哈嘍,大家好!!!今天的主題:HashMap
反觀整個Java的集合框架,我們講了ArrayList、LinkedList、Stack、Queue、Deque、PriorityQueue等等集合,以及它們背后所對應的資料結構,今天我們來看一下java集合中,最為重要的,也是最常用的一個集合:HashMap,它的重要性,毋庸置疑,網上隨意找一篇面經,幾乎都會問到HashMap的底層實作、哈希沖突該怎么辦?…… 這里我們就不細說了,直接進入主題,

文章目錄
- 一、認識HashMap
- 二、哈希函式
- 1、哈希函式的概念
- 2、哈希沖突,該怎么辦?
- 3、JDK1.8的HashMap原始碼
- (1)構造方法
- (2)put方法
- 三、面試題總結
一、認識HashMap
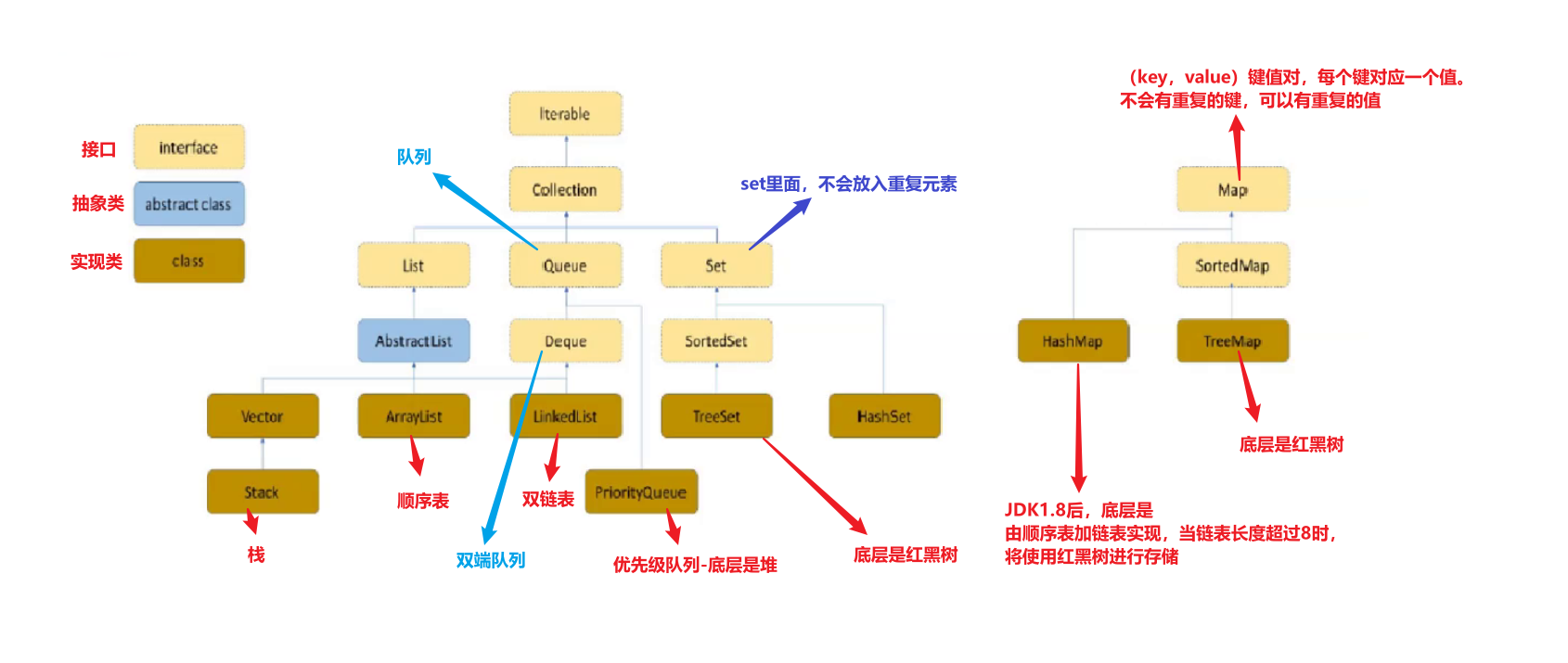
HashMap,實作了Map介面,資料存盤形式采用鍵值對,也就是一個鍵對應一個值,如下圖:
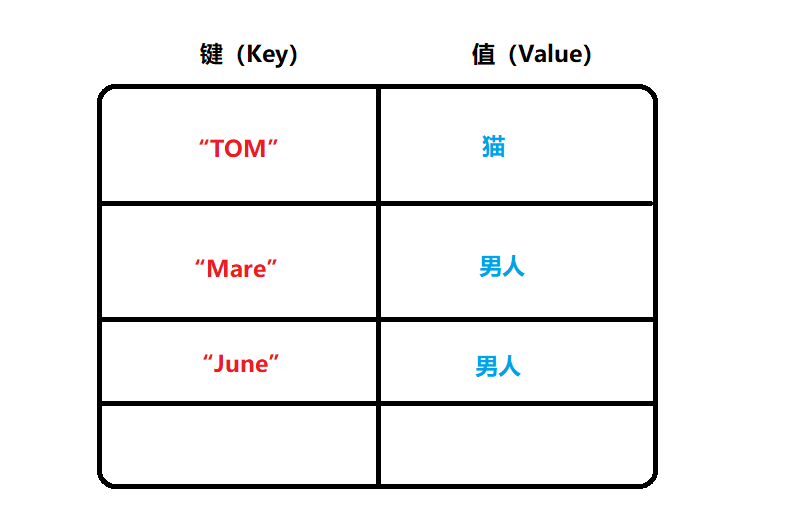
由上圖可以清晰地看出,每一個鍵都對應一個唯一的值,并且鍵(Key)不能夠重復,但值(Value)可以有重復的,這就是哈希表的形式,可能大家覺得這也沒什么奇妙之處,不急,后面再說它的驚人之處,我們先來看看這該怎么使用這個HashMap,
構造方法:
HashMap<String, String> map1 = new HashMap<>(); //無參構造
HashMap<String, String> map2 = new HashMap<>(20);//指定初始容量
HashMap<String, String> map3 = new HashMap<>(20, 0.75f); //指定初始容量和負載因子
