在計算機里,所有的資料結構本質上可以歸為兩類:陣列和鏈表
陣列的記憶體模型
1.一維陣列
什么是陣列?
在計算機科學中,陣列可以被定義為是一組被保存在存盤連續空間中,并且具有相同型別的資料元素的集合,而陣列中的每一個元素都可以通過索引來進行訪問,
例:以java語言中一個例子說明一下陣列的記憶體模型,當定義了一個擁有5個元素的int陣列后,看看記憶體是長什么樣子?
int[] data = https://www.cnblogs.com/gxkeven/p/new int[5];
通過上面的聲音,計算機會在記憶體中分配一段連續的空間給這個data陣列,現在假設在一個32位上的機器上運行這段程式,java的int型別的資料占據了4個位元組的空間,同時也假設計算機分配的地址是從0X80000000開始的,整個data陣列在計算機記憶體中分配的模型如下圖所示:
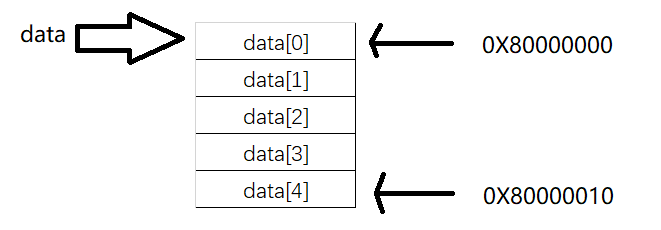
這種分配連續空間的記憶體模型同時也揭示了陣列在資料結構中的另外一個特性,即隨機訪問(Random Access),隨機訪問這個概念在計算機科學中被定義為:可以用同等的時間訪問到一組資料中的任意一個元素,這個特性除了和連續的記憶體空間模型有關以外,其實也和陣列如何通過索引訪問到特定的元素有關,
在計算機中,為什么在訪問陣列中的第一個元素時,程式一般都是表達成以下這樣的:
data[0]
也就是說,陣列的第一個元素是通過索引“0”來進行訪問的,第二個元素是通過索引“1”來進行訪問的,......,這種從0開始進行索引的編碼的方式被稱為“Zero-based Indexing”,當然了在計算機世界中,也存在著其他的編碼方式,像Visual Basic中的某些函式索引采用1-based Indexing的,也就是說第一個元素是通過索引“1”來獲取的,像這種方式就不多說了,等以后有時間慢慢研究,
為什么陣列的第一個元素要用過索引“0”來進行訪問呢?原因就在于獲取陣列元素的方式是按以下的公式來進行獲取的:
base_address + index(索引) * data_size(資料型別大小)
索引在這里可以看做是一個偏移量(Offset),還是以上面的例子來進行說明:
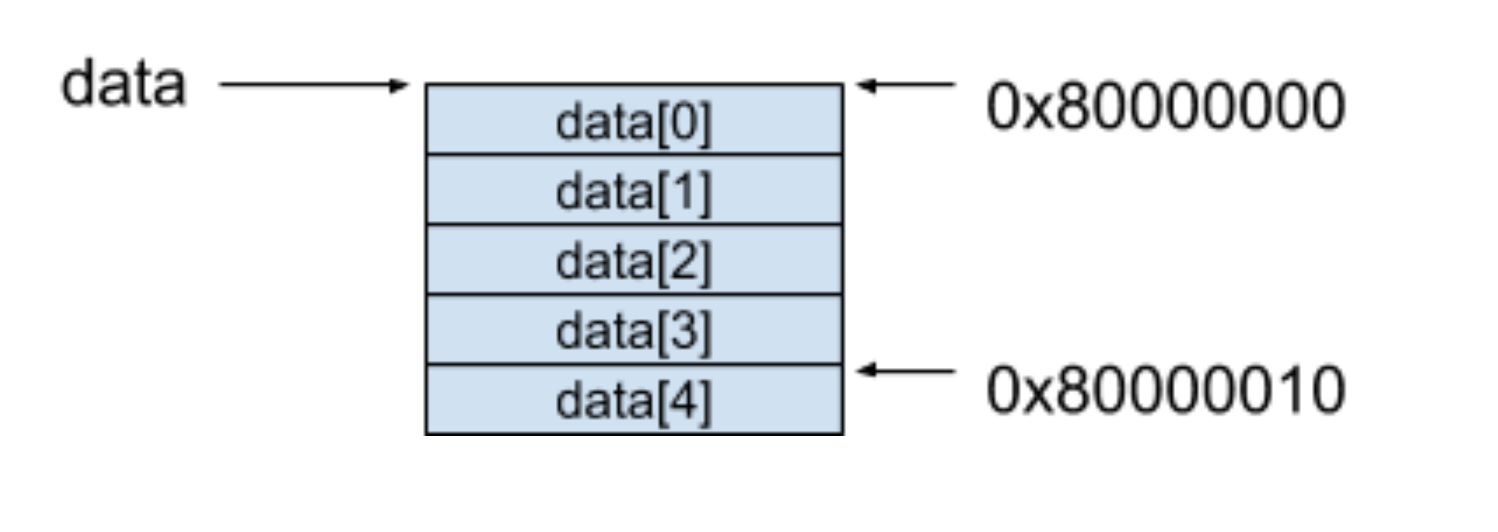
data這個陣列被分配到的起始地址是0X80000000,是因為int型別資料占據了4個位元組的空間,如果我們要訪問第五個元素data[4]的時候,按照上面的公式,只需要取得0X80000000 + 4 * 4 = 0X80000010這個地址的內容就可以了,隨機訪問的背后原理其實也就是利用這個公式達到了同等的時間訪問到一組資料中的任意元素,
2.二維陣列
