位元組按位反轉演算法,在有些演算法加密或者一些特殊的場合有著較為重要的應用,其速度也是一個非常關鍵的應用,比如一個byte變數a = 3,其二進制表示為00000011,進行按位反轉后的結果即為11000000,即十進制的192,還有一種常用的應用是int型變數按位反轉,其基本的原理和位元組反轉類似,本文僅以位元組反轉為例來比較這個演算法的實作,
一種最為傳統和直接的演算法實作如下:
unsigned char Reverse8U(unsigned char x)
{
x = (x & 0xaa) >> 1 | (x & 0x55) << 1;
x = (x & 0xcc) >> 2 | (x & 0x33) << 2;
x = (x & 0xf0) >> 4 | (x & 0x0f) << 4;
return x;
}
我們對大資料進行測驗,測驗的代碼如下:
void Byte_Reverse_01(unsigned char *Src, unsigned char *Dest, int Length)
{
for (int Y = 0; Y < Length; Y++)
{
Dest[Y] = Reverse8U(Src[Y]);
}
}
當Length=100000000(一億)時,上面的代碼大概用時470毫秒,我們稍微更改下函式的樣式,更改如下:
unsigned char Reverse8U(unsigned int x)
{
x = (x & 0xaa) >> 1 | (x & 0x55) << 1;
x = (x & 0xcc) >> 2 | (x & 0x33) << 2;
x = (x & 0xf0) >> 4 | (x & 0x0f) << 4;
return x;
}
還是使用Byte_Reverse_01的代碼,神奇的結果顯示速度一下子就跳到220ms,快了一倍多,其實這個看下反匯編的代碼就可以看到問題所在了,主要是前面的代碼使用了暫存器的低位,在32位的環境下不是很有效,
注意C語言中默認是傳值,所以在函式體內改變了x變數的值,并不會產生其他的什么問題,直接回傳這個x不會影響Src中的資料,
第二步改動,我們試著4路并行看看,即如下代碼:
void Byte_Reverse_02(unsigned char *Src, unsigned char *Dest, int Length)
{
int BlockSize = 4, Block = Length / BlockSize;
for (int Y = 0; Y < Block * BlockSize; Y += BlockSize)
{
Dest[Y + 0] = Reverse8U(Src[Y + 0]);
Dest[Y + 1] = Reverse8U(Src[Y + 1]);
Dest[Y + 2] = Reverse8U(Src[Y + 2]);
Dest[Y + 3] = Reverse8U(Src[Y + 3]);
}
for (int Y = Block * BlockSize; Y < Length; Y++)
{
Dest[Y] = Reverse8U(Src[Y]);
}
}
四路并行,一個是可以讓編譯器編譯出能更充分利用指令級并行的指令(即在同一個指令周期內完成2個或多個指令),二是在一定程度上減少了回圈變數計數的耗時,雖然這個對大回圈不明顯,但是在本例這種輕計算量的代碼里還是有一定作用的,
演算法的速度變為大概195ms,提速不是很明顯,
下一步改進,我們知道,現代編譯器對位元組變數的處理其實速度可能還不如處理int型別,因此,我們考慮把這個四個位元組的反轉用一個int型別的變數也一次性實作,這可以用下面的代碼實作:
unsigned int Reverse32I(unsigned int x)
{
x = (((x & 0xaaaaaaaa) >> 1) | ((x & 0x55555555) << 1));
x = (((x & 0xcccccccc) >> 2) | ((x & 0x33333333) << 2));
x = (((x & 0xf0f0f0f0) >> 4) | ((x & 0x0f0f0f0f) << 4));
return x;
}
注意這里起名叫Reverse32I其實不是很適合,畢竟他不是反轉32位數,但你知道就可以了,
測驗代碼如下:
void Byte_Reverse_03(unsigned char *Src, unsigned char *Dest, int Length)
{
int BlockSize = 4, Block = Length / BlockSize;
for (int Y = 0; Y < Block * BlockSize; Y += BlockSize)
{
*((unsigned int *)(Dest + Y)) = Reverse32I(*((unsigned int *)(Src + Y)));
}
for (int Y = Block * BlockSize; Y < Length; Y++)
{
Dest[Y] = Reverse8U(Src[Y]);
}
}
測驗結果顯示執行耗時為65ms,靠,速度提高了三四倍,