具體的用法就是:
-
添加元素
map1.put("TOM", "貓");//put方法,往里面添加元素 -
獲得值(Value)
//根據TOM這個鍵,拿到相應的值,如果沒有這個鍵,則回傳null String value = map1.get("TOM"); -
洗掉元素
map1.remove("TOM");//根據鍵,去洗掉鍵值對 map1.clear(); //洗掉map1的所有元素 -
元素個數
int size = map1.size(); //回傳當前集合中的鍵值對數量 -
查找是否包含鍵(Key)
//查找map1是否有TOM這個鍵(Key) boolean isContainsK = map1.containsKey("TOM"); -
查找是否包含值(Value)
//查找map1是否有貓,這個值(Value) boolean isContainsV = map1.containsValue("貓"); -
map轉Set
//將map集合,轉換為Set型別的集合 Set<Map.Entry<String, String>> entry = map1.entrySet();
以上方法,都好理解,主要就是最后一個Map轉為Set的這個方法,我們講解一下,
因為Set集合,它只是存盤一個型別的元素,而不像HashMap這樣是鍵值對,所有當HashMap轉為Set時,會將HashMap的鍵和值,打包成一個整體(Map.Entry<K,V>),打包后的物件型別就是這個括號里面的,然后再將打包好的整體放入Set集合中,如下圖所示:
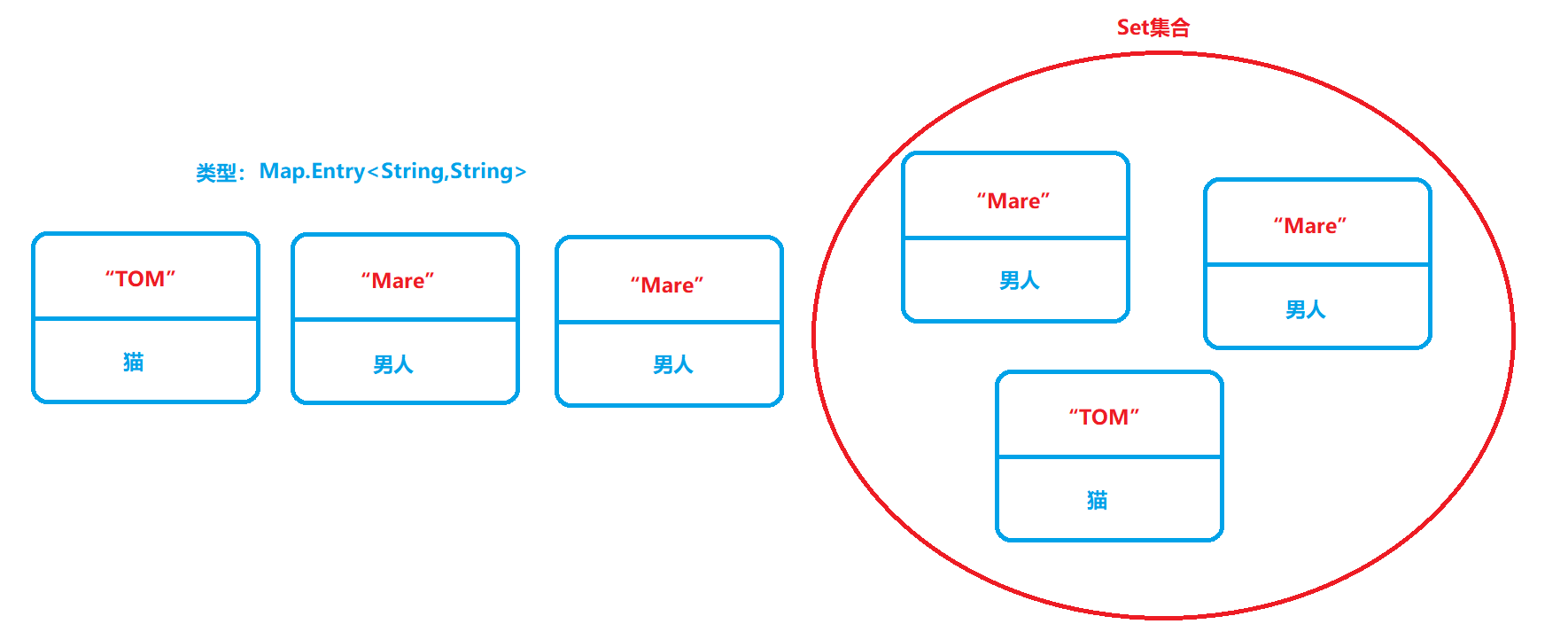
