試答系列:“西瓜書”-周志華《機器學習》習題試答
系列目錄
[第01章:緒論]
[第02章:模型評估與選擇]
[第03章:線性模型]
[第04章:決策樹]
[第05章:神經網路]
[第06章:支持向量機]
第07章:貝葉斯分類器
第08章:集成學習
第09章:聚類
第10章:降維與度量學習
第11章:特征選擇與稀疏學習
第12章:計算學習理論(暫缺)
第13章:半監督學習
第14章:概率圖模型
(后續章節更新中...)
目錄
- 8.1 假設拋硬幣正面為上的概率為p,反面朝上的概率為1-p,令H(n)代表拋n次硬幣所得正面朝上的次數,則最多k次正面朝上的概率為
- 8.2 對于0/1損失函式來說,指數損失函式并非僅有的一致替代函式,考慮式(8.5),試證明:任意損失函式 $L(-f(x)H(x))$,若對于H(x)在區間[-∞,δ] (δ>0)上單調遞減,則是0/1損失函式的一致替代函式,
- 8.3 從網上下載或自己編程實作AdaBoost,以不剪枝決策樹為基學習器,在西瓜資料集3.0α上訓練一個AdaBoost集成,并與圖8.4進行比較,
- 1. AdaBoost演算法總結
- 2. 編程計算
- 3. 運行結果討論
- 8.4 Gradient Boosting [Friedman,2001]是一種常用的Boosting演算法,試析其與AdaBoost的異同,
- 8.5 試編程實作Bagging,以決策樹樁為基學習器,在西瓜資料集3.0α上訓練一個Bagging集成,并與圖8.6進行比較,
- 8.6 試析Bagging通常為何難以提升樸素貝葉斯分類器的性能,
- 8.7 試析隨機森林為何比決策樹Bagging集成的訓練速度更快,
- 8.8 MultiBoosting演算法[Webb,2000]將AdaBoost作為Bagging的基學習器,Iterative Bagging演算法[Breiman,2001b]則將Bagging作為AdaBoost的基學習器,試比較二者的優缺點,(暫缺)
- 8.9 試設計一種可視的多樣性度量,對習題8.3和習題8.5中得到的集成進行評估,并與κ-誤差圖比較,(暫缺)
- 8.10 試設計一種能提升k近鄰分類器性能的集成學習演算法,(暫缺)
- 附:習題代碼
- 8.3(python)
- 8.5(python)
8.1 假設拋硬幣正面為上的概率為p,反面朝上的概率為1-p,令H(n)代表拋n次硬幣所得正面朝上的次數,則最多k次正面朝上的概率為
\[P(H(n)\leq k)=\sum_{i=0}^k {n \choose i}p^i(1-p)^{n-i}\tag{8.43} \]對δ>0,k=(p-δ)n,有Hoeffding不等式
\[P(H(n)\leq (p-\delta n)\leq e^{-2\delta^2 n}\tag{8.44} \]試推匯出式(8.3).
證明:(8.3)表達了集成錯誤率,當不超過半數預測正確時,集成分類器預測錯誤,因此集成錯誤率為:
注意,上式中第一行中的H(x)是集成分類器預測函式,第二行的H(T)是題目中所述的硬幣朝上次數的函式,與題目中的(8.43)、(8.44)式對比,進行變數代換:n=T,p=1-ε,k=[T/2],那么δ=1-ε-[T/2]/T,其中[T/2]/T≤1/2,所以δ≥1/2-ε,于是有
\[\begin{aligned} P(H(n)\neq f(x))&\leq exp(-2\delta^2T)\\ &\leq exp(-\frac{1}{2}(1-2\epsilon)^2 T) \end{aligned}\]得證,
8.2 對于0/1損失函式來說,指數損失函式并非僅有的一致替代函式,考慮式(8.5),試證明:任意損失函式 \(L(-f(x)H(x))\),若對于H(x)在區間[-∞,δ] (δ>0)上單調遞減,則是0/1損失函式的一致替代函式,
證明:這道題表述大概存在筆誤,應該是“…,若對于f(x)H(x)在區間…”才對,比如,對于Adaboost中采用的指數損失函式,\(L(-f(x)H(x))=exp(-f(x)H(x))\),當f(x)=1時,損失函式=exp(-H(x))是對于H(x)在[-∞,+∞]上的單調減函式,但是當f(x)=-1時,損失函式=exp(H(x))是H(x)的增函式,與題目描述不符,
對于任意損失函式,若對于f(x)H(x)在區間[-∞,δ] (δ>0)上單調遞減,函式曲線當形如下圖:
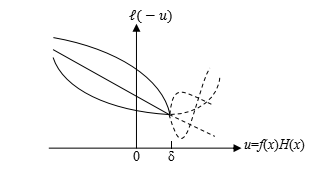
\(L(-u)\)函式的特點是:在[-∞,δ]區間是單調遞減函式(無論其凹凸性如何),在[δ,+∞]區間,可以是任意形狀曲線,無論其單調性如何,從上圖中可以看出,對該損失函式進行最小化時,所對應的橫坐標位置u*總是在δ右側,也就是f(x*)H(x*)≥δ>0,這說明H(x)與f(x)同正負號,因此sign(H(x*))=f(x*),其結果與最小化0/1損失函式結果一致,是一致替代函式,
8.3 從網上下載或自己編程實作AdaBoost,以不剪枝決策樹為基學習器,在西瓜資料集3.0α上訓練一個AdaBoost集成,并與圖8.4進行比較,
答:
1. AdaBoost演算法總結
- 西瓜書中的推導大概程序
\(\alpha_t=argmin_\alpha l_{exp}(\alpha_t h_t| D_t)=\frac{1}{2}\ln(\frac{1-\epsilon_t}{\epsilon_t})\),其中\(\epsilon_t=P_{x\sim D_t}(f(x)\neq h_t(x))\);
\(h_t (x)=argmin_h l_{exp}(H_{t-1}+h|D)\dots=argmin_h E_{x\sim D_t}[Ⅱ(f(x)\neq h(x))]\),其中將\(H_{t-1}\)的影響包含在\(D_t\)中,\(D_t(x)\)是關于x的分布,\(D_t(x)∝D(x)e^{-f(x)H_{t-1}(x)}\),Dt存在遞推關系\(D_{t+1}=D_t e^{-f(x)\alpha_t h_t(x)}/Z_t\),
然而,看完教材上的上述推導,心里充滿了疑問:
- 為什么求\(α_t\)是通過最小化\(l_{exp}(α_th_t|D_t)\)來求得?
