論文地址:Some Commonly Used Speech Feature Extraction Algorithms
前言
語言是一種復雜的自然習得的人類運動能力,成人的特點是通過大約100塊肌肉的協調運動,每秒發出14種不同的聲音,說話人識別是指軟體或硬體接收語音信號,識別語音信號中出現的說話人,然后識別說話人的能力,特征提取是通過將語音波形以相對最小的資料速率轉換為引數表示形式進行后續處理和分析來實作的,因此,可接受的分類是從優良和優質的特征中衍生出來的,Mel頻率倒譜系數(MFCC)、線性預測系數(LPC)、線性預測倒譜系數(LPCC)、線譜頻率(LSF)、離散小波變換(DWT)和感知線性預測(PLP)是本章討論的語音特征提取技術,這些方法已經在廣泛的應用中進行了測驗,使它們具有很高的可靠性和可接受性,研究人員對上述討論的技術做了一些修改,使它們更不受噪音影響,更健壯,消耗的時間更少,總之,沒有一種方法優于另一種,應用范圍將決定選擇哪種方法,
本文主要的關鍵技術:mel頻率倒譜系數(MFCC),線性預測系數(LPC),線性預測倒譜系數(LPCC),線譜頻率(LSF),離散小波變換(DWT),感知線性預測(PLP)
1 介紹
人類通過言語來表達他們的感情、觀點、觀點和觀念,語音生成程序包括發音、語音和流利性[1,2],這是一種復雜的自然習得的人類運動能力,在正常成年人中,這項任務是通過脊椎和顱神經連接的大約100塊肌肉協調運動,每秒發出大約14種不同的聲音,人類說話的簡單性與任務的復雜性形成對比,這種復雜性有助于解釋為什么語言對與神經系統[3]相關的疾病非常敏感,
在開發能夠分析、分類和識別語音信號的系統方面已經進行了幾次成功的嘗試,為這類任務所開發的硬體和軟體已應用于保健、政府部門和農業等各個領域,說話人識別是指軟體或硬體接收語音信號,識別語音信號中出現的說話人,并在[4]之后識別說話人的能力,說話人的識別執行的任務與人腦執行的任務類似,這從語音開始,語音是說話人識別系統的輸入,一般來說,說話人的識別程序主要分為三個步驟:聲音處理、特征提取和分類/識別[5],
在提取語音[6]的重要屬性并進行識別之前,對語音信號進行去噪處理,特征提取的目的是通過給定數量的信號分量來描述語音信號,這是因為聲學信號中的所有資訊處理起來都過于繁瑣,有些資訊與識別任務無關[7,8],
特征提取是通過以相對較低的資料速率將語音波形轉換為引數表示形式進行后續處理和分析來完成的,這通常稱為前端信號處理[9,10],它將經過處理的語音信號轉換成一種簡潔而有邏輯的表示形式,比實際信號更有鑒別性和可靠性,前端是序列中的初始元素,后續特征(模式匹配和speaker建模)的質量受到前端[10]質量的顯著影響,
因此,可接受的分類是從優良和優質的特征中衍生出來的,在當前自動說話人識別(ASR)系統,特征提取的程序通常被發現表示相對可靠的幾個條件相同的語音信號,即使在環境條件改變或發言人,同時保留的部分描述語音信號中的資訊(7、8),
特征提取方法通常為每個語音信號提取一個多維特征向量,語音信號的引數化表示方法有很多種,如感知線性預測(PLP)、線性預測編碼(LPC)和mel-頻率倒譜系數(MFCC),MFCC是最有名和非常受歡迎的[9,12],特征提取是說話人識別中最相關的部分,語音特征在區分說話人與其他[13]人的程序中起著至關重要的作用,特征提取在不損害語音信號[14]功率的前提下,降低了語音信號的幅度,
在特征提取之前,首先進行預處理階段的序列,預處理步驟是預強調,這是通過一個FIR濾波器[15]來實作的,它通常是一個一階有限脈沖回應(FIR)濾波器[16],接著是幀阻塞,這是一種將語音信號分割成幀的方法,它消除了存在于語音信號[17]的開始和結束處的聲學介面,
然后將加框的語音信號加窗,帶通濾波器是一個合適的視窗[15],用于最小化每幀開始和結束時的不均勻性,最著名的兩類窗戶是漢明窗和矩形窗[18],它增加了諧波的銳度,消除了信號的不連續,減少了幀零的開始和結束,它也減少了由重疊[17]形成的光譜失真,
2 Mel倒頻譜系數(MFCC)
Mel頻率倒譜系數(MFCC)最初被建議用于識別連續口陳述句子中的單音節詞,但不用于說話人識別,MFCC計算是對人耳聽覺系統的一種復制,它假設人耳是一個可靠的說話人識別器[19],以人為地實作人耳的作業原理,MFCC特征來源于人耳臨界帶寬的差異,低頻線性間隔的頻率濾波器和高頻對數間隔的頻率濾波器被用來保留語音信號的語音重要特性,語音信號通常包含不同頻率的音調,每個音調都有一個實際的頻率,f (Hz),主觀音高在梅爾等級上計算,梅爾頻率標度在1000赫茲以下為線性頻率間隔,在1000赫茲以上為對數頻率間隔,1 kHz音高,高于感知可聽閾值40 dB,定義為1000 mels,作為參考點[20],
MFCC是在濾波器組的幫助下實作信號分解的,MFCC給出了在Mel頻標[21]上顯示的短期能量的實對數的離散余弦變換(DCT),MFCC用于識別機票預訂、電話號碼和語音識別系統的安全性,為了獲得更好的魯棒性,有人對基本的MFCC演算法進行了一些修改,比如在應用dct0之前將log- mel振幅提升到適當的功率(大約2或3),并減少低能部分[4]的影響,
2.1 演算法說明,優缺點
MFCC是在扭曲的頻率尺度上推匯出的倒譜系數,以人類聽覺感知為中心,在MFCC的計算中,首先對語音信號進行加窗處理,將語音信號分割成幀,由于高頻共振峰的振幅比低頻共振峰的振幅要小,所以高頻共振峰的振幅要比低頻共振峰的振幅小,加窗后,應用快速傅里葉變換(FFT)求出各幀的功率譜,然后,利用mel-scale對功率譜進行濾波器組處理,將功率譜變換為對數域后,將離散余弦變換應用于語音信號,計算MFCC系數[5],計算任意頻率的mels的公式是[19,22]
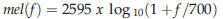
其中mel(f)為頻率(mels), f為頻率(Hz),
MFCCs的計算公式為[9,19]:
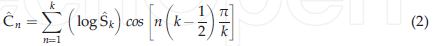
其中k是mel倒譜系數的個數,$\hat{S}_k$是filterbank的輸出,$\hat{C}_n$是最終的mfcc系數,
MFCC處理器的框圖如圖1所示,它總結了獲得所需系數的所有程序和步驟,MFCC比高頻區域更能有效地表示低頻區域,因此,它可以計算低頻范圍內的共振峰,并描述聲道共振,它是典型的說話人識別應用的前端程式,降低了噪聲干擾的脆弱性,會話不一致性小,易于挖掘[19],此外,當源特征是穩定和一致的(音樂和語音)[23]時,它是聲音的完美表現,此外,它還可以從采樣信號中捕獲頻率最大為5千赫的資訊,這封裝了人類[9]發出的聲音的大部分能量,
倒譜系資料說在與人類聲音有關的某些模式識別問題中是準確的,它們廣泛應用于說話人識別和語音識別[21]中,其他共振峰也可能在1khz以上,而且高頻[19]范圍內的濾波器間距較大,不能有效地考慮共振峰,MFCC特征在背景噪聲存在的情況下并不完全準確[14,24],可能不適用于泛化[23],
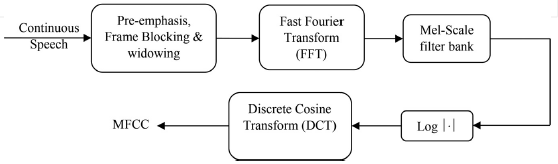
圖1 MFCC處理器的框圖
3 線性預測系數(LPC)
線性預測系數(LPC)模擬人體聲道[16],具有魯棒性強的語音特征,它通過近似共振峰來評估語音信號,從語音信號中去除共振峰的影響,并估計殘留語音信號的濃度和頻率,結果表明信號的每個樣本都是前一個樣本的直接結合,差分方程的系數表征共振峰,因此,LPC需要近似這些系數[25],LPC是一種功能強大的語音分析方法,它作為一種共振峰估計方法獲得了廣泛的應用,
共振峰出現的頻率稱為共振峰頻率,因此,使用這種技術,通過計算滑動視窗上的線性預測系數,并在隨后的線性預測濾波器[17]的頻譜中找到峰值,可以預測語音信號中共振峰的位置,LPC有助于在低位元率下對高質量語音進行編碼[13,26,27],
從線性預測倒譜系數(LPCC)、對數面積比(LAR)、反射系數(RC)、線譜頻率(LSF)和反正弦系數(Arcus Sine coefficients)[13]可以推匯出LPC的其他特征,LPC通常用于語音重建,LPC方法一般應用于音樂和電氣公司,用于制造移動機器人,在電話公司,小提琴和其他弦樂器的音調分析[4],
3.1 演算法說明,優缺點
采用線性預測的方法,通過減小輸入語音與估計語音[28]之間的均方誤差,得到等效于聲道的濾波系數,語音信號的線性預測分析是對給定語音樣本在特定時間段內的預測,其預測結果是前一樣本的線性加權集合,語音生成的線性預測模型為[13,25]

