python資料爬蟲專案
作者:YRH
時間:2020/9/26
新手上路,如果有寫的不好的請多多指教,多多包涵
前些天在一個學習群中有位老哥發布了一個專案,當時抱著滿滿的信心想去嘗試一下,可惜手慢了,搶不到,最后只拿到了專案的任務之間去練習,感覺該專案還不錯,所以就發布到博客上來,讓大家一起學習學習
一、任務清單
專案名稱:國家自然科學基金大資料知識管理服務門戶爬取專案
爬取內容:爬取內容:資助專案(561914項)
爬取鏈接:HTTP://KD.NSFC.GOV.CN/BASEQUERY/SUPPORTQUERY
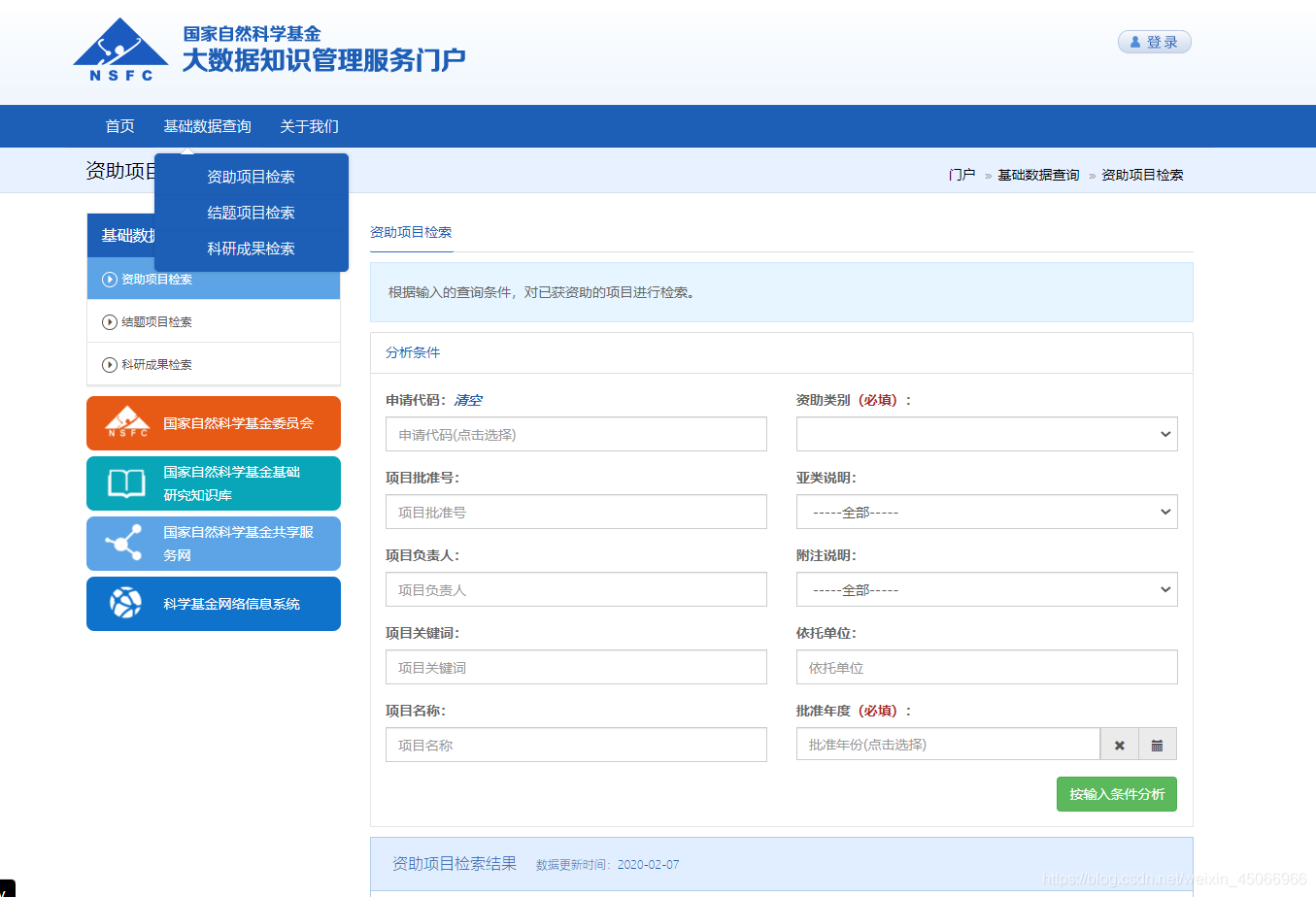
第一階段:
1、 需要對申請代碼、資助類別和批準年度進行篩選,
2、 爬取資訊:
專案名稱、批準號、專案類別、專案負責人、批準年度、資助金飛、依托單位、起止年月、申請代碼、關鍵詞、研究成果、結題專案

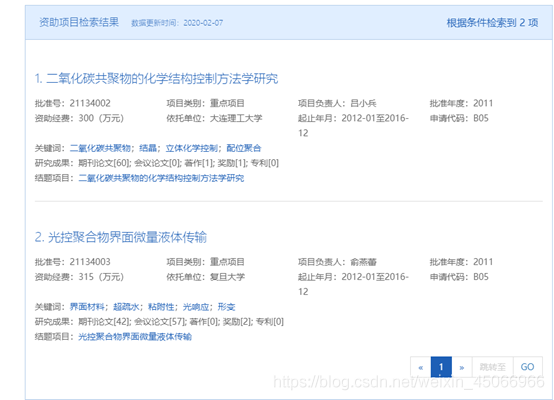
第二階段:爬取完整的專案資訊
1、 根據批準號從鏈接爬取
2、 需要爬取的資訊
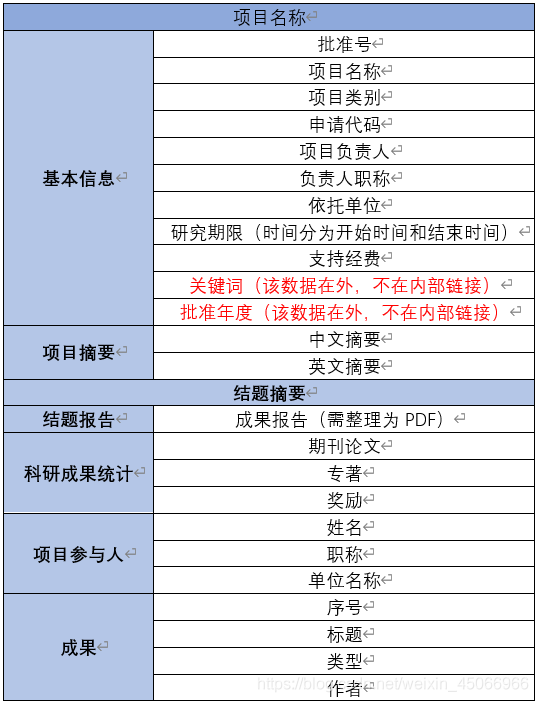
二、網頁結構分析
1、路線選擇
剛開始看到網頁是第一時間想到的是使用selenium自動化爬取,但是通過網路請求方式察覺到該網站的資料獲取方式是post請求的
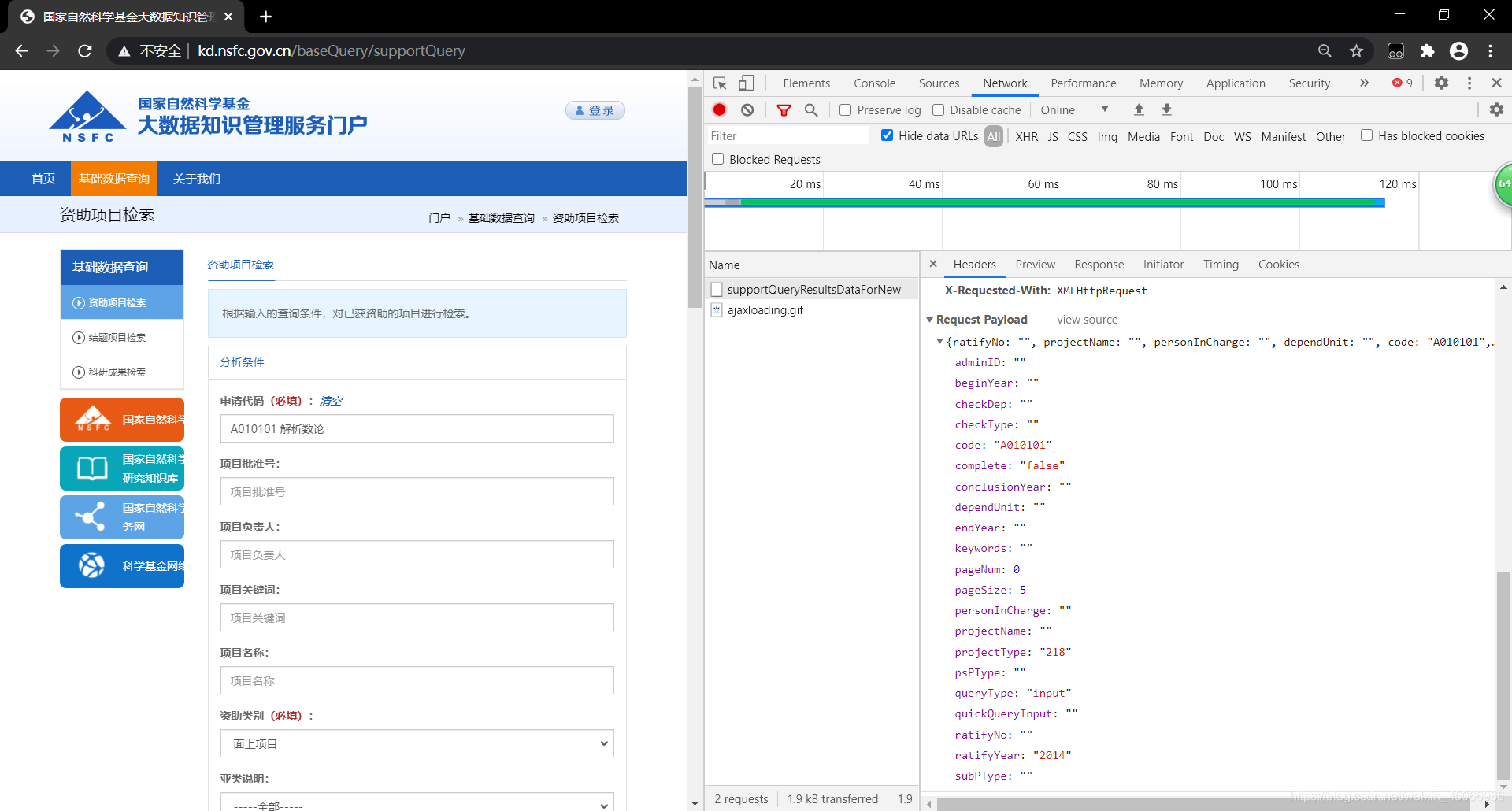
所以只有利用post請求方式將傳表單到http://kd.nsfc.gov.cn/baseQuery/data/supportQueryResultsDataForNew上,就能獲取到資料,
所以最后選擇了requests路線進行爬取
2、表單上傳結構分析
從網頁界面可以看出,想要提取資訊必須上傳三個引數,分別是申請代碼、資助型別和批準年度,這三個所對應的是鍵是code、projectType和ratifyYear,所以這三個是回去資料各項型別必傳的引數,但是當我在訪問是一直錯誤,訪問不了,然后就嘗試多加幾個引數進去,最后發現queryType: "input"這個引數必須上傳,否則會報錯
在傳入引數前必須先看一下引數型別是什么,在Requests Headers中有一個引數Content-Type: application/json,可以看得出傳入的引數是json型別的,所有引數必須先轉為json型別
三、資料爬取代碼
因為該網站資料比較多,所以我將資料保存至MySQL資料庫在,如果想執行我代碼需要先將訪問資料庫的代碼給修改一下
資料比較多,所以我只爬取了2019年份的資料,沒爬全
# -*- coding: utf-8 -*-
# Author : YRH
# Data :
# Project :
# Tool : PyCharm
import json
import requests
import xlwt
import time
import pymysql
import random
#這下面一段是創建資料庫的代碼,如果需要可以執行下面代碼創建資料表
"""CREATE TABLE IF NOT EXISTS `prodectData`(
`序號` INT UNSIGNED AUTO_INCREMENT,
`專案名稱` varchar(50) not null,
`批單號` VARCHAR(20) NOT NULL,