- 為什么通過最小化\(l_{exp}(H_{t-1}+h_t|D)\)來求取\(h_t\)時,\(h_t\)前面沒有系數\(α_t\),后面推導\(D_{t+1}\)和\(D_t\)的遞推關系時,怎么就突然要加上系數\(α_t\)了?
- 其他推導方法
此前看過吳恩達的CS229課程,其補充材料中有介紹Boosting演算法的內容,同樣是對AdaBoost演算法的推導,容易理解的多,現將其總結至此:
(為了與西瓜書中的表達符號一致,對原文進行了一定的改寫)
在計算到第t步時,當前已經得到的模型為\(H_{t-1}\),接下來的學習器對當前模型\(H_{t-1}\)預測錯誤的樣本進行重點關注,定義新的樣本權重分布:
\[D_t(x)=D(x)e^{-f(x)H_{t-1}(x)}/E_{x\sim D}[e^{-f(x)H_{t-1}(x)}] \]該權重分布反映了對預測錯誤樣本的重點關注,因為,如果預測正確,\(e^{-f(x)H_{t-1}(x)}<1\),如果預測錯誤,\(e^{-f(x)H_{t-1}(x)}>1\),
\[\begin{aligned} \alpha_t &=argmin_{\alpha}l_{exp}(H_t |D)\\ &=argmin_{\alpha}E_{x\sim D}[e^{-f(x)H_{t-1}(x)}\cdot e^{-f(x)\alpha_t h_t(x)}]\\ &=argmin_{\alpha}E_{x\sim D_t}[e^{-f(x)\alpha_t h_t(x)}]\\ &=argmin_{\alpha}(1-\epsilon_t)e^{-\alpha_t}+\epsilon_t e^{\alpha_t}\\ &=\frac{1}{2}ln(\frac{1-\epsilon_t}{\epsilon_t}) \end{aligned}\]
\(h_t(x)\)的確定:在新的樣本權重下進行學習訓練,
\(α_t\)的確定:接著證明了 演算法的收斂性,注意到\(D_t\)的歸一化系數\(Z_t=E_{x\sim D}[e^{-f(x)H_{t-1}(x)}]=l_{exp}(H_{t-1}|D)\),因此有:
\[\begin{aligned} l_{exp}(H_t |D)&=E_{x\sim D}[e^{-f(x)H_{t-1}(x)}\cdot e^{-f(x)\alpha_t h_t(x)}]\\ &=E_{x\sim D}[Z_t \cdot D_t(x)\cdot e^{-f(x)\alpha_t h_t(x)}]\\ &=l_{exp}(H_{t-1} |D)\cdot E_{x\sim D_t}[e^{-f(x)\alpha_t h_t(x)}]\\ &=l_{exp}(H_{t-1} |D)\cdot 2\sqrt{\epsilon_t(1-\epsilon_t)} \end{aligned}\]設每個弱分類器的誤差滿足\(\epsilon_t \leq \frac{1}{2}-\gamma\),則有:
\[\begin{aligned} l_{exp}(H_t |D)&=l_{exp}(H_{t-1} |D)\cdot 2\sqrt{\epsilon_t(1-\epsilon_t)}\\ &\leq l_{exp}(H_{t-1} |D)\cdot \sqrt{1-4\gamma^2} \end{aligned}\]因此有:
\[l_{exp}(H_t |D)\leq l_{exp}(H_0|D)(1-4\gamma^2)^{t/2}=(1-4\gamma^2)^{t/2} \]其中\(l_{exp}(H_0|D)=Z_0 =1\),經過有限步T以后,必然有\(l_{exp}(H_T|D)< \frac{1}{m}\),此時所有樣本都被正確分類,對應的最大步數\(T_{max}=-2\ln m/ln(1-4γ^2)≤\ln m/2γ^2\).
