作者|Renu Khandelwal
編譯|VK
來源|Medium
在這篇文章中,我們將了解神經網路的基礎知識,
這個博客的先決條件是對機器學習的基本理解,如果你嘗試過一些機器學習演算法,那就更好了,
首先簡單介紹一下人工神經網路,也叫ANN,
很多機器學習演算法的靈感來自大自然,而最大的靈感來自我們的大腦,我們如何思考、學習和做決定,
有趣的是,當我們觸摸到熱的東西時,我們身體里的神經元將信號傳遞給大腦的,然后,大腦產生沖動,從熱的區域撤退,我們根據經驗接受了訓練,根據我們的經驗,我們開始做出更好的決定,
使用同樣的類比,當我們向神經網路發送一個輸入(觸摸熱物質),然后根據學習(先前的經驗),我們產生一個輸出(從熱區域退出),在未來,當我們得到類似的信號(接觸熱表面),我們可以預測輸出(從熱區退出),
假設我們輸入了諸如溫度、風速、能見度、濕度等資訊,以預測未來的天氣狀況——下雨、多云還是晴天,
這可以表示為如下所示,
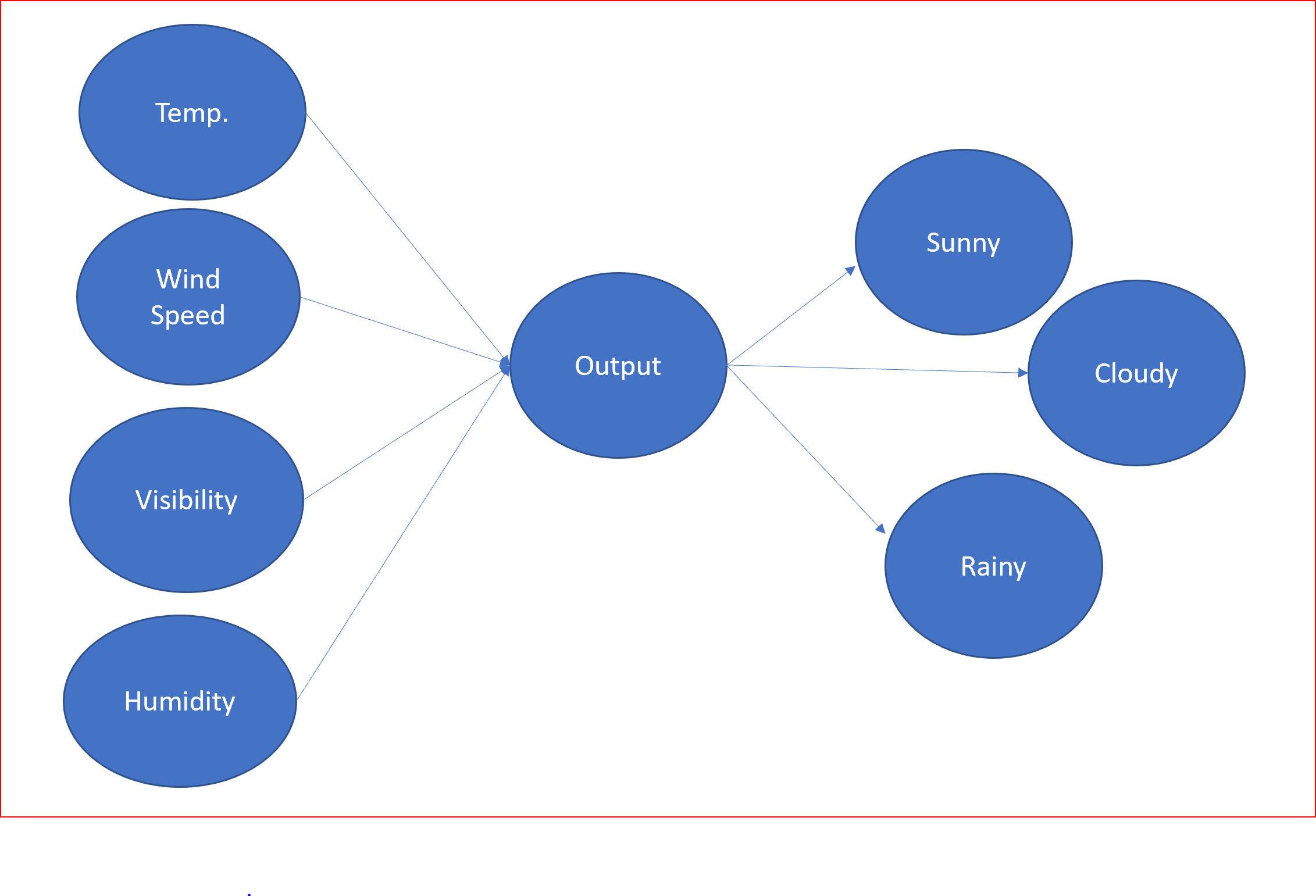
讓我們用神經網路來表示它并理解神經網路的組成部分,
神經網路接收輸入,通過使用激活函式改變狀態來轉換輸入信號,從而產生輸出,
輸出將根據接收到的輸入、強度(如果信號由權值表示)和應用于輸入引數和權值的激活而改變,
神經網路與我們神經系統中的神經元非常相似,
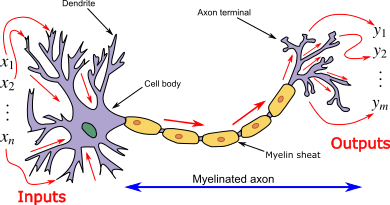
x1、x2、…xn是神經元向樹突的輸入信號,在神經元的軸突末端會發生狀態改變,產生輸出y1、y2、…yn,