上面所提到的陣列是屬于一維陣列的范疇,我們平時可能還會聽到一維陣列的其他叫法,例如向量(Vector)或者表(Table),因為在數學上,二維陣列可以很好的用來表達矩陣(Matrix)這個概念,所以很多時候我們又會將矩陣或者二維陣列這種稱呼交替使用,
如果我們按照下面的方式宣告一個二維陣列:
int[][] data = https://www.cnblogs.com/gxkeven/p/new int[2][3];
在面試中我們知道了陣列的起始地址,在基于上面的二維陣列宣告的前提下,data[0][1] 這個元素的記憶體地址是多少呢?標準答案其實是“無法確定”,什么?標準答案是無法確定,別著急,因為這個問題的答案其實和二維陣列在記憶體中的尋址方式有關,而這其實涉及到計算機記憶體到底是以行優先(Row-Major Order)還是以列優先(Column-Major Order)存盤的,
假設現在有一個二維陣列,如下圖所示:
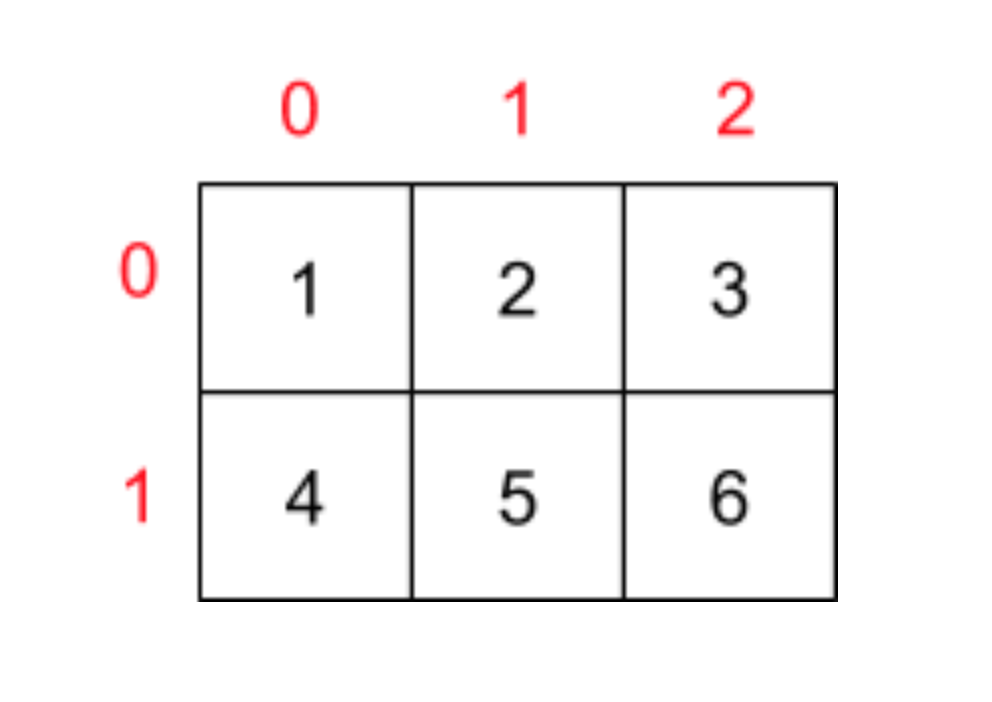
下面我們就這看看行優先或列優先造成的記憶體模型會造成什么樣的區別:
(1)行優先
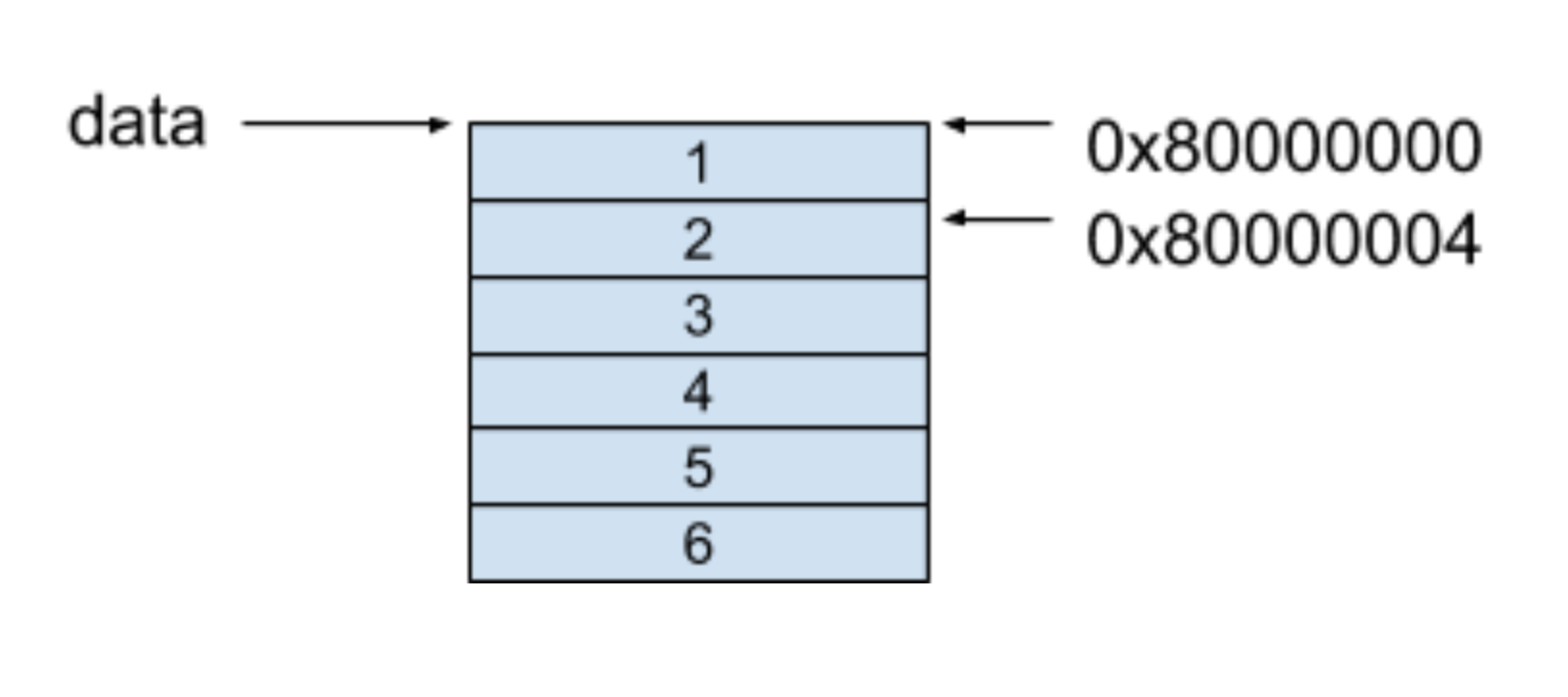
行優先的記憶體模型保證的每一行的每個相鄰元素都保存在了相鄰的連續空間中,對于上面的例子,這個記憶體模型如下圖所示,假設起止地址是0X80000000:
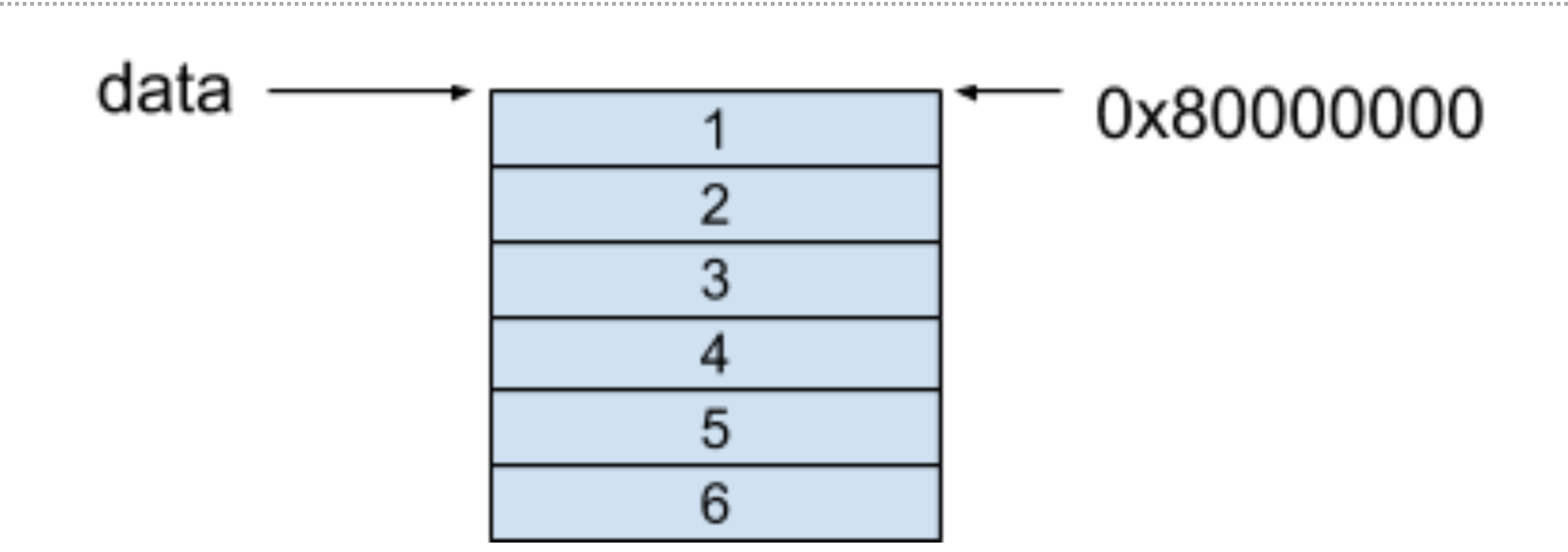
