我有 DataFrame,我試圖在其中添加一個新的“排名”列,以通過比較價格(“價格”列)來確定相對于“名稱”和“國家/地區”列的價格評級。如果一種產品的價格相同,則在使用時
df['rank'] = df.groupby('name')['price'].apply(lambda x: x.sort_values().rank())
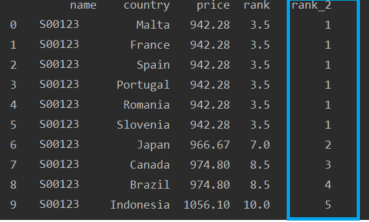
我得到以下結果 -> 'rank' 列,但我需要得到在 'rank_2' 中突出顯示的那個,它不準確,因為這六種產品的價格相同,應該獲得 1 的評級。如何是否有可能獲得列 -> 'rank_2' 中的給定結果。請幫忙,我將不勝感激
uj5u.com熱心網友回復:
您必須在排名函式中選擇排名方法,如下所示:
df['rank'] = df.groupby('name')['price'].apply(lambda x: x.sort_values().rank(method="dense"))
uj5u.com熱心網友回復:
如果我理解正確的話:
您可以使用:
df['rank'] = df.sort_values(by=['name', 'price']).groupby(['name'])[['price']].apply(lambda x: x!= x.shift()).cumsum()
或者
df['rank'] = df.sort_values(by=['name', 'price']).groupby('name')['price'].apply(lambda x: x.rank(method="dense"))
兩種情況下的輸出:
name country price rank
0 S00123 mal 3.5 1.0
1 S00123 fra 3.5 1.0
2 S00123 spa 3.5 1.0
3 S00123 pur 3.5 1.0
4 S00123 rom 3.5 1.0
5 S00123 slo 3.5 1.0
6 S00123 jap 7.0 2.0
7 S00123 can 8.5 3.0
8 S00123 bra 8.5 3.0
9 S00123 ind 10.0 4.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/313012.html