以天氣預報為例,溫度、風速、能見度和濕度是輸入引數,然后,神經元通過使用激活函式對輸入施加權重來處理這些輸入,從而產生輸出,這里預測的輸出是晴天、雨天或陰天的型別,
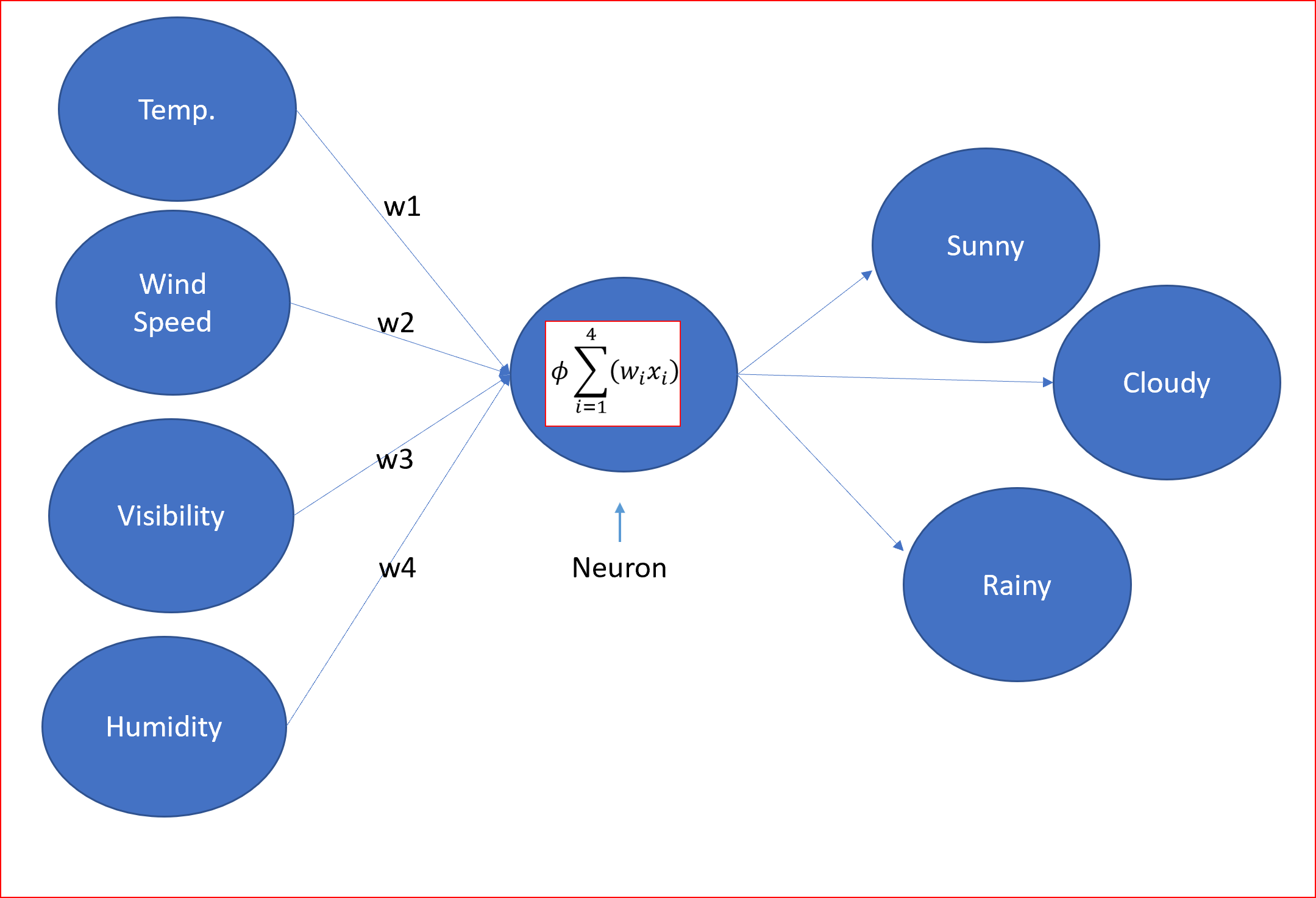
那么,神經網路的組成部分是什么呢
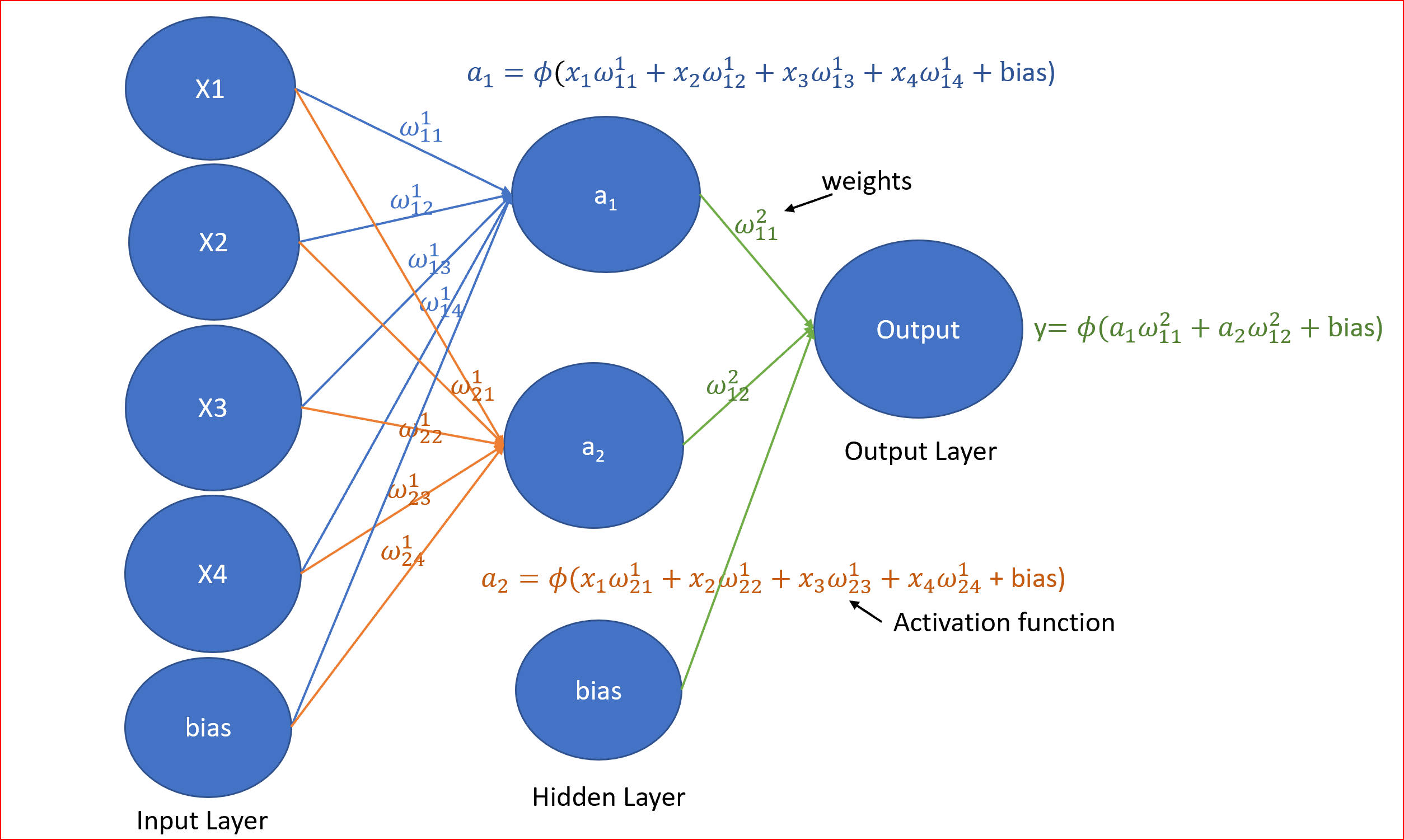
神經網路會有
- 輸入層,偏置單元為1,
- 一個或多個隱藏層,每個隱藏層將有一個偏置單元
- 輸出層
- 與每個連接相關的權重
- 將節點的輸入信號轉換為輸出信號的激活函式
輸入層、隱含層和輸出層通常稱為全連接層
這些權值是什么,什么是激活函式,這些復方程是什么?