可以看到,在二維陣列的每一行中,每個相鄰的元素都保存在了相鄰的連續記憶體里,
在以行優先存盤的記憶體模型中,假設我們要訪問data[i][j]里的元素,獲取陣列的方式是按照以下公式進行獲取的:
base_address + data_size * (i * number_of_column + j)
回到一開始的問題里,當我們訪問data[0][1]這個值時,可以套用上面的公式,其得到的值就是我們要找的0X80000004地址的值,也就是2,
0x80000000 + 4 x (0 x 3 + 1) = 0x80000004
(2)列優先
列優先的記憶體模型保證了每一列的每個相鄰元素都保存在了相鄰的連續記憶體中,對于上面的例子,這個二維陣列的記憶體模型如下圖所示:
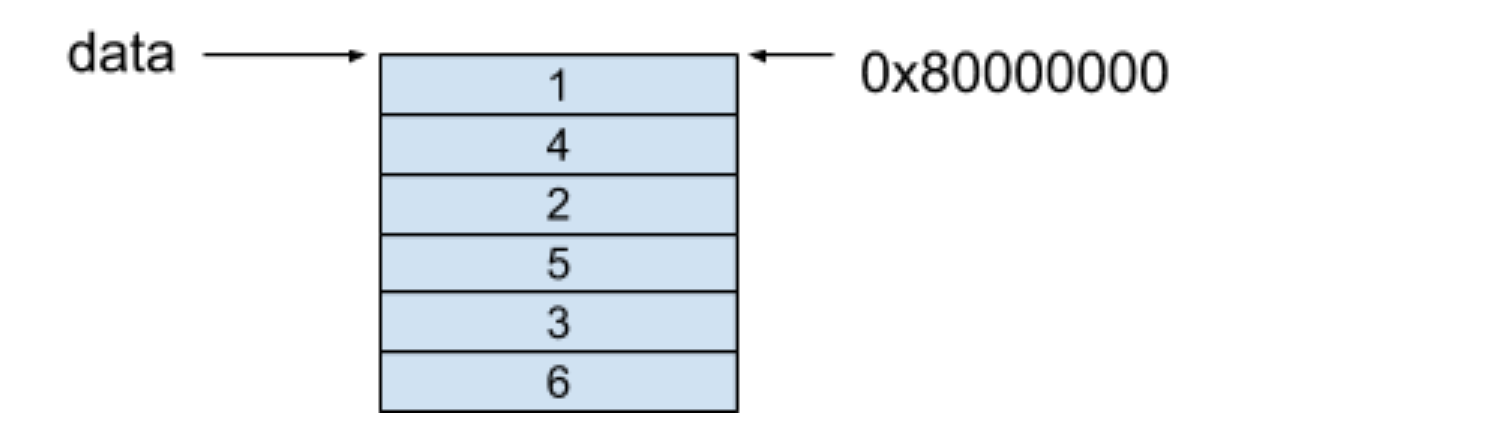
可以看到,在二維陣列的每一列中,每個相鄰的元素都保存在了相鄰的連續的記憶體中,
在以列優先存盤的記憶體模型中,假設我們要訪問data[i][j]里的元素,獲取陣列元素的方式是按照一下公式獲取的:
base_address + data_size * (i + number_of_row * j)
當我們訪問data[0][1]這個值時,可以套用上面的公式,其得到的值就是我們要找的0x80000008地址的值:
0x80000000 + 4 * (0 + 2 * 1) = 0x80000008
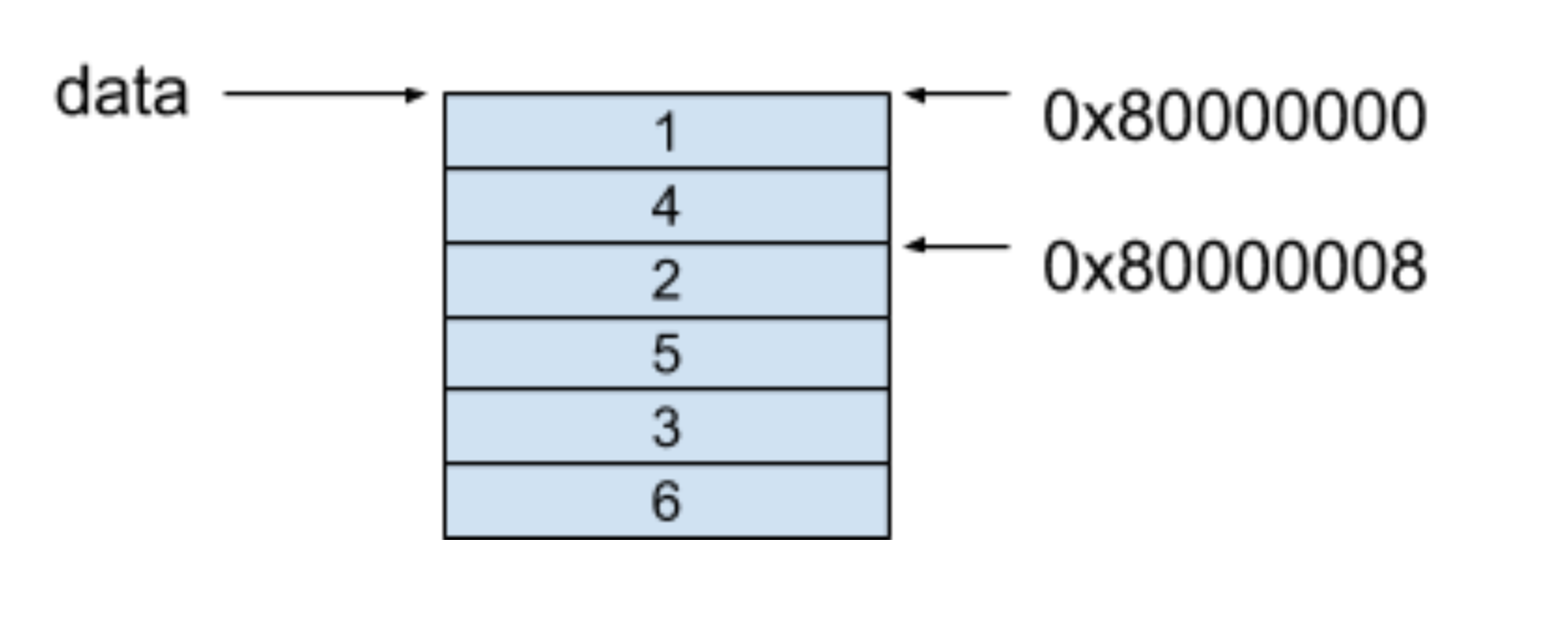
所以回到一開始那個問題里,行優先還是列優先存盤方式會造成data[0][1]元素的記憶體地址不一樣,
3.多維陣列
多維陣列其實本質上和前面介紹的一維陣列和二維陣列是一樣的,如果我們按照下面的方式來宣告一個三位陣列:
int[][][] data = https://www.cnblogs.com/gxkeven/p/new int[2][3][4];
則可以把這個陣列想象成兩個int[3][4]這樣的二維陣列,對于多維陣列則可以以此類推,下面把行優先和列優先的記憶體尋址方式列出來:
假設宣告一個data[S1][S2][S3]...[Sn]的多維陣列,如果要訪問data[D1][D2][D3]...[Dn]的元素,記憶體尋址計算方式按照如下方式尋址:
行優先:
base_address + data_size * (Dn + Sn * (Dn - 1 + Sn - 1 * (Dn - 2 + Sn - 2 * (... + S2 * D1 )... )))
列優先:
base_address + data_size * (D1 + (S1 * (D2 + S2 * (D3 + S3 * (... + Sn - 1 * Dn)...))))
