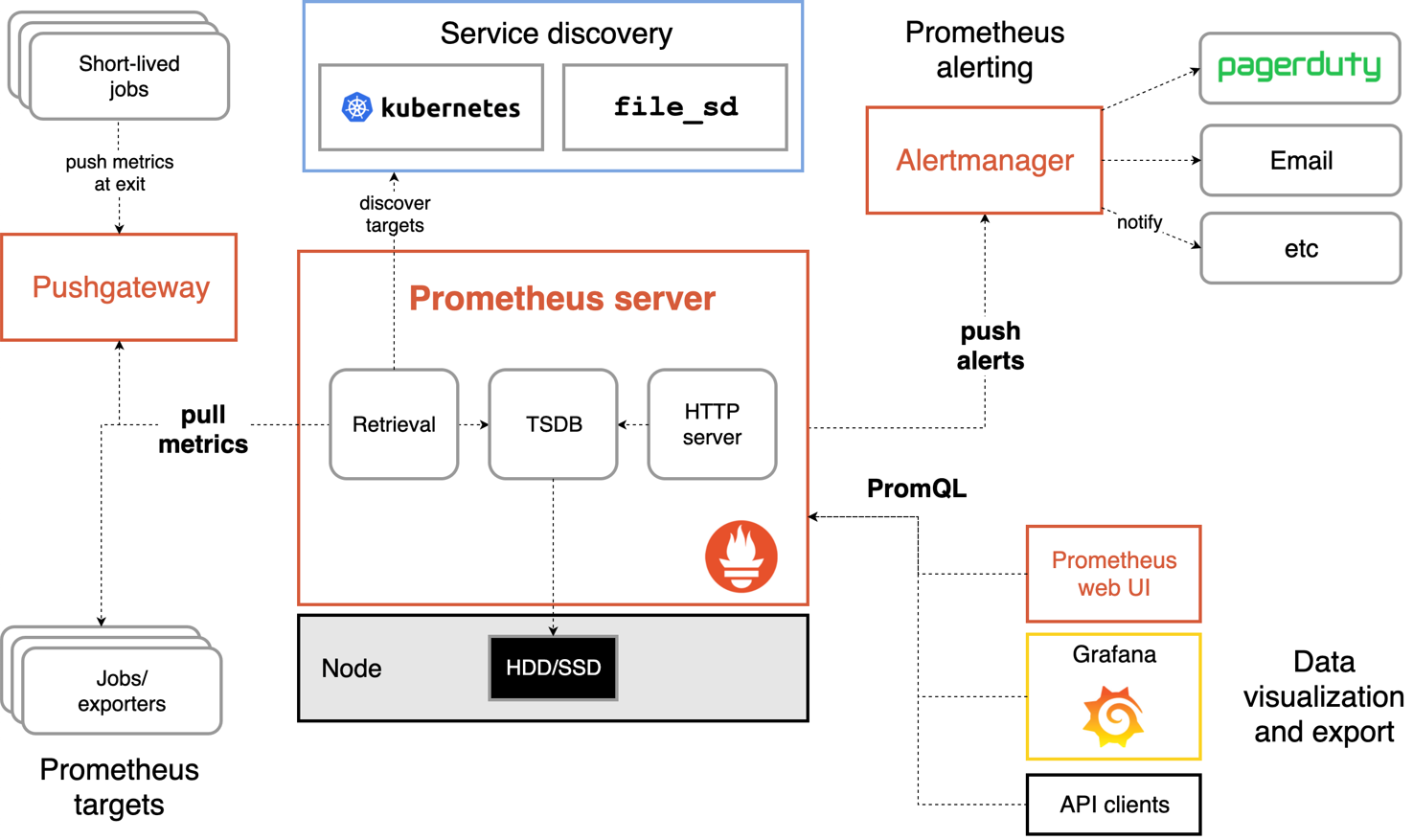
主要包含四部分:
- Prometheus Server,Prometheus Server用于從Exporters拉取資料,將采集到的監控資料按照時間序列的方式存盤在本地磁盤當中(Prometheus Server本身也是一個時序資料庫);并支持通過PromQL和通過API Client對資料進行查詢; 它還負責通過服務發現或者靜態配置的方式來識別監控目標,
- Exporters,用于從監控目標采集資料,并先Prometheus Server提供收集資料的埠,是一個廣義的概念,只要可以支持Server獲取監控資料,就可以稱為Exporter,具體分為兩類:直接采集:此類Exporter直接內置了對Prometheus監控的支持,如cAdvisor, Kubernetes, Etcd等;間接采集:被監控目標不支持直接采集,需要集成專門的類別庫,比如Mysql Exporter, Consule Exporter, ASP.NET Core Exporter等,
- PushGateway,Prometheus采用Pull模式采集資料,Server會定期呼叫Exporter提供的埠;但對于定期運行的Job類應用來說,并不是總能采集到資料,此外也可能受網路的限制,Server無法訪問到Exporter,這些情況下,可以使用PushGateway進行資料的中轉,由Exporter采用Push模式主動將資料發送到PushGateway,再由Server從PushGateway拉取資料,
- AlertManager,Prometheus Server支持基于PromQL創建告警規則,如果規則滿足,會產生一條告警,告警的后續處理流程由AlertManager來處理,它內置支持郵件、Slack等方式,也可以通過WebHook支持更多的自定義方式,
通過Docker容器啟動
docker run -p 9090:9090 -v ${pwd}\prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
啟動完成后,可以通過http://localhost:9090/graph 訪問Prometheus的UI界面,或者通過http://localhost:9090/metrics查看原始資料,
任務和實體
prometheus.yml的配置示例:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
這段基本的prometheus.yml進行了對任務(job_name)、實體(targets)、抓取間隔(scrape_interval)的配置,
實體:暴露監控樣本資料的HTTP服務,也就是Exporter的HTTP埠地址;
任務: 一組相同采集目的的實體,或者同一個采集行程的多個副本則通過任務來管理,
時間序列
Prometheus會將所有采集到的樣本資料以時間序列(time-series)的方式保存在記憶體資料庫中,并且定時保存到硬碟上,time-series是按照時間戳和值的序列順序存放的,稱為向量(vector). 每條time-series通過指標名稱(metrics name)和一組標簽集(labelset)命名,可以將time-series理解為一個以時間為X軸的數字矩陣,
^
│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu="cpu0",mode="idle"}
│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu="cpu0",mode="system"}
│ . . . . . . . . . . . . . . . . . . node_load1{}
│ . . . . . . . . . . . . . . . . . .
v
<------------------ time ---------------->
Sample
