scrapy爬取小說時極易遇到章節混亂以及重復等問題,爬取小說主頁,并獲得各個章節,因為只是一個頁面,因此不會遇到排序和重復問題,然后利用pandas庫進行資料清洗,再利用DataFrame的to_csv進行存盤自動對其進行標號,再利用scrapy框架對每個章節進行爬取的時候,在MySQL資料表的指定位置插入資料
一、爬取并保存各章節目錄,然后進行資料清洗
網址分析:
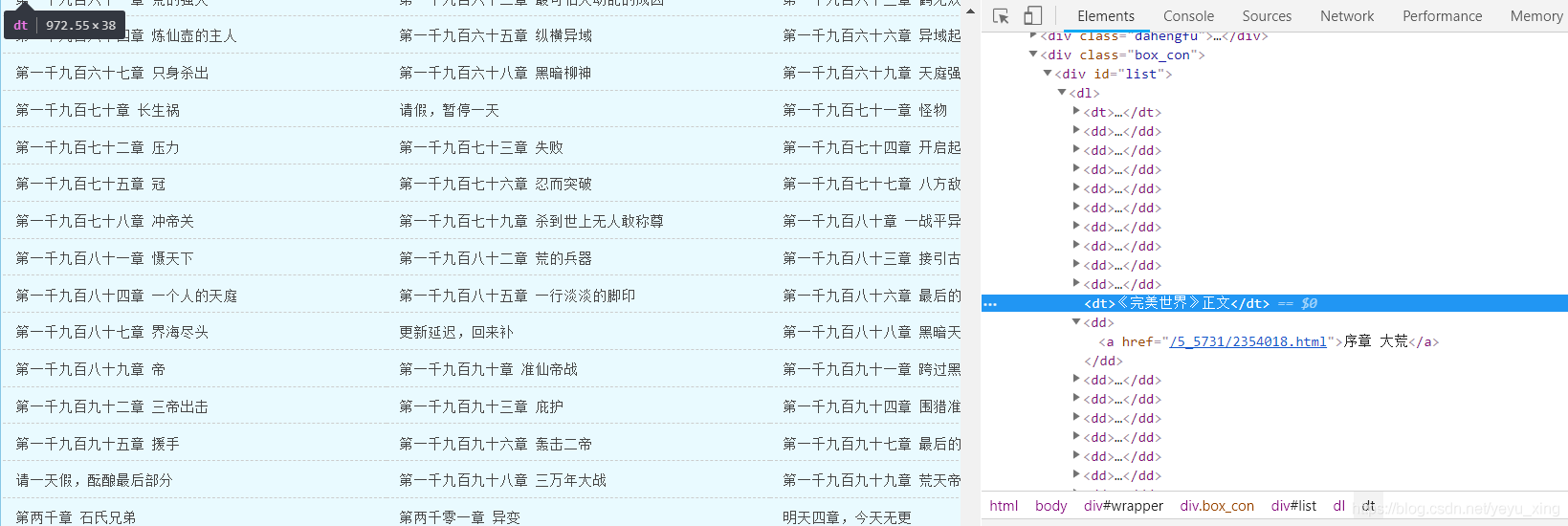
爬取并保存各章節目錄:
import requests
from lxml import etree
from pandas import DataFrame
url = 'http://www.tianxiabachang.cn/5_5731/'
res = requests.get(url)
res.encoding = 'utf-8' # 設定編碼格式(通過res.apparent_encoding可得)
text = res.text
html = etree.HTML(text)
chapter_lst, site_lst = [], [] # 創建這兩個串列用于保存章節及網址
for i in html.xpath("//div[@id='list']/dl/dd/a")[9:]:
chapter = str(i.xpath("./text()")[0])
isExisted = chapter.find('章')
if isExisted != -1:
site = url + str(i.xpath("./@href")[0]).split('/')[-1]
chapter_lst.append(chapter)
site_lst.append(site)
print('{}: {}'.format(chapter, site))
df = DataFrame({
'章節': chapter_lst,
'網址': site_lst
})
df.to_csv('d:/fictions/完美世界.csv', encoding='utf_8_sig') # 保存為csv檔案
print('csv檔案保存成功!')
