下面的代碼將 html 資料放入一個串列中。我正在嘗試data-append-csv="abbotco01"從棒球參考頁面 html 鏈接(請參閱鏈接的代碼)中抓取一個名為 data-append-csv 的特定元素(例如:):
當前代碼:
from bs4 import BeautifulSoup
from bs4 import Comment
import pandas as pd
import os.path
import requests
r = requests.get("https://www.baseball-reference.com/leagues/majors/2021-standard-batting.shtml")
soup = BeautifulSoup(r.content, "html.parser") # try lxml
[x.extract() for x in soup.find_all(string=lambda text: isinstance(text, Comment)) if 'id="div_players_standard_batting"' in x]
當前環境設定:
dependencies:
- python=3.9.7
- beautifulsoup4=4.11.1
- jupyterlab=3.3.2
- pandas=1.4.2
- pyodbc=4.0.32
最終目標:能夠擁有一個熊貓資料框,其中包含來自 html 表的 data-append-csv 的每個元素。
| 指數 | 資料附加-csv |
|---|---|
| 0 | 艾博科01 |
| 1 | abreual01 |
| 2 | abreubr01 |
等等
uj5u.com熱心網友回復:
你應該能夠得到這個表:
import requests
from bs4 import BeautifulSoup
from bs4 import Comment
import pandas as pd
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:101.0) Gecko/20100101 Firefox/101.0"
}
url = "https://www.baseball-reference.com/leagues/majors/2021-standard-batting.shtml"
with requests.Session() as s:
comments = (
BeautifulSoup(
s.get(url, headers=headers).text,
"lxml"
).find_all(string=lambda text: isinstance(text, Comment))
)
table = pd.concat(
pd.read_html(
[c for c in comments if "players_standard_batting" in c][0]
)
)
print(table)
table.to_csv("batting.csv", index=False)
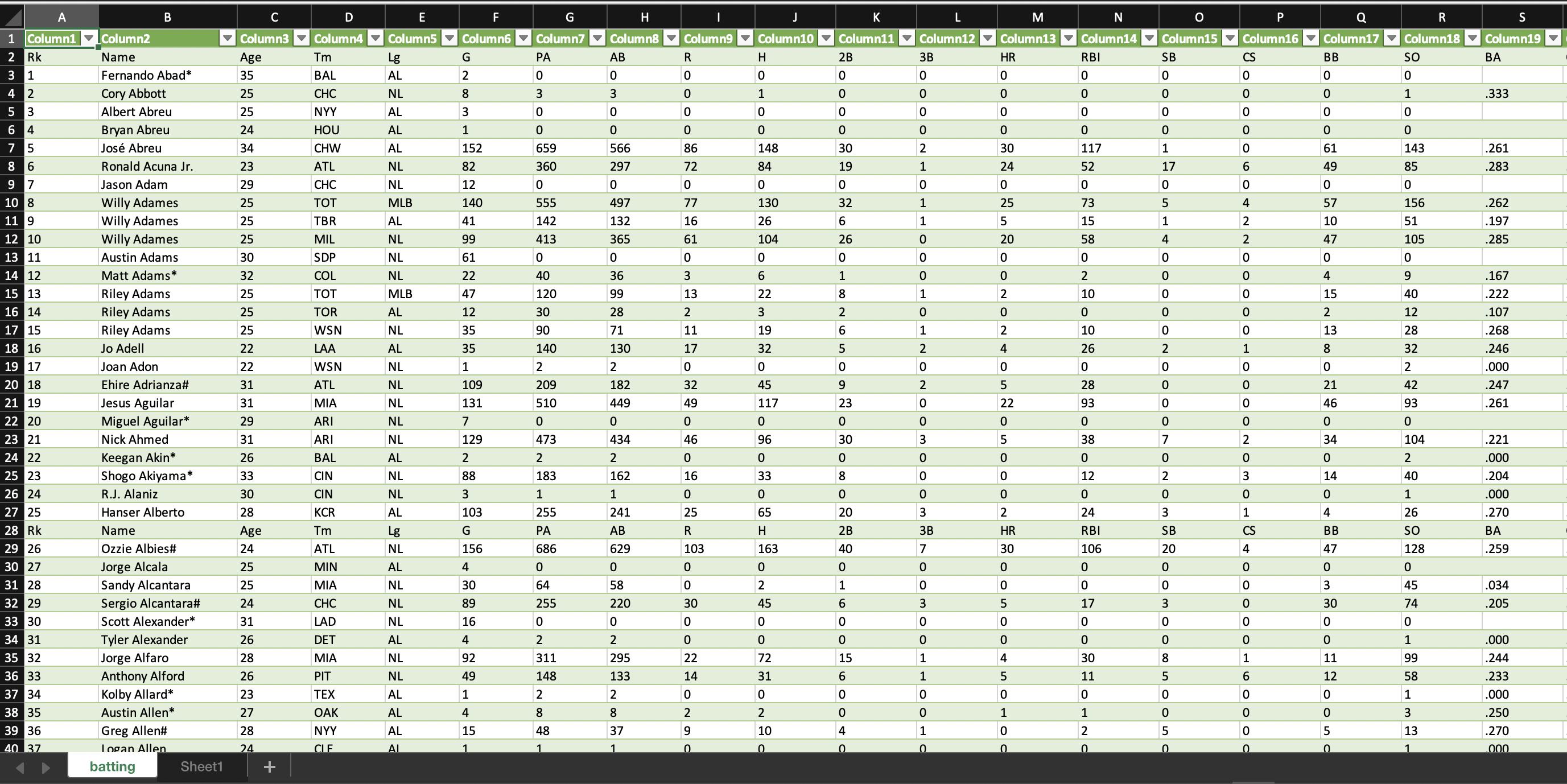
輸出:
Rk Name Age Tm Lg ... HBP SH SF IBB Pos Summary
0 1 Fernando Abad* 35 BAL AL ... 0 0 0 0 1
1 2 Cory Abbott 25 CHC NL ... 0 0 0 0 /1H
2 3 Albert Abreu 25 NYY AL ... 0 0 0 0 1
3 4 Bryan Abreu 24 HOU AL ... 0 0 0 0 1
4 5 José Abreu 34 CHW AL ... 22 0 10 3 *3D/5
... ... ... ... ... ... ... .. .. .. .. ...