矩陣的每一個點稱為一個樣本(sample),樣本由以下三部分組成:
- 指標(metric):metric name和描述當前樣本特征的labelsets;
- 時間戳(timestamp):一個精確到毫秒的時間戳;
- 樣本值(value):一個float64的浮點型資料,表示當前樣本的值,
<--------------- metric ---------------------><-timestamp -><-value->
http_request_total{status="200", method="GET"}@1434417560938 => 94355
Metric
Metric的格式:
<metric name>{<label name>=<label value>, ...}
其中,一個metric可以包含多個標簽(label),用來從多個維度反映當前樣本的特征,通過這些維度,Prometheus可以對樣本資料進行過濾、聚合等計算,
Metric的型別:
在Prometheus的存盤實作上所有的監控樣本都是以time-series的形式保存在記憶體TSDB(時序資料庫)中的,而time-series又歸屬于不同的metric,所以從存盤上來講所有的metric都是相同的,但是在不同的場景下這些metric又有區別,具體分為:
- Counter(計數器)
- Gauge(儀表盤)
- Histogram(直方圖)
- Summary(摘要)
Counter
Counter計數器的值只增不減(除非系統發生重置),這種metric用途非常廣泛,比如可以在應用程式中記錄某些事件發生的次數,然后通過使用PromQL內置的一系列函式對資料做進一步的分析,比如計算該事件產生速率隨時間的變化,
通過rate()計算5m內的平均增長率:
rate(process_cpu_seconds_total[5m])
通過topk查詢埠訪問量前10:
topk(10,prometheus_http_requests_total)
Gauge
與Counter不同,Gauge型別的指標側重于反應系統的當前狀態,因此這類指標的樣本資料可增可減,常見指標如node_exporter提供的node_memory_MemFree(主機當前空閑的內容大小)、node_memory_MemAvailable(可用記憶體大小)等,
直接查看系統的當前狀態:
go_goroutines
通過delta()可以獲取樣本在一段時間回傳內的增減情況:
delta(go_goroutines[2h])
Summary和Histogram
這兩類指標主要用于統計和分析樣本的分布情況,對于一些量化的指標,一般情況下都會計算其平均值,比如API平均回應時間,但這些統計方式會受長尾問題的影響,比如假設大多數API回應都在500ms之間,只有少部分回應時間需要5s,那么統計平均值后就無法識別這少部分回應特別慢的請求,
為了區分是平均的慢還是長尾的慢,可以按照請求回應的時間范圍進行分組,Summary和Histogram都可以用于這類統計,但Histogram會按值所在的范圍,統計各范圍區間的數量;Summary則會按照中位數來統計,
比如Summary型別的go_gc_duration_seconds:
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.8753e-05
go_gc_duration_seconds{quantile="0.25"} 7.731e-05
go_gc_duration_seconds{quantile="0.5"} 0.000111513
go_gc_duration_seconds{quantile="0.75"} 0.000220177
go_gc_duration_seconds{quantile="1"} 0.00450966
go_gc_duration_seconds_sum 0.164080505
go_gc_duration_seconds_count 1003
