串的主分支-字串
字串主要用于編程,概念說明、函式解釋、用法詳述見正文,
這里補充一點:字串在存盤上類似字符陣列,所以它每一位的單個元素都是可以提取的,
如s=“abcdefghij”,則s[1]=“b”,s[9]="j",而字串的零位正是它的長度,如s[0]=10,
這可以給我們提供很多方便,如高精度運算時每一位都可以轉化為數字存入陣列,
中文名 字串
外文名 Character string
拼 音 zi fu chuan
簡 稱 串(String)
記 作 s=“a1a2···an”(n>=0)
釋 義 編程語言中表示文本的資料型別
簡介
字串或串(String)是由數字、字母、下劃線組成的一串字符,一般記為 s=“a1a2···an”(n>=0),它是編程語言中表示文本的資料型別,在程式設計中,字串(string)為符號或數值的一個連續序列,如符號串(一串字符)或二進制數字串(一串二進制數字),
通常以串的整體作為操作物件,如:在串中查找某個子串、求取一個子串、在串的某個位置上插入一個子串以及洗掉一個子串等,兩個字串相等的充要條件是:長度相等,并且各個對應位置上的字符都相等,設p、q是兩個串,求q在p中首次出現的位置的運算叫做模式匹配,串的兩種最基本的存盤方式是順序存盤方式和鏈接存盤方式,
設 Σ 是叫做字母表的非空有限集合,Σ 的元素叫做“符號”或“字符”,在 Σ 上的字串(或字)是來自 Σ 的任何有限序列,例如,如果 Σ = {0, 1},則 0101 是在 Σ 之上的字串,
字串的長度是在字串中字符的數目(序列的長度),它可以是任何非負整數,“空串”是在 Σ 上的唯一的長度為 0 的字串,并被指示為 ε 或 λ,
在 Σ 上的所有長度為 n 的字串的集合指示為 Σn,例如,如果 Σ = {0, 1} 則 Σ2 = {00, 01, 10, 11},注意 Σ0 = {ε} 對于任何字母表 Σ,
在 Σ 上的所有任何長度的字串的集合是 Σ 的Kleene閉包并被指示為 Σ*, 依據Σn, ,例如,如果 Σ = {0, 1} 則 Σ* = {ε, 0, 1, 00, 01, 10, 11, 000, 001, 010, 011, …},盡管 Σ* 自身是可數無限的,Σ* 的所有元素都有有限長度,
在 Σ 上一個字串的集合(就是 Σ* 的任何子集)被稱為在 Σ 上的形式語言,例如,如果 Σ = {0, 1},則帶有偶數個零的字串的集合({ε, 1, 00, 11, 001, 010, 100, 111, 0000, 0011, 0101, 0110, 1001, 1010, 1100, 1111, …})是在 Σ 上的形式語言,
字符編碼
歷史上,字串資料型別為每個字符分配一個位元組,盡管精確的字符集隨著區域而改變,字符編碼足夠類似得程式員可以忽略它
— 同一個系統在不同的區域中使用的字符集組要么讓一個字符在同樣位置,要么根本就沒有它,這些字符集典型的基于ASCII碼
或EBCDIC碼,
意音文本的語言比如漢語、日語和朝鮮語(合稱為CJK)的合理表示需要多于256個字符(每字符一個位元組編碼的極限),常規的解決
涉及保持對ASCII碼的單位元組表示并使用雙位元組來表示CJK字形,現存代碼在用到它們會導致一些字串匹配和切斷上的問題,嚴
重程度依賴于字符編碼是如何設計的,某些編碼比如EUC家族保證在ASCII碼范圍內的位元組值只表示ASCII字符,使得使用這些字
符作為欄位分隔符的系統得到編碼安全,其他編碼如ISO-2022和Shift-JIS不做這種擔保,使得基于位元組的代碼做的匹配不安全,
另一個問題是如果一個字串的開頭被洗掉了,對解碼器的重要指示或關于在多位元組序列中的位置的資訊可能就丟失了,另一個
問題是如果字串被連接到一起(特別是在被不知道這個編碼的代碼截斷了它們的結尾之后),第一個字串可能不能導致編碼器
進入適合處理第二個字串的狀態中,
Unicode也有些復雜的問題,多數語言有Unicode字串資料型別(通常是UTF-16,因為它在Unicode補充位面介入之前就被增
加了),在Unicode和本地編碼之間轉換要求理解本地編碼,這對于現存系統要一起傳輸各種編碼的字串而又沒有實際標記出它
們用了什么編碼就是個問題,
主要操作
1. 連接運算 concat(s1,s2,s3…sn) 相當于s1+s2+s3+…+sn.
