試答系列:“西瓜書”-周志華《機器學習》習題試答
系列目錄
[第01章:緒論]
[第02章:模型評估與選擇]
[第03章:線性模型]
[第04章:決策樹]
[第05章:神經網路]
[第06章:支持向量機]
第07章:貝葉斯分類器
第08章:集成學習
第09章:聚類
第10章:降維與度量學習
第11章:特征選擇與稀疏學習
第12章:計算學習理論(暫缺)
第13章:半監督學習
第14章:概率圖模型
(后續章節更新中...)
目錄
- 7.1 試使用極大似然法估算西瓜資料集3.0中前三個屬性的類條件概率,
- 7.2 試證明:條件獨立性假設不成立時,樸素貝葉斯分類器仍有可能產生最優貝葉斯分類器,
- 7.3 試編程實作拉普拉斯修正的樸素貝葉斯分類器,并以西瓜資料集3.0為訓練集,對p151“測1”樣本進行判別,
- 7.4 實踐中使用式(7.15)決定分類類別時,若資料的維度非常高,則概率連乘$\Pi_{i=1}^dP(x_i|c)$的結果通常會非常接近于0從而導致下溢,試述防止下溢的可能方案,
- 7.5 試證明:二分類任務中兩類資料滿足高斯分布且方差相同時,線性判別分析產生貝葉斯最優分類器,
- 7.6 試編程實作AODE分類器,并以西瓜資料集3.0為訓練集,對p.151的“測1”樣本進行判別,
- 7.7 給定d個二值屬性的二分類任務,假設對于任何先驗概率項的估算至少需30個樣例,則在樸素貝葉斯分類器式(7.15)中估算先驗概率項$P(c)$需30×2=60個樣例,試估計在AODE式(7.23)中估算先驗概率$P(c,x_i)$所需的樣例數(分別考慮最好和最壞情形),
- 7.8 考慮圖7.3,試證明:在同父結構中,若x1的取值未知,則x3⊥x4不成立;在順序結構中,y⊥z|x,但y⊥z不成立,
- 7.9 以西瓜資料集2.0為訓練集,試基于BIC準則構建一個貝葉斯網,
- 1、貝葉斯網路結構在計算機中的表示,
- 2、BIC評分函式,
- 3、搜索演算法,
- 4、計算結果,
- 7.10 以西瓜資料集2.0中屬性“臍部”為隱變數,試基于EM演算法構建一個貝葉斯網,
- 1、EM演算法總結
- 2. 本題解答思路,
- 3. EM演算法下計算網路引數和BIC評分函式,
- 4.編程計算
- 5.結果討論
- 附:編程代碼
- 習題7.3(Python)
- 習題7.6(Python)
- 習題7.9(Python)
- 習題7.10(Python)
7.1 試使用極大似然法估算西瓜資料集3.0中前三個屬性的類條件概率,
答:只需對西瓜資料集3.0中具體相同類別和屬性取值的樣本進行計數即可得到前三個屬性的類條件概率:
P青綠|是=3/8,P烏黑|是=4/8,P淺白|是=3/8,P青綠|否=3/9,P烏黑|否=2/9,P淺白|否=4/9;
P蜷縮|是=5/8,P稍蜷|是=3/8,P硬挺|是=0/8,P蜷縮|否=3/9,P稍蜷|否=4/9,P硬挺|否=2/9;
P濁響|是=6/8,P沉悶|是=2/8,P清脆|是=0/8,P濁響|否=4/9,P沉悶|否=3/9,P清脆|否=2/9;
7.2 試證明:條件獨立性假設不成立時,樸素貝葉斯分類器仍有可能產生最優貝葉斯分類器,
答:可以參考“閱讀材料”部分的解釋,(待完善)
1、對分類任務來說,只需各類別的條件概率排序正確、無須精準概率值即可導致正確分類結果,
2、若屬性間依賴對所有類別影響相同,或依賴關系的影響能相互抵消,則屬性條件獨立性假設在降低計算開銷的同時不會對性能產生負面影響,
7.3 試編程實作拉普拉斯修正的樸素貝葉斯分類器,并以西瓜資料集3.0為訓練集,對p151“測1”樣本進行判別,
答: 代碼附后,
其中撰寫了函式c=nb(x,X,Y,laplace=True),可以通過引數laplace選擇是否進行拉普拉斯修正,將其設為False時,可以將計算結果與教材計算結果進行對比,對比發現,教材中對于連續型屬性-----密度和含糖率的正態分布引數估計中,對于方差的估計采用了無偏估計,亦即\(\sigma_{c,i}^{2}=\frac{1}{|D_c|-1}\sum_{x\in D_c}(x-\mu_{c,i})^2\),
7.4 實踐中使用式(7.15)決定分類類別時,若資料的維度非常高,則概率連乘\(\Pi_{i=1}^dP(x_i|c)\)的結果通常會非常接近于0從而導致下溢,試述防止下溢的可能方案,
答: 通常采用取對數的方法將連乘變為連加:\(\Pi_{i=1}^dP(x_i|c)\rightarrow log[\Pi_{i=1}^dP(x_i|c)]=\Sigma_{i=1}^dlogP(x_i|c)\)
7.5 試證明:二分類任務中兩類資料滿足高斯分布且方差相同時,線性判別分析產生貝葉斯最優分類器,
答:假設資料滿足高斯分布:\(P(x|c)\sim N(\mu_c,\Sigma)\),模型中需要確定的引數有均值\(\mu_1\)和\(\mu_0\),以及共同的方差\(\Sigma\),\(\Sigma\)為對稱正定矩陣,資料集的對數似然為:
\[\begin{aligned} LL(\mu_1,\mu_0,\Sigma)&=\sum_ilogP(x_i|c_i)\\ &=\sum_ilog\{\frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}}exp[-\frac{1}{2}(x_i-\mu_{c_i})^T\Sigma^{-1}(x_i-\mu_{c_i})]\} \end{aligned} \]通過最大化對數似然可以求得引數估計:
\[\begin{aligned} \nabla_{\mu_c}LL=0 &\Rightarrow \mu_c=\frac{1}{|D_c|}\sum_{x_i \in D_c}x_i\\ \nabla_{\Sigma^{-1}}LL=0 &\Rightarrow \Sigma=\frac{1}{m}\sum_i(x_i-\mu_{c_i})(x_i-\mu_{c_i})^T \end{aligned} \]上式中求取\(\Sigma^{-1}\)梯度時應用了關系\(\nabla_A|A|=|A|(A^{-1})^T\),
那么,該貝葉斯分類器的決策函式為:
對于二分類任務,這等價于:
\[\begin{aligned} h_{Bayes}(x)&=sign[P(1)P(x|1)-P(0)P(x|0)]\\ &=sign\{exp[-\frac{1}{2}(x-\mu_1)^T\Sigma^{-1}(x-\mu_1)]-exp[-\frac{1}{2}(x-\mu_0)^T\Sigma^{-1}(x-\mu_0)]\}\\ &=sign[\mu_0^T\Sigma^{-1}\mu_0-\mu_1^T\Sigma^{-1}\mu_1+2(\mu_1-\mu_0)^T\Sigma^{-1}x] \end{aligned} \]上式中第二行采取了同先驗假設,亦即P(0)=P(1)=1/2.
在3.4節線性判別分析(LDA)中,關于\(\mu_1,\mu_0\)的定義與上面求得的\(\mu_c\)完全相同,而根據(3.33)式可知,\(S_w=m\Sigma\),在3.4節中求得最優投影直線方向為\(w=S_w^{-1}(\mu_0-\mu_1)\), LDA對于新資料的分類是根據投影點距離兩個投影中心的距離遠近決定的,可以將其表達為:
注意到上式第二行右邊項\(w^T(\mu_1-\mu_0)=-(\mu_1-\mu_0)^TS_w^{-1}(\mu_1-\mu_0)\),而\(S_w\)為對稱正定矩陣,因此該項恒為負,因此,上式可以進一步化簡為:
\[\begin{aligned}h_{LDA}(x) &=sign[w^T(\mu_1+\mu_0)-2w^Tx]\\ &=sign[(\mu_0-\mu_1)^T\Sigma^{-1}(\mu_1+\mu_0-2x)]\\ &=sign[\mu_0^T\Sigma^{-1}\mu_0-\mu_1^T\Sigma^{-1}\mu_1+2(\mu_1-\mu_0)^T\Sigma^{-1}x] \end{aligned}\]對比可知,決策函式\(h_{Bayes}(x)\)和\(h_{LDA}(x)\)完全相同,因此可以說LDA產生了最優Bayes分類,
7.6 試編程實作AODE分類器,并以西瓜資料集3.0為訓練集,對p.151的“測1”樣本進行判別,
答: 編程代碼附后,
在實作AODE分類器程序中,需要應用(7.23)~(7.25)式計算各個概率值,由于西瓜資料集3.0中含有連續屬性,需要對(7.24)和(7.25)計算式進行相應的拓展,
-
對于(7.24)式,若\(x_i\)為連續屬性,則按下式計算:
\[P(c,x_i)=P(c)P(x_i|c)=\frac{|D_c|}{|D|}\cdot N(x_i|\mu_{c,i},\sigma_{c,i}^2) \]其中\(N\)為正態分布的概率密度函式,引數為\(N(x|\mu,\sigma^2)\),
-
對于(7.25)式,存在多種情況:
\[P(x_j|c,x_i)=N(x_j|\mu_{c,x_i;j},\sigma_{c,x_i;j}^2) \]
(a). 若\(x_i\)為離散屬性,\(x_j\)為連續屬性,此時:(b). 若\(x_i\)為連續屬性,\(x_j\)為離散屬性,此時:
\[\begin{aligned}P(x_j|c,x_i)&=\frac{P(x_i|c,x_j)P(c,x_j)}{P(c,x_i)}\\ &=N(x_i|\mu_{c,x_j;i},\sigma_{c,x_j;i}^2)\cdot\frac{P(c,x_j)}{P(c,x_i)} \end{aligned}\](c.). 若\(x_i\)為連續屬性,\(x_j\)為連續屬性,此時:
\[\begin{aligned} P(x_j|c,x_i)&=\frac{P(x_i,x_j|c)P(c)}{P(c,x_i)}\\ &=N[(x_i,x_j)|\mu_{c,(i,j)},\Sigma_{c,(i,j)}]\cdot\frac{P(c)}{P(c,x_i)} \end{aligned}\]需要注意的是,對于上面(a),(b)兩種情況下,求取正態分布引數時,可能因為子集\(D_{c,x_i}\)中樣本數太少而無法估計,在編程中,若樣本數為零,則假定為正態分布,亦即\(\mu=0,\sigma=1\);若僅一個樣本,則將平均值設為該唯一取值,方差設為1.