從上面的樣本可以得知go_gc的總次數為1003次,總耗時0.164080505s,中位數耗時0.000111513s,
PromQL
PromQL是Prometheus內置的資料查詢語言,其提供對時間序列資料豐富的查詢、聚合以及邏輯運算能力的支持,常用于資料查詢、可視化、告警處理等場景,
查詢時間序列
Prometheus通過指標名稱(metrics name)以及對應的一組標簽(labelset)唯一定義一條時間序列,
當直接使用監控指標名稱查詢時,可以查詢該指標名稱下的所有時間序列:
promhttp_metric_handler_requests_total
promhttp_metric_handler_requests_total{code="200", instance="host.docker.internal:9090", job="prometheus"} 893
promhttp_metric_handler_requests_total{code="500", instance="host.docker.internal:9090", job="prometheus"} 0
promhttp_metric_handler_requests_total{code="503", instance="host.docker.internal:9090", job="prometheus"} 0
標簽匹配模式
- 完全匹配,=和!=
promhttp_metric_handler_requests_total{code="200"}
promhttp_metric_handler_requests_total{code!="200"}
- 正則匹配,=~和!~
promhttp_metric_handler_requests_total{code=~"200|500"}
promhttp_metric_handler_requests_total{code!~"200|500"}
范圍查詢
直接使用監控指標名稱查詢時,回傳值中只包含該時間序列中最新的一個樣本值,這樣的回傳結果也叫瞬時向量,對應的運算式稱為瞬時向量運算式,
如果想查詢過去一段時間范圍內的樣本資料時,則需要使用區間向量運算式,通過[]來定義
promhttp_metric_handler_requests_total[5m]
支持的時間單位有s m h d w y
promhttp_metric_handler_requests_total{code="200", instance="host.docker.internal:9090", job="prometheus"}[15s]
1280 @1653186543.159
1281 @1653186548.16
1282 @1653186553.16
時間位移操作
瞬時向量運算式或者區間向量運算式都是以當前時間為基準,而通過時間位移操作,可以改變時間基準,如位移到2天前:
promhttp_metric_handler_requests_total[15s] offset 2d
聚合操作
通過PromQL查詢時,如果指標和標簽不能唯一確定一條時間序列,則會回傳多條滿足這些特征維度的結果,而通過聚合操作可以對這些時間序列進行處理,現成一條新的時間序列,
sum (求和)
min (最小值)
max (最大值)
avg (平均值)
stddev (標準差)
stdvar (標準方差)
count (計數)
count_values (對value進行計數)
bottomk (后n條時序)
topk (前n條時序)
quantile (分位數)
如
sum(promhttp_metric_handler_requests_total)
{} 1387
avg(promhttp_metric_handler_requests_total) by (code)
{code="200"} 1395
{code="500"} 0
{code="503"} 0
標量和字串