讓我們簡化
權重是神經網路學習的方式,我們調整權重來確定信號的強度,
權重幫助我們得到不同的輸出,
例如,要預測晴天,溫度可能介于宜人到炎熱之間,晴天的能見度非常好,因此溫度和能見度的權重會更高,
濕度不會太高,否則當天會下雨,所以濕度的重量可能會小一些,也可能是負的,
風速可能與晴天無關,它的強度要么為0,要么非常小,
我們隨機初始化權重(w)與輸入(x)相乘并添加偏差項(b),所以對于隱藏層,一個版本是計算z,然后應用激活函式(?),
我們稱之為前項傳播,一個方程可以表示如下,其中\(l\)為層的編號,對于輸入層\(l=1\),
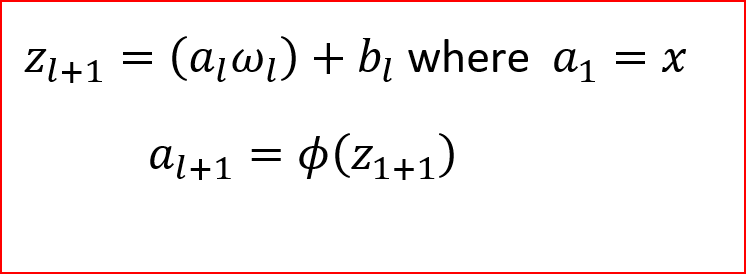
說到激活函式,我們來了解一下它們的用途
激活函式幫助我們決定是否需要激活一個神經元如果我們需要激活一個神經元那么信號的強度是多少,
激活函式是神經元通過神經網路處理和傳遞資訊的機制,
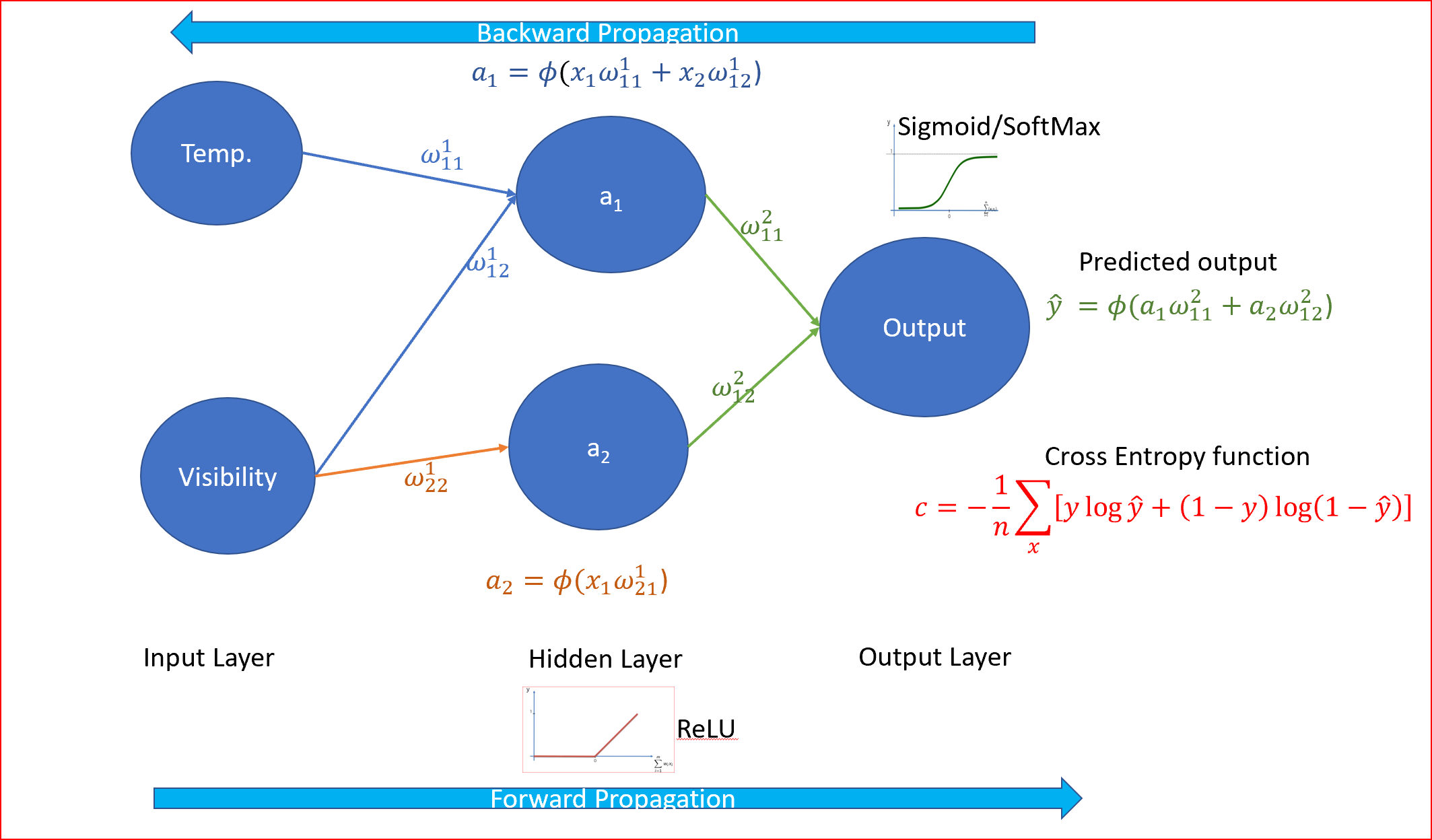
讓我們用預測天氣的樣本資料來理解神經網路