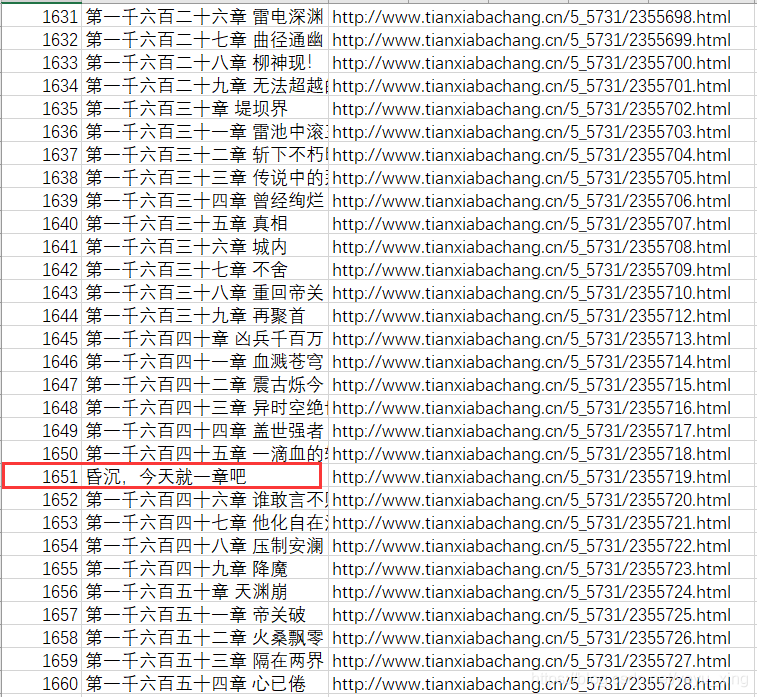
雖然保存了小說章節,但有一些章節存在問題,需要清洗
進行資料清洗:(直接每一行的查看太過費力,因此利用程式進行檢測)
from pandas import DataFrame, read_csv
from re import match
df = DataFrame(read_csv('d:/fictions/完美世界.csv')) # 匯入csv檔案
unqualified = []
# 進行逐行遍歷:
index, col = df.index, df.columns[1]
for row in index:
chapter = df.loc[row, col]
isMatched = match('第?[序零一兩二三四五六七八九十百千]*章.*', chapter)
if isMatched is None:
unqualified.append(row)
df.drop(index=unqualified, inplace=True) # 洗掉不符合正則運算式的資料
df.drop(columns=df.columns[0], inplace=True)
df.drop_duplicates(inplace=True) # 洗掉重復行
df.reset_index(inplace=True, drop=True) # 重置索引
df.to_csv('d:/fictions/完美世界[清洗后].csv', encoding='utf_8_sig') # 保存為csv檔案
print('檔案清洗成功!')
但是仍然有一些不足之處:
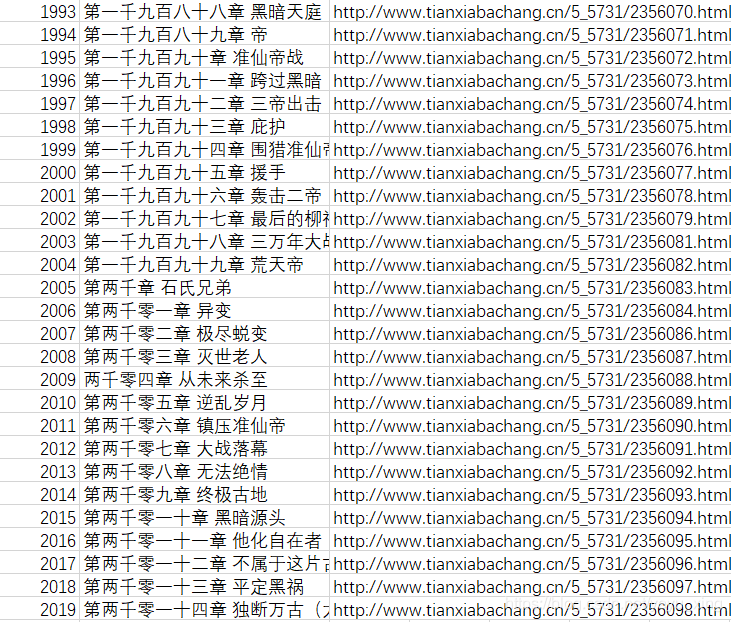
觀察資料可以發現,小說總共有2014章,但是資料資料統計卻有2019 + 1行(因為是dataframe生成,所以行索引從0開始)
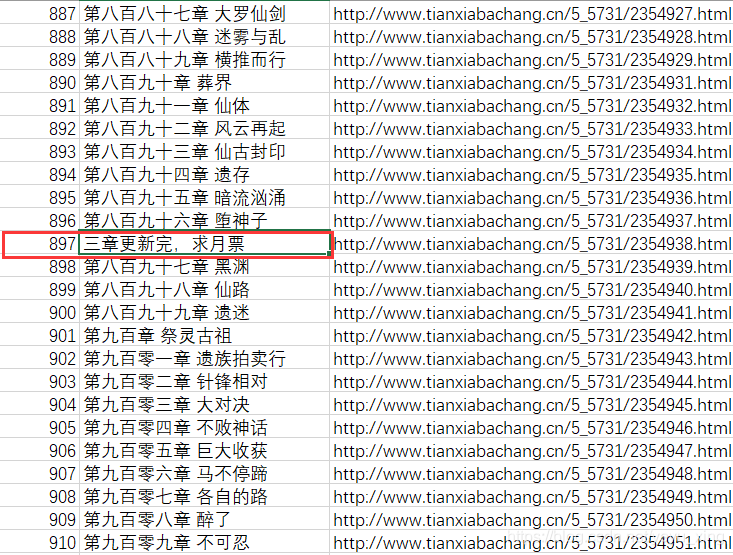
還有一些章節存在問題,提示:利用cn2an庫(可以將中文數字轉換為阿拉伯數字)和正則運算式再次清洗,反正我是不想再做了,感興趣的自己去嘗試吧
二、創建資料表
因為MySQL的原因,不能在指定行插入資料,但我們可以另辟蹊徑,先創建資料表,資料內容隨意,然后進行資料更新,變相達到在指定行插入資料
創建fictions資料庫和如下所示的表:
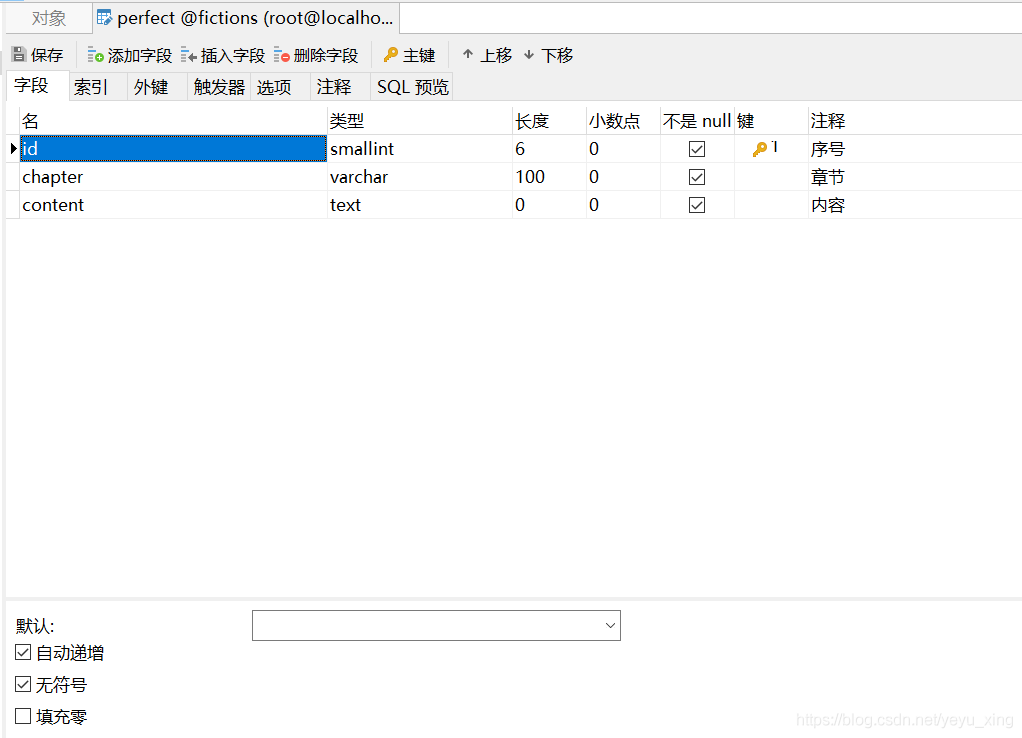
至于資料內容,自己利用MySQL回圈陳述句生成,資料條數就是2020條
三、爬取小說正文