除了向量型別,PromQL還支持使用標量(Scalar)和字串(String), Scalar是浮點型別的數字值,直接使用字串作為PromQL的運算式,則會直接回傳字串,
PromQL 運算子
數學運算
瞬時向量與標量直接可以進行加減乘除、取余、冪運算等數學運算,數學運算子會依次作用于瞬時向量的每個樣本值,從而得到一組新的時間序列,
而如果是瞬時向量與瞬時向量之間進行數學運算時,程序會相對復雜一點, 例如,如果我們想根據node_disk_bytes_written和node_disk_bytes_read獲取主機磁盤IO的總量,可以使用如下運算式:
node_disk_bytes_written + node_disk_bytes_read
PromQL會根據這個運算式依次找到與左邊向量元素匹配(標簽完全一致)的右邊向量元素進行運算,如果沒找到匹配元素,則直接丟棄,同時新的時間序列將不會包含指標名稱,
布爾運算
布爾運算可以根據時間序列中樣本的值,對其進行過濾,PrmoQL支持的布爾運算子有:
== (相等)
!= (不相等)
> (大于)
< (小于)
>= (大于等于)
<= (小于等于)
瞬時向量與標量進行布爾運算時,會依次對向量中所有時間序列樣本的值進行比較,如果結果為true則保留,否則會丟棄,
使用bool修飾符改變布爾運算子的行為
布爾運算子的默認行為是對時序資料進行過濾,而在其它的情況下我們可能需要的是真正的布爾結果,
比如判斷promhttp_metric_handler_requests_total的值是否大于1800,是則回傳1,否則回傳0,這時可以使用bool修飾符:
promhttp_metric_handler_requests_total > bool 1800
PromQL內置函式
通過內置函式可以對時序資料進行豐富的處理,
Increase: 計算Counter指標增長率
Counter型別的監控指標其特點是只增不減,在沒有發生重置(如服務器重啟,應用重啟)的情況下其樣本值應該是不斷增大的,為了能夠更直觀的表示樣本資料的變化劇烈情況,需要計算樣本的增長速率,
increase(v range-vector),引數v是一個區間向量,increase函式獲取區間向量中的第一個和最后一個樣本并回傳其增長量,因此promhttp_metric_handler_requests_total的增長率可以這樣計算:
increase(promhttp_metric_handler_requests_total[1m]) / 60
rate/irate
除了上述方法,使用rate函式也可以直接計算增長率:
rate(promhttp_metric_handler_requests_total[1m])
需要注意的是使用rate或者increase函式去計算樣本的平均增長速率,容易陷入“長尾問題”當中,其無法反應在時間視窗內樣本資料的突發變化, 例如,對于主機而言在2分鐘的時間視窗內,可能在某一個由于訪問量或者其它問題導致CPU占用100%的情況,但是通過計算在時間視窗內的平均增長率卻無法反應出該問題,
為了解決該問題,PromQL提供了另外一個靈敏度更高的函式irate(v range-vector),irate同樣用于計算區間向量的計算率,但是其反應出的是瞬時增長率,
irate(promhttp_metric_handler_requests_total[1m])
irate函式是通過區間向量中最后兩個樣本資料來計算區間向量的增長速率,這種方式可以避免在時間視窗范圍內的“長尾問題”,并且體現出更好的靈敏度,通過irate函式繪制的圖示能夠更好的反應樣本資料的瞬時變化狀態,
參考資料
https://yunlzheng.gitbook.io/prometheus-book/
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/498933.html
標籤:其他
下一篇:SmartIDE v0.1.18 已經發布 - 助力阿里國產IDE OpenSumi 插件安裝提速10倍、Dapr和Jupyter支持、CLI k8s支持