什么是ZooKeeper
ZooKeeper 是一個分布式的,開放原始碼的分布式應用程式協同服務,ZooKeeper 的設計目標是將那些復雜且容易出錯的分布式一致性服務封裝起來,構成一個高效可靠的原語集,并以一系列簡單易用的介面提供給用戶使用,
ZooKeeper 發展歷史
ZooKeeper 最早起源于雅虎研究院的一個研究小組,在當時,研究人員發現,在雅虎內部很多大型系統基本都需要依賴一個類似的系統來進行分布式協同,但是這些系統往往都存在分布式單點問題,
所以,雅虎的開發人員就開發了一個通用的無單點問題的分布式協調框架,這就是 ZooKeeper,ZooKeeper 之后在開源界被大量使用,下面列出了 3 個著名開源專案是如何使用 ZooKeeper:
- Hadoop:使用 ZooKeeper 做 Namenode 的高可用,
- HBase:保證集群中只有一個 master,保存 hbase:meta 表的位置,保存集群中的 RegionServer 串列,
- Kafka:集群成員管理,controller 節點選舉,
ZooKeeper 應用場景
很多分布式協調服務都可以用 ZooKeeper 來做,其中典型應用場景如下:
- 配置管理(configuration management):如果我們做普通的 Java 應用,一般配置項就是一個本地的組態檔,如果是微服務系統,各個獨立服務都要使用集中化的配置管理,這個時候就需要 ZooKeeper,
- DNS 服務
- 組成員管理(group membership):比如上面講到的 HBase 其實就是用來做集群的組成員管理,
- 各種分布式鎖
ZooKeeper 適用于存盤和協同相關的關鍵資料,不適合用于大資料量存盤,如果要存 KV 或者大量的業務資料,還是要用資料庫或者其他 NoSql 來做,
為什么 ZooKeeper 不適合大資料量存盤呢?主要有以下兩個原因:
- 設計方面:ZooKeeper 需要把所有的資料(它的 data tree)加載到記憶體中,這就決定了ZooKeeper 存盤的資料量受記憶體的限制,這一點 ZooKeeper 和 Redis 比較像,一般的資料庫系統例如 MySQL(使用 InnoDB 存盤引擎的話)可以存盤大于記憶體的資料,這是因為 InnoDB 是基于 B-Tree 的存盤引擎,B-tree 存盤引擎和 LSM 存盤引擎都可以存盤大于記憶體的資料量,
- 工程方面:ZooKeeper 的設計目標是為協同服務提供資料存盤,資料的高可用性和性能是最重要的系統指標,處理大數量不是 ZooKeeper 的首要目標,因此,ZooKeeper 不會對大數量存盤做太多工程上的優化,
ZooKeeper 服務的使用
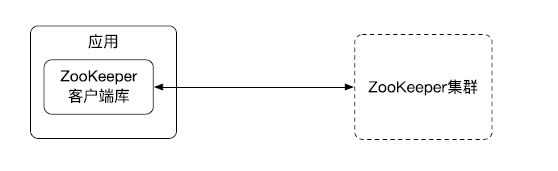
要使用 ZooKeeper 服務,首先我們的應用要引入 ZooKeeper 的客戶端庫,然后我們客戶端庫和 ZooKeeper 集群來進行網路通信來使用 ZooKeeper 的服務,本質上是 Client-Server 的架構,我們的應用作為一個客戶端來呼叫 ZooKeeper Server 端的服務,
ZooKeeper 資料模型
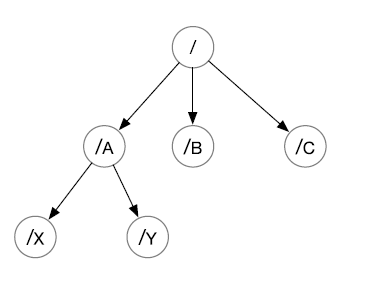
ZooKeeper 的資料模型是層次模型,層次模型常見于檔案系統,層次模型和 key-value 模型是兩種主流的資料模型,ZooKeeper 使用檔案系統模型主要基于以下兩點考慮:
- 檔案系統的樹形結構便于表達資料之間的層次關系,
- 檔案系統的樹形結構便于為不同的應用分配獨立的命名空間(namespace),
ZooKeeper 的層次模型稱作 data tree,Data tree 的每個節點叫做 znode,不同于檔案系統,每個節點都可以保存資料,每個節點都有一個版本(version),版本從 0 開始計數,
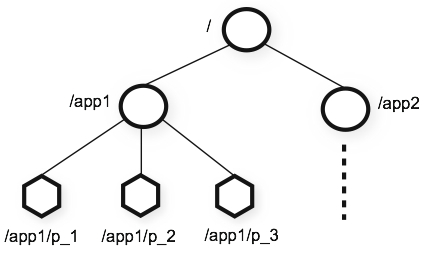
如上圖所示的 data tree 中有兩個子樹,一個用于應用 1(/app1)和另一個用于應用 2(/app2),
應用 1 的子樹實作了一個簡單的組成員協議:每個客戶端行程 pi 創建一個 znode p_i 在 /app1 下,只要 /app1/p_i 存在就代表行程 pi 在正常運行,
data tree 介面