7.7 給定d個二值屬性的二分類任務,假設對于任何先驗概率項的估算至少需30個樣例,則在樸素貝葉斯分類器式(7.15)中估算先驗概率項\(P(c)\)需30×2=60個樣例,試估計在AODE式(7.23)中估算先驗概率\(P(c,x_i)\)所需的樣例數(分別考慮最好和最壞情形),
答:需要計算的先驗概率\(P(c,x_i)\)的數目共有2×2×d個,因為c有2個取值,i有d個取值,\(x_i\)有2個取值,
首先考慮屬性\(x_1\),對于引數\(P(c=0,x_1=0),P(c=0,x_1=1),P(c=1,x_1=0),P(c=1,x_1=1)\),分別需要30個樣例來估算,總計需要120個樣例,
在最好情形下,對于所有其他屬性\(x_i,i=2,3,…,d\),假設剛好能在c=0的60個樣例中找到30個\(x_i\)=0和30個\(x_i\)=1的樣例,同樣地,對于c=1的情況也如此,則無需更多樣例,此時對于所有屬性總計需要120個樣例;
在最壞情形下,比如對于屬性\(x_2\),假設60個c=0的樣例中\(x_2\)取值全部為0,則需要另外補充30個\(c=0,x_2=1\)的樣例,同樣的,對于c=1的情況,也需要補充30個樣例,考慮所有其他屬性,總共要補充60×(d-1)個樣例,這樣總計需要120+60(d-1)=60(d+1)個樣例,
因此,對于最好和最壞情形,分別需要樣例數120和60(d+1)個樣例,
7.8 考慮圖7.3,試證明:在同父結構中,若x1的取值未知,則x3⊥x4不成立;在順序結構中,y⊥z|x,但y⊥z不成立,
證明:
- 在同父結構中,假設x3⊥x4成立,則有:
\(P(x_3,x_4)=P(x_3)P(x_4)=\sum_{x_1}P(x_1)P(x_3|x_1)P(x_4)\)
另一方面有:
\(P(x_3,x_4)=\sum_{x_1}P(x_1,x_3,x_4)=\sum_{x_1}P(x_1)P(x_3|x_1)P(x_4|x_1)\)
兩式相減有:
\(\sum_{x_1}P(x_1)P(x_3|x_1)[P(x_4)-P(x_4|x_1)]=0\)
然而上式未必成立,因此x3⊥x4成立未必成立, - 在順序結構中,首先有聯合概率為:
\(P(x,y,z)=P(z)P(x|z)P(y|x)\)
可以證明:
\(P(y,z|x)=\frac{P(x,y,z)}{P(x)}=\frac{P(z)P(x|z)P(y|x)}{P(x)}=\frac{P(x,z)P(y|x)}{P(x)}=P(z|x)P(y|x)\)
上式即表明 z⊥y | x.
至于z⊥y是否成立,先假設其成立,則有:
\(P(y,z)=P(y)P(z)=P(z)\sum_xP(y|x)P(x)\)
又因為:
\(P(y,z)=\sum_xP(x,y,z)=\sum_xP(z)P(x|z)P(y|x)=P(z)\sum_xP(x|z)P(y|x)\)
兩式相減有:
\(\sum_xP(y|x)[P(x)-P(x|z)]=0\)
然而上式未必成立,因此z⊥y未必成立,
7.9 以西瓜資料集2.0為訓練集,試基于BIC準則構建一個貝葉斯網,
答:
1、貝葉斯網路結構在計算機中的表示,
首先,我們約定一下如何在計算機中表達一個貝葉斯網路:設有\(n\)個節點,\(x_1,x_2,…,x_n\),利用\(B\in R^{n×n}\)矩陣的右上角元素來表達連接邊,右上角元素\(B_{ij}\)可能取值為0,1,-1,取值0意味著\(x_i\)與\(x_j\)之間沒有連接邊,等于1意味著\(x_i \rightarrow x_j\)的連接邊,等于-1意味著\(x_i \leftarrow x_j\)的連接邊,比如,將下圖中的貝葉斯網路用矩陣表達為:
2、BIC評分函式,
在貝葉斯網路中,對于某個節點\(x_i\),設它的可能取值數目為\(r_i\),它的父節點集為\(\pi_i\),父節點取值的可能組合數目為\(q_i\),在資料集D中,父節點集\(\pi_i\)取值組合為第\(j\)種組合的樣本數目為\(m_{ij}\),與此同時,節點\(x_i\)取第\(k\)個值的樣本數為\(m_{ijk}\),
那么,對于某個網路結構B,它的BIC評分函式計算公式可以表示[1]:
下面試著對上式進行詳細說明,
我們用\(\theta_{ijk}=P(x_i=k|\pi_i=j)\)來表示網路引數:對于第i個結點,父節點取值為第j種組合,并且該結點取第k個離散值的概率,\(\theta_{ijk}\)對應于第i格概率表,第j行,第k列的取值,如下圖所示:

BIC評分公式右邊第一項為結構風險項,|B|表示網路中的引數數目,對于結點xi處的概率表包含\(q_ir_i\)個引數,但是考慮到概率表存在歸一化的約束條件:\(\Sigma_k\theta_{ijk}=1\),因此,獨立的引數個數有\(q_i(r_i-1)\)個,
第二項為經驗風險項:負對數似然概率,下面試著對其進行詳細推導:
上式是對很多個概率值對數\(logθ_{ijk}\)的累加求和,其計算結果必然是這樣的形式:
\[LL(B|D)=\sum_i\sum_j\sum_km_{ijk}log\theta_{ijk}\tag{3} \]其中\(m_{ijk}\)為正整數,它的意義恰好代表:對于某個節點\(x_i\),父節點集\(\pi_i\)取第j種組合,節點\(x_i\)取第k個離散值的樣本數,
考慮到網路引數\(θ_{ijk}\)應該滿足約束條件:\(\Sigma_k\theta_{ijk}=1\),利用帶等式約束的拉格朗日方法對似然函式求取極大值來求解網路引數:
其中\(\lambda_{ij}\)為拉格朗日引數,對上式求導數,并令其等于零:
\[\begin{aligned} &\frac{\partial L}{\partial\theta_{ijk}}=\frac{m_{ijk}}{\theta_{ijk}}-\lambda_{ij}=0\\ &\Rightarrow \theta_{ijk}=\frac{m_{ijk}}{\lambda_{ij}} \end{aligned}\tag{5}\]考慮約束條件\(\sum_k\theta_{ijk}=1\),可以得到\(\lambda_{ij}=\sum_k m_{ijk}=m_{ij}\),這里\(m_{ij}\)恰好代表著對于某個節點\(x_i\),父節點集\(π_i\)取第j種組合的樣本數,因此,網路引數為:
\[\theta_{ijk}=\frac{m_{ijk}}{m_{ij}}\tag{6} \]這就是為什么在固定網路結構下,網路引數簡單地等于對應取值樣本的“計數”,
將網路引數(6)帶回到前面的(3)式即得到:
3、搜索演算法,
我們的目標是搜尋BIC評分最小化的貝葉斯網路結構,這里采用下山法進行搜索,每一步隨機選取一個邊進行調整,調整包括三種操作[1:1]:加邊、減邊、轉向,需要注意的是,加邊和轉向后可能會引入環,要予以避免,
如果新網路的BIC評分結果更低,則進行更新,否則維持原網路,同時允許一個較小的概率調整為BIC分值更大的網路,演算法如下:
初始化網路結構B,