至于為什么\(l_{exp}(H_T|D)< \frac{1}{m}\)時,所有樣本都正確分類?因為\(l_{exp}(H_T|D)\geq l_{1/0}(H_T|D)=\epsilon\),當\(l_{exp}(H_T|D)< \frac{1}{m}\)時,\(\epsilon=\frac{誤分數}{m}<\frac{1}{m}\),誤分樣本數<1,意味著所有樣本都被正確分類,
- 討論
現在可以回頭來解答前面存在的疑問了:
- 為什么求\(α_t\)是通過最小化\(l_{exp}(α_th_t|D_t)\)來求得?
最小化\(l_{exp}(α_th_t|D_t)\)實際上等價于最小化\(l_{exp}(H_{t-1}+α_th_t|D)\),而后者正是我們最終的優化目標,如此便好理解了, - 為什么通過最小化\(l_{exp}(H_{t-1}+h_t|D)\)來求取\(h_t\)時,\(h_t\)前面沒有系數\(α_t\),后面推導\(D_{t+1}\)和\(D_t\)的遞推關系時,怎么就突然要加上系數\(α_t\)了?
西瓜書上最小化\(l_{exp}(H_{t-1}+h_t|D)\)來求取\(h_t\)不太好理解,\(D_t\)是化簡前式程序中析出的一部分,是個析出量,而CS229課程中的證明程序則直觀易于理解,\(D_t\)反映了當前步驟對之前預測錯誤的樣本進行重點關注的權重重新分配,是個直接定義量.
另外,注意到,在上述證明演算法收斂性的程序中,假設每個弱分類器的預測錯誤率優于隨機分類器:\(\epsilon_t \leq \frac{1}{2}-\gamma\),從而得到的結論\(l_{exp}(H_t |D)\leq l_{exp}(H_{t-1} |D)\sqrt{1-4\gamma^2}\),接著有后面演算法必然收斂的結論,其實,如果分類器很差,\(\epsilon_t >\frac{1}{2}+\gamma\),也可以得到相同的結果,再者,即便分類器\(h_t(x)\)的錯誤率比隨機分類器還差:\(\epsilon_t >\frac{1}{2}\),由此得到的\(α_t<0\),那么\(α_t h_t(x)=|α_t|·[-h_t(x)]\),這相當于自動將\(h_t(x)\)進行了翻轉糾正,
因此,教材中提到的\(\epsilon_t <\frac{1}{2}\)的限制,完全沒必要,真正關鍵的在于 錯誤率要遠離1/2,更靠近0或者1都可以, 假如某次迭代時\(\epsilon_t =\frac{1}{2}\),則\(α_t=0\),\(l_{exp}(H_t |D)=l_{exp}(H_{t-1} |D)\),不會再產生新的學習器,損失函式不再變化,Boosting演算法陷入停滯,無法再進行下去,
2. 編程計算
題目上說“以不剪枝決策樹為基學習器”,沒明白什么意思,好像有問題,AdaBoost的基學習器通常是弱學習器,而不剪枝決策樹第一步便可實作零誤差分類,對應的\(α_1=∞\),下一步的分布\(D_2=0\),演算法無法再進行下去,既然要與圖8.4進行比較,下面的解答采用與之相同的決策樹樁作為基學習器,
詳細編程代碼附后,
說明一點,根據前面討論,對于每個決策樹樁,我統一約定左分支取值為1,右分支取值為-1,即便當前\(h_t(x)\)的效果較差,\(\epsilon_t>1/2\),流程也會通過\(α_t<0\)的方式自動將其糾正過來,
3. 運行結果討論
首先,嘗試在生成決策樹樁時,以資訊增益最大化來確定劃分屬性和劃分點,結果失敗,程序中會導致\(ε_t=1/2\),Boosting演算法無法再進行下去,
于是,改用最小化誤差來進行劃分選擇:\(min E_{x\sim D_t}[Ⅱ(f(x)\neq h_t(x))]\),計算結果如下:

在t=7時即達到零錯誤率(此處的錯誤率是指總的預測函式\(H_t(x)\)在原資料集D上的錯誤率,注意與\(\epsilon_t\)區分),
正如前面的分析(“其他推導方法”中對收斂性的證明),\(l_{exp}≥l_{0/1}=錯誤率ε\),\(l_{exp}\)是\(l_{0/1}\)的上界,當\(l_{exp}<1/m\)時,必有\(l_{0/1}<1/m\),必有\(l_{0/1}=0\),

上圖中采用與教材8.4中相同的表示方法:紅粗線和黑細線分別表示集成和基學習器的分類邊界,這里得到的分類邊界與教材8.4有所不同,
另外,根據前面的討論,只要\(\epsilon_t\)不等于1/2,都能保證\(l_{exp}\)收斂并在有限步迭代后達到零錯誤率,因此,我嘗試了用隨機方法產生\(h_t(x)\),按理說仍然能夠保證演算法收斂,某次實驗結果如下:


正如預期,盡管每個\(h_t\)是隨機產生的,卻能夠確保演算法收斂,只不過收斂速度較慢,損失函式\(l_{exp}\)總是單調下降的,錯誤率在t=29歸零之后盡管有反彈,但總能穩定歸零,
那么,在Adaboost演算法中,當\(\epsilon_t\)=1/2時,可以不必break,可以重新隨機產生一個\(\epsilon_t\)≠1/2 的基學習器來避免程式早停,
再次嘗試通過資訊增益最大化來進行劃分,但是引入一個機制:當\(\epsilon_t\)=1/2時,重新隨機產生一個弱學習器,某次實驗結果如下:

8.4 Gradient Boosting [Friedman,2001]是一種常用的Boosting演算法,試析其與AdaBoost的異同,
答:
-
Gradient Boosting演算法簡介