cpu在讀取記憶體資料的時后,通常會有一個cpu快取策略,也就是說再cpu讀取程式指定地址的數值時,cpu會把它地址相鄰的一些資料一并讀取,并放到更高一級的快取中,比如L1或者L2快取,當資料存放到這種快取上的時候,讀取的速度有可能會比直接從記憶體上讀取的速度快10倍以上,
在高級語言中常用的C/C++和Objective-C都是行優先的記憶體模型,而Fortran或者Matlab是列優先的記憶體模型,
“高效”的訪問與“低效”的插入洗掉
從前面的的陣列記憶體模型學習中,我們知道了訪問一個陣列的元素是隨機訪問方式,只需要按照上面講到的尋址方式來獲取相應位置的數值便可,所以訪問陣列元素的復雜度是O(1),
對于保存基本型別(Primitive Type)陣列來說,它們的記憶體大小在一開始就已經確定好了,我們稱他為靜態陣列(Static Array),靜態陣列的大小是無法改變的,所以我們無法對這種陣列進行插入和洗掉操作,但是在使用高級語言的時候,比如java,我們知道java中的ArrayList這種Collection提供了像add和remove這樣的API來進行插入和洗掉操作,這種陣列可稱之為動態陣列(Dynamic Array),
我們一起來看看add和remove函式在java Open-jdk11中的原始碼,一起分析他們的時間復雜度:
在java Connection中,底層的資料結構其實還是使用的陣列,一般在初始化的時候會分配一個比我們在初始化時設定好的大小更大的空間,以方便以后進行增加元素的操作,
假設所有的元素都保存在elementData[]這個陣列中,add函式的主要時間復雜度來源于以下原始碼片段:
1.add(int index,E element)函式原始碼:
首先來看看add(int index,E element)這個函式的原始碼:
public void add(int index,E element){
rangeCheckForAdd(index);
modCount++;
final int s;
Object[] elementData;