接下來,我們考慮另外的實作方法,因為byte只有256個不同的數,因此,我們也可以直接用查表的方式來實作,這個表可以實時計算(耗時可以忽視),也可以靜態給出,前人已經給給出了,這里我直接貼出來:
static const unsigned char BitReverseTable256[] =
{
0x00, 0x80, 0x40, 0xC0, 0x20, 0xA0, 0x60, 0xE0, 0x10, 0x90, 0x50, 0xD0, 0x30, 0xB0, 0x70, 0xF0,
0x08, 0x88, 0x48, 0xC8, 0x28, 0xA8, 0x68, 0xE8, 0x18, 0x98, 0x58, 0xD8, 0x38, 0xB8, 0x78, 0xF8,
0x04, 0x84, 0x44, 0xC4, 0x24, 0xA4, 0x64, 0xE4, 0x14, 0x94, 0x54, 0xD4, 0x34, 0xB4, 0x74, 0xF4,
0x0C, 0x8C, 0x4C, 0xCC, 0x2C, 0xAC, 0x6C, 0xEC, 0x1C, 0x9C, 0x5C, 0xDC, 0x3C, 0xBC, 0x7C, 0xFC,
0x02, 0x82, 0x42, 0xC2, 0x22, 0xA2, 0x62, 0xE2, 0x12, 0x92, 0x52, 0xD2, 0x32, 0xB2, 0x72, 0xF2,
0x0A, 0x8A, 0x4A, 0xCA, 0x2A, 0xAA, 0x6A, 0xEA, 0x1A, 0x9A, 0x5A, 0xDA, 0x3A, 0xBA, 0x7A, 0xFA,
0x06, 0x86, 0x46, 0xC6, 0x26, 0xA6, 0x66, 0xE6, 0x16, 0x96, 0x56, 0xD6, 0x36, 0xB6, 0x76, 0xF6,
0x0E, 0x8E, 0x4E, 0xCE, 0x2E, 0xAE, 0x6E, 0xEE, 0x1E, 0x9E, 0x5E, 0xDE, 0x3E, 0xBE, 0x7E, 0xFE,
0x01, 0x81, 0x41, 0xC1, 0x21, 0xA1, 0x61, 0xE1, 0x11, 0x91, 0x51, 0xD1, 0x31, 0xB1, 0x71, 0xF1,
0x09, 0x89, 0x49, 0xC9, 0x29, 0xA9, 0x69, 0xE9, 0x19, 0x99, 0x59, 0xD9, 0x39, 0xB9, 0x79, 0xF9,
0x05, 0x85, 0x45, 0xC5, 0x25, 0xA5, 0x65, 0xE5, 0x15, 0x95, 0x55, 0xD5, 0x35, 0xB5, 0x75, 0xF5,
0x0D, 0x8D, 0x4D, 0xCD, 0x2D, 0xAD, 0x6D, 0xED, 0x1D, 0x9D, 0x5D, 0xDD, 0x3D, 0xBD, 0x7D, 0xFD,
0x03, 0x83, 0x43, 0xC3, 0x23, 0xA3, 0x63, 0xE3, 0x13, 0x93, 0x53, 0xD3, 0x33, 0xB3, 0x73, 0xF3,
0x0B, 0x8B, 0x4B, 0xCB, 0x2B, 0xAB, 0x6B, 0xEB, 0x1B, 0x9B, 0x5B, 0xDB, 0x3B, 0xBB, 0x7B, 0xFB,
0x07, 0x87, 0x47, 0xC7, 0x27, 0xA7, 0x67, 0xE7, 0x17, 0x97, 0x57, 0xD7, 0x37, 0xB7, 0x77, 0xF7,
0x0F, 0x8F, 0x4F, 0xCF, 0x2F, 0xAF, 0x6F, 0xEF, 0x1F, 0x9F, 0x5F, 0xDF, 0x3F, 0xBF, 0x7F, 0xFF
};
最直接的查找代碼如下:
void Byte_Reverse_04(unsigned char *Src, unsigned char *Dest, int Length)
{
for (int Y = 0; Y < Length; Y++)
{
Dest[Y] = BitReverseTable256[Src[Y]];
}
}
測驗耗時:70ms,速度也是不錯的,
如果分四路并行測驗,代碼如下:
void Byte_Reverse_05(unsigned char *Src, unsigned char *Dest, int Length)
{
int BlockSize = 4, Block = Length / BlockSize;
for (int Y = 0; Y < Block * BlockSize; Y += BlockSize)
{
Dest[Y + 0] = BitReverseTable256[Src[Y + 0]];
Dest[Y + 1] = BitReverseTable256[Src[Y + 1]];
Dest[Y + 2] = BitReverseTable256[Src[Y + 2]];
Dest[Y + 3] = BitReverseTable256[Src[Y + 3]];
}
for (int Y = Block * BlockSize; Y < Length; Y++)