就如上圖,打包成Map.Entry<K,V>型別,再放入Set集合中,這樣做的好處就是,可以使用迭代器(Iterator)進行遍歷,因為Map介面是沒實作Interable介面的,無法使用迭代器,只能轉為Set集合,再使用迭代器,以下是使用迭代器的代碼:
Set<Map.Entry<String, String>> entry = map1.entrySet();
for (Map.Entry<String,String> set : entry) {
//呼叫get方法,即可拿到鍵和值
String key = set.getKey();
String value = set.getValue();
}
還有值得注意的是,鍵重復的情況,假設目前HashMap中已經有了(“TOM”,“貓”)這一對鍵值,如果此時我再添加元素(“TOM”,“狗”),因為鍵是一樣的,則會找到表中TOM的位置,將“狗”放入了表中,實作了覆寫的效果,如下代碼:
HashMap<String,String> map1 = new HashMap<>();
map1.put("TOM", "貓"); //第一次放入
map1.put("TOM", "狗"); //第二次方法,則會將貓改寫為狗
二、哈希函式
1、哈希函式的概念
在我們前面學習的所有資料結構中,無論是二叉樹,還是鏈表,在增刪查改的操作上,時間復雜度都還是有那么一點點不盡人意,拿搜索二叉樹舉例,當插入的資料有序時,會退化成鏈表,從而產生了平衡樹,但平衡樹的增刪查改也只能做到O(logN)的水平,沒法再快了,
但哈希函式可以做到O(1)的水平,這是一個非常恐怖的概念,增刪查改都能做到O(1)的水平,快了不止多少倍,那么它到底是怎么實作的?我們來簡單分析一下:
哈希函式:根據給定的資料,進行計算,得到一個地址,在這個地址的地方進行放入元素,
取出元素的時候,也只是根據資料計算一個地址,在該地址處取出元素,
這就是哈希函式簡單的認識,就是根據一些計算,推匯出一個地址,
比如:hash = 元素 % 10; 這樣一個最簡單的哈希函式公式,假設我們傳遞的資料,是99,則99 % 10 = 9,則在陣列下標為9的位置放入資料……
但是還有一個問題就是:假設現在傳遞的資料是89,89 % 10 = 9,還是在下標為9 的位置進行插入資料,此時就發生了意外,當前9下標位置已經有資料了,
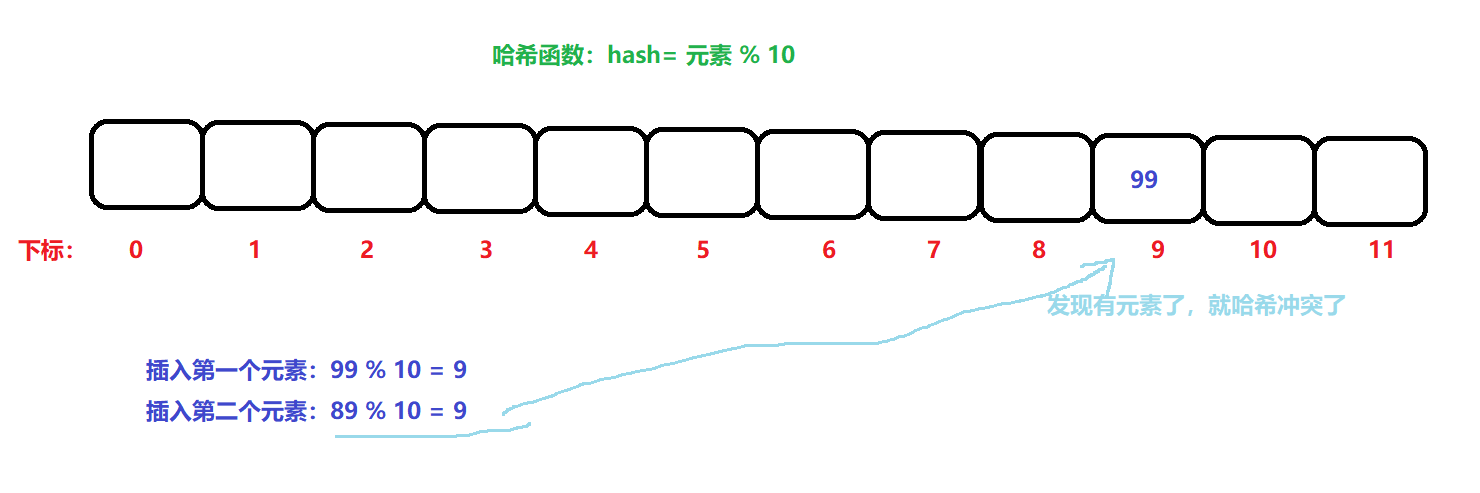
以上這樣的情況,就稱為哈希沖突,不同的關鍵字,根據相同的哈希函式計算出相同的哈希值,就是哈希沖突,
人們可以設計出精妙的哈希函式,來降低哈希沖突的概率,但是絕對不可能做到不發生沖突,也就是說,但我們添加元素足夠多時,發生哈希沖突,是一個必然的現象,
常見的哈希函式,我們這里就不列舉了,大家查一下就行,大多數人都不會去設計哈希函式,我們只需知道有這么個東西即可,
2、哈希沖突,該怎么辦?
為了盡量降低哈希沖突,我們就得從兩個方面著手:在發生沖突之前和發生沖突之后,
發生沖突之前:設計出精妙的哈希函式,存放資料的記憶體空間開辟大一點,還有就是有一個負載因子的概念,
負載因子:
也就是表中的元素除以哈希表的長度,就是負載因子,
負載因子的曲線圖大致如下:
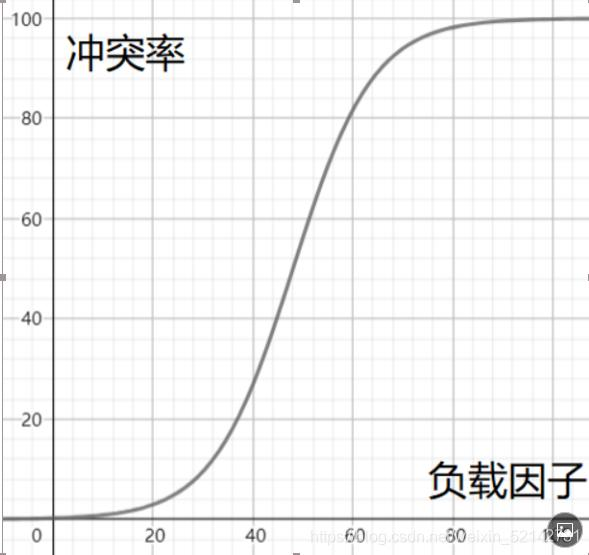
也就是說在負載因子達到一個界限的時候,就需要進行擴容,將陣列擴大,即可降低負載因子,
以上方案只是在盡量預防發生沖突,那如果真的發生沖突了,又該怎么辦?