`專案類別` VARCHAR(20) NOT NULL,
`批準負責人` VARCHAR(20) NOT NULL,
`批準年度` VARCHAR(20) NOT NULL,
`資助經費` VARCHAR(20) NOT NULL,
`依托單位` VARCHAR(20) NOT NULL,
`起始年月` VARCHAR(20) NOT NULL,
`申請代碼` VARCHAR(20) NOT NULL,
PRIMARY KEY ( `序號` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;"""
user_agent = ["Mozilla/5.0 (Windows NT 10.0; WOW64)", 'Mozilla/5.0 (Windows NT 6.3; WOW64)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET '
'CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)',
'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12',
'Opera/9.27 (Windows NT 5.2; U; zh-cn)',
'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0',
'Opera/8.0 (Macintosh; PPC Mac OS X; U; en)',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 '
'Navigator/9.0.0.6',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; '
'.NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 '
'Chrome/26.0.1410.43 Safari/537.1 ',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; '
'.NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; '
'QQBrowser/7.3.9825.400)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 '
'Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 '
'TaoBrowser/3.0 Safari/536.11']
db = pymysql.Connect(host="localhost",
port=3306,
user="root", #資料庫名稱
password=XXXXX, #資料庫密碼
db="zzProject",
charset="utf8"
)
cur = db.cursor()
def spider(info):
#通過回圈生成專案型別編號和申請代碼
i = ["A", "B", "C", "D", "E", "F", "G", "H"]