{
Dest[Y] = BitReverseTable256[Src[Y]];
}
}
測驗耗時:40ms,速度又有了大幅度的提高了,同時和前面的Byte_Reverse_02相比,明天提速比例完全不在一個檔次,這是因此這里代碼非常簡單,就是一個查找表,他很容易實作指令級的并行,
還有一種方式,其實也類似于四路并行,如下所示:
void Byte_Reverse_06(unsigned char *Src, unsigned char *Dest, int Length)
{
int BlockSize = 4, Block = Length / BlockSize;
for (int Y = 0; Y < Block * BlockSize; Y += BlockSize)
{
unsigned int Value = https://www.cnblogs.com/Imageshop/p/*((unsigned int *)(Src + Y));
*((unsigned int *)(Dest + Y)) = (BitReverseTable256[Value & 0xff]) |
(BitReverseTable256[(Value >> 8) & 0xff] << 8) |
(BitReverseTable256[(Value >> 16) & 0xff] << 16) |
(BitReverseTable256[(Value >> 24) & 0xff] << 24);
}
for (int Y = Block * BlockSize; Y < Length; Y++)
{
Dest[Y] = BitReverseTable256[Src[Y]];
}
}
本來想利用int比byte處理起來快的特性,但是這樣處理有計算量增大了,結果耗時50ms,比四路并行反而慢了一點,
在 c語言實作bit反轉的最佳演算法-從msb-lsb到lsb-msb一文的回復一欄中,我無意看到ytfhwfnh的回復如下:
我覺得查表法不錯,但是表太大了,建議改為半位元組為單元的查表,這樣,只需要16個uchar的表就夠了,查表,再翻轉高低半位元組,再翻轉一個int32的4個位元組,就能搞定了,
他這個話的后續的再翻轉一個int32的4個位元組在本例中正好不要,他提供的示例代碼如下:
LOCAL u_long ucharBitsListR2Ulong(u_char* ucBits)
{
const static u_char BitReverseTable16[] =
{
0x0, 0x8, 0x4, 0xC, 0x2, 0xA, 0x6, 0xE,
0x1, 0x9, 0x5, 0xD, 0x3, 0xB, 0x7, 0xF
};
u_long ret = 0;
int i = 0;
for (; i < 4; i++)
{
/* 獲取當前位元組,高4位 */
u_char ucTmp = (ucBits[i] >> 4) & 0x0F;
/* 查表得反轉的半位元組,并轉為u_long */
u_long ulTmp = BitReverseTable16[ucTmp];
/* 存入ret對應位置的低4位 */
ret [表情]= ulTmp << (i * 8);
/* 獲取當前位元組,低4位 */
ucTmp = ucBits[i] & 0x0F;
/* 查表得反轉的半位元組,并轉為u_long */
ulTmp = BitReverseTable16[ucTmp];
/* 存入ret對應位置的高4位 */
ret [表情]= ulTmp << (i * 8 + 4);
}
return ret;
}
這個[表情]是 CSDN的特色,實際上他應該是| 運算子,
我們把他這個函式直接展開嵌入到回圈中,形成了如下的利用16位進行查表的演算法:
void Byte_Reverse_08(unsigned char *Src, unsigned char *Dest, int Length)
{
int BlockSize = 4, Block = Length / BlockSize;
for (int Y = 0; Y < Block * BlockSize; Y += BlockSize)
{
unsigned int Value = https://www.cnblogs.com/Imageshop/p/*((unsigned int *)(Src + Y));
*((unsigned int *)(Dest + Y)) =
(BitReverseTable16[(Src[Y + 0] >> 4) & 0x0F]) | (BitReverseTable16[Src[Y + 0] & 0x0F] << 4) |
(BitReverseTable16[(Src[Y + 1] >> 4) & 0x0F] << 8) | (BitReverseTable16[Src[Y + 1] & 0x0F] << 12) |
(BitReverseTable16[(Src[Y + 2] >> 4) & 0x0F] << 16) | (BitReverseTable16[Src[Y + 2] & 0x0F] << 20) |