哈希沖突后:
常見的解決哈希沖突的方法是:閉散列和開散列,
閉散列:也叫開放地址法,當發生哈希沖突的時候,說明此當前下標位置已經有資料了,此時我們只需沿著當前位置往下查找一個沒放資料的位置,插入資料即可,如下:
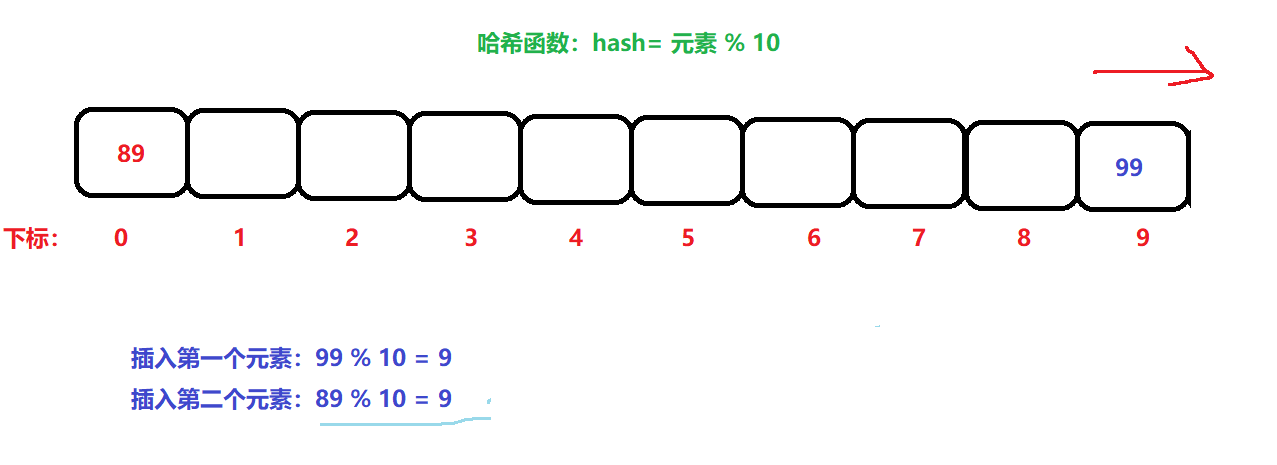
在插入89時,發生了沖突,就在9下標的后面找到一個空位置插入資料,但是9下標后面沒位置了,則從陣列前面開始找,
那有人可能就會問,會不會整個資料都已經滿了呢??
不可能的!因為有一個負載因子在控制陣列的大小,當負載因子達到一個值的時候,就會進行擴容,
以上的方法就稱為線型探測法,沿著下標,一直往下找,找到一個空位就插入即可,但是這樣做的不好之處就在于,發生沖突的所有資料都聚集在一塊地方,對洗掉操作增加了不小的難度,
例如:假設現在需要洗掉99,那能直接將99拿走嗎?如果拿走了,那89,又如何通過哈希函式取出呢??
所有線型探測法,對于洗掉操作,采用了偽洗掉法,也就是說,有一個變數記錄99的狀態表示已經洗掉了,
除了線型探測,還有二次探測法,就是為了解決沖突的元素聚集在一塊這個問題:二次探測法,將不在沿著沖突位置的下標一個一個往下找空位置,而是通過一個公式:待插入下標 = (沖突下標 + i 2)% m ,此處的i就是發生沖突的次數,比如89第一次插入時,會跟99第一次發生沖突,計算下一個下標后,發現下一位置還是沖突的,則i=2,一直往下推導……
最重要的就是開散列:
開散列:又叫鏈地址法,將發生沖突的元素,用一個單鏈表進行串連起來,將頭節點,放入陣列中即可,如下圖:
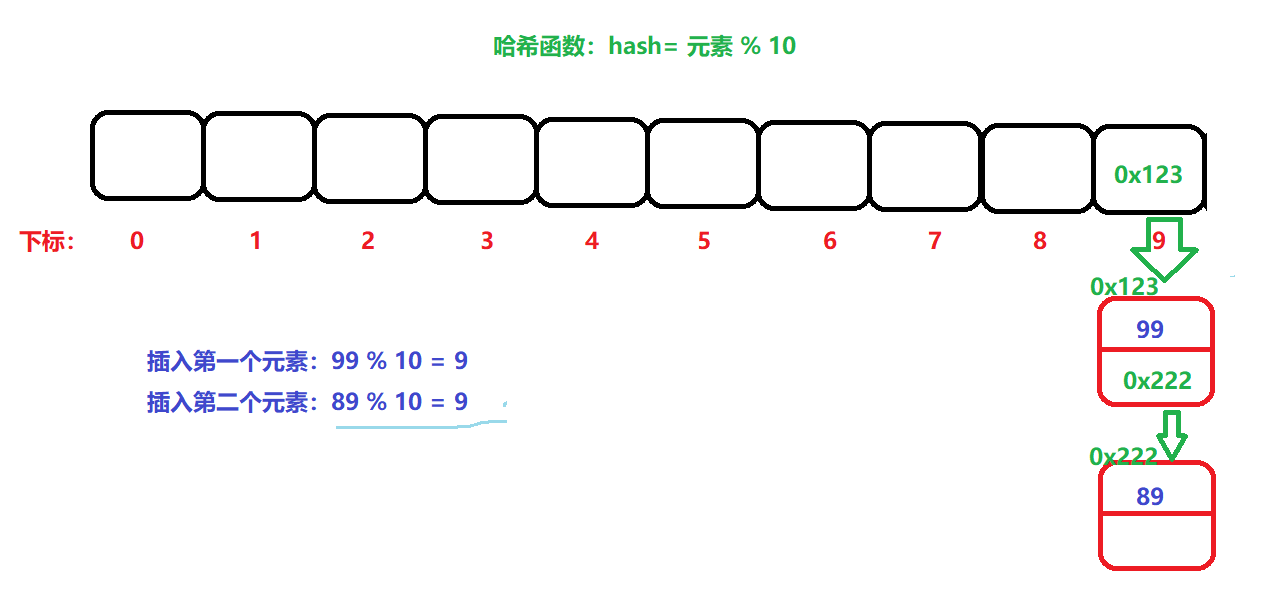