運行以下代碼建立爬蟲專案
scrapy startproject NovelDemo
1、定義item類,設定要爬取物件的屬性
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class NoveldemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
index = scrapy.Field()
chapter = scrapy.Field()
content = scrapy.Field()
2、創建Spider類
創建spider類的方法
scrapy genspider name domain
利用以下命令創建Spider類
scrapy genspider perfect tianxiabachang.cn
perfect.py檔案如下:
import scrapy, requests
from pandas import read_csv, DataFrame
from NovelDemo.items import NoveldemoItem
from lxml import etree
from re import match
class PerfectSpider(scrapy.Spider):
name = 'perfect'
allowed_domains = ['tianxiabachang.cn']
start_urls = ['http://tianxiabachang.cn/']
def parse(self, response):
df = DataFrame(read_csv('D:/fictions/完美世界[清洗后].csv'))
index, cols = df.index, df.columns
item = NoveldemoItem()
for row in index:
item['index'] = row
item['chapter'] = '\n' + df.loc[row, cols[1]] + '\n'
res = requests.get(url=df.loc[row, cols[2]])
res.encoding = 'utf-8'
text = res.text
html = etree.HTML(text)
content = []
for i in html.xpath("//div[@id='content']/text()"):
paragraph = str(i).strip()
isMatched = match('.*第[\u4e00-\u9fa5]+章.*', paragraph)
if not isMatched:
content.append(paragraph)
item['content'] = '\n'.join(content)
yield item
pipelines.py檔案如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from pymysql import connect
from time import time
class NoveldemoPipeline:
def __init__(self):
self.conn = connect(
host='localhost',
user='root',
password='5180',
port=3306,
db='fictions',
charset='utf8'
)
self.cur = self.conn.cursor()
self.start = time()
self.end = 0
def process_item(self, item, spider):
# print('{}: {}'.format(item['index'], item['chapter']))
# print(item['content'])
index, chapter, content = item['index'] + 1, item['chapter'], item['content']
sql = "update perfect set chapter = %s, content = %s where id = %s;"
count = self.cur.execute(sql, (chapter, content, index))
if count > 0:
print('{} 抓取成功!'.format(chapter))
self.conn.commit()
def close_spider(self, spider):
if self.cur:
self.cur.close()
if self.conn:
self.conn.close()
print('釋放資源!')
self.end = time()
print('爬取耗時:{:.2f}m'.format((self.end - self.start) / 60))
settings.py檔案如下:
BOT_NAME = 'NovelDemo'
SPIDER_MODULES = ['NovelDemo.spiders']