為了更好地理解,我們將進行簡化,我們只需要兩個輸入:有兩個隱藏節點的溫度和能見度,沒有偏置,我們仍然希望將天氣劃分為晴天或不晴天
溫度是華氏溫度,能見度是英里,
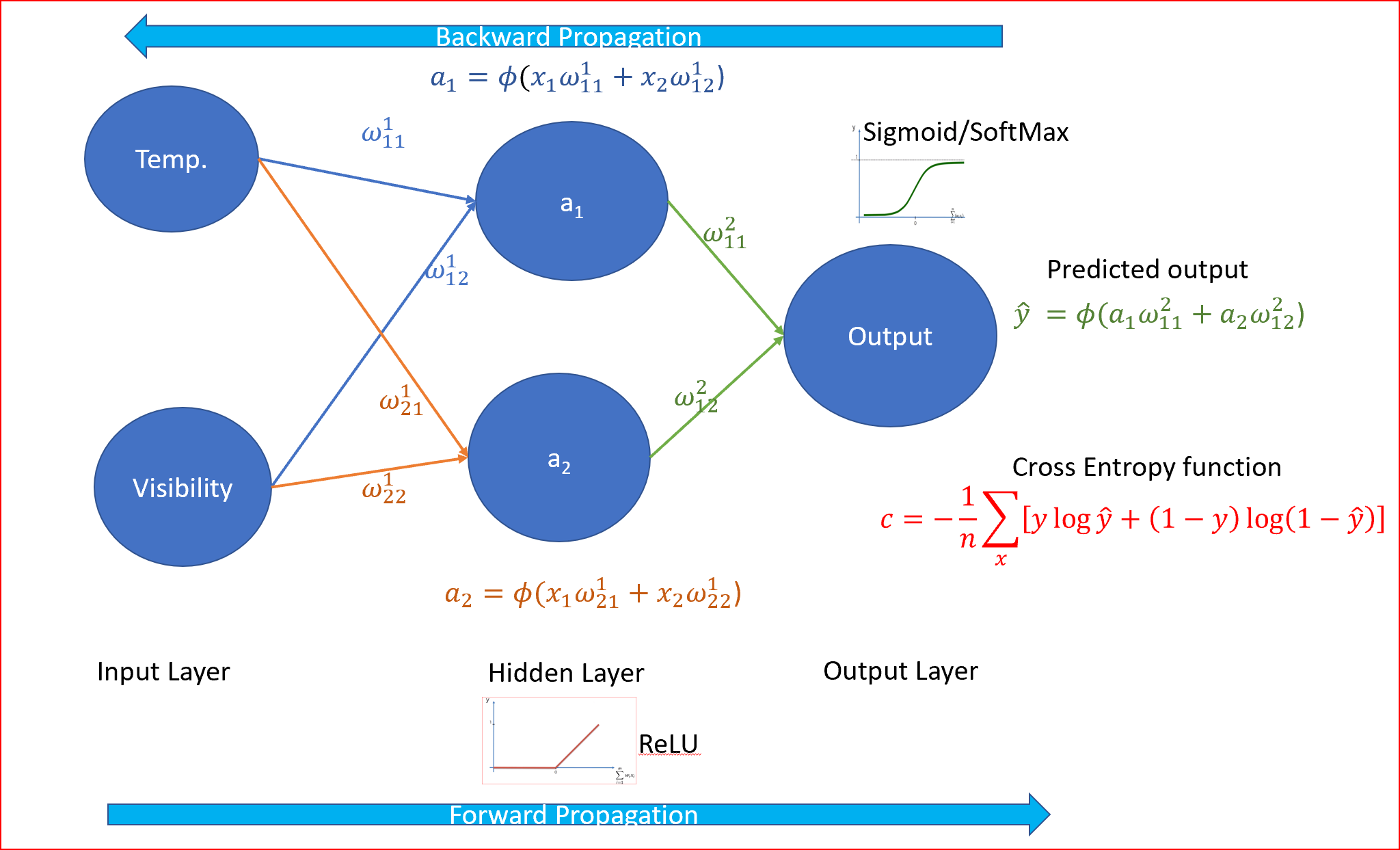
讓我們看一個溫度為50華氏度,能見度為0.01英里的資料,
步驟1:我們將權重隨機初始化為一個接近于0但不等于0的值,
步驟2:接下來,我們用我們的溫度和能見度的輸入節點獲取我們的單個資料點,并通過神經網路,
步驟3:應用從左到右的前項傳播,將權值乘以輸入值,然后使用ReLU作為激活函式,我們知道ReLU是隱層的最佳激活函式,
步驟4:現在我們預測輸出,并將預測輸出與實際輸出值進行比較,由于這是一個分類問題,我們使用交叉熵函式
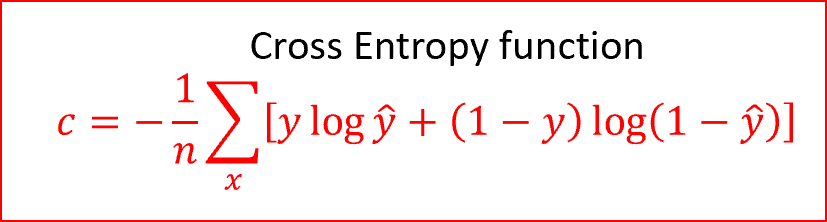
交叉熵是一個非負的代價函式,取值范圍在0和1之間
在我們的例子中,實際的輸出不是晴天,所以y的值為0,如果y?是1,那么我們把值代入成本函式,看看得到什么
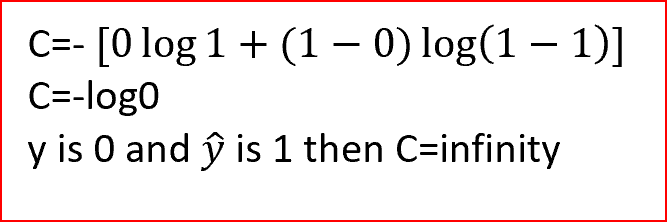