將所有發生沖突的元素,用一個單鏈表串連起來即可,然后在這個單鏈表中一個個查找,
但是還是會出現意外,如果單鏈表的長度很長的話,還是做不到O(1)的時間復雜度,那么此時就需要將這個單鏈表,轉換為一個哈希表,或者是建一個紅黑樹(JDK1.8之后)的形式,
以上兩種方法,就是解決哈希沖突之后的方案,特別值得記住的就是開散列,
3、JDK1.8的HashMap原始碼
(1)構造方法
在JDK1.8之前,HashMap只是采用陣列+單鏈表的形式進行存盤,且當時的單鏈表是用頭插法的形式插入節點的,
在JDK1.8之后,HashMap采用陣列+單鏈表+紅黑樹的形式進行存盤,且單鏈表是用尾插法的形式插入節點,
那么是怎么進行存盤的,我們來簡單分析一下原始碼:
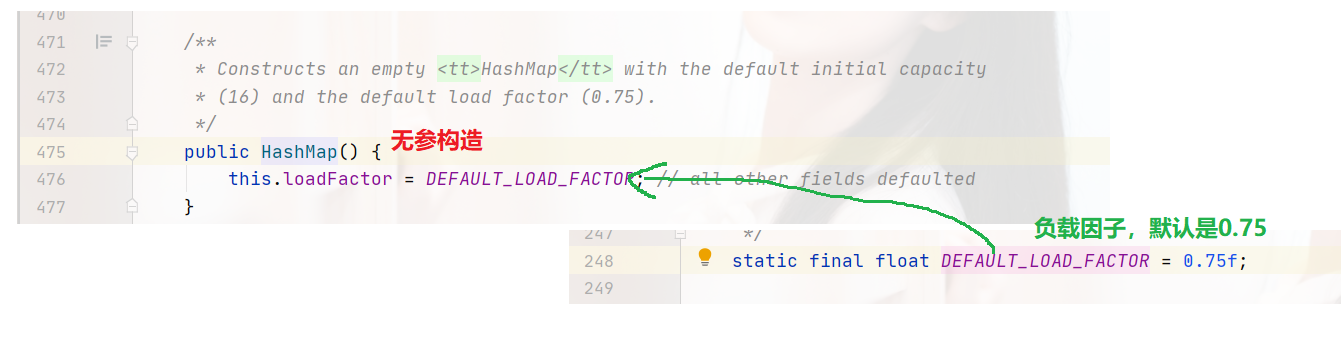
無參構造方法,只是設定了負載因子,并沒有設定HashMap底層陣列的大小,所以,只呼叫構造方法,不呼叫put方法,陣列大小是0,跟ArrayList是一樣的,ArrayList在呼叫add時,會將陣列大小設定為10,
有參構造方法:

切記:HashMap底層陣列的大小,一定是2的某次方,假設呼叫方傳遞的是20,這個數并不是2的某次方,則會向上調整,取離20最近的,且還是2的某次方的數,這里的話,離20最近且還是2的某次方的數,就是32,
千萬注意,HashMap底層陣列大小,不一定就是new的時候的初始化容量,
其次,我們需要認識一下幾個常見的成員變數,以便于我們后續讀懂put方法,

(2)put方法
在讀put方法前,一定需要理解上圖中的幾個成員變數的意義,然后再來讀put方法,這樣才不至于越看越懵,