例:concat(‘11’,'aa’)='11aa’;
2. 求子串 Copy(s,I,I) 從字串s中截取第I個字符開始后的長度為l的子串,
例:copy(‘abdag’,2,3)=’bda’
3. 洗掉子串 程序 Delete(s,I,l) 從字串s中洗掉第I個字符開始后的長度為l的子串,
例:s:=’abcde’;delete(s,2,3);結果s:=’ae’
4. 插入子串 程序Insert(s1,s2,I) 把s1插入到s2的第I個位置
例:s:=abc;insert(‘12’,s,2);結果s:=’a12bc’
5. 求字串長度 length(s) 例:length(‘12abc’)=5
在ASP中 求字串長度用 len(s)例: len("abc12")=5
6. 搜索子串的位置 pos(s1,s2) 如果s1是s2的子串 ,則回傳s1的第一個字符在s2中的位置,若不是子串,則回傳0.
例:pos(‘ab’,’12abcd’)=3
7. 字符的大寫轉換, Upcase(ch) 求字符ch的大寫體,
例:upcase(‘a’)=’A’
8. 數值轉換為數串 程序 Str(x,s) 把數值x化為數串s.
例:str(12345,s); 結果s=’12345’
9. 數串轉換為數值 程序val(s,x,I) 把數串s轉化為數值x,如果成功則I=0,不成功則I為無效字符的序數,第三個引數也可不傳
例:val(‘1234’,x,I);結果 x:=1234
主要演算法
字串查找演算法
正則運算式演算法
模式匹配
字串的模式匹配演算法(KMP)
AC自動機
后綴陣列/樹/自動機
(這是一些字串處理演算法,在字串上進行不同的處理)
KMP(字串的模式匹配演算法)
KMP演算法的名字是由這個演算法的三個創始人Knuth、Morris、Pratt名字的首字母縮寫而得名的
下面是KMP演算法的C語言實作
#include <stdio.h> #include <string.h> #include <stdlib.h> typedef int Position; #define NotFound -1 void BuildMatch( char *pattern, int *match ) { Position i, j; int m = strlen(pattern); match[0] = -1; for ( j=1; j<m; j++ ) { i = match[j-1]; while ( (i>=0) && (pattern[i+1]!=pattern[j]) ) i = match[i]; if ( pattern[i+1]==pattern[j] ) match[j] = i+1; //i回退的總次數不會超過i增加的總次數 else match[j] = -1; } } Position KMP( char *string, char *pattern ) { int n = strlen(string); //O(n) int m = strlen(pattern); //O(m) Position s, p, *match; if ( n < m ) return NotFound; match = (Position *)malloc(sizeof(Position) * m); BuildMatch(pattern, match); //Tm=O(m) s = p = 0; while ( s<n && p<m ) { //O(n) if ( string[s]==pattern[p] ) { s++; p++; } else if (p>0) p = match[p-1]+1; else s++; } return ( p==m )? (s-m) : NotFound; } int main() { char string[] = "This is a simple example."; char pattern[] = "simple"; Position p = KMP(string, pattern); if (p==NotFound) printf("Not Found.\n"); else printf("%s\n", string+p); return 0; }
KMP這個演算法的關鍵在于下面這個BuildMatch函式的實作
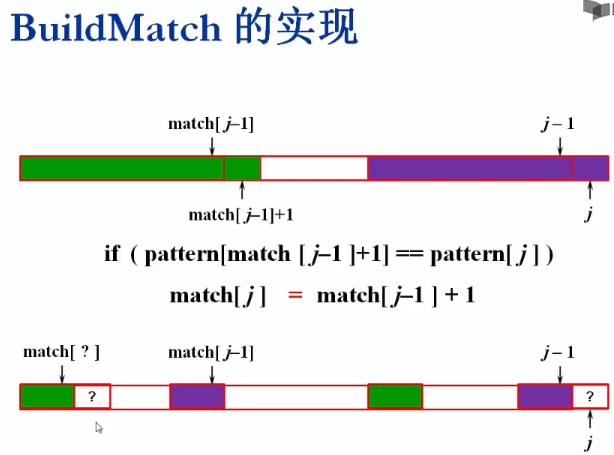
這里有個值得注意的地方
PS:當pattern[match[j-1]+1]!=pattern[j]時,
下一個待與pattern[j]比較的元素下標為:
match[match[j-1]]+1
程序的變化
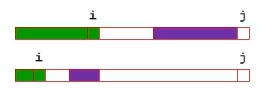


通過對上面的分析我們可以得到KMP演算法的時間復雜度為 T=O(n+m)
(這對于形如查找指定文本中的關鍵字之類的問題而言效率已經很高了哦)
2019-12-22 12:54:08
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/114569.html
標籤:其他
上一篇:陣列與鏈表的應用—陣列記憶體模型