類似地,當實際輸出和預測輸出相同時,我們得到成本c=0,
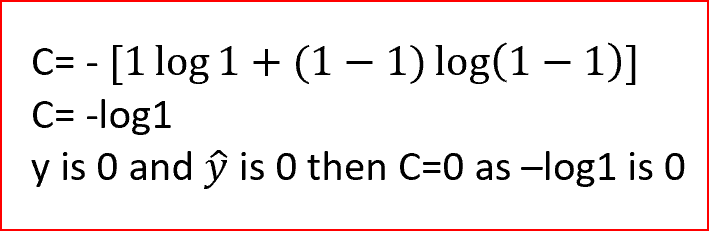
我們可以看到,對于交叉熵函式,當預測的輸出與實際輸出相匹配時,成本為零,當預測產量與實際產量不匹配時,成本是無窮大的,
步驟5:從右向左反向傳播并調整權重,權重是根據權重對錯誤負責的程度進行調整的,學習率決定了我們更新權重的多少,
反向傳播,學習率,我們將用簡單的術語來解釋一切,
反向傳播
把反向傳播看作是我們有時從父母、導師、同伴那里得到的反饋機制,反饋幫助我們成為一個更好的人,
反向傳播是一種快速的學習演算法,它告訴我們,當我們改變權重和偏差時,成本函式會發生怎樣的變化,從而改變了神經網路的行為,
不需要深入研究反向傳播的詳細數學,在反向傳播中,我們計算每個訓練實體的成本對權重的偏導數和成本對偏差的偏導數,求所有訓練樣本的偏導數的平均值,
對于我們的單個資料點,我們確定每個權值和偏差對錯誤的影響程度,基于這些權值對錯誤的影響程度,我們同時調整所有權值,