-

首先第一步就是put方法,呼叫了putVal方法 ,這里需注意hash函式,設計的比較精妙,

hash函式,除了呼叫了hashCode方法以外,還將計算出來的hashCode的值右移了16位,然后再做與運算,因為hashCode放回的是int型別,右移16位是將這個數值的每一位都利用起來,
-
putVal方法
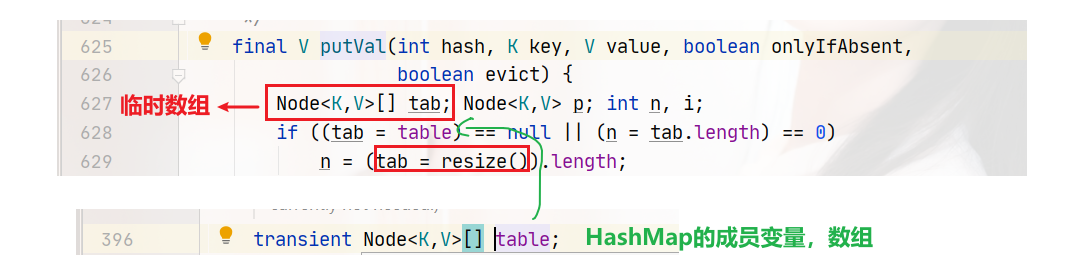
tab指向成員變數table陣列,n就是當前陣列的長度,
首先我們先來看第一條邏輯分支,628行,tab=table,首先是判斷是否為null,第二判斷就是陣列的長度等于0的時候,當呼叫無參構造方法時,沒有為陣列分配大小和賦值等操作,所有此時呼叫put方法是,第628行的邏輯判斷就是真:
第629行,tab=resize(),人如其名,resize就是調整陣列大小的,這個方法有兩個作用:
初始化陣列大小和擴容,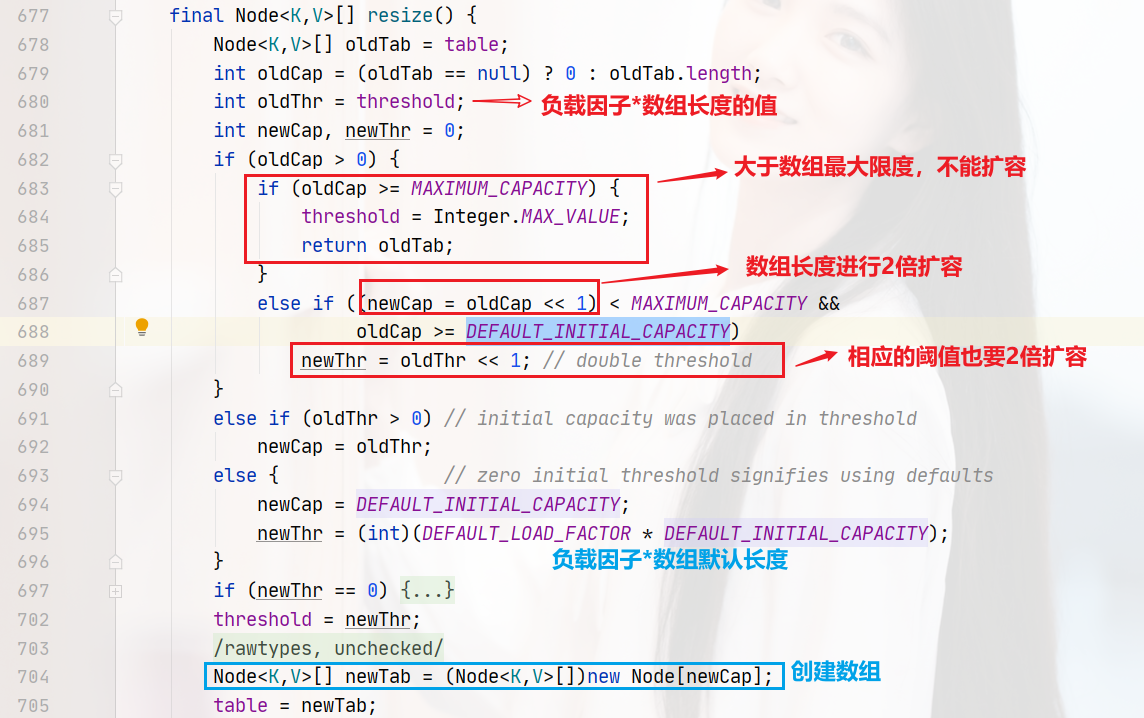
677行至705行的代碼,就是初始化創建table陣列,706行至749行的代碼,就是將擴容前的舊陣列的所有資料重新進行hash計算,放入新陣列,這里就不多講了,代碼如下:

-
陣列開辟好之后,就是將Key和Value放入HashMap中

切記切記:上圖的藍色框中,非常重要,可以說是精妙絕倫、無與倫比的設計理念,
i = (n - 1)& hash, n是當前陣列的長度,假設就是16,hash就是Key計算出來的哈希值
在n是2的某次方的前提下,切記切記,必須是2的某次方的前提,重要的事說三遍!!!
