我有一個看起來像這樣的資料框:
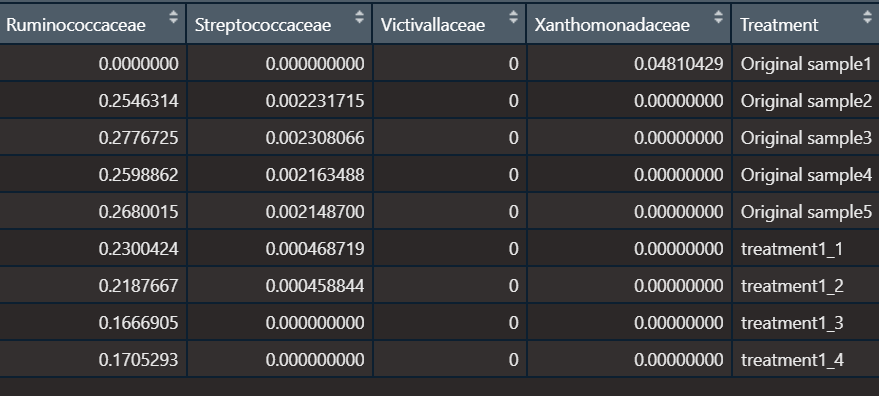
總共 36 列。
資料示例代碼:
df <-
structure(
list(
Bacteroidaceae = c(
0,
0.10944999,
0.104713314,
0.125727668,
0.124136247,
0.005155911,
0.005072778,
0.010231826,
0.010188139
),
Christensenellaceae = c(
0,
0.009910731,
0.010131195,
0.009679938,
0.01147601,
0.010484508,
0.008641566,
0.010017172,
0.010741488
),
treatment = c(
"Original Sample1",
"Original Sample2",
"Original Sample3",
"Original Sample4",
"treatment1_1",
"treatment1_2",
"treatment1_3",
"treatment1_4"
)
),
class = "data.frame",
row.names = c(NA,-8L)
)
我想要做的是為資料中的所有列創建圖,這樣每一列都會有 2 個圖:一個用于處理 1,另一個用于原始樣本,總共 72 個圖
例如:
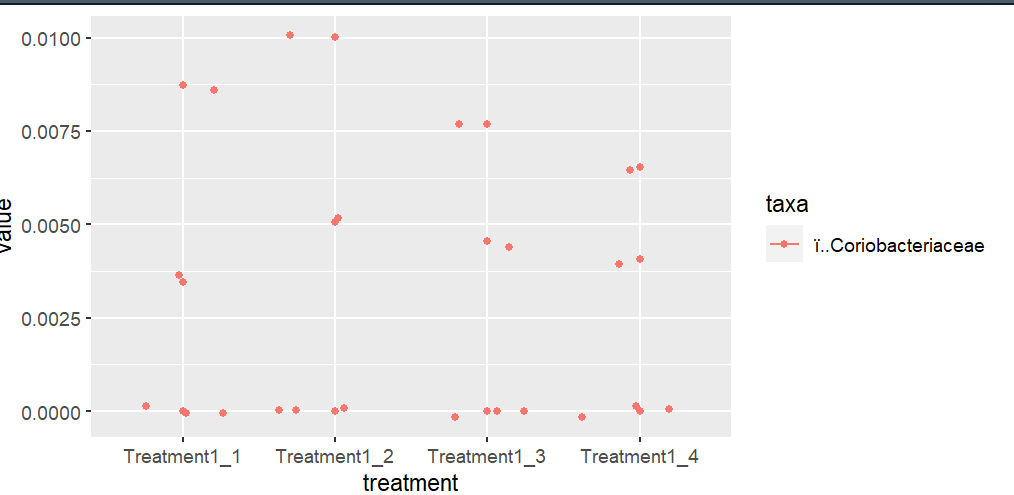
對于我嘗試使用此代碼的原始樣本型別,相同:
df %>%
tidyr::pivot_longer(!treatment, names_to = "taxa", values_to = "value") %>%
dplyr::filter(str_detect(treatment, "Treatment1")) %>%
for (i in columns(df)){
)
ggplot(aes(x = treatment, y = value, color = taxa),group=treatment)
geom_point()
stat_summary(fun.y = mean,
geom = "line", width = 0.5) geom_jitter(widh=0.25)
theme_bw()}}
但它沒有用。還有其他方法嗎?