設定引數eta和tao,
for loop in range(step):
隨機選取需要調整連接邊的兩個節點xi和xj,
對Bij值進行修改,
if 新網路有環:
continue
if BIC值減小 or rand()<eta*exp(-loop/tao):
更新網路,輸出當前BIC值
else:
continue
輸出最終得到的網路結構和引數,
詳細的編程代碼附后,
說明一點:觀察前面的BIC評分函式計算式可以發現,總的BIC分值為各個節點處BIC分值之和,因此,在比較調整前后BIC分值變化時,由于網路僅在節點xi和xj處發生變化,為了減小計算量,可以僅計算這兩個節點處的BIC分值進行比較,
4、計算結果,
下面是在西瓜資料集2.0上某一次運行的結果:
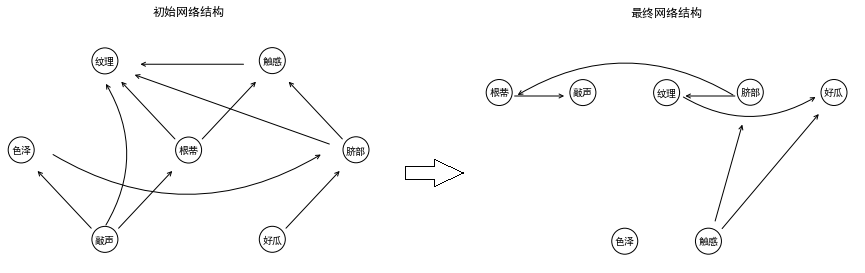
初始BIC評分:277.572(結構203.991,經驗73.580)
最終BIC評分:119.360(結構 43.915,經驗75.445)
多次運行,在不同初始網路的情況下,結果均表現出一個規律:“色澤”是一個獨立的屬性,是否是“好瓜”主要由“紋理”和“觸感”兩個屬性決定,
7.10 以西瓜資料集2.0中屬性“臍部”為隱變數,試基于EM演算法構建一個貝葉斯網,
答:
1、EM演算法總結
先來總結一下EM演算法,大概是這么回事:我們要建立一個概率模型,它具有引數θ,能夠告訴我們任意一種變數取值下的概率分布,但是這個模型所涉及的變數中既包含可觀測變數X,又包含不可觀測變數Z(或者說隱變數),在利用關于X的資料集D來估計引數θ時只能采用“邊際似然”最大化:
\[max LL(\theta|X)=logP(X|\theta)=log\sum_zP(X,Z|\theta)\tag{1} \]按理說,求上式的極大便可以得到所需估計的引數θ,但是上式往往求解較為困難,于是便有了EM演算法,
按照周志華《機器學習》上的介紹,沒有過多的推導,完全是一種直觀的認識,很容易理解,EM演算法是重復以下兩個步驟:假如已經知道了引數θ,便可以根據引數θ來估計隱變數Z的分布P(Z|X;θ)或者最佳取值,這便是E步驟(求期望);假設知道了隱變數Z的分布或者最佳取值,便可以按照完整資料的極大似然的方法來求解θ,這便是M步(求極大),
但是在其他很多書籍中,介紹的EM演算法是這樣推導得到的:
上式中Q(Z)是關于Z的一個分布,EM演算法程序為:
\[E-Step: Q(z)=P(z|X;\theta)\tag{2} \]\[M-Step:\theta=argmax_\theta\sum_{i=1}^m\sum_zQ^{(i)}(z)log(\frac{P(X^{(i)},z;\theta)}{Q^{(i)}(z)})\tag{3} \]將上式與教材中的(7.37)式對比,貌似不同,實際上兩者是等價的,說明如下:
教材中的(7.36)式可以詳細表達為:
上式中將教材中所采用的字母Q改為ELL,以防與前文中的Q(Z)相混淆;
將教材中表示引數的Θ換成小寫θ表示,以與前文保持一致,
上式是對于單個樣本而言的,對于m個樣本有:
然后(7.37)式即為:
\[\begin{aligned} \theta^{t+1}&=argmax_\theta ELL(\theta|\theta^t)\\ &=argmax_\theta \sum_{i=1}^m\sum_ZQ^{(i)}(Z)logP(X^{(i)},Z;\theta) \end{aligned}\tag{4}\]由于在M步驟中將\(Q^{(i)}(Z)\)視為常量,所以(4)式和(3)式所得到的\(θ^{(t+1)}\)完全一樣,
2. 本題解答思路,
具體在貝葉斯網路模型中情況又有所不同,除了計算網路引數,還需要搜索網路結構,回顧上一題7.9中,基于BIC準則搜索最佳貝葉斯網路,演算法中主要關注于網路結構的搜索,而網路引數的確定則通過簡單計數來確定,并隱含在BIC評分函式中,
上題中的演算法流程為:

本題解答采用完全一樣的演算法流程,只不過在計算BIC分值這個步驟需要多做一些作業,此時需要(同樣是在固定的網路結構下)通過EM演算法來確定網路引數,然后再計算出BIC評分分值,
3. EM演算法下計算網路引數和BIC評分函式,
本題中將屬性“臍部”作為隱變數,單個隱變數的情況應該較為簡單,下面具體分析,
3.1 E-Step: 求取P(Z|X,θ),也就是說,根據當前的網路引數來確定“臍部”的條件概率分布,“臍部”分別取值凹陷、平坦、稍凹的概率是多少,
上式中多處引入正比例符號∝,這是因為只需要計算z在各種取值下的相對概率大小,然后再進行歸一化即可,因此與z無關的部分,或者說對于所有z相同的部分可以不予考慮,
上式中倒數第二行對\(x_i\)的求積是對所有結點的求積,包括隱變數結點z,這些乘積因子中只有z結點及其子節點與z有關,其中son(z)是指結點z的子結點,因此,隱變數的條件概率僅與隱變數結點本身及其子結點處的網路引數(概率表)有關,
比如,在下圖的網路結構中,只有Z結點和\(X_5\)結點處的概率表影響Q(z)的計算結果,

3.2 M-Step: 根據上一步所確定的Q(z),通過最大化似然函式的期望來求取網路引數,
與前邊一樣,上式中從第2行開始對i的求和是指對所有結點的求和,這其中包括了隱變數結點Z;而對z的求和是指對z不同取值的求和,
其中網路引數\(θ_{i,j,k}\)與上一題7.9中的含義一樣:對于第i個結點,父節點取值為第j種組合,并且該結點取第k個離散值的概率,
若令:
其中\(\mathbf {II}(·)\)是指示函式,與教材中含義相同,表示在\(\{Q_s^{(s)}\}\)分布下,結點xi取第k個離散值,對應的父節點取第j種組合的樣本數的期望,當xi是隱結點或者其子結點時,πi或者xi的取值與z有關,分布Qz會影響到相應結果,對于其他結點,Qz分布與之無關,\(\overline m_{ijk}\)變為\(m_{ijk}\),
那么,前面的式子可以繼續表示為:
與7.9題中求取網路引數的程序完全一樣,我們可以得到網路引數為:
\[\begin{aligned} \theta_{ijk}^{t+1}&=argmax_\theta ELL(\theta|\theta^t)\\ &=\frac{\overline m_{ijk}}{\sum_k \overline m_{ijk}}\\ &=\frac{\overline m_{ijk}}{\overline m_{ij}} \end{aligned}\tag{6}\]注意到,z的不同取值分布只會影響到隱結點z本身以及它的子節點處\(\overline m_{ijk}\)的數值,因此,僅隱結點及其子節點處的網路引數會進行更新,其余結點處的網路引數始終保持不變,
3.3 合并E-step和M-step程序
EM演算法需要不斷的重復E-step和M-step兩個程序,在這個程序中,Qz和θ不斷地被更新:
Qz相較于θ引數方便于表示和存盤,可以將Qz存盤于m×|z|的矩陣中,|z|為z的狀態數,我們可以將這兩個程序合并,直接考察Qz隨著迭代程序的變化規律:
Qz0→Qz1→Qz2→...