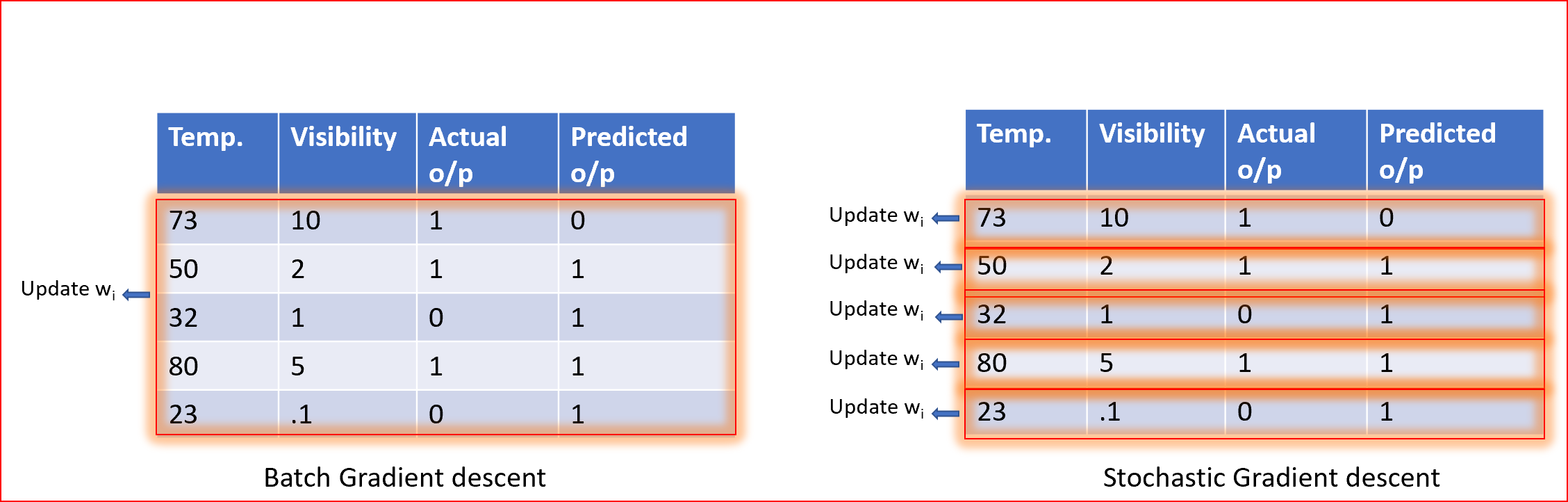
對于使用批量梯度下降(GD)的所有訓練資料,可以更新一次權值;對于使用隨機梯度下降(SGD)的每個訓練示例,可以更新一次權值,
對于不同的權重,我們使用GD或SGD重復步驟1到步驟5,
隨著權重的調整,某些節點將根據激活函式打開或關閉,
在我們的天氣例子中,溫度與預測多云的相關性較小,因為夏季的溫度可能在70度以上,而冬季仍然是多云的,或者冬季的溫度可能在30度或更低,但仍然是多云的,在這種情況下,激活函式可以決定關閉負責溫度的隱藏節點,只打開可見度節點,以預測輸出不是晴天,如下圖所示
Epoch是指用于一次學習,一次正向傳播和一次反向傳播的完整資料集,
我們可以重復也就是在多個epoch下前項和反向傳播,直到我們收斂到一個全域極小值,
什么是學習率?
學習率控制著我們應該在多大程度上根據損失梯度調整權重,
值越低,學習率越慢,收斂到全域最小,
較高的學習率值不會使梯度下降收斂
學習率是隨機初始化的,

如何確定隱藏層的數量和每個隱藏層的節點數量?