演算法描述如下圖所示(參考原論文,以及這篇博文)

下面試將Gradient Boosting演算法改寫成與本教材一致的表達方式:演算法:Gradient Boosting
- \(h_0(x)=argmin_\alpha E_{x\sim D}[L(f(x),\alpha)]\)
- for t=1,2,...,T do:
- \(\,\,\,\,\,\,\,\,\tilde{y_i}=-[\frac{\partial L(f(x_i),H(x_i))}{\partial H(x_i)}]_{H(x)=H_{t-1}(x)}, i=1\sim m\)
- \(\,\,\,\,\,\,\,\,h_t(x)=argmin_{\beta,h}E_{x\sim D}[(\tilde{y}-\beta h(x))^2]\)
- \(\,\,\,\,\,\,\,\,\alpha_t=argmin_\alpha E_{x\sim D}[L(y,H_{t-1}(x)+\alpha h_t(x))]\)
- \(\,\,\,\,\,\,\,\,H_t(x)=H_{t-1}(x)+\alpha_t h_t(x)\)
- end for
討論
Gradient Boosting演算法第3行即是求取目標函式L關于預測函式H的負梯度,比如,\(L=(y-H)^2\),則有\(\partial L/\partial H=2(H-y)\),
此前,在對率回歸和神經網路的訓練中我們了解過梯度下降法,不過,那里是求取目標函式L關于引數θ的梯度,預測函式H(x;θ)的模型本身的形式不變,比如對率回歸中,它固定是線性函式,在神經網路中,各層神經元數目固定,而引數θ則可任意變化,我們的任務是在θ的引數空間中搜索最佳引數,
然而在這里,我們把H看成可以任意變化的函式,L是關于H這個函式的函式(泛函),如果H真的可以任意變化,我們直接令H(x)=y不就好了,也有可能H(x)=y未必使L達到最小,此時可以通過最小化\(L(y,H_{t-1}+h)\)來求取\(h_t\),
然而,通常H不能任意變化,具體在boosting演算法中,H被限定為多個弱學習器相加的形式,那么在第t步確定\(h_t\)時,Gradient Boosting演算法便是以這個負梯度作為啟發方向,使\(h_t\)應該盡可能地接近于該方向,
Gradient Boosting演算法適用于多種形式的損失函式,如果L取與AdaBoost中一樣的指數損失函式,并且f(x)={1,-1},我們可以試著推導一下,結果應如是:演算法:exp-boost
- \(h_0(x)=sign(m_+-m_-)\)
- for t=1,2,...,T do:
- \(\,\,\,\,\,\,\,\,\tilde{y_i}=f(x_i)exp[-f(x_i)H_{t-1}(x_i)], i=1\sim m\)
- \(\,\,\,\,\,\,\,\,h_t(x)=argmin_{\beta,h}E_{x\sim D}[(\tilde{y}-\beta h(x))^2]=\cdots=argmin_hE_{x\sim D_t}[Ⅱ(f(x)\neq h(x))]\)
- \(\,\,\,\,\,\,\,\,\alpha_t=argmin_\alpha E_{x\sim D}[L(y,H_{t-1}(x)+\alpha h_t(x))]=\cdots=\frac{1}{2}ln\frac{1-\epsilon_t}{\epsilon_t}\)
- \(\,\,\,\,\,\,\,\,H_t(x)=H_{t-1}(x)+\alpha_t h_t(x)\)
- end for
可見,此時Gradient Boosting演算法除了多了一個\(h_0(x)\),相應的初始分布D1有所不同,在t=1,2…,T迭代步驟中,\(h_t\)和\(\alpha_t\)的計算方法與AdaBoost演算法完全相同,
-
比較Gradient Boosting和AdaBoost演算法
相同點:
預測函式H(x)同樣是“加性模型”,亦即基學習器的線性組合;
第t步產生\(h_t\)和\(\alpha_t\)時,都保持前面的\(H_{t-1}(x)\)不變;
\(\alpha_t\)的計算都是通過在既定\(h_t(x)\)的情況下來最小化目標函式;
AdaBoost演算法可以看成是在指數損失函式和y={1,-1}情況下的Gradient Boosting演算法特例;
不同點:
求取\(h_t\)的思路不同(盡管在指數損失函式和y={1,-1}情況下結果一樣),在AdaBoost中,根據當前\(H_{t-1}(x)\)的預測效果來重新調整各個樣本的權重,提高錯誤樣本的權重,基于此來訓練\(h_t(x)\),而在Gradient Boosting中,通過尋找與負梯度方向最接近的函式\(h_t(x)=argmin_h|\nabla_HL-βh(x)|^2\),
Gradient Boosting演算法適用范圍更廣,函式取值可以連續取值、離散取值(不限于y={1,-1}),損失函式可以是平方差,絕對偏差,Huber,logistic型,而AdaBoost演算法只能用于二分類的情況,
8.5 試編程實作Bagging,以決策樹樁為基學習器,在西瓜資料集3.0α上訓練一個Bagging集成,并與圖8.6進行比較,
答:詳細編程代碼附后,
以樁決策樹為基學習器,下圖是某一次的計算結果:


可見,訓練誤差最低為0.17,最少有3個樣本被誤分,與圖8.6比較,分類效果較差,哪里出了問題?