projectType = ["218", "220", "222", "339", "429", "432", "433", "649", "579", "630",
"631", "632", "635", "51", "52", "2699", "70", "7161"]
for y in [2019]: # 可通過這里修改爬取年份,如果想要多個年份爬取,可通過下面那一行進行回圈
# for y in range(2000, 2021):
print("年度" + str(y))
for p in projectType:
print("專案類別編號:" + p)
for j in i:
if j == "A":
end = 10
elif j == "B":
end = 9
elif j == "C":
end = 22
elif j == "D":
end = 8
elif j == "E":
end = 14
elif j == "F":
end = 8
elif j == "G":
end = 5
elif j == "H":
end = 31
else:
end = 2
for b in range(1, end):
if len(str(b)) == 1:
code = j + str(0) + str(b)
else:
code = j + str(b)
# print(code)
pac(info, code, y, p)
for t in range(1, 10):
if len(str(t)) == 1:
code2 = code + str(0) + str(t)
else:
code2 = code + str(b)
# print(code)
pac(info, code2, y, p)
for l in range(1, 10):
if len(str(l)) == 1:
code3 = code2 + str(0) + str(l)
else:
code3 = code + str(l)
pac(info, code3, y, p)
def pac(info, code, year, projectType):
url = "http://kd.nsfc.gov.cn/baseQuery/data/supportQueryResultsDataForNew"
# print(code)
data = {
"code": code, "ratifyYear": str(year), "projectType": projectType, "queryType": "input",
"complete": "false", "pageNum": 0, "pageSize": 5
}
headers = {
"User-Agent": random.choice(user_agent),
"Content-Type": "application/json"
}
rep = requests.post(url, data=json.dumps(data), headers=headers)
rep.encoding = rep.apparent_encoding
text = rep.text
text = text.replace("\ue06d", "").replace("\u2022", "")
data = eval(text)
if len(data["data"]["resultsData"]) == 0:
# print(1)
pass
else:
# print(data["data"]["resultsData"])
data = data["data"]["resultsData"]
for d in data:
try:
name = d[1] # 專案名稱
# print(name)
except:
name = " " # 專案名稱
# print(name)
try:
num = d[2] # 批單號
# print(num)
except:
num = " " # 批單號
# print(num)
try:
itemCl = d[3] # 專案類別
# print(itemCl)
except:
itemCl = " " # 專案類別
# print(itemCl)
try:
itemLe = d[5] # 批準負責人
# print(itemLe)
except:
itemLe = " " # 批準負責人
# print(itemLe)
try:
year = d[7] # 批準年度
# print(year)
except:
year = " " # 批準年度
# print(year)
try:
money = str(d[6]) + "(萬元)" # 資助經費
# print(money)
except:
money = " " # 資助經費
# print(money)
try:
supOrg = d[4] # 依托單位
# print(supOrg)
except:
supOrg = " " # 依托單位
# print(supOrg)
try:
startData = d[-2] # 起始年月
# print(startData)
except:
startData = " " # 起始年月
# print(startData)
try:
code = d[-3] # 申請代碼
# print(code)
except:
code = " " # 申請代碼
# print(code)
# print("=" * 30)
# info.append([name, num, itemCl, itemLe, year, money, supOrg, startData, code]) #當資料保存至excel是使用這個
# =====================================
# 保存至mysql
try:
op = "insert into prodectdata (專案名稱,批單號,專案類別,批準負責人,批準年度,資助經費,依托單位,起始年月," \
"申請代碼) " \
"values ('%s','%s','%s','%s','%s','%s','%s','%s','%s')" % \
(str(name), str(num), str(itemCl), str(itemLe), str(year), str(money), str(supOrg),
str(startData), str(code))
cur.execute(op)
db.commit()
except:
pass
# ======================================
time.sleep(0.5)
def save(info): # 保存資料至excel
print("save.....")
