論文傳送門: You Only Look Once: Unified, Real-Time Object Detection
You Only Look Once: Unified, Real-Time Object Detection
Abstract
作為one-stage演算法的經典成員, YOLOv1提出使用回歸的方法得到bbox. 相較于tow-stage演算法把提取bbox(bounding box)和分類分開來做, YOLOv1直接從圖片中回歸出bbox并進行分類. 因為用的beckbone比較簡單, 主要特點就是快, 速度方面能輕松超越其他state-of-the-art演算法, 可以做到端到端的實時檢測(45FPS, GPU為Titan X).
Introduction
為了檢測到目標(object), 之前一些演算法會基于不同尺度, 不同位置在一張影像上對目標進行分類評估. 比如DPM(deformable parts models)使用滑窗(sliding window)的方法在每張影像上生成大量的候選框, 并進行分類, 留下符合要求的.
而作為tow-stage的經典, R-CNN則是先使用select search演算法生成一定數量的候選框, 將其送入分類器后進一步得到合適的bbox, 將得到的bbox再進一步地調整位置, 隨后進行一些后處理就能得到想要的bbox了. 但步驟比較復雜, 難以優化, 個別步驟還是分開進行訓練的.
而YOLOv1將目標檢測視為一個簡單的bbox坐標回歸和分類的問題.
如圖, 先將影像resize成
448
?
448
448*448
448?448, 然后輸入到一個簡單的卷積神經網路中, 最后使用NMS做后處理.
此外,YOLOv1也承認自己存在不足, 在正確率方面滯后于其他state-of-the-art演算法.
Unified Detection
接下來就是演算法設計的細節部分了.
- 訓練階段, 輸入的影像經過卷積神經網路后尺度變為
S
×
S
S×S
S×S個grid, 含有目標的groundtruth box的中心點落在哪個grid上, 哪個grid就負責該目標的預測. 然后每個負責預測的grid則會生成B個bbox, 每個bbox會預測出一個置信度(confidence), 即
B
×
1
B×1
B×1個置信度, 置信度反映了該grid包含目標的可能程度. 如果模型判定該處不存在目標(置信度過低), 那么就直接輸出0就好了, 所以置信度
c
o
n
f
i
d
e
n
c
e
confidence
confidence等于目標存在的概率乘于groundtruth和prediction的
I
O
U
IOU
IOU,
P
r
(
O
b
j
e
c
t
)
?
I
O
U
p
r
e
d
t
r
u
t
h
Pr(Object) ? IOU^{truth}_{pred}
Pr(Object)?IOUpredtruth?.

每個生成的bbox還會包含4個引數: x, y, w, h, 即bbox中心點的坐標(x, y)和bbox的寬高w, h. 每個grid還需要輸出C個類別的概率, 不過是帶條件的, P r ( C l a s s i ∣ O b j e c t ) Pr(Classi |Object) Pr(Classi∣Object), 即當在該grid中沒有檢測到目標是, 那每個類別的概率就為0了.
最后網路的輸出是 S × S × ( B × 5 + C ) S × S × (B × 5 + C) S×S×(B×5+C)的張量. 再次理解一下, 每個預測的bbox需要輸出5個值: x , y , w , h , c o n f i d e n c e x, y, w, h, confidence x,y,w,h,confidence, 每個grid需要生成B個bbox, 所以就有了 B × 5 B × 5 B×5, 然后每個grid還需要預測C個類別的概率, 所以就是 B × 5 + C B × 5 + C B×5+C, 一共有 S × S S × S S×S個grid, 所以最終輸出的形式是 S × S × ( B × 5 + C ) S × S × (B × 5 + C) S×S×(B×5+C). 但訓練時并不是每個grid都參與預測, 所以沒有目標中心點包含目標中心點的grid就直接輸出0了. - 推理階段, 有區別與訓練部分的是, 并不是只有目標中心點所在的grid才需要預測, 而是所有
S
×
S
S×S
S×S個grid都需要進行預測, 因為推理的時候沒有了groundtruth,也就不知道哪個grid包含了目標的中心點.