將(5)式和(6)式進行合并,比如對于第r個樣本,z取值z1的分布更新為:
\[\begin{aligned} Q^{[t+1](r)}(z=z_1)&\propto P(X^{(r)},z=z_1;\theta)\\ &=\prod_i P(x_i^{(r)}|\pi_i^{(r)})\\ &=\prod_i\theta_{i,\pi_i^{(r)},x_i^{(r)}}\\ &=\prod_i\frac{\overline m_{i,\pi_i^{(r)},x_i^{(r)}}}{\overline m_{i,\pi_i^{(r)}}}\\ &\propto\overline m_{z,\pi_z^{(r)},z_1}\prod_{i\in son(z)}\frac{\overline m_{i,\pi_i^{(r)},x_i^{(r)}}}{\overline m_{i,\pi_i^{(r)}}} \end{aligned}\]上式第二行開始對i的求和包括對Z結點,其中隱含了z=z1(暫未發現恰當的表示方法),最后一行只取其中與z有關的項:z結點處的mijk與z有關,而mij與z無關,z子結點的mijk和mij都與z有關,比如具體來說,對于下圖中的貝葉斯網路,Z結點的子結點只有x5,那么有:

在第t+1步更新Qz時的演算法總結如下:
輸入:上一步得到的Qz
資料集D
Z結點的子結點索引號son(z)
各個結點的父結點索引號πi
程序:
NewQz=ones(size(Qz)) #新的Qz初始化為全1矩陣
#考察Z結點
for j in |πz|: #遍歷Z結點父結點的所有取值組合
Index=第j種取值的樣本索引號
NewQz[index]*=sum(Qz[index])
#考察Z的子結點
for i in son(z): #遍歷Z的子結點
for j in |πi+xi-z|: #遍歷(父結點+xi結點-z結點)的所有取值組合
Index=第j種取值的樣本索引號
NewQz[index]*=sum(Qz[index])
for j in |πi-z|: #遍歷(父結點-z結點)的所有取值組合
Index=第j種取值的樣本索引號
NewQz[index]/=sum(Qz[index])
NewQz/=sum(NewQz,axis=1)
Qz=NewQz
3.4 BIC評分函式
上題7.9中的BIC評分函式包含結構項和經驗項,其中結構項保持不變,將經驗項由“似然函式”變為“邊際似然函式”:
其中結構項部分與上題完全一樣,其中ri表示結點xi的可能取值數目,qi為父節點集取值可能組合數目,
下面著重分析經驗項部分:
當EM演算法收斂時,對于最終的網路引數θ和隱變數分布\(\{Q_z^{(s)}\}\),上式最后一行的不等式取等號,上式進一步化簡為:
\[\begin{aligned} LL(B|D)&=\sum_{s=1}^m\sum_z Q_z^{(s)} log P(X^{(s)},z|\theta)-\sum_{s=1}^m\sum_z Q_z^{(s)} log Q_z^{(s)}\\ &=\sum_{s=1}^m\sum_z Q_z^{(s)} \sum_i log P(X_i^{(s)}|\pi_i^{(s)})-\sum_{s=1}^m\sum_z Q_z^{(s)} log Q_z^{(s)}\\ &=\sum_i\sum_j\sum_k\overline m_{ijk}log\theta_{ijk}-\sum_{s=1}^m\sum_z Q_z^{(s)} log Q_z^{(s)}\\ &=\sum_i\sum_j\sum_k\overline m_{ijk}log\frac{\overline m_{ijk}}{\overline m_{ij}}-\sum_{s=1}^m\sum_z Q_z^{(s)} log Q_z^{(s)}\\ &=\sum_i\sum_j\sum_k\overline m_{ijk}log\overline m_{ijk}-\sum_i\sum_j\overline m_{ij}log\overline m_{ij}-\sum_{s=1}^m\sum_z Q_z^{(s)} log Q_z^{(s)}\\ \end{aligned}\]觀察上式,前兩項仍然是對各個結點求和的形式,第三項僅與隱結點z的取值分布函式Q(z)有關,
4.編程計算
代碼附后,在上一題代碼的基礎上增加EM演算法以及新的BIC評分函式計算方法,
說明幾點:
① 設定不同的初始值,EM演算法可能收斂到不同的結果,可以嘗試不同的初始值,最后取邊際似然最大的結果,
② 在更新Qz的程序中,將θ的更新隱含在其中,\(\theta_{ijk}=\frac{\overline m_{ijk}}{\overline m_{ij}}\),當計算到的mij=0時,會出現0/0的錯誤,這可以通過laplace修正來解決,但在這里,我采取在mij上統一加一個較小的數,比如1E-100,來避免錯誤,
③ 在調整網路結構后,如果隱結點及其子結點處概率表不發生變化,可以無需運行EM演算法來求取Qz,BIC評分只涉及到有限幾個結點處的變化,可以利用這些特點來減少計算量,
5.結果討論
從前面的分析可以看出,z的不同取值具有對稱性,也就是我們讓z1=“凹陷”還是“平坦”無關緊要,起影響作用的只有z的狀態數(可能取值數目),本題中狀態數為3,計算到的Qz也可以在不同狀態之間進行輪換,比如Qz→Qz[:,[2,0,1]],不影響結果,
BIC評分包含兩部分,結構項和經驗項,與其他演算法類似,可以通過系數來調整兩者的相對比重:BIC_score=struct*alpha+emp,下面是設定不同alpha值的情況下搜索到的貝葉斯網路結構:

結果表明:alpha越大,結構項比重越大,搜索到的結構越簡單,alpha越小,搜索到的結構越復雜;alpha=1時,結果表明“臍部”為一個獨立屬性,alpha取其他值時,“臍部”均作為多個屬性的根屬性,
附:編程代碼
習題7.3(Python)
# -*- coding: utf-8 -*-
"""
Created on Thu Jan 9 09:53:04 2020
@author: MS
"""
import numpy as np
def nb(x,X,Y,laplace=True):
#樸素貝葉斯分類器
# x 待預測樣本
# X 訓練樣本特征值
# Y 訓練樣本標記
# laplace 是否采用“拉普拉斯修正”,默認為真
C=list(set(Y)) #所有可能標記
p=[] #存盤概率值
print('===============樸素貝葉斯分類器===============')
for c in C:
Xc=[X[i] for i in range(len(Y)) if Y[i]==c] #c類樣本子集
pc=(len(Xc)+laplace)/(len(X)+laplace*len(C)) #類先驗概率
print('P(c=%s)=%.3f;\nP(xi|c=%s)='%(c,pc,c),end='')
logp=np.log(pc) #對數聯合概率P(x,c)
for i in range(len(x)):
if type(x[i])!=type(X[0][i]):
print(
'樣本資料第%d個特征的資料型別與訓練樣本資料型別不符,無法預測!'%(i+1))
return None
if type(x[i])==str:
# 若為字符型特征,按離散取值處理
Xci=[1 for xc in Xc if xc[i]==x[i]] #c類子集中第i個特征與待預測樣本一樣的子集
pxc=(len(Xci)+laplace)/(len(Xc) #pxc為類條件概率P(xi|c)
+laplace*len(set([x[i] for x in X])))
print('%.3f'%pxc,end=',')
elif type(x[i])==float:
# 若為浮點型特征,按高斯分布處理
Xci=[xc[i] for xc in Xc]
u=np.mean(Xci)
sigma=np.std(Xci,ddof=1)
pxc=1/np.sqrt(2*np.pi)/\
sigma*np.exp(-(x[i]-u)**2/2/sigma**2)
print('%.3f(~N(%.3f,%.3f^2))'%(pxc,u,sigma),end=',')
else:
print('目前只能處理字符型和浮點型資料,對于其他型別有待擴展相應功能,')
return None
logp+=np.log(pxc)
p.append(logp)
print(';\nlog(P(x,c=%s))=log(%.3E)=%.3f\n'%(c,np.exp(logp),logp))
predict=C[p.index(max(p))]
print('===============預測結果:%s類==============='%predict)
return predict
#====================================
# 主程式
#====================================
# 表4.3 西瓜資料集3.0
#FeatureName=['色澤','根蒂','敲聲','紋理','臍部','觸感','密度','含糖率']
#LabelName={1:'好瓜',0:'壞瓜'}
X=[['青綠','蜷縮','濁響','清晰','凹陷','硬滑',0.697,0.460],
['烏黑','蜷縮','沉悶','清晰','凹陷','硬滑',0.774,0.376],
['烏黑','蜷縮','濁響','清晰','凹陷','硬滑',0.634,0.264],
['青綠','蜷縮','沉悶','清晰','凹陷','硬滑',0.608,0.318],
['淺白','蜷縮','濁響','清晰','凹陷','硬滑',0.556,0.215],
['青綠','稍蜷','濁響','清晰','稍凹','軟粘',0.403,0.237],
['烏黑','稍蜷','濁響','稍糊','稍凹','軟粘',0.481,0.149],
['烏黑','稍蜷','濁響','清晰','稍凹','硬滑',0.437,0.211],
['烏黑','稍蜷','沉悶','稍糊','稍凹','硬滑',0.666,0.091],
['青綠','硬挺','清脆','清晰','平坦','軟粘',0.243,0.267],
['淺白','硬挺','清脆','模糊','平坦','硬滑',0.245,0.057],
['淺白','蜷縮','濁響','模糊','平坦','軟粘',0.343,0.099],
['青綠','稍蜷','濁響','稍糊','凹陷','硬滑',0.639,0.161],
['淺白','稍蜷','沉悶','稍糊','凹陷','硬滑',0.657,0.198],
['烏黑','稍蜷','濁響','清晰','稍凹','軟粘',0.360,0.370],
['淺白','蜷縮','濁響','模糊','平坦','硬滑',0.593,0.042],
['青綠','蜷縮','沉悶','稍糊','稍凹','硬滑',0.719,0.103]]
Y=[1]*8+[0]*9
x=['青綠','蜷縮','濁響','清晰','凹陷','硬滑',0.697,0.460] #測驗例"測1"
print("測1樣本:")
nb(x,X,Y,False) #此時不用拉普拉斯修正,方便與教材對比計算結果
#若用拉普拉斯修正,可以去掉最后一個引數,或者設定為True
#任意設定一個新的"測例"
x=['淺白','蜷縮','沉悶','稍糊','平坦','硬滑',0.5,0.1]
print("\n任設的一個新測例,觀察結果:")
nb(x,X,Y)
習題7.6(Python)
# -*- coding: utf-8 -*-
"""
Created on Thu Jan 9 09:53:04 2020
@author: MS
"""
import numpy as np
def AODE(x,X,Y,laplace=True,mmin=3):
#平均獨依賴貝葉斯分類器
# x 待預測樣本
# X 訓練樣本特征值
# Y 訓練樣本標記
# laplace 是否采用“拉普拉斯修正”,默認為真
# mmin 作為父屬性最少需要的樣本數
C=list(set(Y)) #所有可能標記
N=[len(set([x[i] for x in X])) for i in range(len(x))] #各個屬性的可能取值數
p=[] #存盤概率值
print('===============平均獨依賴貝葉斯分類器(AODE)===============')
for c in C:
#--------求取類先驗概率P(c)--------
Xc=[X[i] for i in range(len(Y)) if Y[i]==c] #c類樣本子集
pc=(len(Xc)+laplace)/(len(X)+laplace*len(C)) #類先驗概率
print('P(c=%s)=%.3f;'%(c,pc))
#--------求取父屬性概率P(c,xi)--------
p_cxi=np.zeros(len(x)) #將計算結果存盤在一維向量p_cxi中
for i in range(len(x)):
if type(x[i])!=type(X[0][i]):
print(
'樣本資料第%d個特征的資料型別與訓練樣本資料型別不符,無法預測!'%(i+1))
return None
if type(x[i])==str:
# 若為字符型特征,按離散取值處理
Xci=[1 for xc in Xc if xc[i]==x[i]] #c類子集中第i個特征與待預測樣本一樣的子集
p_cxi[i]=(len(Xci)+laplace)/(len(X)
+laplace*len(C)*N[i])
elif type(x[i])==float:
# 若為浮點型特征,按高斯分布處理
Xci=[xc[i] for xc in Xc]
u=np.mean(Xci)
sigma=np.std(Xci,ddof=1)
p_cxi[i]=pc/np.sqrt(2*np.pi)/\
sigma*np.exp(-(x[i]-u)**2/2/sigma**2)
else:
print('目前只能處理字符型和浮點型資料,對于其他型別有待擴展相應功能,')
return None
print(''.join(['p(c=%d,xi)='%c]+['%.3f'%p_cxi[i]+
(lambda i:';' if i==len(x)-1 else ',')(i) for i in range(len(x))]))
#--------求取父屬性條件依賴概率P(xj|c,xi)--------
p_cxixj=np.eye(len(x)) #將計算結果存盤在二維向量p_cxixj中
for i in range(len(x)):
for j in range(len(x)):
if i==j:
continue
#------根據xi和xj是離散還是連續屬性分為多種情況-----
if type(x[i])==str and type(x[j])==str:
Xci=[xc for xc in Xc if xc[i]==x[i]]
Xcij=[1 for xci in Xci if xci[j]==x[j]]
p_cxixj[i,j]=(len(Xcij)+laplace)/(len(Xci)+laplace*N[j])
if type(x[i])==str and type(x[j])==float:
Xci=[xc for xc in Xc if xc[i]==x[i]]
Xcij=[xci[j] for xci in Xci]
#若子集Dc,xi數目少于2個,則無法用于估計正態分布引數,
#則將其設為標準正態分布
if len(Xci)==0:
u=0
else:
u=np.mean(Xcij)
if len(Xci)<2:
sigma=1
else:
sigma=np.std(Xcij,ddof=1)
p_cxixj[i,j]=1/np.sqrt(2*np.pi)/\
sigma*np.exp(-(x[j]-u)**2/2/sigma**2)
if type(x[i])==float and type(x[j])==str:
Xcj=[xc for xc in Xc if xc[j]==x[j]]
Xcji=[xcj[i] for xcj in Xcj]
if len(Xcj)==0:
u=0
else:
u=np.mean(Xcji)
if len(Xcj)<2:
sigma=1
else:
sigma=np.std(Xcji,ddof=1)
p_cxixj[i,j]=1/np.sqrt(2*np.pi)/sigma*np.exp(-(x[i]-u)**2/2/sigma**2)*p_cxi[j]/p_cxi[i]
if type(x[i])==float and type(x[j])==float:
Xcij=np.array([[xc[i],xc[j]] for xc in Xc])
u=Xcij.mean(axis=0).reshape(1,-1)
sigma2=(Xcij-u).T.dot(Xcij-u)/(Xcij.shape[0]-1)
p_cxixj[i,j]=1/2*np.pi/np.sqrt(np.linalg.det(sigma2))\
*np.exp(-0.5*([x[i],x[j]]-u).
dot(np.linalg.inv(sigma2)).
dot(([x[i],x[j]]-u).T))*pc/p_cxi[i]
print(''.join([(lambda j:'p(xj|c=%d,x%d)='%(c,i+1)if j==0 else '')(j)
+'%.3f'%p_cxixj[i][j]
+(lambda i:';\n' if i==len(x)-1 else ',')(j)
for i in range(len(x)) for j in range(len(x))]))
#--------求計算總的概率∑iP(c,xi)*∏jP(xj|c,xi)--------
sump=0
for i in range(len(x)):
if len([1 for xi in X if xi[1]==x[1]])>=mmin:
sump+=p_cxi[i]*p_cxixj[i,:].prod()
print('P(c=%d,x) ∝ %.3E\n'%(c,sump))
p.append(sump)
#--------做預測--------
predict=C[p.index(max(p))]
print('===============預測結果:%s類==============='%predict)
return predict
#====================================
# 主程式
#====================================
# 表4.3 西瓜資料集3.0
#FeatureName=['色澤','根蒂','敲聲','紋理','臍部','觸感','密度','含糖率']
#LabelName={1:'好瓜',0:'壞瓜'}
X=[['青綠','蜷縮','濁響','清晰','凹陷','硬滑',0.697,0.460],
['烏黑','蜷縮','沉悶','清晰','凹陷','硬滑',0.774,0.376],
['烏黑','蜷縮','濁響','清晰','凹陷','硬滑',0.634,0.264],
['青綠','蜷縮','沉悶','清晰','凹陷','硬滑',0.608,0.318],
['淺白','蜷縮','濁響','清晰','凹陷','硬滑',0.556,0.215],
['青綠','稍蜷','濁響','清晰','稍凹','軟粘',0.403,0.237],
['烏黑','稍蜷','濁響','稍糊','稍凹','軟粘',0.481,0.149],
['烏黑','稍蜷','濁響','清晰','稍凹','硬滑',0.437,0.211],
['烏黑','稍蜷','沉悶','稍糊','稍凹','硬滑',0.666,0.091],
['青綠','硬挺','清脆','清晰','平坦','軟粘',0.243,0.267],
['淺白','硬挺','清脆','模糊','平坦','硬滑',0.245,0.057],
['淺白','蜷縮','濁響','模糊','平坦','軟粘',0.343,0.099],
['青綠','稍蜷','濁響','稍糊','凹陷','硬滑',0.639,0.161],
['淺白','稍蜷','沉悶','稍糊','凹陷','硬滑',0.657,0.198],
['烏黑','稍蜷','濁響','清晰','稍凹','軟粘',0.360,0.370],
['淺白','蜷縮','濁響','模糊','平坦','硬滑',0.593,0.042],
['青綠','蜷縮','沉悶','稍糊','稍凹','硬滑',0.719,0.103]]
Y=[1]*8+[0]*9
x=['青綠','蜷縮','濁響','清晰','凹陷','硬滑',0.697,0.460] #測驗例"測1"
print("測1樣本:")
AODE(x,X,Y) #此時不用拉普拉斯修正,方便與教材對比計算結果
#若用拉普拉斯修正,可以去掉最后一個引數,或者設定為True
#任意設定一個新的"測例"
x=['淺白','蜷縮','沉悶','稍糊','平坦','硬滑',0.5,0.1]
print("\n任設的一個新測例,觀察結果:")
AODE(x,X,Y)
習題7.9(Python)
# -*- coding: utf-8 -*-
"""
Created on Wed Jan 15 17:02:12 2020
@author: lsly
"""
import numpy as np
import matplotlib.pyplot as plt
#==============首先撰寫幾個函式,主程式見后==============
def relationship(net):
# 計算網路中的每個結點的父母結點以及父母以上的祖輩結點
# 輸入:
# net:array型別,網路結構,右上角元素ij表示各個連接邊
# 取值0表示無邊,取值1表示Xi->Xj,取值-1表示Xi<-Xj
# 輸出:
# parents:list型別,存盤各個結點的父節點編號,用取值1~N代表各個節點
# grands:list型別,存盤各個結點更深的依賴節點,可以看成是“祖結點”
# circle:list型別,存盤環節點編號,若圖中存在環,那么這個結點將是它本身的“祖結點”
N=len(net) #節點數
#-----確定父結點-----
parents=[list(np.where(net[i,:]==-1)[0]+1)+
list(np.where(net[:,i]==1)[0]+1)
for i in range(N)]
grands=[]
#-----確定“祖結點”-----
for i in range(N):
grand=[]
#---爺爺輩---
for j in parents[i]:
for k in parents[j-1]:
if k not in grand:
grand.append(k)
#---曾祖及以上輩---
loop=True
while loop:
loop=False
for j in grand:
for k in parents[j-1]:
if k not in grand:
grand.append(k)
loop=True
grands.append(grand)
#-----判斷環結點-----
circle=[i+1 for i in range(N) if i+1 in grands[i]]
return parents,grands,circle
def draw(net,name=None,title=''):
# 繪制貝葉斯網路的變數關系圖
# net:array型別,網路結構,右上角元素ij表示各個連接邊
# 取值0表示無邊,取值1表示Xi->Xj,取值-1表示Xi<-Xj
# name:指定各個節點的名稱,默認為None,用x1,x2...xN作為名稱
N=net.shape[0]
Level=np.ones(N,dtype=int)
#-----確定層級-----
for i in range(N):
for j in range(i+1,N):
if net[i][j]==1 and Level[j]<=Level[i]:
Level[j]+=1
if net[i][j]==-1 and Level[i]<=Level[j]:
Level[i]+=1
#-----確定橫向坐標-----
position=np.zeros(N)
for i in set(Level):
num=sum(Level==i)
position[Level==i]=np.linspace(-(num-1)/2,(num-1)/2,num)
#-----畫圖-----
plt.figure()
plt.title(title)
#設定出圖顯示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#--先畫出各個結點---
for i in range(N):
if name==None:
text='x%d'%(i+1)
else:
text=name[i]
plt.annotate(text,xy=[position[i],Level[i]],bbox={'boxstyle':'circle','fc':'1'},ha='center')
#--再畫連接線---
for i in range(N):
for j in range(i+1,N):
if net[i][j]==1:
xy=np.array([position[j],Level[j]])
xytext=np.array([position[i],Level[i]])
if net[i][j]==-1:
xy=np.array([position[i],Level[i]])
xytext=np.array([position[j],Level[j]])
if net[i][j]!=0:
L=np.sqrt(sum((xy-xytext)**2))
xy=xy-(xy-xytext)*0.2/L
xytext=xytext+(xy-xytext)*0.2/L
if (xy[0]==xytext[0] and abs(xy[1]-xytext[1])>1)or\
(xy[1]==xytext[1] and abs(xy[0]-xytext[0])>1):
arrowprops=dict(arrowstyle='->',connectionstyle='arc3,rad=0.3')
#畫弧線,避免遮擋(只考慮了橫向和豎向邊,暫未考慮斜向邊遮擋的情況)
else:
arrowprops=dict(arrowstyle='->')
plt.annotate('',xy=xy,xytext=xytext,arrowprops=arrowprops,ha='center')
plt.axis([position.min(),position.max(),Level.min(),Level.max()+0.5])
plt.axis('off')
plt.show()
def BIC_score(net,D,consider=None):
# 計算評分函式
# 輸入:
# net:貝葉斯網路
# D:資料集
# 輸出:
# [struct,emp]:評分函式的結構項和經驗項
#-----從資料集D中提取一些資訊-----
m,N=D.shape #樣本數和特征數
values=[np.unique(D[:,i])for i in range(len(D[0]))] #各個離散屬性的可能取值
#-----父節點-----
parents=[list(np.where(net[i,:]==-1)[0]+1)+
list(np.where(net[:,i]==1)[0]+1)
for i in range(N)]
#-----計算BIC評分-----
struct,emp=0,0 #BIC評分的結構項和經驗項
if consider==None:
consider=range(N)
for i in consider:
r=len(values[i]) #Xi結點的取值數
pa=parents[i] #Xi的父節點編號
nums=[len(values[p-1]) for p in pa] #父節點取值數
q=np.prod(nums) #父節點取值組合數
struct+=q*(r-1)/2*np.log(m) #對結構項的貢獻
#-----如果父節點數目為零,亦即沒有父節點
if len(pa)==0:
for value_k in values[i]:
Dk=D[D[:,i]==value_k] #D中Xi取值v_k的子集
mk=len(Dk) #Dk子集大小
if mk>0:
emp-=mk*np.log(mk/m) #對經驗項的貢獻
continue
#-----有父節點時,通過編碼方式,遍歷所有父節點取值組合
for code in range(q):
#解碼:比如,父節點有2×3種組合,
#將0~5解碼為[0,0]~[1,2]
code0=code
decode=[]
for step in range(len(pa)-1):
wight=np.prod(nums[step+1:])
decode.append(code0//wight)
code0=code0%wight
decode.append(code0)
# 父節點取某一組合時的子集
index=range(m) #子集索引號,初始為全集D
#起初誤將m寫為N,該錯誤極不容易發現,兩天后發現并更正
for j in range(len(pa)):
indexj=np.where(D[:,pa[j]-1]==values[pa[j]-1][decode[j]])[0]
index=np.intersect1d(index,indexj)
Dij=D[index,:] #子集
mij=len(Dij) #子集大小
if mij>0: #僅當子集非空時才計算該種情況
for value_k in values[i]:
Dijk=Dij[Dij[:,i]==value_k] #Dij中Xi取值v_k的子集
mijk=len(Dijk) #Dijk子集大小
if mijk>0:
emp-=mijk*np.log(mijk/mij) #對經驗項的貢獻
return np.array([struct,emp])
#================================================
# 主程式
#================================================
#==============西瓜資料集2.0======================
# 將X和類標記Y放一起
D=[['青綠','蜷縮','濁響','清晰','凹陷','硬滑','是'],
['烏黑','蜷縮','沉悶','清晰','凹陷','硬滑','是'],
['烏黑','蜷縮','濁響','清晰','凹陷','硬滑','是'],
['青綠','蜷縮','沉悶','清晰','凹陷','硬滑','是'],
['淺白','蜷縮','濁響','清晰','凹陷','硬滑','是'],
['青綠','稍蜷','濁響','清晰','稍凹','軟粘','是'],
['烏黑','稍蜷','濁響','稍糊','稍凹','軟粘','是'],
['烏黑','稍蜷','濁響','清晰','稍凹','硬滑','是'],
['烏黑','稍蜷','沉悶','稍糊','稍凹','硬滑','否'],
['青綠','硬挺','清脆','清晰','平坦','軟粘','否'],
['淺白','硬挺','清脆','模糊','平坦','硬滑','否'],
['淺白','蜷縮','濁響','模糊','平坦','軟粘','否'],
['青綠','稍蜷','濁響','稍糊','凹陷','硬滑','否'],
['淺白','稍蜷','沉悶','稍糊','凹陷','硬滑','否'],
['烏黑','稍蜷','濁響','清晰','稍凹','軟粘','否'],
['淺白','蜷縮','濁響','模糊','平坦','硬滑','否'],
['青綠','蜷縮','沉悶','稍糊','稍凹','硬滑','否']]
D=np.array(D)
FeatureName=['色澤','根蒂','敲聲','紋理','臍部','觸感','好瓜']
#=================初始化貝葉斯網結構=============
#構建貝葉斯網路,右上角元素ij表示各個連接邊
#取值0表示無邊,取值1表示Xi->Xj,取值-1表示Xi<-Xj
m,N=D.shape
net=np.zeros((N,N))
choose=4 #選擇初始化型別,可選1,2,3,4
#分別代表全獨立網路、樸素貝葉斯網路、全連接網路,隨機網路
if choose==1: #全獨立網路:圖中沒有任何連接邊
pass
elif choose==2: #樸素貝葉斯網路:所有其他特征的父節點都是類標記"好瓜"
net[:-1,-1]=-1
elif choose==3: #全連接網路:任意兩個節點都有連接邊
again=True #若存在環,則重新生成
while again:
for i in range(N-1):
net[i,i+1:]=np.random.randint(0,2,N-i-1)*2-1
again=len(relationship(net)[2])!=0
elif choose==4: #隨機網路:任意兩個節點之間的連接邊可有可無
again=True #若存在環,則重新生成
while again:
for i in range(N-1):
net[i,i+1:]=np.random.randint(-1,2,N-i-1)
again=len(relationship(net)[2])!=0
draw(net,FeatureName,'初始網路結構')
#==============下山法搜尋BIC下降的貝葉斯網==========
score0=BIC_score(net,D)
score=[score0]
print('===========訓練貝葉斯網============')
print('初始BIC評分:%.3f(結構%.3f,經驗%.3f)'%(sum(score0),score0[0],score0[1]))
eta,tao=0.1,50 #允許eta的概率調整到BIC評分增大的網路
#閾值隨迭代次數指數下降
for loop in range(10000):
# 隨機指定需要調整的連接邊的兩個節點:Xi和Xj
i,j=np.random.randint(0,N,2)
while i==j:
i,j=np.random.randint(0,N,2)
i,j=(i,j) if i<j else (j,i)
# 確定需要調整的結果
value0=net[i,j]
change=np.random.randint(2)*2-1 #結果為+1或-1
value1=(value0+1+change)%3 -1 #調整后的取值
net1=net.copy()
net1[i,j]=value1
if value1!=0 and len(relationship(net1)[2])!=0:
#如果value1取值非零,說明為轉向或者增邊
#若引入環,則放棄該調整
continue
delta_score=BIC_score(net1,D,[i,j])-BIC_score(net,D,[i,j])
if sum(delta_score)<0 or np.random.rand()<eta*np.exp(-loop/tao):
score0=score0+delta_score
score.append(score0)
print('調整后BIC評分:%.3f(結構%.3f,經驗%.3f)'
%(sum(score0),score0[0],score0[1]))
net=net1
else:
continue
draw(net,FeatureName,'最終網路結構')
score=np.array(score)
x=np.arange(len(score))
plt.title('BIC貝葉斯網路結構搜索程序')
plt.xlabel('更新次數')
plt.ylabel('分值')
plt.plot(x,score[:,0],'.r-')
plt.plot(x,score[:,1],'.b-')
plt.plot(x,score.sum(axis=1),'.k-')
plt.legend(['struct','emp','BIC(struct+emp)'])
plt.show()
習題7.10(Python)
# -*- coding: utf-8 -*-
"""
Created on Wed Jan 15 17:02:12 2020
@author: lsly
"""
import numpy as np
import matplotlib.pyplot as plt
#==============首先撰寫幾個函式,主程式見后==============
def relationship(net):
# 計算網路中的每個結點的父母結點以及父母以上的祖輩結點
# 輸入:
# net:array型別,網路結構,右上角元素ij表示各個連接邊
# 取值0表示無邊,取值1表示Xi->Xj,取值-1表示Xi<-Xj
# 輸出:
# parents:list型別,存盤各個結點的父節點編號,用取值1~N代表各個節點
# grands:list型別,存盤各個結點更深的依賴節點,可以看成是“祖結點”
# circle:list型別,存盤環節點編號,若圖中存在環,那么這個結點將是它本身的“祖結點”
N=len(net) #節點數