if((s = size) == (elementData = https://www.cnblogs.com/gxkeven/p/this.element).length){
elementData = grow();
}
System.arraycopy(elementData,index,elementData,index +1,s - index);
elementData[index] = element;
size = s + 1;
}
可以看到add函式呼叫了一個System.arraycopy的函式進行記憶體操作,s在這里代表了ArrayList的size,當我們呼叫add函式的時候,函式在實作的程序中到底發生了什么?我們來看一個例子,
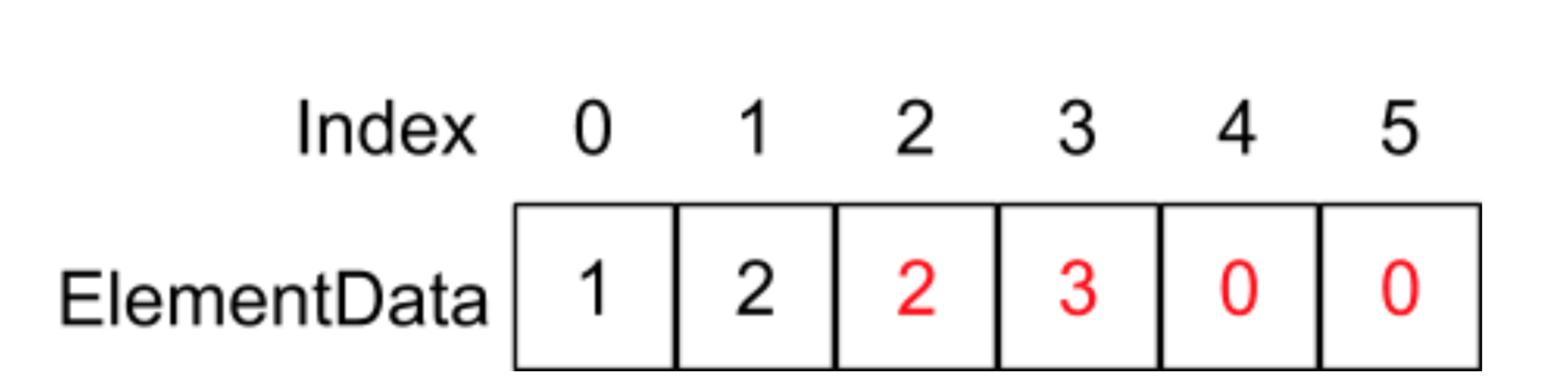
假設elementData里面存放著以下元素:
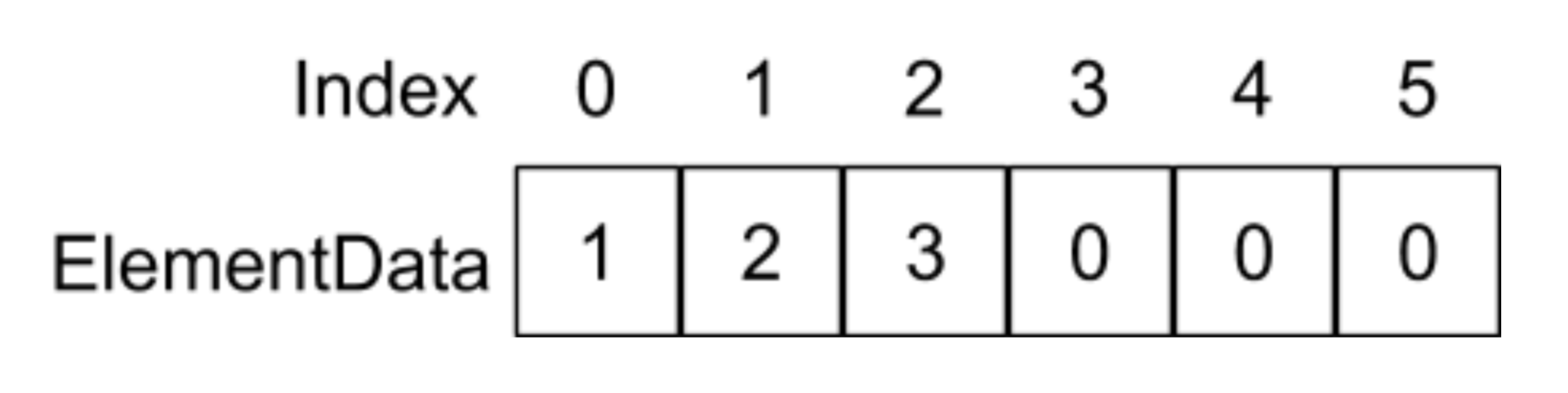
當我們呼叫的add(1,4)函式,也就是在index為1的地方插入4這個元素,在add函式中則會執行System.arraycopy(elementData,1,elementData,2,6 - 2)陳述句,它的意思是將重elementData陣列index為1的地址開始,復制往后的4個元素到elementData陣列為2的地址位置,如下圖所示:
紅色部分代表執行完System.arraycopy函式的結果,最后執行elementData[1] = 4;這條陳述句:
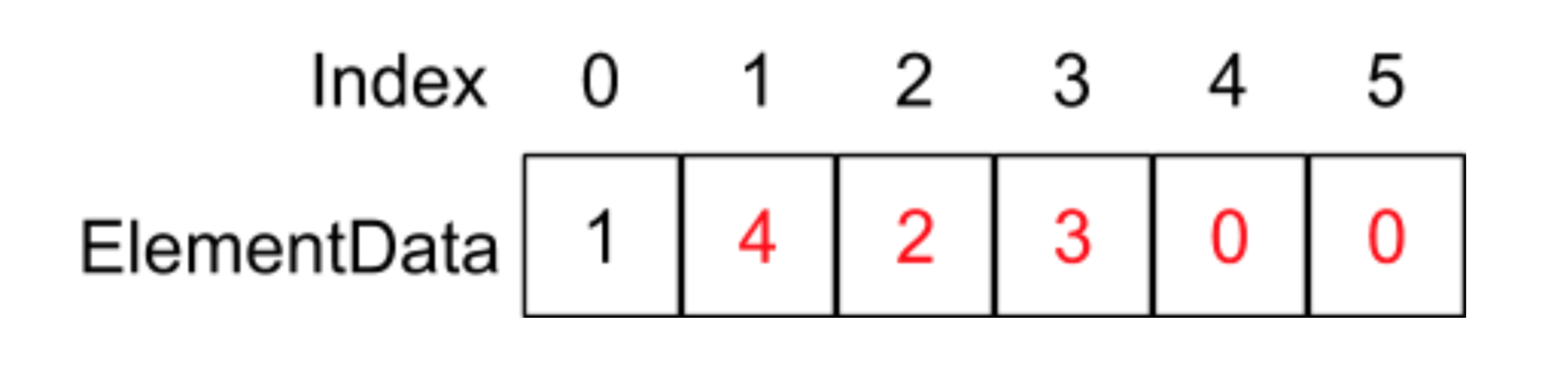
因為這里涉及到每個元素的復制,平均下來的時間復雜度相當于O(n),
2.remove(int index)函式原始碼:
1 public E remove(int index){
2 Objects.checkIndex(index,size);
3 final Object[] es = elementData;
4
5 @SuppressWarnings("unchecked") E oldValue =https://www.cnblogs.com/gxkeven/p/ (E) es[index];