作者在PASCAL VOC資料集上做實驗, 取 S = 7 S=7 S=7, B = 2 B=2 B=2. 該資料集有20個類別, C = 20 C=20 C=20. 所以最后輸出為 7 × 7 × 30 7 × 7 × 30 7×7×30.
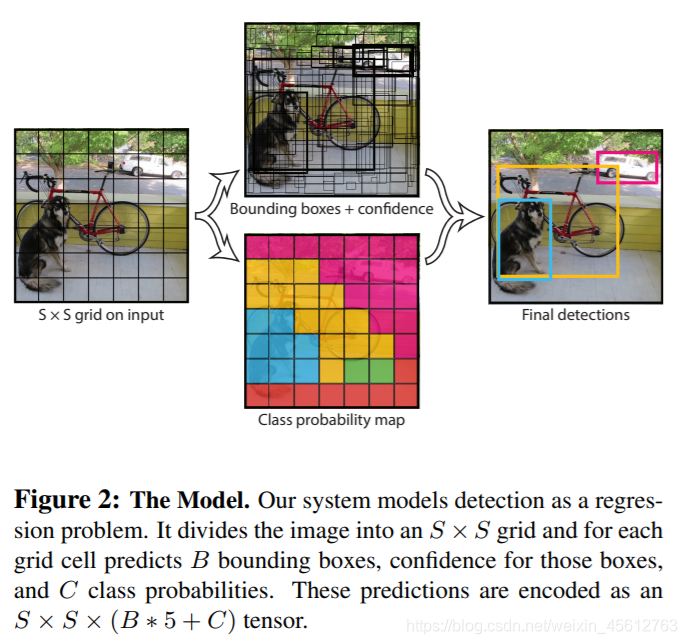
1. Network Design
模型設計圖如下, 結構較為簡單, 最后輸出7×7×30的tensor.


2. Training
-
預處理: 將bbox的W和H歸一化, bbox的中心點坐標(x, y)表示為該點所在grid左上角的偏移量(offset), 同樣進行了歸一化. 還將上圖中的前20層卷積層經過一個平均池化再接一個全連接層,在ImageNet上做預訓練,
-
激活函式: Leaky ReLU
? ( x ) = { x , if x > 0 0.1 x , otherwise \phi(x) = \begin{cases} x, & \text{if x > 0} \\[5ex] 0.1x, & \text{otherwise} \end{cases} ?(x)=????????x,0.1x,?if x > 0otherwise? -
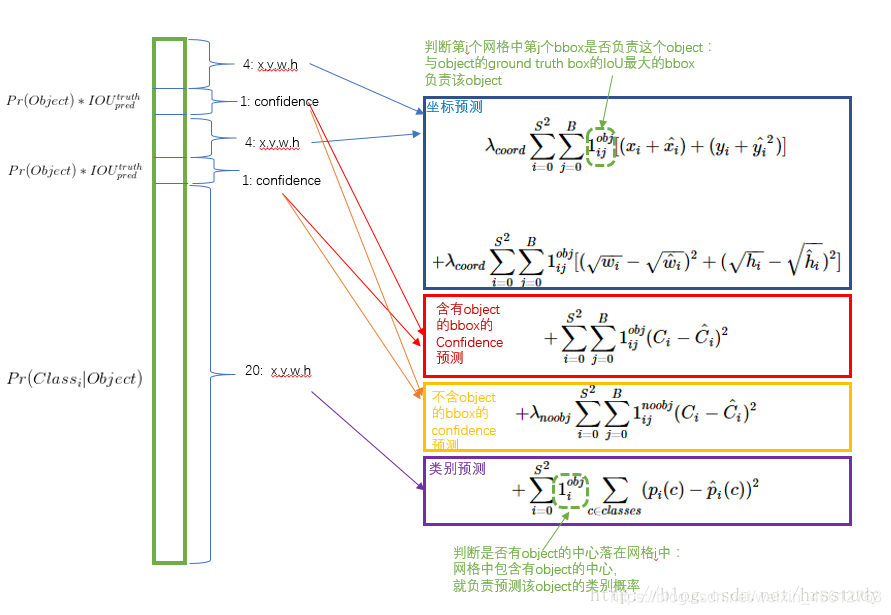
損失函式(loss):

因為輸出有多個引數, 所以loss會由多個部分組成, 每個部分都使用平方和誤差.