ZooKeeper 對外提供一個用來訪問 data tree的簡化檔案系統 API:
- 使用 UNIX 風格的路徑名來定位 znode,例如 /A/X 表示 znode A 的子節點 X,
- znode 的資料只支持全量寫入和讀取,沒有像通用檔案系統那樣支持部分寫入和讀取,
- data tree 的所有 API 都是 wait-free 的,正在執行中的 API 呼叫不會影響其他 API 的完成,
- data tree 的 API都是對檔案系統的 wait-free 操作,不直接提供鎖這樣的分布式協同機制,但是 data tree 的 API 非常強大,可以用來實作多種分布式協同機制,
znode 分類
一個 znode 可以是持久性的,也可以是臨時性的,znode 節點也可以是順序性的,每一個順序性的 znode 關聯一個唯一的單調遞增整數,因此 ZooKeeper 主要有以下 4 種 znode:
- 持久性的 znode (PERSISTENT): ZooKeeper 宕機,或者 client 宕機,這個 znode 一旦創建就不會丟失,
- 臨時性的 znode (EPHEMERAL): ZooKeeper 宕機了,或者 client 在指定的 timeout 時間內沒有連接 server,都會被認為丟失,
- 持久順序性的 znode (PERSISTENT_SEQUENTIAL): znode 除了具備持久性 znode 的特點之外,znode 的名字具備順序性,
- 臨時順序性的 znode (EPHEMERAL_SEQUENTIAL): znode 除了具備臨時性 znode 的特點之外,znode 的名字具備順序性,
安裝 ZooKeeper
到 https://archive.apache.org/dist/zookeeper/stable/ 下載 ZooKeeper,目前的最新版是 3.5.6,
把 apache-zookeeper-3.5.6-bin.tar.gz 解壓到一個本地目錄 (目錄名最好不要包含空格和中文),我使用 /usr/local 目錄,
tar -zxvf apache-zookeeper-3.5.6-bin.tar.gz
把 conf 目錄下的 zoo_sample.cfg 重命名為 zoo.cfg,然后修改配置,
# 心跳檢查的時間 2秒
tickTime=2000
# 初始化時 連接到服務器端的間隔次數,總時間10*2=20秒
initLimit=10
# ZK Leader 和follower 之間通訊的次數,總時間5*2=10秒
syncLimit=5
# 存盤記憶體中資料快照的位置,如果不設定引數,更新事務日志將被存盤到默認位置,
dataDir=/data/zookeeper
# ZK 服務器端的監聽埠
clientPort=2181
配置以下環境變數 vim /etc/profile :
export ZOOKEEPER_HOME=/usr/local/apache-zookeeper-3.5.6-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
啟動 Zookeeper
再安裝配置完成后,就可以啟動 Zookeeper,使用 zkServer.sh start 啟動 ZooKeeper 服務:
[root@wupx apache-zookeeper-3.5.6-bin]# zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/apache-zookeeper-3.5.6-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
檢查 ZooKeeper 日志是否有出錯資訊:
[root@wupx apache-zookeeper-3.5.6-bin]# cd logs/
[root@wupx logs]# grep -E -i "((exception)|(error))" *
因為回傳沒有結果,說明沒有錯誤資訊,
檢查 ZooKeeper 資料檔案,這里存放的 ZooKeeper 的事務日志檔案和快照日志檔案,
[root@wupx zookeeper]# cd /data/zookeeper/
[root@wupx zookeeper]# tree
.
