概述
- What for?主要用在某個變數(或特征)值是不是和應變數有顯著關系,換種說法就是看某個變數是否獨立
- \(X^2=\sum{\frac{(observed-expected)^2}{expected}}\)
observed表示觀測值,expected為理論值,可以看出,理論值與觀測值差別越大,\(X^2\)越大
Contingency table(聯連表)
介紹卡方檢驗之前,需要先介紹下聯連表,因為這個是所有假設檢驗的基礎,這個直接看中文翻譯容易不知所以,個人認為維基百科上解釋的比較到位:是一種矩陣形式的表格,用來表示變數或者多變數的頻率分布,
似乎意思知道了一點,我們現在舉個例子:
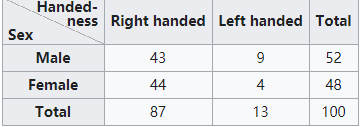
一目了然,
實作程序
然后我們看下實作程序:
1 按照假設檢驗的步驟,首先我們需要確定原假設\(H_0\)(null hypothesis):原假設是變數獨立的,實際觀測頻率和理論頻率一致,
2 其次我們根據實際觀測的聯連表,去求理論的聯連表;\(卡方統計值:X^2\),記為Statistic;自由度,
3 然后選取適合的置信度(一般為95%)同自由度一起確定臨界值Critical Value,比較卡方統計值和臨界值大小:
- If Statistic >= Critical Value: 認為變數對結果有影響,則拒絕原假設,變數不獨立
- If Statistic < Critical Value: 認為變數對結果沒有影響,接受原假設,變數獨立
python 中用scipy.stats 中chi2_contingency實作:
from scipy.stats import chi2_contingency
from scipy.stats import chi2
table = [[10,20,30],[6,9,17]]
print(table)
stat,p,dof,expected = chi2_contingency(table) # stat卡方統計值,p:P_value,dof 自由度,expected理論頻率分布
print('dof=%d'%dof)
print(expected)
prob = 0.95 # 選取95%置信度
critical = chi2.ppf(prob,dof) # 計算臨界閥值
print('probality=%.3f,critical=%.3f,stat=%.3f '%(prob,critical,stat))
if abs(stat)>=critical:
print('reject H0:Dependent')
else:
print('fail to reject H0:Independent')
顯示結果:
probality=0.950,critical=5.991,stat=0.272
fail to reject H0:Independent
除了直接比較\(X^2\)和臨界值外,
我們還可以比較p-value和顯著性水平(significance level),alpha:
- P_value<=alpha:認為有顯著性影響,則拒絕原假設,變數不獨立
- P_value>alpha:認為沒有顯著性影響,則接受原假設,變數獨立
python實作
# interpret p_value
alpha = 1-prob
print('significance=%.3f,p=%.3f'%(alpha,p))
if p<alpha:
print('reject H0:Dependent')
else:
print('fail to reject H0:Independent')
顯示結果:
significance=0.050,p=0.873
fail to reject H0:Independent
reference:
https://en.wikipedia.org/wiki/Contingency_table
https://www.jianshu.com/p/807b2c2bfd9b
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.chi2_contingency.html
https://machinelearningmastery.com/chi-squared-test-for-machine-learning/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/10789.html
標籤:其他
上一篇:Tensorflow實作對fashion mnist(衣服,褲子等圖片)資料集的softmax分類
下一篇:神經網路簡易教程