謝謝你
uj5u.com熱心網友回復:
也許這就是您要尋找的:
library(tidyverse)
df %>%
pivot_longer(-treatment) %>%
mutate(plot = ifelse(str_detect(treatment, "Original"),
"Original Sample",
"Treatment 1"),
treatment = str_extract(treatment, "\\d $")) %>%
group_by(name) %>%
group_split() %>%
map(~.x %>% ggplot(aes(x = factor(treatment), y = value, color = factor(name)))
geom_point()
facet_wrap(~plot)
labs(x = "Treatment", y = "Value", color = "Taxa")
theme_bw())
這會生成兩個圖(基于測驗資料):
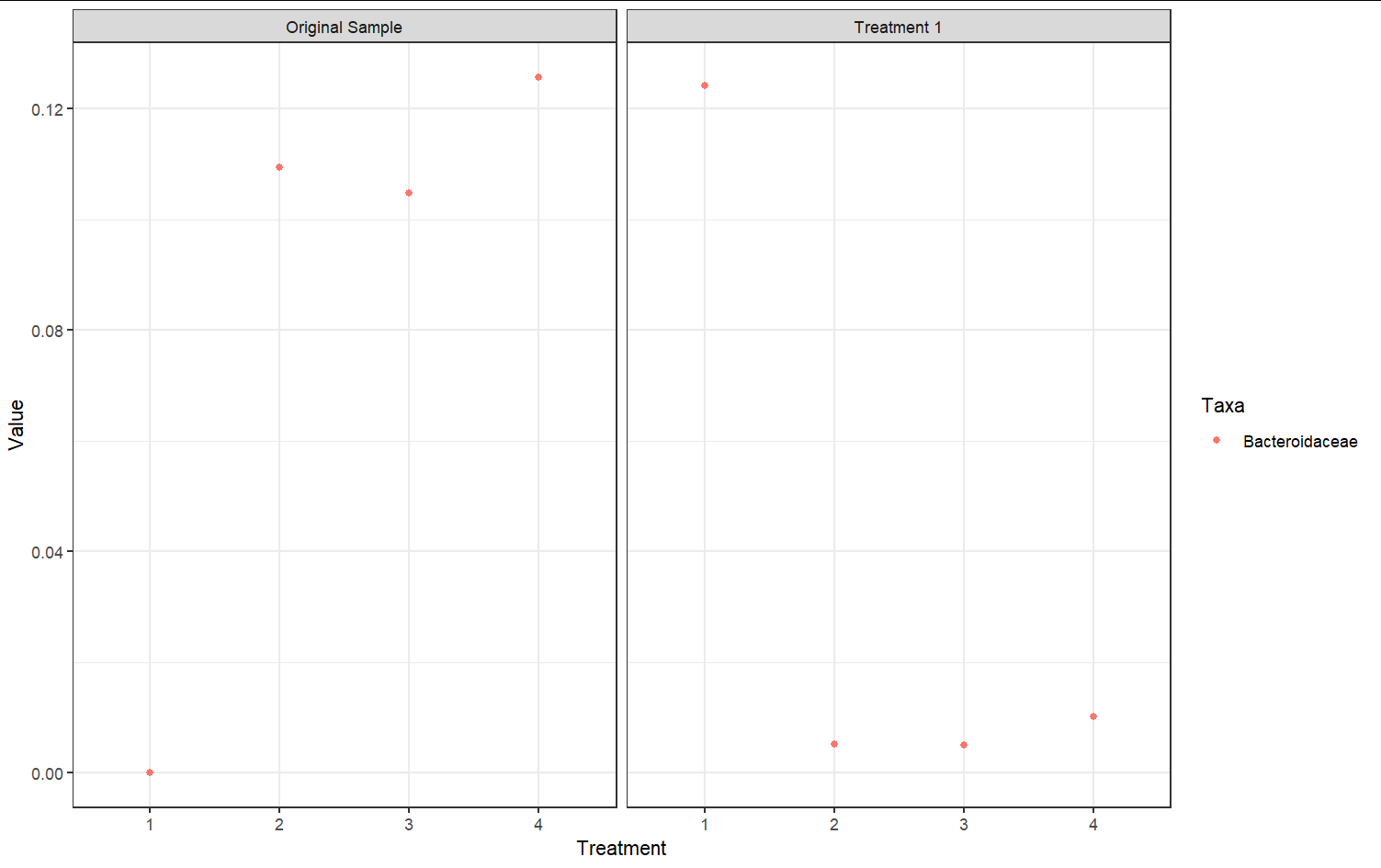
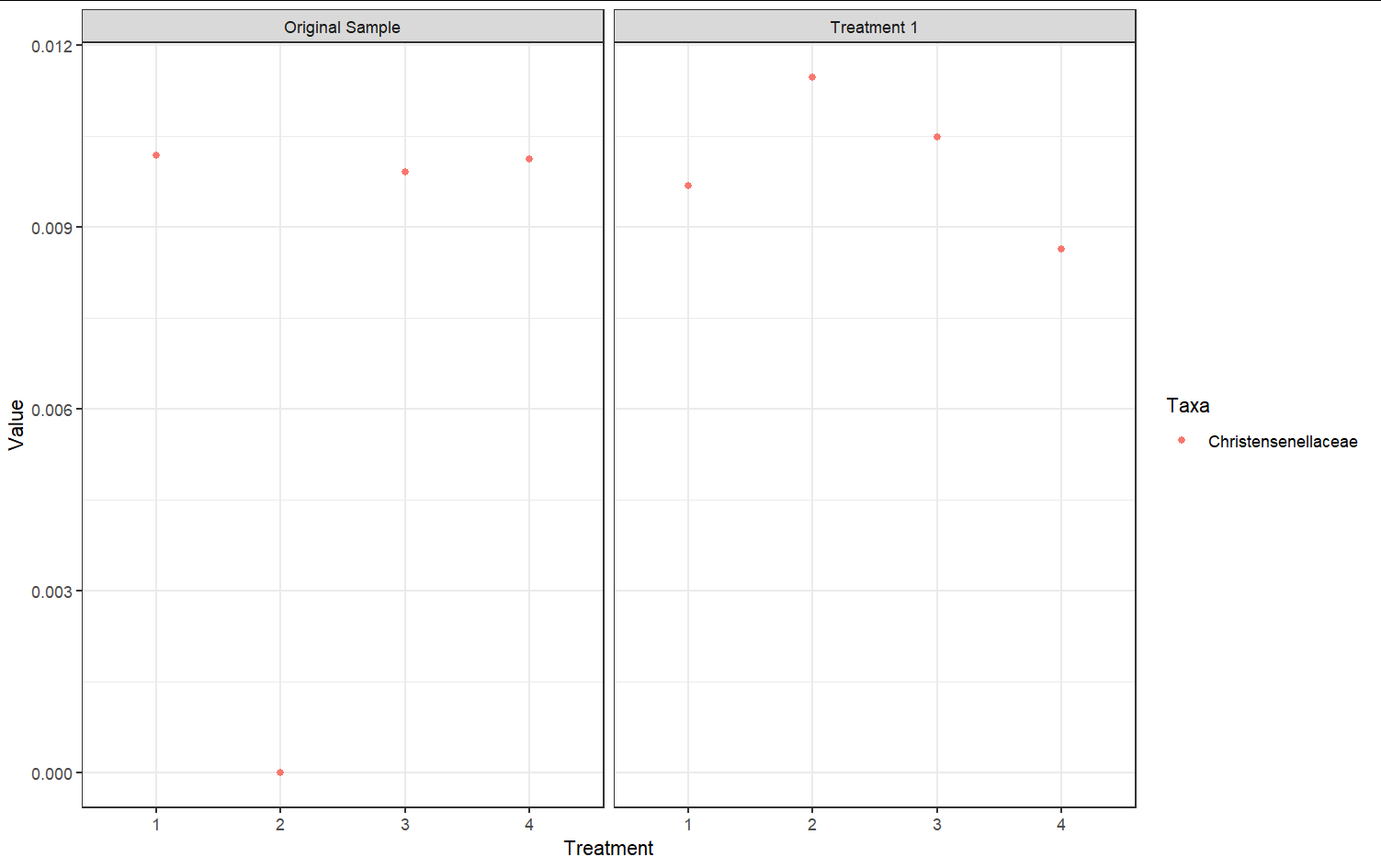
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/376443.html
上一篇:從ggtree圖中洗掉“a”