#-----確定父結點-----
parents=[list(np.where(net[i,:]==-1)[0]+1)+
list(np.where(net[:,i]==1)[0]+1)
for i in range(N)]
grands=[]
#-----確定“祖結點”-----
for i in range(N):
grand=[]
#---爺爺輩---
for j in parents[i]:
for k in parents[j-1]:
if k not in grand:
grand.append(k)
#---曾祖及以上輩---
loop=True
while loop:
loop=False
for j in grand:
for k in parents[j-1]:
if k not in grand:
grand.append(k)
loop=True
grands.append(grand)
#-----判斷環結點-----
circle=[i+1 for i in range(N) if i+1 in grands[i]]
return parents,grands,circle
def draw(net,name=None,title=''):
# 繪制貝葉斯網路的變數關系圖
# net:array型別,網路結構,右上角元素ij表示各個連接邊
# 取值0表示無邊,取值1表示Xi->Xj,取值-1表示Xi<-Xj
# name:指定各個節點的名稱,默認為None,用x1,x2...xN作為名稱
N=net.shape[0]
Level=np.ones(N,dtype=int)
#-----確定層級-----
for i in range(N):
for j in range(i+1,N):
if net[i][j]==1 and Level[j]<=Level[i]:
Level[j]+=1
if net[i][j]==-1 and Level[i]<=Level[j]:
Level[i]+=1
#-----確定橫向坐標-----
position=np.zeros(N)
for i in set(Level):
num=sum(Level==i)
position[Level==i]=np.linspace(-(num-1)/2,(num-1)/2,num)
#-----畫圖-----
plt.figure()
plt.title(title)
#設定出圖顯示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#--先畫出各個結點---
for i in range(N):
if name==None:
text='x%d'%(i+1)
else:
text=name[i]
plt.annotate(text,xy=[position[i],Level[i]],bbox={'boxstyle':'circle','fc':'1'},ha='center')
#--再畫連接線---
for i in range(N):
for j in range(i+1,N):
if net[i][j]==1:
xy=np.array([position[j],Level[j]])
xytext=np.array([position[i],Level[i]])
if net[i][j]==-1:
xy=np.array([position[i],Level[i]])
xytext=np.array([position[j],Level[j]])
if net[i][j]!=0:
L=np.sqrt(sum((xy-xytext)**2))
xy=xy-(xy-xytext)*0.2/L
xytext=xytext+(xy-xytext)*0.2/L
if (xy[0]==xytext[0] and abs(xy[1]-xytext[1])>1)or\
(xy[1]==xytext[1] and abs(xy[0]-xytext[0])>1):
arrowprops=dict(arrowstyle='->',connectionstyle='arc3,rad=0.3')
#畫弧線,避免遮擋(只考慮了橫向和豎向邊,暫未考慮斜向邊遮擋的情況)
else:
arrowprops=dict(arrowstyle='->')
plt.annotate('',xy=xy,xytext=xytext,arrowprops=arrowprops,ha='center')
plt.axis([position.min(),position.max(),Level.min(),Level.max()+0.5])
plt.axis('off')
plt.show()
def coder(StateNums):
# 編碼器,
# 設有結點x1,x2,...xN,各個結點的狀態數為s1,s2,...sN,
# 那么結點取值的組合數目為s1*s2*...sN,
# 這些組合狀態可以編碼表示為[0,0,...0]~[s1-1,s2-1,...sN-1]
# 輸出:
# StateNums:各個結點狀態數,
# 比如[2,3,2]意為x1,x2,x3分別有2,3,2種狀態,
# 組合起來便有12種狀態,
# 輸出:
# codes:用于遍歷所有狀態的索引編號,
# 比如,對于[2,3],總共6種組合狀態,遍歷這6種組合狀態的編碼為:
# [0,0],[0,1],[0,2],[1,0],[1,1],[1,2]
Nodes=len(StateNums) #結點數
states=np.prod(StateNums) #組合狀態數
codes=[]
for s in range(states):
s0=s
code=[]
for step in range(Nodes-1):
wight=np.prod(StateNums[step+1:])
code.append(s0//wight)
s0=s0%wight
code.append(s0)
codes.append(code)
return codes
def EM(net,D,ZStateNum,Try=1):
# EM演算法計算隱變數概率分布Q(z),這里僅考慮單個隱變數的簡單情況
# 輸入:
# net:貝葉斯網路結構,以矩陣右上角元素表示連接關系,
# 約定將隱變數排在最后一個,
# D:可觀測變數資料集
# ZStateNum:隱變數狀態數(離散取值數目)結果
# Try:嘗試次數,由于EM演算法收斂到的結果受初始值影響較大,
# 因此,嘗試不同初始值,最終選擇邊際似然最大的,
# 輸出:
# Qz:隱變數概率分布
#=====網路性質=====
parents=[list(np.where(net[i,:]==-1)[0])+
list(np.where(net[:,i]==1)[0])
for i in range(len(net))] #計算各個結點的父節點
#=====可觀測變數引數=====
m,Nx=D.shape #樣本數和可觀測變數數
values=[np.unique(D[:,i])for i in range(Nx)] #可觀測變數的離散取值
#=====隱變數子節點=====
Zsonindex=list(np.where((net[:Nx,Nx:]==-1).any(axis=1))[0]) #隱結點子節點索引號
#=====運行多次EM,每次隨機初始化Qz,最終選擇邊際似然最大的結果=====
for t in range(Try):
#=====隱變數分布初始化=====
Qz=np.random.rand(m,ZStateNum) #初始化隱變數概率分布
Qz=Qz/Qz.sum(axis=1).reshape(-1,1) #概率歸一化
#Qz=np.c_[np.ones([m,1]),np.zeros([m,2])]
#=====迭代更新Qz=====
dif=1 #兩次Qz的差別
while dif>1E-8:
NewQz=np.ones(Qz.shape)
#-----對于隱結點-----
pa=parents[-1] #隱結點的父結點
if len(parents[-1])==0: #如果隱結點沒有父節點
NewQz*=Qz.sum(axis=0)
else:
ValueNums=[len(values[p]) for p in pa] #各個父結點的狀態數
codes=coder(ValueNums) #用于遍歷各種取值的編碼
for code in codes:
#父結點取值組合
CombValue=https://www.cnblogs.com/NoNameIsBeginning/archive/2020/09/26/[values[pa[p]][code[p]] for p in range(len(pa))]
index=np.where((D[:,pa]==CombValue).all(axis=1))[0]
NewQz[index]*=Qz[index].sum(axis=0) if len(index)!=0 else 1
#-----對于隱結點的子結點-----
for son in Zsonindex:
#分子部分
pa=parents[son] #父結點,
Nodes=pa+[son] #加上該結點本身,
Nodes.remove(Nx) #然后,移去隱結點作為考察結點
ValueNums=[len(values[N]) for N in Nodes] #各個結點的狀態數
codes=coder(ValueNums) #用于遍歷各種取值的編碼
for code in codes:
CombValue=[values[Nodes[N]][code[N]] for N in range(len(Nodes))]
index=np.where((D[:,Nodes]==CombValue).all(axis=1))[0]
NewQz[index]*=Qz[index].sum(axis=0) if len(index)!=0 else 1
#分母部分
pa=parents[son]+[] #僅考察父結點
pa.remove(Nx) #移去隱結點
if len(pa)==0: #如果父結點只有隱結點一個
NewQz/=Qz.sum(axis=0)
else:
ValueNums=[len(values[p]) for p in pa] #各個父結點的狀態數
codes=coder(ValueNums) #用于遍歷各種取值的編碼
for code in codes:
#父結點取值組合
CombValue=[values[pa[p]][code[p]] for p in range(len(pa))]
index=np.where((D[:,pa]==CombValue).all(axis=1))[0]
NewQz[index]/=Qz[index].sum(axis=0)+1E-100 if len(index)!=0 else 1
NewQz=NewQz/NewQz.sum(axis=1).reshape(-1,1) #歸一化
dif=np.sum((Qz-NewQz)**2,axis=1).mean() #新舊Qz的差別
Qz=NewQz #更新Qz
if t==0:
BestQz=Qz
maxLL=LL(net,D,Qz,consider=(Zsonindex+[Nx]))
else:
newLL=LL(net,D,Qz,consider=(Zsonindex+[Nx]))
if newLL>maxLL:
maxLL=newLL
BestQz=Qz
return BestQz
def LL(net,D,Qz,consider=None):
# 含有單個隱變數的情況下,計算邊際似然
# 輸入:
# net:貝葉斯網路結構,以矩陣右上角元素表示連接關系,
# 約定將隱變數排在最后一個,
# D:可觀測變數資料集
# Qz:隱變數概率分布
# consider:所考察的結點,根據分析,
# 邊際似然中部分項可以表示為各個結點求和的形式,
# 因此可以指定求和所包含的結點
# 輸出:
# LL:邊際似然
#=====網路性質=====
parents=[list(np.where(net[i,:]==-1)[0])+
list(np.where(net[:,i]==1)[0])
for i in range(len(net))] #計算各個結點的父節點
#=====可觀測變數引數=====
m,Nx=D.shape #樣本數和可觀測變數數
values=[np.unique(D[:,i])for i in range(Nx)] #可觀測變數的離散取值
#=====待考察結點=====
if consider is None:
consider=range(Nx+1)
#=====計算邊際似然的求和項=====
LL=0
#print(consider)
for i in consider:
#print(i)
pa=parents[i] #父結點
sign=1
for nodes in [pa+[i],pa]: #nodes為當前所考察的結點
if len(nodes)==0: #考慮當前xi沒有父結點的情況
LL+=sign*m*np.log(m)
continue
zin=nodes.count(Nx)!=0 #是否含有隱結點
if zin:
nodes.remove(Nx)
if len(nodes)==0: #除了隱結點外沒有其他結點
mz=Qz.sum(axis=0)
LL+=sign*sum(np.log(mz**mz))
else:
StateNums=[len(values[nd]) for nd in nodes]
for code in coder(StateNums):
CombValue=[values[nodes[N]][code[N]] for N in range(len(nodes))]
index=np.where((D[:,nodes]==CombValue).all(axis=1))[0]
if zin:
mz=Qz[index].sum(axis=0)
LL+=sign*sum(np.log(mz**mz))
else:
mz=len(index)
LL+=sign*(np.log(mz**mz))
sign*=-1
#=====計算隱變數概率分布項=====
LL-=np.sum(np.log(Qz**Qz))
return LL
def BIC(net,D,Qz,alpha=1,consider=None):
# 計算BIC評分
# 輸入:
# net:貝葉斯網路結構,以矩陣右上角元素表示連接關系,
# 約定將隱變數排在最后一個,
# D:可觀測變數資料集
# Qz:隱變數分布
# alpha:結構項的比重系數
# consider:所考察的結點,根據分析,
# BIC評分中前兩項可以表示為各個結點求和的形式,
# 因此可以指定求和所包含的結點
# 輸出:
# np.array([struct,emp]):BIC評分結構項和經驗項兩部分的分值
#-----從資料集D中提取一些資訊-----
m,Nx=D.shape #樣本數和可觀測變數數特征數
values=[list(np.unique(D[:,i])) for i in range(len(D[0]))] #各個離散屬性的可能取值
values.append(range(ZStateNum)) #再加上隱變數的取值數
#-----父節點-----
parents=[list(np.where(net[i,:]==-1)[0])+
list(np.where(net[:,i]==1)[0])
for i in range(len(net))]
#-----計算BIC評分-----
emp=-LL(net,D,Qz,consider) #經驗項部分呼叫LL函式來計算
struct=0 #下面計算結構項
if consider is None:
consider=range(Nx+1)
for i in consider:
r=len(values[i]) #Xi結點的取值數
pa=parents[i] #Xi的父節點編號
nums=[len(values[p]) for p in pa] #父節點取值數
q=np.prod(nums) #父節點取值組合數
struct+=q*(r-1)/2*np.log(m) #對結構項的貢獻
return np.array([struct*alpha,emp])
def BIC_change(net0,D,Qz,change,alpha=1):
# 計算貝葉斯網路結構發生變化后BIC評分的變化量
# 輸入:net0:變化前的網路結構
# D:資料集
# Qz:隱結點分布
# change:網路結構的變化,內容為[i,j,value],
# 意為xi到xj之間的連接邊變為value值
# alpha:計算BIC評分時,結構項的比重系數
# 輸出:dscore:BIC評分的改變,內容為[struct,emp],
# 分別表示結構項和經驗項的變化
# NewQz:新的隱結點分布
#=====網路結構的改變
i,j,value=change
consider=[i,j]
net1=net0.copy()
net1[i,j]=value
#=====隱變數子節點
son0=list(np.where(net0[:-1,-1]==-1)[0])
son1=list(np.where(net1[:-1,-1]==-1)[0])
#=====判斷是否需要重新運行EM
if j==len(net0)-1 or (i in son0) or (j in son0):
Qz1=EM(net1,D,Qz.shape[1],12)
consider=consider+son0+son1+[len(net0)-1]
consider=np.unique(consider)
else:
Qz1=Qz
dscore=BIC(net1,D,Qz1,alpha,consider)-BIC(net0,D,Qz,alpha,consider)
return dscore,Qz1
#================================================
# 主程式
#================================================
#==============西瓜資料集2.0======================
# 將X和類標記Y放一起
D=[['青綠','蜷縮','濁響','清晰','凹陷','硬滑','是'],
['烏黑','蜷縮','沉悶','清晰','凹陷','硬滑','是'],
['烏黑','蜷縮','濁響','清晰','凹陷','硬滑','是'],
['青綠','蜷縮','沉悶','清晰','凹陷','硬滑','是'],
['淺白','蜷縮','濁響','清晰','凹陷','硬滑','是'],
['青綠','稍蜷','濁響','清晰','稍凹','軟粘','是'],
['烏黑','稍蜷','濁響','稍糊','稍凹','軟粘','是'],
['烏黑','稍蜷','濁響','清晰','稍凹','硬滑','是'],
['烏黑','稍蜷','沉悶','稍糊','稍凹','硬滑','否'],
['青綠','硬挺','清脆','清晰','平坦','軟粘','否'],
['淺白','硬挺','清脆','模糊','平坦','硬滑','否'],
['淺白','蜷縮','濁響','模糊','平坦','軟粘','否'],
['青綠','稍蜷','濁響','稍糊','凹陷','硬滑','否'],
['淺白','稍蜷','沉悶','稍糊','凹陷','硬滑','否'],
['烏黑','稍蜷','濁響','清晰','稍凹','軟粘','否'],
['淺白','蜷縮','濁響','模糊','平坦','硬滑','否'],
['青綠','蜷縮','沉悶','稍糊','稍凹','硬滑','否']]
D=np.array(D)
FeatureName=['色澤','根蒂','敲聲','紋理','臍部','觸感','好瓜']
#======將“臍部”視為隱變數,對資料進行相應的修改=====
D=D[:,[0,1,2,3,5,6]] #可觀測資料集
XName=['色澤','根蒂','敲聲','紋理','觸感','好瓜'] #x變數名稱
ZName=['臍部'] #隱變數名稱
ZStateNum=3 #隱變數的狀態數(離散取值數目)
FeatureName=XName+ZName #包括可觀測變數和隱變數的所有變數的名稱
#=================初始化為樸素貝葉斯網=============
#構建貝葉斯網路,右上角元素ij表示各個連接邊
#取值0表示無邊,取值1表示Xi->Xj,取值-1表示Xi<-Xj
m=D.shape[0] #樣本數
N=len(XName)+1 #結點數
net=np.zeros((N,N))
choose=4 #選擇初始化型別,可選1,2,3,4
#分別代表全獨立網路、樸素貝葉斯網路、全連接網路,隨機網路
if choose==1: #全獨立網路:圖中沒有任何連接邊
pass
elif choose==2: #樸素貝葉斯網路:所有其他特征的父節點都是類標記"好瓜"
net[:-1,-1]=-1
elif choose==3: #全連接網路:任意兩個節點都有連接邊
again=True #若存在環,則重新生成
while again:
for i in range(N-1):
net[i,i+1:]=np.random.randint(0,2,N-i-1)*2-1
again=len(relationship(net)[2])!=0
elif choose==4: #隨機網路:任意兩個節點之間的連接邊可有可無
again=True #若存在環,則重新生成
while again:
for i in range(N-1):
net[i,i+1:]=np.random.randint(-1,2,N-i-1)
again=len(relationship(net)[2])!=0
draw(net,FeatureName,'初始網路結構')
#==============下山法搜尋BIC下降的貝葉斯網==========
alpha=0.1 #BIC評分的結構項系數
Qz=EM(net,D,ZStateNum,12)
score0=BIC(net,D,Qz,alpha)
score=[score0]
print('===========訓練貝葉斯網============')
print('初始BIC評分:%.3f(結構%.3f,經驗%.3f)'%(sum(score0),score0[0],score0[1]))
eta,tao=0.1,50 #允許eta的概率調整到BIC評分增大的網路
#閾值隨迭代次數指數下降
for loop in range(500):
# 隨機指定需要調整的連接邊的兩個節點:Xi和Xj
i,j=np.random.randint(0,N,2)
while i==j:
i,j=np.random.randint(0,N,2)
i,j=(i,j) if i<j else (j,i)
# 確定需要調整的結果
value0=net[i,j] #可能為0,1,-1
change=np.random.randint(2)*2-1 #結果+1或-1
value1=(value0+1+change)%3 -1 #調整后的取值
net1=net.copy()
net1[i,j]=value1
if value1!=0 and len(relationship(net1)[2])!=0:
#如果value1取值非零,說明為轉向或者增邊
#若引入環,則放棄該調整
continue
chage,NewQz=BIC_change(net,D,Qz,[i,j,value1],alpha)
if sum(chage)<0 or np.random.rand()<eta*np.exp(-loop/tao):
score0=score0+chage
score.append(score0)
net=net1
Qz=NewQz
print('調整后BIC評分:%.3f(結構%.3f,經驗%.3f)'
%(sum(score0),score0[0],score0[1]))
else:
continue
draw(net,FeatureName,'最終網路結構,alpha=%.3f'%(alpha))
Qz=EM(net,D,ZStateNum)
score=np.array(score)
x=np.arange(len(score))
plt.title('BIC貝葉斯網路結構搜索程序,alpha=%.3f'%(alpha))
plt.xlabel('更新次數')
plt.ylabel('分值')
plt.plot(x,score[:,0],'.r-')
plt.plot(x,score[:,1],'.b-')
plt.plot(x,score.sum(axis=1),'.k-')
plt.legend(['struct','emp','BIC(struct+emp)'])
plt.show()
王書海等, BIC評分貝葉斯網路模型及其應用, 計算機工程, 2008.08 ?? ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/131607.html
標籤:其他
下一篇:二進制中 1 的個數