x , y , w , h , C , p ( c ) x, y, w, h, C, p(c) x,y,w,h,C,p(c)為groundtruth, 而 x ^ , y ^ , w ^ , h ^ , C ^ , p ^ ( c ) \hat x, \hat y, \hat w, \hat h, \hat C, \hat p(c) x^,y^?,w^,h^,C^,p^?(c)為則為預測值. 其中 C C C表示置信度, p ( c ) p(c) p(c)表示類別的概率,
∑ i = 0 S 2 \sum_{i=0}^{S^{2}} ∑i=0S2?表示遍歷所用的grid, ∑ j = 0 B \sum_{j=0}^B ∑j=0B?, 表示遍歷這個grid里面的bbox. 即i表示第i個grid,j表示第j個bbox, l i j o b j l^{obj}_{ij} lijobj?表示 S ? S ? B S*S*B S?S?B個bbox中存在object的那幾個bbox;而 l i j n o o b j l^{noobj}_{ij} lijnoobj?自然表示不存在object的bbox.
因為w, h和x, y的偏移尺度不相同, 比如 x ? x ^ = 0.2 x-\hat x=0.2 x?x^=0.2, 而 w ? w ^ = 0.6 w-\hat w=0.6 w?w^=0.6, 會使梯度往 w w w的方向下降更多, 所以在w和h上開個根號. 同樣, 為了平衡坐標x, y, w, h與不存在目標的bbox的權重, 增加了兩個引數 λ c o o r d \lambda_{coord} λcoord?和 λ n o o b j \lambda_{noobj} λnoobj?, 并分別取5和0.5, 降低 l i j n o o b j l^{noobj}_{ij} lijnoobj?的權重是因為很多grid都不包含目標, 負樣本數量比較多.
-
貼一下詳細的超引數設定和訓練方式:
We train the network for about 135 epochs on the training and validation data sets from PASCAL VOC 2007 and 2012. When testing on 2012 we also include the VOC 2007 test data for training. Throughout training we use a batch size of 64, a momentum of 0.9 and a decay of 0.0005. Our learning rate schedule is as follows: For the first epochs we slowly raise the learning rate from 1 0 ? 3 10^{?3} 10?3 to 1 0 ? 2 10^{?2} 10?2. If we start at a high learning rate our model often diverges due to unstable gradients. We continue training with 1 0 ? 2 10^{?2} 10?2 for 75 epochs, then 1 0 ? 3 10^{?3} 10?3 for 30 epochs, and finally 1 0 ? 4 10^{?4} 10?4 for 30 epochs.
To avoid overfitting we use dropout and extensive data augmentation. A dropout layer with rate = .5 after the first connected layer prevents co-adaptation between layers . For data augmentation we introduce random scaling and translations of up to 20% of the original image size. We also randomly adjust the exposure and saturation of the image by up to a factor of 1.5 in the HSV color space.
Limitations of YOLO
YOLOv1演算法的部分差不多就講完了,不過論文中還講了該演算法的局限性,
- 由于YOLOv1每個grid只預測兩個bbox,并且只預測一個類別,當多個小目標靠一起的時候就比較難預測了,比如鳥群,
- 對于新的長寬比的object的泛化能力較弱,
- 損失函式對與大小差異大的bbox的處理能力較弱,同一個誤差對小bbox的影響比大bbox的影響要大得多,
Experiments
實驗部分就略過了,只放一張效果圖吧,

Conclusion
相較于classifier-based的方法(先生成bbox,再對bbox里的內容分類),YOLOv1直接同時對整張影像進行坐標回歸和分類,能更快地完成檢測任務,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/131944.html
標籤:其他
上一篇:用python觀察三門問題的頻率(Monty Hall Problem)
下一篇:厚薄讀書法