(BitReverseTable16[(Src[Y + 3] >> 4) & 0x0F] << 24) | (BitReverseTable16[Src[Y + 3] & 0x0F] << 28);
}
for (int Y = Block * BlockSize; Y < Length; Y++)
{
Dest[Y] = Reverse8U(Src[Y]);
}
}
很可惜,我沒有得到我想要的效果,這段代碼結果耗時110ms,比256個元素的查找表慢,
那同樣,我們用四路并行實作他們試下,即如下代碼:
void Byte_Reverse_08(unsigned char *Src, unsigned char *Dest, int Length)
{
int BlockSize = 4, Block = Length / BlockSize;
for (int Y = 0; Y < Block * BlockSize; Y += BlockSize)
{
Dest[Y + 0] = (BitReverseTable16[(Src[Y + 0] >> 4) & 0x0F]) | (BitReverseTable16[Src[Y + 0] & 0x0F] << 4);
Dest[Y + 1] = (BitReverseTable16[(Src[Y + 1] >> 4) & 0x0F]) | (BitReverseTable16[Src[Y + 1] & 0x0F] << 4);
Dest[Y + 2] = (BitReverseTable16[(Src[Y + 2] >> 4) & 0x0F]) | (BitReverseTable16[Src[Y + 2] & 0x0F] << 4);
Dest[Y + 3] = (BitReverseTable16[(Src[Y + 3] >> 4) & 0x0F]) | (BitReverseTable16[Src[Y + 3] & 0x0F] << 4);
}
for (int Y = Block * BlockSize; Y < Length; Y++)
{
Dest[Y] = Reverse8U(Src[Y]);
}
}
同樣道理,這樣又要快一點了,能做到75ms,但比256個查找表的多路并行還是要慢的,
這是可以理解的,一般來說,查找表越少,同樣的查找次數耗時則越小,這主要得益于小的查找表有著較小的cache miss,但是我們注意到,上述16個元素的查找表的查找次數多了一倍,而且也多了很多移位和或運算,因此,總的耗時并沒有減少,
但是,到這里,就出現了一個令我非常感興趣的話題了,我一直在思考如何利用SIMD指令實作快速的查表問題,后來得到的結論是,這個基本上不可行,對應SSE,除非幾個特殊的表,一個情況就是,這個查找表只有16個元素,而且表的型別是byte型別,這個時候,我們就可以利用_mm_shuffle_epi8指令進行快速的shuffle,此時的效果就比直接查表要快了很多了,
那么仔細的觀察上面的代碼,除了查表之外,其他的計算太容易用SSE相應的指令實作了,或計算,并計算,注意移位計算SSE指令的_mm_srli_si128 、_mm_slli_si128并不是按位移位的,他是按照位元組進行的移位,這個時候我們可借用_mm_srli_epi16或者_mm_srli_epi32來實作相同的功能,
此時,可編制如下的SSE代碼實作相同的功能:
void Byte_Reverse_09(unsigned char *Src, unsigned char *Dest, int Length)
{
int BlockSize = 16, Block = Length / BlockSize;
__m128i Table = _mm_loadu_si128((__m128i *)BitReverseTable16);
__m128i Mask = _mm_set1_epi8(0x0F);
for (int Y = 0; Y < Block * BlockSize; Y += BlockSize)
{
__m128i SrcV = _mm_loadu_si128((__m128i *)(Src + Y));
__m128i High = _mm_and_si128(_mm_srli_epi16(SrcV, 4), Mask); // 高四位
__m128i Low = _mm_and_si128(SrcV, Mask); // 低四位
High = _mm_shuffle_epi8(Table, High); // 查找表
Low = _mm_shuffle_epi8(Table, Low);
_mm_storeu_si128((__m128i *)(Dest + Y), _mm_or_si128(High, _mm_slli_epi16(Low, 4))); // 合并保存
}
for (int Y = Block * BlockSize; Y < Length; Y++)
{
Dest[Y] = Reverse8U(Src[Y]);
}
}
此時函式的執行速度提高到了25ms左右,并且我們看到,這里其實是實質上就沒有任何的查表作業了,也不存在所謂的cache miss的,