在n是2的某次方的前提下,切記切記,必須是2的某次方的前提,重要的事說三遍!!!
在n是2的某次方的前提下,切記切記,必須是2的某次方的前提,重要的事說三遍!!!
i = (n - 1) & hash ,等價于 i = hash % n
這一點非常非常重要!!!
因為位運算肯定是比取模運算快,這也是為什么在前面講構造方法的時候,JDK為什么會將容量調整為2的某次方的原因,可以說,JDK的實作者,為了加快HashMap的速度,費了大心思,
這一點理解后,就好理解后面的了,根據上面的i計算之后,當前i的值肯定是在0~n-1的范圍內,此時再去相應的位置放資料,
第630行判斷當前i位置是不是null,如果是null,說明這個位置還沒有元素,直接插入node節點即可,
不用想,632行開始,就是i位置不是null時,就需要將新節點插入到單鏈表中

在調整為紅黑樹的時候,網上很多帖子寫的都是在JDK1.8之后,當鏈表長度大于8時,就調整為紅黑樹,這是錯的,

調整為紅黑樹的代碼如上圖,如果此時的數值長度沒有超過64時,只會進行擴容,不會調整為紅黑樹,
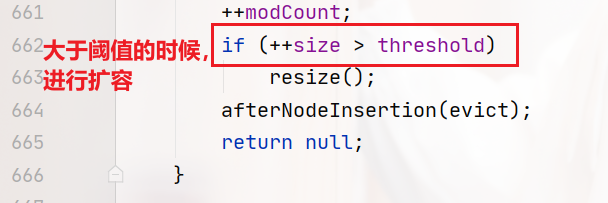
代碼的最后就是計算當前HashMap的元素個數,看是否超過了負載因子*數值長度,這個閾值,超過了就擴容:
三、面試題總結

-
如果new HashMap(19),此時HashMap內的陣列長度是多少?
答:如果只是呼叫構造方法的話,陣列大小是0,因為此時的構造方法,只是將計算好的陣列長度存盤到一個成員變數里,還并沒有開辟陣列,在第一次呼叫put方法時,會呼叫resize方法,進行開辟陣列, 如果除了呼叫構造方法,還呼叫了一次put方法的話,那么陣列長度就是32,因為JDK底層會將19向上調整,第一個是2的某次方的數,就是最后陣列的長度,
-
那么為什么JDK底層會調整19這個陣列長度呢?必須是2的某次方,目的是什么?
答:因為在存放資料的時候,需要對哈希值求余數,這個余數就是陣列的下標,如果此時用取模運算(%),不夠高效;而當陣列的長度是2的某次方的時候,可以通過以下公式直接計算取模后的結果:i = (n - 1) & hash,(與運算比取模運算快)
-
HashMap在什么時候進行擴容?
答:在JDK1.8中,當前哈希表的元素個數大于等于負載因子*陣列長度時,會進行擴容操作,(JDK1.8的負載因子是0.75)
-
當兩個物件的hash值相同時,會發生什么?
答:哈希沖突,
-
如果兩個鍵的hash值相同,該怎么取到相應的Value值?
答:遍歷當前的鏈表(紅黑樹),如果在某一個節點處,這個節點Key和此時我傳遞進去的Key相等,那么就是當前這個節點Value,
-
你了解過重新調整HashMap大小時存在什么問題嗎?
答:重新調整HashMap的大小,會將以前舊陣列的所有資料,重新進行哈希計算,再放入新陣列,
-
HashMap的內部是如何進行存盤資料的?
答:在JDK1.8之前,采用陣列+單鏈表的形式,且單鏈表的插入方式是頭插法,在JDK1.8之后,采用陣列+單鏈表+紅黑樹的形式,且單鏈表的插入方式是尾插法,
-
在什么情況下,HashMap會將單鏈表轉換為紅黑樹?
答:在陣列的長度大于等于64,且單鏈表的長度大于等于8的時候,會轉換為紅黑樹,
好啦,本期更新就到此結束啦!!!我們下期見!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/347111.html
標籤:java