1787 1720 Bruce Zimmermann* 26 BAL AL ... 0 0 0 0 1
1788 1721 Jordan Zimmermann 35 MIL NL ... 0 0 0 0 /1
1789 1722 Tyler Zuber 26 KCR AL ... 0 0 0 0 1
1790 1723 Mike Zunino 30 TBR AL ... 7 0 1 0 2/H
1791 NaN LgAvg per 600 PA NaN NaN NaN ... 7 2 4 2 NaN
[1792 rows x 30 columns]
并上傳了csv:
uj5u.com熱心網友回復:
您需要轉換您提取的 html 注釋并使用 BeautifulSoup 對其進行決議,然后使用 CSS 選擇器獲取'data-append-csv'其屬性中包含 的行。
import requests
import pandas as pd
from bs4 import Comment, BeautifulSoup
r = requests.get("https://www.baseball-reference.com/leagues/majors/2021-standard-batting.shtml")
soup = BeautifulSoup(r.content, 'html.parser')
table_txt = [x.extract() for x in soup.find_all(string=lambda text: isinstance(text, Comment)) if 'id="div_players_standard_batting"' in x][0]
table_soup = BeautifulSoup(table_txt, 'html.parser')
list_ = [{'index':index, 'data-append-csv':player['data-append-csv']} for index, player in enumerate(table_soup.select('td[data-append-csv]'), start=1)]
df = pd.DataFrame(list_)
uj5u.com熱心網友回復:
首先將字串轉換為BeautifulSoup物件和.select('[data-append-csv]'):
table = [x.extract() for x in soup.find_all(string=lambda text: isinstance(text, Comment)) if 'id="div_players_standard_batting"' in x][0]
[(a.find_previous('th').text,a.get('data-append-csv')) for a in BeautifulSoup(table).select('[data-append-csv]')]
為了確保正確連接到您的原始資料,如果存在沒有這些屬性的行并且兩個資料幀的長度將不同,請嘗試抓取排名:
(a.find_previous('th').text,a.get('data-append-csv'))
現在您可以從串列中創建資料框:
pd.DataFrame([(a.find_previous('th').text,a.get('data-append-csv')) for a in BeautifulSoup(table).select('[data-append-csv]')],columns=['Rk','data-append-csv'],dtype='object')
例子
將您的資料加入初始資料框并檢查最后一列:
from bs4 import BeautifulSoup
from bs4 import Comment
import pandas as pd
import requests
r = requests.get("https://www.baseball-reference.com/leagues/majors/2021-standard-batting.shtml")
soup = BeautifulSoup(r.text)
table = [x.extract() for x in soup.find_all(string=lambda text: isinstance(text, Comment)) if 'id="div_players_standard_batting"' in x][0]
### create and clean dataframe 1
df1 = pd.read_html(table)[0]
df1 = df1[(~df1.Rk.isna()) & (df1.Rk != 'Rk')]
df1.set_index('Rk', inplace=True)
### create and clean dataframe 2
df2 = pd.DataFrame([(a.find_previous('th').text,a.get('data-append-csv')) for a in BeautifulSoup(table).select('[data-append-csv]')],columns=['Rk','data-append-csv'],dtype='object')
df2.set_index('Rk', inplace=True)
### join both dataframe
df1.join(df2).reset_index()
輸出
| Rk | 姓名 | 年齡 | Tm值 | LG | G | 功放 | AB | R | H | 2B | 3B | 人力資源 | 打點 | 某人 | CS | BB | 所以 | 文學學士 | OBP | SLG | 運維 | 運維 | 結核病 | 國內生產總值 | 高血壓病 | 上海 | 順豐 | 國際文憑組織 | 職位摘要 | 資料附加-csv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 費爾南多·阿巴德* | 35 | 巴爾 | 鋁 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 楠 | 楠 | 楠 | 楠 | 楠 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | abadfe01 |
| 1 | 2 | 科里·雅培 | 25 | CHC | 荷蘭 | 8 | 3 | 3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.333 | 0.333 | 0.333 | 0.667 | 81 | 1 | 0 | 0 | 0 | 0 | 0 | /1H | 艾博科01 |
| 2 | 3 | 阿爾伯特·阿布雷烏 | 25 | 紐約年 | 鋁 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 楠 | 楠 | 楠 | 楠 | 楠 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | abreual01 |
| 3 | 4 | 布萊恩·阿布雷烏 | 24 | 侯 | 鋁 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 楠 | 楠 | 楠 | 楠 | 楠 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | abreubr01 |
| 4 | 5 | 何塞·阿布雷烏 | 34 | CHW | 鋁 | 152 | 659 | 566 | 86 | 148 | 30 | 2 | 30 | 117 | 1 | 0 | 61 | 143 | 0.261 | 0.351 | 0.481 | 0.831 | 124 | 272 | 28 | 22 | 0 | 10 | 3 | *3D/5 | abreujo02 |
……
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/488849.html