網上查閱相關介紹,比如這篇博文,
了解到:Boosting演算法的基學習器通常是弱學習器,特點是偏差較大,通過Boosting演算法可以逐步提升,較低偏差;而Bagging的基學習器通常是強學習器,比如,全域策樹和神經網路,特點是偏差較小,但是容易過擬合,方差較大,通過多個基學習器的平均來減小方差,防止過擬合,
這里采用的基學習器是決策樹樁,本身偏差較大,Bagging集成只有降低方差的效果,對于偏差并無改善,所以集成后的訓練誤差仍然很低,于是,我們將基學習器改為全域策樹,下圖是某次計算結果:


可見,前4個集成后便已經實作了零訓練誤差,
8.6 試析Bagging通常為何難以提升樸素貝葉斯分類器的性能,
答:參考上題8.5的一些結論,樸素貝葉斯分類器本身的特點是偏差較大,算是弱學習
8.7 試析隨機森林為何比決策樹Bagging集成的訓練速度更快,
答:在選擇劃分屬性時,隨機森林只需考察隨機選取的幾個屬性,而決策樹Bagging則要考察所有屬性,因此訓練速度更快,
8.8 MultiBoosting演算法[Webb,2000]將AdaBoost作為Bagging的基學習器,Iterative Bagging演算法[Breiman,2001b]則將Bagging作為AdaBoost的基學習器,試比較二者的優缺點,(暫缺)
答:
8.9 試設計一種可視的多樣性度量,對習題8.3和習題8.5中得到的集成進行評估,并與κ-誤差圖比較,(暫缺)
答:
8.10 試設計一種能提升k近鄰分類器性能的集成學習演算法,(暫缺)
答:
附:習題代碼
8.3(python)
# -*- coding: utf-8 -*-
"""
Created on Wed Mar 11 09:50:11 2020
@author: MS
"""
import numpy as np
import matplotlib.pyplot as plt
#設定出圖顯示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def Adaboost(X,Y,T,rule='MaxInfoGain',show=False):
# 以決策樹樁為基學習器的Adaboost演算法
# 輸入:
# X:特征,m×n維向量
# Y:標記,m×1維向量
# T:訓練次數
# rule:決策樹樁屬性劃分規則,可以是:
# 'MaxInfoGain','MinError','Random'
# show:是否計算并顯示迭代程序中的損失函式和錯誤率
# 輸出:
# H:學習結果,T×3維向量,每行對應一個基學習器,
# 第一串列示αt,第二串列示決策樹樁的分類特征,第三串列示劃分點
m,n=X.shape #樣本數和特征數
D=np.ones(m)/m #初始樣本分布
H=np.zeros([T,3]) #初始化學習結果為全零矩陣
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#這部分用于計算迭代程序中的損失函式和錯誤率的變化
#可有可無
H_pre=np.zeros(m) #H對各個樣本的預測結果
L=[] #存盤每次迭代后的損失函式
erro=[] #存盤每次迭代后的錯誤率
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
for t in range(T):
if rule=='MaxInfoGain':
ht=decision_sdumps_MaxInfoGain(X,Y,D)
elif rule=='MinError':
ht=decision_sdumps_MinError(X,Y,D)
else: #rule=='Random'或者其他未知取值時,隨機產生
ht=decision_sdumps_Random(X,Y,D)
ht_pre=(X[:,ht[0]]<=ht[1])*2-1 #左分支為1,右分支為-1
et=sum((ht_pre!=Y)*D)
while abs(et-0.5)<1E-3:
# 若et=1/2,重新隨機生成
ht=decision_sdumps_Random(X,Y,D)
ht_pre=(X[:,ht[0]]<=ht[1])*2-1
et=sum((ht_pre!=Y)*D)
alphat=0.5*np.log((1-et)/et)
H[t,:]=[alphat]+ht
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#這部分用于計算迭代程序中的損失函式和錯誤率的變化
#可有可無
if show:
H_pre+=alphat*ht_pre
L.append(np.mean(np.exp(-Y*H_pre)))
erro.append(np.mean(np.sign(H_pre)!=Y))
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
D*=np.exp(-alphat*Y*ht_pre)
D=D/D.sum()
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#這部分用于顯示迭代程序中的損失函式和錯誤率的變化
#可有可無
if show:
try:
plt.title('t=%d時錯誤率歸0'%(np.where(np.array(erro)==0)[0][0]+1))
except:
plt.title('錯誤率尚未達到0')
plt.plot(range(1,len(L)+1),L,'o-',markersize=2,label='損失函式的變化')
plt.plot(range(1,len(L)+1),erro,'o-',markersize=2,label='錯誤率的變化')
plt.plot([1,len(L)+1],[1/m,1/m],'k',linewidth=1,label='1/m 線')
plt.xlabel('基學習器個數')
plt.ylabel('指數損失函式/錯誤率')
plt.legend()
plt.show()
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
return H
def decision_sdumps_MinError(X,Y,D):
# 基學習器---決策樹樁
# 以最小化錯誤率來選擇劃分屬性和劃分點
m,n=X.shape #樣本數和特征數
results=[] #存盤各個特征下的最佳劃分點和錯誤率
for i in range(n): #遍歷各個候選特征
x=X[:,i] #樣本在該特征下的取值