在此基礎上,我們可以將這個函式擴展到使用AVX優化,AVX支持一次性處理32個位元組的資料,比SSE還要擴展一倍,并且現在大部分CPU已經支持AVX2了,嘗試一下:
void Byte_Reverse_10(unsigned char *Src, unsigned char *Dest, int Length)
{
int BlockSize = 32, Block = Length / BlockSize;
__m256i Table = _mm256_loadu_si256((__m256i *)BitReverseTable32);
__m256i Mask = _mm256_set1_epi8(0x0F);
for (int Y = 0; Y < Block * BlockSize; Y += BlockSize)
{
__m256i SrcV = _mm256_loadu_si256((__m256i *)(Src + Y));
__m256i High = _mm256_and_si256(_mm256_srli_epi16(SrcV, 4), Mask); // 高四位
__m256i Low = _mm256_and_si256(SrcV, Mask); // 低四位
High = _mm256_shuffle_epi8(Table, High); // 查找表
Low = _mm256_shuffle_epi8(Table, Low);
_mm256_storeu_si256((__m256i *)(Dest + Y), _mm256_or_si256(High, _mm256_slli_epi16(Low, 4))); // 合并保存
}
for (int Y = Block * BlockSize; Y < Length; Y++)
{
Dest[Y] = Reverse8U(Src[Y]);
}
}
速度也基本在25ms左右波動,區別和SSE不是很多大,
最后,我們在回傳到最開始的unsigned char Reverse8U(unsigned char x)函式,我們發現,這個函式內部的演算法天然的就支持SSE并行化處理,我們可以稍微修改下語法就可以得到對應的SSE版本函式,如下所示:
void Byte_Reverse_11(unsigned char *Src, unsigned char *Dest, int Length)
{
int BlockSize = 16, Block = Length / BlockSize;
for (int Y = 0; Y < Block * BlockSize; Y += BlockSize)
{
__m128i V = _mm_loadu_si128((__m128i *)(Src + Y));
V = _mm_or_si128(_mm_srli_epi16(_mm_and_si128(V, _mm_set1_epi8(0xaa)), 1), _mm_slli_epi16(_mm_and_si128(V, _mm_set1_epi8(0x55)), 1));
V = _mm_or_si128(_mm_srli_epi16(_mm_and_si128(V, _mm_set1_epi8(0xcc)), 2), _mm_slli_epi16(_mm_and_si128(V, _mm_set1_epi8(0x33)), 2));
V = _mm_or_si128(_mm_srli_epi16(_mm_and_si128(V, _mm_set1_epi8(0xf0)), 4), _mm_slli_epi16(_mm_and_si128(V, _mm_set1_epi8(0x0f)), 4));
_mm_storeu_si128((__m128i *)(Dest + Y), V);
}
for (int Y = Block * BlockSize; Y < Length; Y++)
{
Dest[Y] = Reverse8U(Src[Y]);
}
}
這個版本也是相當的快的,大約用時28ms左右,而且不占用任何其他記憶體,
當然,以上的時間比較只基于本人的一臺電腦,在不同的CPU系列當中,各演算法之間的耗時比例是不太相同的,有些甚至出現了相反的現象,總的來說,用多路并行256個元素的查找表方式是最為穩妥和夸平臺的,如果在PC段,則可以考慮時候用SIMD優化的版本,
各版本的總和速度比較如下:
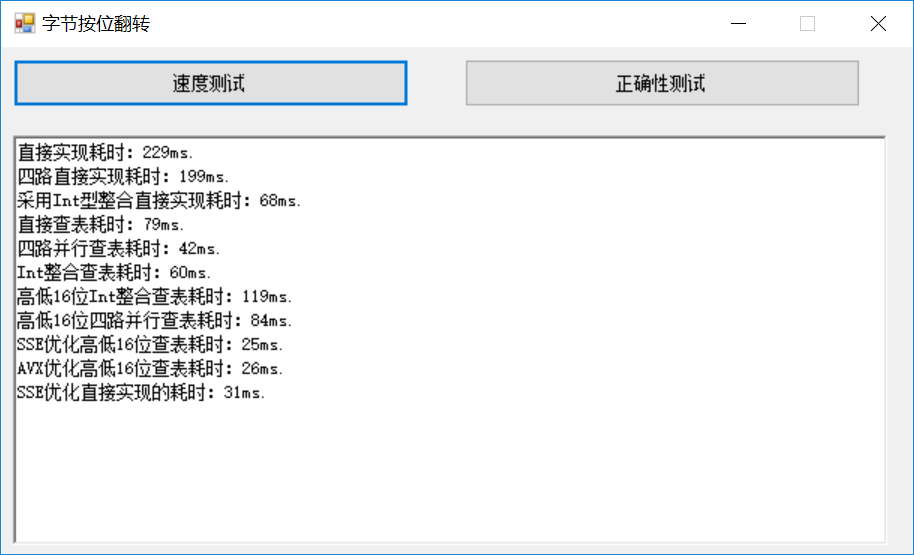
附本文完整測驗代碼供有興趣的朋友研究:https://files.cnblogs.com/files/Imageshop/Byte_Reverse.rar
既然是針對位元組的資料處理,自然而然我們想到可以直接把他應用在影像上,比如對lena影像,應用這個演算法得到如下效果:


后面一幅圖你還能看出他是lena嗎,但是確實可以對后面的圖再次利用本演算法,恢復出完整的lena圖,這也可以算是最簡答的影像加密演算法之一吧,
寫博不易,歡迎土豪打賞贊助,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/112996.html
標籤:其他
下一篇:PAT乙級1001