隨著隱層數目的增加和隱層神經元或節點數目的增加,神經網路的容量也隨之增大,神經元可以協作來表達不同的功能,這常常會導致過擬合,我們必須小心過擬合,
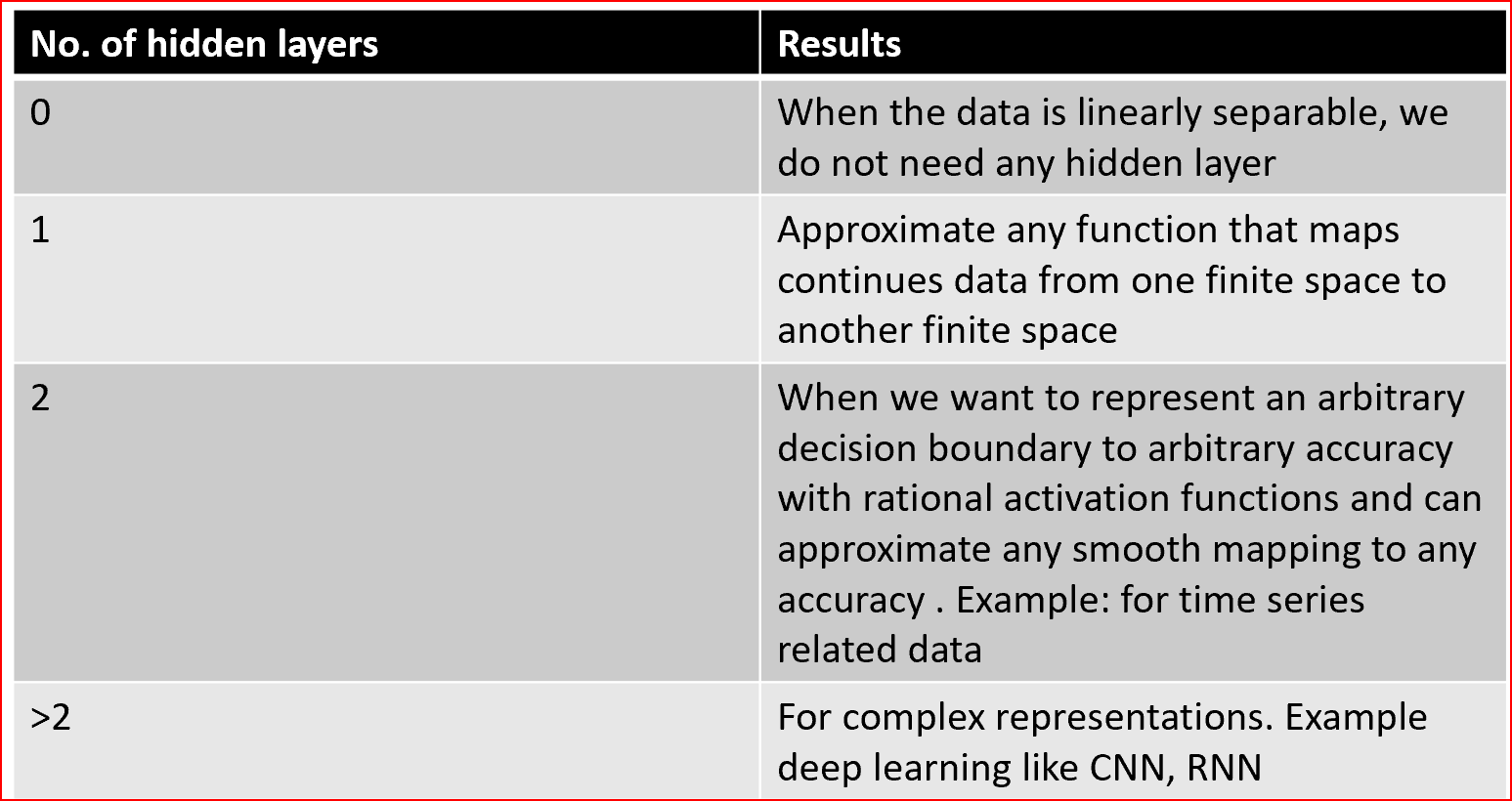
對于神經網路中隱藏層的最優數量,根據Jeff Heaton提出的下表
對于隱藏層中神經元的最佳數目,我們可以采用下面的任何一種方法
- 輸入層和輸出層神經元數目的平均值,
- 在輸入層的大小和輸出層的大小之間,
- 2/3輸入層的大小,加上輸出層的大小,
- 小于輸入層大小的兩倍,
這是一種試圖以一種簡單的方式解釋人工神經網路而不深入復雜數學的文章,
原文鏈接:https://medium.com/datadriveninvestor/neural-network-simplified-c28b6614add4
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/10797.html
標籤:其他
上一篇:卡方檢驗(Chi_square_test): 原理及python實作
下一篇:時間背景關系相關的協同過濾演算法