workbook = xlwt.Workbook(encoding="utf-8") # 創建workbook物件
movieBook = workbook.add_sheet("sheet1") # 創建作業表
# 輸入頭標簽
head = ["專案名稱", "批單號", "專案類別", "批準負責人", "批準年度", "資助經費", "依托單位", "起始年月", "申請代碼"]
for i in range(0, len(head)):
movieBook.write(0, i, head[i]) # 引數1是行,引數2是列,引數3是值
# 資料逐行輸入
y = 1
for a in info:
print("成功保存:" + str(y))
for x in range(0, len(a)):
movieBook.write(y, x, a[x])
y += 1
workbook.save("資助專案資訊.xls") # 保存資料表
if __name__ == '__main__':
info = []
spider(info)
# save(info) #如果是保存至excel的話,請帶有改方法
db.close()
四、資料結果展示
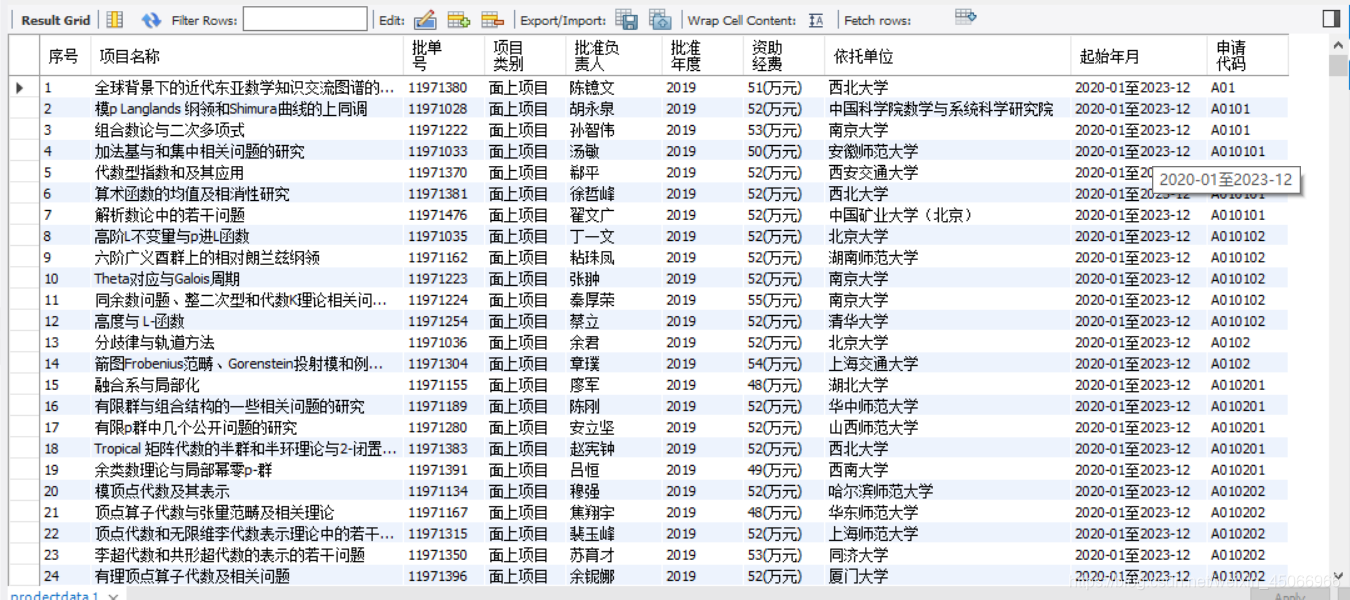
新手上路,多多指教
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/135138.html
標籤:其他