x_sorted=np.unique(x) #該特征下的可能取值并排序
ts=(x_sorted[1:]+x_sorted[:-1])/2 #候選劃分點
Errors=[] #存盤各個劃分點下的|錯誤率-0.5|的值
for t in ts:
Ypre=(x<=t)*2-1
Errors.append(abs(sum(D[Ypre!=Y])-0.5))
Bestindex=np.argmax(Errors) #距離0.5最遠的錯誤率的索引號
results.append([ts[Bestindex],Errors[Bestindex]])
results=np.array(results)
divide_feature=np.argmax(results[:,1]) #劃分特征
h=[divide_feature,results[divide_feature,0]] #劃分特征和劃分點
return h
def decision_sdumps_MaxInfoGain(X,Y,D):
# 基學習器---決策樹樁
# 以資訊增益最大來選擇劃分屬性和劃分點
m,n=X.shape #樣本數和特征數
results=[] #存盤各個特征下的最佳劃分點和資訊增益
for i in range(n): #遍歷各個候選特征
x=X[:,i] #樣本在該特征下的取值
x_sorted=np.unique(x) #該特征下的可能取值并排序
ts=(x_sorted[1:]+x_sorted[:-1])/2 #候選劃分點
Gains=[] #存盤各個劃分點下的資訊增益
for t in ts:
Gain=0
Y_left,D_left=Y[x<=t],D[x<=t] #左分支樣本的標記和分布
Dl=sum(D_left) #左分支總分布數
p1=sum(D_left[Y_left==1])/Dl #左分支正樣本分布比例
p0=sum(D_left[Y_left==-1])/Dl #左分支負樣本分布比例
Gain+=Dl*(np.log2(p1**p1)+np.log2(p0**p0))
Y_right,D_right=Y[x>t],D[x>t] #右分支樣本的標記和分布
Dr=sum(D_right) #右分支總分布數
p1=sum(D_right[Y_right==1])/Dr #右分支正樣本分布比例
p0=sum(D_right[Y_right==-1])/Dr #右分支負樣本分布比例
Gain+=Dr*(np.log2(p1**p1)+np.log2(p0**p0))
Gains.append(Gain)
results.append([ts[np.argmax(Gains)],max(Gains)])
results=np.array(results)
divide_feature=np.argmax(results[:,1]) #劃分特征
h=[divide_feature,results[divide_feature,0]] #劃分特征和劃分點
return h
def decision_sdumps_Random(X,Y,D):
# 基學習器---決策樹樁
# 隨機選擇劃分屬性和劃分點
m,n=X.shape #樣本數和特征數
bestfeature=np.random.randint(2)
x=X[:,bestfeature] #樣本在該特征下的取值
x_sorted=np.sort(x) #特征取值排序
ts=(x_sorted[1:]+x_sorted[:-1])/2 #候選劃分點
bestt=ts[np.random.randint(len(ts))]
h=[bestfeature,bestt]
return h
def predict(H,X1,X2):
# 預測結果
# 僅X1和X2兩個特征,X1和X2同維度
pre=np.zeros(X1.shape)
for h in H:
alpha,feature,point=h
pre+=alpha*(((X1*(feature==0)+X2*(feature==1))<=point)*2-1)
return np.sign(pre)
##############################
# 主程式
##############################
#>>>>>西瓜資料集3.0α
X=np.array([[0.697,0.46],[0.774,0.376],[0.634,0.264],[0.608,0.318],[0.556,0.215],
[0.403,0.237],[0.481,0.149],[0.437,0.211],[0.666,0.091],[0.243,0.267],
[0.245,0.057],[0.343,0.099],[0.639,0.161],[0.657,0.198],[0.36,0.37],
[0.593,0.042],[0.719,0.103]])
Y=np.array([1,1,1,1,1,1,1,1,-1,-1,-1,-1,-1,-1,-1,-1,-1])
#>>>>>運行Adaboost
T=50
H=Adaboost(X,Y,T,rule='MaxInfoGain',show=True)
# rule:決策樹樁屬性劃分規則,可以取值:'MaxInfoGain','MinError','Random'
#>>>>>觀察結果
x1min,x1max=X[:,0].min(),X[:,0].max()
x2min,x2max=X[:,1].min(),X[:,1].max()
x1=np.linspace(x1min-(x1max-x1min)*0.2,x1max+(x1max-x1min)*0.2,100)
x2=np.linspace(x2min-(x2max-x2min)*0.2,x2max+(x2max-x2min)*0.2,100)
X1,X2=np.meshgrid(x1,x2)
for t in [3,5,11,30,40,50]:
plt.title('前%d個基學習器'%t)
plt.xlabel('密度')
plt.ylabel('含糖量')
# 畫樣本資料點
plt.scatter(X[Y==1,0],X[Y==1,1],marker='+',c='r',s=100,label='好瓜')
plt.scatter(X[Y==-1,0],X[Y==-1,1],marker='_',c='k',s=100,label='壞瓜')
plt.legend()
# 畫基學習器劃分邊界
for i in range(t):
feature,point=H[i,1:]
if feature==0:
plt.plot([point,point],[x2min,x2max],'k',linewidth=1)
else:
plt.plot([x1min,x1max],[point,point],'k',linewidth=1)
# 畫集成學習器劃分邊界
Ypre=predict(H[:t],X1,X2)
plt.contour(X1,X2,Ypre,colors='r',linewidths=5,levels=[0])
plt.show()
8.5(python)
以決策樹樁為基學習器
# -*- coding: utf-8 -*-
"""
Created on Wed Mar 11 09:50:11 2020
@author: MS
"""
import numpy as np
import matplotlib.pyplot as plt
#設定出圖顯示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def decision_sdumps_MaxInfoGain(X,Y):
# 基學習器---決策樹樁
# 以資訊增益最大來選擇劃分屬性和劃分點
m,n=X.shape #樣本數和特征數
results=[] #存盤各個特征下的最佳劃分點,左分支取值,右分支取值,資訊增益
for i in range(n): #遍歷各個候選特征
x=X[:,i] #樣本在該特征下的取值
x_values=np.unique(x) #當前特征的所有取值
ts=(x_values[1:]+x_values[:-1])/2 #候選劃分點
Gains=[] #存盤各個劃分點下的資訊增益
for t in ts:
Gain=0
Y_left=Y[x<=t] #左分支樣本的標記
Dl=len(Y_left) #左分支樣本數
p1=sum(Y_left==1)/Dl #左分支正樣本比例
p0=sum(Y_left==-1)/Dl #左分支負樣本比例
Gain+=Dl/m*(np.log2(p1**p1)+np.log2(p0**p0))
Y_right=Y[x>t] #右分支樣本的標記
Dr=len(Y_right) #右分支總樣本數
p1=sum(Y_right==1)/Dr #右分支正樣本比例
p0=sum(Y_right==-1)/Dr #右分支負樣本比例
Gain+=Dr/m*(np.log2(p1**p1)+np.log2(p0**p0))
Gains.append(Gain)
best_t=ts[np.argmax(Gains)] #當前特征下的最佳劃分點
best_gain=max(Gains) #當前特征下的最佳資訊增益
left_value=https://www.cnblogs.com/NoNameIsBeginning/archive/2020/09/25/(sum(Y[x<=best_t])>=0)*2-1 #左分支取值(多數類的類別)
right_value=(sum(Y[x>best_t])>=0)*2-1 #右分支取值(多數類的類別)
results.append([best_t,left_value,right_value,best_gain])
results=np.array(results)
df=np.argmax(results[:,-1]) #df表示divide_feature,劃分特征
h=[df]+list(results[df,:3]) #劃分特征,劃分點,左枝取值,右枝取值
return h
def predict(H,X1,X2):
# 預測結果
# 僅X1和X2兩個特征,X1和X2同維度
pre=np.zeros(X1.shape)
for h in H:
df,t,lv,rv=h #劃分特征,劃分點,左枝取值,右枝取值
X=X1 if df==0 else X2
pre+=(X<=t)*lv+(X>t)*rv
return np.sign(pre)
#>>>>>西瓜資料集3.0α
X=np.array([[0.697,0.46],[0.774,0.376],[0.634,0.264],[0.608,0.318],[0.556,0.215],
[0.403,0.237],[0.481,0.149],[0.437,0.211],[0.666,0.091],[0.243,0.267],
[0.245,0.057],[0.343,0.099],[0.639,0.161],[0.657,0.198],[0.36,0.37],
[0.593,0.042],[0.719,0.103]])
Y=np.array([1,1,1,1,1,1,1,1,-1,-1,-1,-1,-1,-1,-1,-1,-1])
m=len(Y)
#>>>>>Bagging
T=20
H=[] #存盤各個決策樹樁,
#每行為四元素串列,分別表示劃分特征,劃分點,左枝取值,右枝取值
H_pre=np.zeros(m) #存盤每次迭代后H對于訓練集的預測結果
error=[] #存盤每次迭代后H的訓練誤差
for t in range(T):
boot_strap_sampling=np.random.randint(0,m,m) #產生m個亂數
Xbs=X[boot_strap_sampling] #自助采樣
Ybs=Y[boot_strap_sampling] #自助采樣
h=decision_sdumps_MaxInfoGain(Xbs,Ybs) #訓練基學習器
H.append(h) #存入基學習器
#計算并存盤訓練誤差
df,t,lv,rv=h #基學習器引數
Y_pre_h=(X[:,df]<=t)*lv+(X[:,df]>t)*rv #基學習器預測結果
H_pre+=Y_pre_h #更新集成預測結果
error.append(sum(((H_pre>=0)*2-1)!=Y)/m) #當前集成預測的訓練誤差
H=np.array(H)
#>>>>>繪制訓練誤差變化曲線
plt.title('訓練誤差的變化')
plt.plot(range(1,T+1),error,'o-',markersize=2)
plt.xlabel('基學習器個數')
plt.ylabel('錯誤率')
plt.show()
#>>>>>觀察結果
x1min,x1max=X[:,0].min(),X[:,0].max()
x2min,x2max=X[:,1].min(),X[:,1].max()
x1=np.linspace(x1min-(x1max-x1min)*0.2,x1max+(x1max-x1min)*0.2,100)
x2=np.linspace(x2min-(x2max-x2min)*0.2,x2max+(x2max-x2min)*0.2,100)
