我在 uops.info 上查找了指令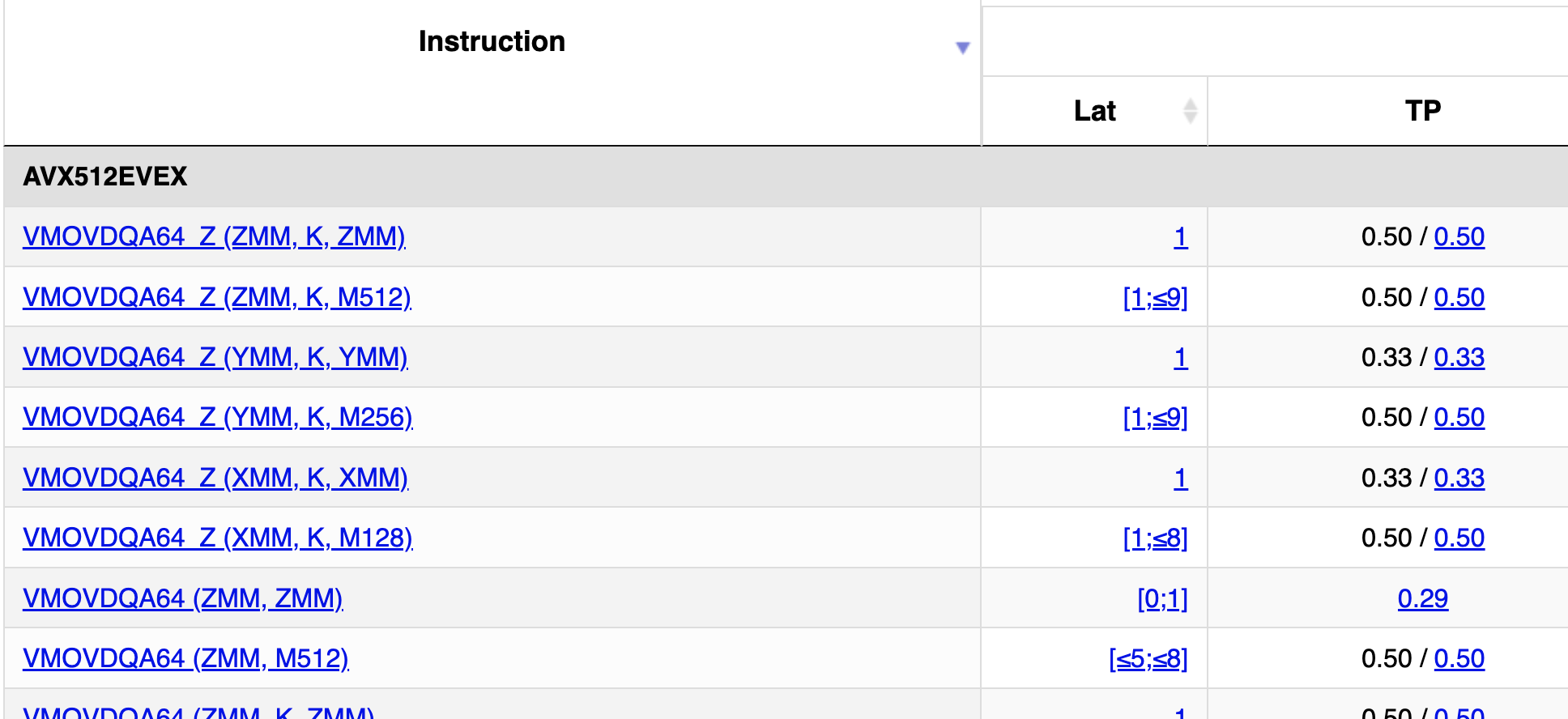
uj5u.com熱心網友回復:
如果僅運行該指令的大塊,則吞吐量是倒數的吞吐量。(或者對于諸如由于隱式暫存器輸入/輸出,尤其是 FLAGS 而無法使背靠背執行不具有資料依賴性的情況的依賴關系破壞指令)adc。div這0.5意味著它可以每 0.5 個周期運行一次,即 2 個/時鐘,正如我們所知道的具有 2 個負載埠的 CPU 所預期的那樣。
為什么有時會有兩個數字表示延遲,例如 [≤10;≤11]?
另請參閱多個值或范圍作為單個指令的延遲意味著什么?以 load ALU ALU 指令為例。(我忘記了副本有多接近,直到我寫完這個答案的其余部分才去尋找它。)
通常這表明從不同輸入到輸出的延遲可能不同。例如,合并屏蔽加載必須合并到目標中,這是一個輸入,加載地址是另一個輸入(通過整數暫存器)。最近存盤在記憶體中的資料是第三個輸入(存盤轉發延遲)。
對于向量加載使用延遲等情況,其中加載結果與地址暫存器位于不同的域中,uops.info 創建一個依賴鏈,其指令序列涉及movd或vmovq rax, xmm0將加載結果耦合回地址以進行另一個加載。很難為每個部分分別建立延遲,因此 IIRC 他們假設鏈中的每個其他指令至少為 1 個周期,并將被測指令的延遲顯示為<= N,其中 N dep 鏈的其余部分加起來為測驗代碼每次迭代的總周期。
查看其中一個結果的詳細資訊頁面,顯示用于測量它的測驗序列。表中的每個數字也是一個鏈接。這些詳細資訊頁面告訴您哪個運算元是哪個,并分解從每個輸入到每個輸出的延遲。讓我們看看他們在asmvmovdqa64中VMOVDQA64_Z (ZMM, K, M512)使用vmovdqa64 zmm0{k1}{z},ZMMWORD PTR [r14]. 列出的延遲是[1;≤9].