NEWSPIDER_MODULE = 'NovelDemo.spiders'
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
'NovelDemo.pipelines.NoveldemoPipeline': 300,
}
main.py檔案如下:
from scrapy import cmdline
crawler = 'scrapy crawl perfect --nolog'
# crawler = 'scrapy crawl perfect'
cmdline.execute(crawler.split())
main.py檔案存放在NovelDemo目錄下,然后從這里啟動爬蟲
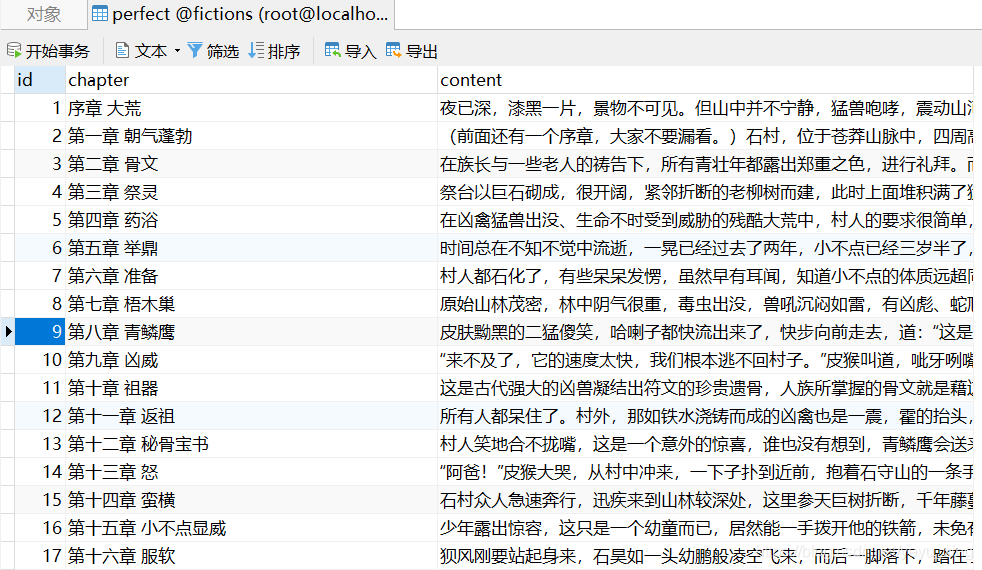
查看perfect資料表的資料:
四、合并成為txt檔案
from pymysql import connect
conn, cur = None, None
try:
conn = connect(host='localhost',
user='root',
password='5180',
port=3306,
db='fictions',
charset='utf8')
cur = conn.cursor()
except Exception as e:
print(e)
else:
sql = 'select * from perfect;'
cur.execute(sql)
for row in cur.fetchall():
with open('D:/fictions/完美世界.txt', 'a+', encoding='utf-8') as file:
chapter = row[1]
content = row[2]
file.write(chapter)
file.write(content)
file.flush()
print('{} 已保存進txt檔案!'.format(chapter))
finally:
if cur:
cur.close()
if conn:
conn.close()
最后將生成的TXT檔案匯入手機小說閱讀器查看:
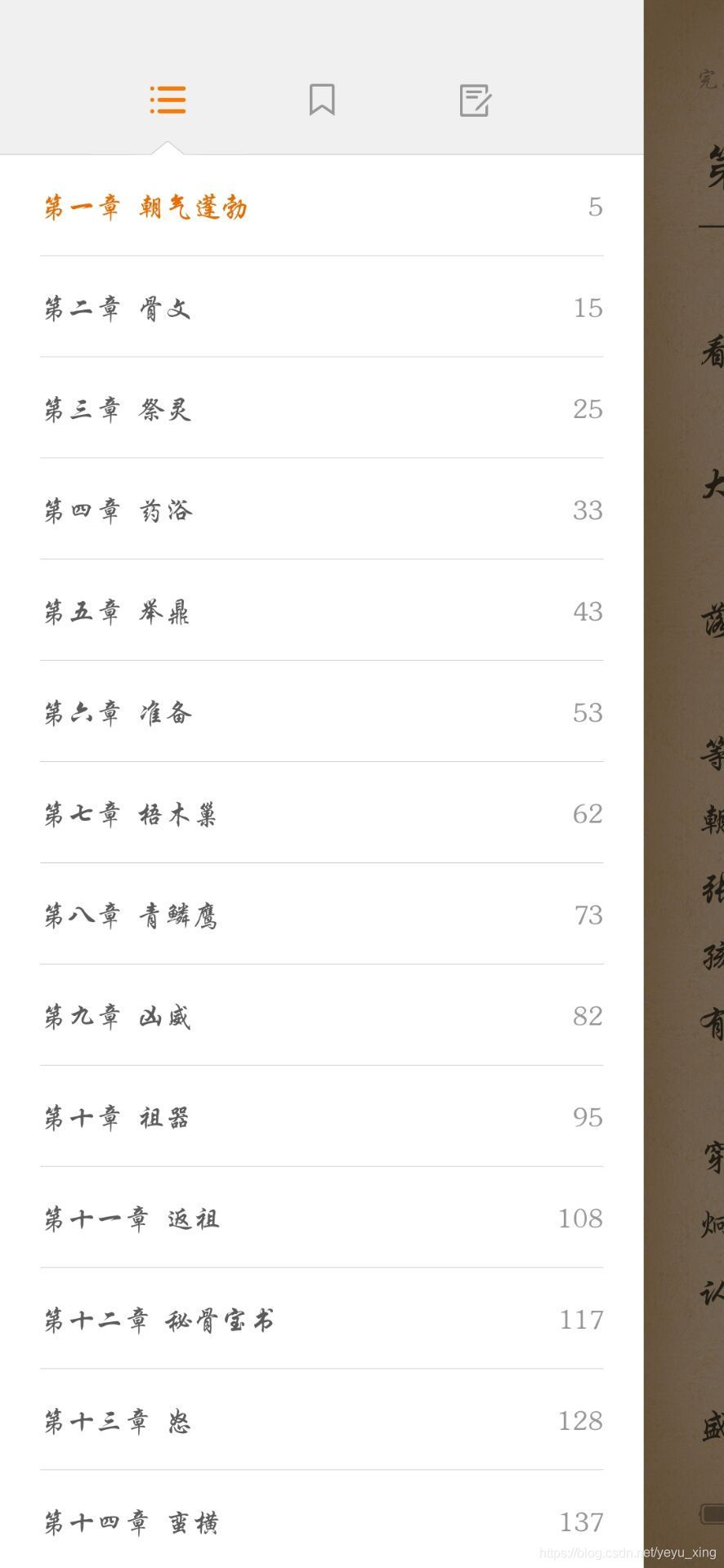

完美!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/135140.html
標籤:其他
上一篇:python資料爬蟲專案
下一篇:anaconda虛擬環境教程大全