X1,X2=np.meshgrid(x1,x2)
for t in [3,5,11,15,20]:
plt.title('前%d個基學習器'%t)
plt.xlabel('密度')
plt.ylabel('含糖量')
#plt.contourf(X1,X2,Ypre)
# 畫樣本資料點
plt.scatter(X[Y==1,0],X[Y==1,1],marker='+',c='r',s=100,label='好瓜')
plt.scatter(X[Y==-1,0],X[Y==-1,1],marker='_',c='k',s=100,label='壞瓜')
plt.legend()
# 畫基學習器劃分邊界
for i in range(t):
feature,point=H[i,:2]
if feature==0:
plt.plot([point,point],[x2min,x2max],'k',linewidth=1)
else:
plt.plot([x1min,x1max],[point,point],'k',linewidth=1)
# 畫基集成效果的劃分邊界
Ypre=predict(H[:t],X1,X2)
plt.contour(X1,X2,Ypre,colors='r',linewidths=5,levels=[0])
plt.show()
以完整決策樹作為基學習器
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 17 13:16:42 2020
@author: MS
前面采用決策樹樁來進行Bagging集成,效果較差,
現在改用全域策樹full-tree來集成,觀察效果,
全域策樹演算法不再自編,直接采用sklearn工具,
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn import tree
#設定出圖顯示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def predict(H,X1,X2):
# 預測結果
# 僅X1和X2兩個特征,X1和X2同維度
X=np.c_[X1.reshape(-1,1),X2.reshape(-1,1)]
Y_pre=np.zeros(len(X))
for h in H:
Y_pre+=h.predict(X)
Y_pre=2*(Y_pre>=0)-1
Y_pre=Y_pre.reshape(X1.shape)
return Y_pre
#>>>>>西瓜資料集3.0α
X=np.array([[0.697,0.46],[0.774,0.376],[0.634,0.264],[0.608,0.318],[0.556,0.215],
[0.403,0.237],[0.481,0.149],[0.437,0.211],[0.666,0.091],[0.243,0.267],
[0.245,0.057],[0.343,0.099],[0.639,0.161],[0.657,0.198],[0.36,0.37],
[0.593,0.042],[0.719,0.103]])
Y=np.array([1,1,1,1,1,1,1,1,-1,-1,-1,-1,-1,-1,-1,-1,-1])
#>>>>>Bagging
T=20
H=[] #存盤各個決策樹樁,每行表示#劃分特征,劃分點,左枝取值,右枝取值
m=len(Y)
H_pre=np.zeros(m) #存盤每次迭代后H對于訓練集的預測結果
error=[] #存盤每次迭代后H的訓練誤差
for t in range(T):
boot_strap_sampling=np.random.randint(0,m,m)
Xbs=X[boot_strap_sampling]
Ybs=Y[boot_strap_sampling]
h=tree.DecisionTreeClassifier().fit(Xbs,Ybs)
H.append(h)
# 計算并存盤當前步的訓練誤差
H_pre+=h.predict(X)
Y_pre=(H_pre>=0)*2-1
error.append(sum(Y_pre!=Y)/m)
#>>>>>繪制訓練誤差變化曲線
plt.title('訓練誤差的變化')
plt.plot(range(1,T+1),error,'o-',markersize=2)
plt.xlabel('基學習器個數')
plt.ylabel('錯誤率')
plt.show()
#>>>>>觀察結果
x1min,x1max=X[:,0].min(),X[:,0].max()
x2min,x2max=X[:,1].min(),X[:,1].max()
x1=np.linspace(x1min-(x1max-x1min)*0.2,x1max+(x1max-x1min)*0.2,100)
x2=np.linspace(x2min-(x2max-x2min)*0.2,x2max+(x2max-x2min)*0.2,100)
X1,X2=np.meshgrid(x1,x2)
for t in [3,5,11]:
plt.title('前%d個基學習器'%t)
plt.xlabel('密度')
plt.ylabel('含糖量')
# 畫樣本資料點
plt.scatter(X[Y==1,0],X[Y==1,1],marker='+',c='r',s=100,label='好瓜')
plt.scatter(X[Y==-1,0],X[Y==-1,1],marker='_',c='k',s=100,label='壞瓜')
plt.legend()
# 畫基學習器劃分邊界
for i in range(t):
#由于sklearn.tree類中將決策樹的結構引數封裝于內部,
#不方便提取,這里采用一個笨辦法:
#用predict方法對區域內所有資料點(100×100)進行預測,
#然后再用plt.contour的方法來找出劃分邊界
Ypre=predict([H[i]],X1,X2)
plt.contour(X1,X2,Ypre,colors='k',linewidths=1,levels=[0])
# 畫集成學習器劃分邊界
Ypre=predict(H[:t],X1,X2)
plt.contour(X1,X2,Ypre,colors='r',linewidths=5,levels=[0])
plt.show()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/131605.html
標籤:其他
上一篇:使用Python調整影像大小