他們將運算元編號為
- 1(只寫):ZMM 目標。
- 2(只讀):
k0..7屏蔽暫存器 - 3(只讀):記憶體(后來分解為地址與實際記憶體內容)
周期1延遲部分是從掩碼暫存器到結果的延遲,“延遲運算元 2 → 1:1”。因此,在加載單元獲取資料之前,掩碼不必準備好。
這<=9是從地址基址或索引暫存器到準備好最終 ZMM 結果的延遲。
顯然,在存盤/重新加載情況下,存盤轉發延遲成為瓶頸,“延遲運算元 3 → 1(記憶體):≤6”。他們用這個序列進行了測驗,描述為“鏈延遲:≥6”。 vshufpd zmm已知有 1 個周期延遲,我猜他們只是將商店計算為有 1 個周期延遲?就像我說的,他們只是假設一切都是 1 個周期,即使將任何延遲都分配給商店有點可疑。
Code:
0: 62 d1 fd c9 6f 06 vmovdqa64 zmm0{k1}{z},ZMMWORD PTR [r14]
6: 62 71 fd 48 c6 e8 00 vshufpd zmm13,zmm0,zmm0,0x0
d: 62 51 95 48 c6 ed 00 vshufpd zmm13,zmm13,zmm13,0x0
14: 62 51 95 48 c6 ed 00 vshufpd zmm13,zmm13,zmm13,0x0
1b: 62 51 95 48 c6 ed 00 vshufpd zmm13,zmm13,zmm13,0x0
22: 62 51 95 48 c6 ed 00 vshufpd zmm13,zmm13,zmm13,0x0
29: 62 51 fd 48 11 2e vmovupd ZMMWORD PTR [r14],zmm13
(對于吞吐量測驗,他們多次重復該塊以創建一個展開的回圈。但對于延遲測驗,他們可能只是圍繞它包裹一個正常的回圈。nanobench 是開源的,因此您可以檢查。)
For the "Latency operand 3 → 1 (address, base register): ≤9" measurement, they say "Chain latency: ≥5". We know a vmovq r,x / vmovq x,r round-trip is more than 2 cycle latency, so the vmovq part of the chain here is probably more than a single cycle. That's why they over-estimate the load-use latency, with a conservative upper bound of 9 cycles.
0: 62 d1 fd c9 6f 06 vmovdqa64 zmm0{k1}{z},ZMMWORD PTR [r14]
6: c4 c1 f9 7e c4 vmovq r12,xmm0
b: 4d 31 e6 xor r14,r12
e: 4d 31 e6 xor r14,r12
11: 4d 31 e6 xor r14,r12
14: 4d 31 e6 xor r14,r12
they measure:
- Instructions retired: 6.0
- Core cycles: 14.0
- Reference cycles: 10.81
- UOPS_EXECUTED.THREAD: 7.0
14 cycles per iteration total, so they compute 14-5 = 9 cycles accounted for by the masked load. (Or fewer if the chain latency is actually longer than 5. The vmovq is probably actually 3 or 4 cycles, so 7 or 6 cycle SIMD load latency sound right. We know integer load-use latency is 5 cycles, and IIRC Intel's optimization manual says something about SIMD loads being 6 or 7 cycles. But this conservative upper bound of 9 is all we can really say for sure based purely on measurement, without extrapolation / guesswork.)
AVX-512 instruction naming.
"A64" is part of the AVX-512 vmovdqa64 instruction mnemonic, of course: check Intel's asm manual: https://www.felixcloutier.com/x86/movdqa:vmovdqa32:vmovdqa64. Remember that AVX-512 supports per-element merge- or zero-masking on (nearly) every instruction, so even movdqa and bitwise operations need an element size. That's also why AVX-512 bitwise booleans are vpord / q instead of just vpor (They could have used b/w/d/q naming for movdqa element sizes, but then we'd have vmovdqad or vmovdqaq, but I think we can be glad they didn't.)
Fortunately a32 vs. a64 doesn't make any performance difference, and only has any difference on the result when you're using masking, e.g. via _mm512_maskz_load_epi32( __mmask16 k, void * sa) vs. epi64 only taking a __mmask8. Or for smaller vector widths, only using fewer than 8 bits of a mask.
Zero-Masking vs. Merge Masking
op Z (ZMM, K, ZMM) vs op (ZMM, K, ZMM) is zero-masking vs. merge-masking. If you don't know how AVX-512 masking works, go read about it. e.g. Kirill Yukhin's presentation slides have an overview:
https://en.wikichip.org/w/images/d/d5/Intel_Advanced_Vector_Extensions_2015-2016_Support_in_GNU_Compiler_Collection.pdf
Reg-reg vmovdqa without masking (no k register) can be 0 latency (mov-elimination), but with masking it's always 1.
Fun fact: register-renaming for k0..k7 uses the same physical register file space as MMX/x87: https://travisdowns.github.io/blog/2020/05/26/kreg2.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/443208.html
上一篇:如何在M1Mac(ARM)上編譯x86_64asm代碼
下一篇:指令集如何標準化?