6 fastRemove(es,index);
7
8 return oldValue;
9 }
10
11 private void fastRemove(Object[] es,int i){
12 modCount++;
13 final int newSize;
14 if((newSize = size -1) > i){
15 System.arraycopy(es,i+1,es,i,newSize - i);
16 }
17 es[size = newSize] = null;
18 }
這里的newSize指原來的elementData的size - 1,當我們呼叫remove(1)會發生什么呢?我們還是以下面的例子來解釋,
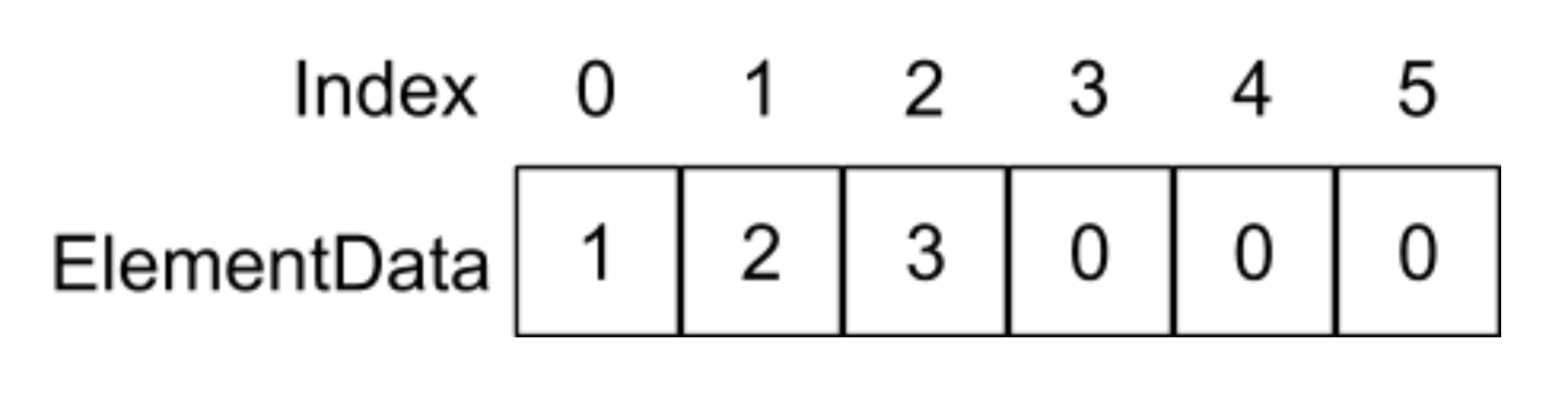
如果呼叫remove(1)函式,也就是洗掉在index為1這個地方的元素,在remove函式中則會執行System.arraycopy(elementData,2,elementData,1,2)陳述句,它的意思是將從elementData陣列index為2的地址開始,復制后面的兩個元素到elementData陣列到index為1的地址位置,如下圖所示:
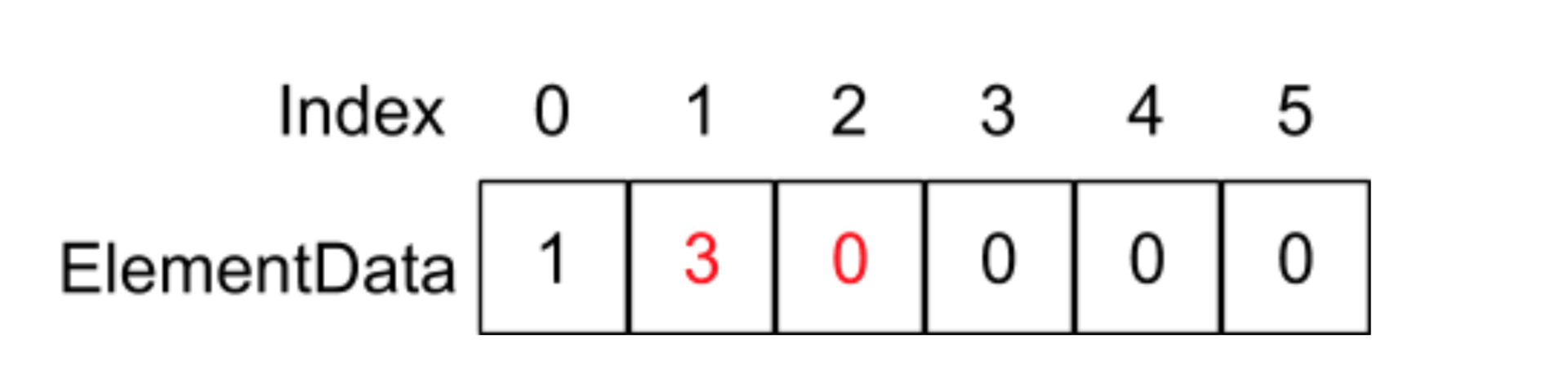
因為這里同樣涉及到每個元素的復制,平均下來時間復雜度相當于O(n),
心得:
這是我學資料結構的第一節課內容,因為基礎太薄弱,看完視頻后,感覺老師在講的時候什么都明白,然后回來再看老師的筆記還是一頭霧水,于是乎就把老師的筆記一個字一個字的打入了博客當中,這些除了圖片之外其他完全是手打的,只為增強記憶力和理解力,打完了之后對里面的內容掌握率感徑訓是不高,我會繼續學習,把我所學到的知識全部寫入我的博客中,供大家學習和交流,(根據蔡元楠老師講解的資料結構精講整理此筆記)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/114565.html
標籤:其他
上一篇:LeetCode529. 掃雷游戲 Python3 DFS+BFS+注釋
下一篇:字串