├── version-2
│ └── snapshot.0
└── zookeeper_server.pid
1 directory, 2 files
因為現在還沒有運行任何 ZooKeeper 命令,所以還沒有事務日志檔案,
最后會檢查 ZooKeeper 是否在 2181 埠上監聽,
netstat -an | ag 2181
執行后,我們可以看到 ZooKeeper 已經在 2181 這個埠上監聽了,
下面我們演示下如何使用 zkCli:
zkCli 使用
在執行 zkCli.sh 命令后,會出現很多訊息,這些訊息證明我們的 zkCli 和 ZooKeeper 的節點建立了有效連接,
2019-12-22 10:38:36,684 [myid:localhost:2181] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@959] - Socket connection established, initiating session, client: /127.0.0.1:54038, server: localhost/127.0.0.1:2181
使用 ls -R / 可以遞回查找 ZooKeeper 的 znode 節點,使用 create /znode_name 可以創建 znode 節點,具體演示如下:
# 使用 ls -R 可以遞回查找 ZooKeeper 的 znode 節點
[zk: localhost:2181(CONNECTED) 0] ls -R /
/
/zookeeper
/zookeeper/config
/zookeeper/quota
# 創建 znode /app1
[zk: localhost:2181(CONNECTED) 1] create /app1
Created /app1
[zk: localhost:2181(CONNECTED) 2] create /app2
Created /app2
[zk: localhost:2181(CONNECTED) 3] create /app1/p_1 1
Created /app1/p_1
[zk: localhost:2181(CONNECTED) 4] create /app1/p_2 2
Created /app1/p_2
[zk: localhost:2181(CONNECTED) 5] create /app1/p_3 3
Created /app1/p_3
[zk: localhost:2181(CONNECTED) 6] ls -R /
/
/app1
/app2
/zookeeper
/app1/p_1
/app1/p_2
/app1/p_3
/zookeeper/config
/zookeeper/quota
用 zkCli 實作鎖
分布式鎖要求如果鎖的持有者宕了,鎖可以被釋放,ZooKeeper 的 ephemeral 節點恰好具備這樣的特性,
接下來我們來演示下,需要在兩個終端上分別啟動 zkCli,
在終端 1 上:
執行 zkCli.sh,再執行 create -e /lock 命令,來建立臨時 znode,加鎖的操作其實就是建立 znode 的程序,此時第一個客戶端加鎖成功,
接下來嘗試在第二個客戶端加鎖,在終端 2 上:
執行 zkCli.sh,再執行 create -e /lock 命令,會發現提示 Node already exists: /lock,提示 znode 已存在,znode 建立失敗,因此加鎖失敗,這時候我們來監控這個 znode,使用 stat -w /lock來等待鎖被釋放,
這個時候我們退出第一個客戶端,在終端 1 上執行 quit 命令,會在客戶端 2 上收到一條 WATCHER 資訊,具體如下:
WATCHER::
WatchedEvent state:SyncConnected type:NodeDeleted path:/lock
再收到這個事件后再次在客戶端 2 上執行加鎖,執行 create -e /lock,會顯示創建 znode 成功,即加鎖成功,
總結
這篇文章主要介紹了 ZooKeeper 的安裝配置,ZooKeeper 的基本概念和 zkCli 的使用,并用 zkCli 來實作一個鎖,為后面更加深入的學習打好基礎,
參考
https://zookeeper.apache.org/doc/current/zookeeperOver.html
https://zookeeper.apache.org/doc/current/zookeeperStarted.html
《從Paxos到Zookeeper:分布式一致性原理與實踐》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/100426.html
標籤:其他
上一篇:線性代數筆記34——左右逆和偽逆