其中^s為預測樣本,s為語音樣本,p為預測系數,
預測誤差為[16,25]:

因此,加窗信號的每一幀都是自相關的,而自相關值最高的是線性預測分析的階數,然后是LPC分析,每一幀的自相關被轉換成LPC引數集,這些引數集由LPC系數[26]組成,獲取LPC的程序摘要如圖2所示,LPC可由[7]推導
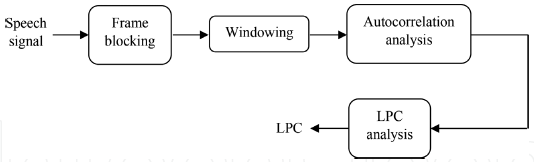
圖2 LPC處理器的框圖,

其中$a_m$為線性預測系數,$k_m$為reflection coefficient(反射系數)
線性預測分析能有效地從給定的語音[16]中選擇聲道資訊,它以計算速度和準確度著稱,LPC很好地代表了穩定一致的[23]源行為,此外,它還被用于語音識別系統中,主要目的是提取聲道特性[25],它對語音引數的估計非常準確,計算效率也相對較高[14,26],傳統的線性預測方法存在自相關系數失真的問題,LPC估計值對量化噪聲[30]具有很高的敏感性,可能不適用于泛化[23],
4 線性預測倒譜系數(LPCC)
線性預測倒譜系數(LPCC)是由LPC計算的頻譜包絡[11]得到的倒譜系數,LPCC是LPC對數幅度譜的傅里葉變換的系數[30,31],倒譜分析是語音處理領域中常用的一種分析方法,因為它能夠以有限的[31]特征來完美地表征語音波形和特征,
Rosenberg和Sambur觀察到相鄰的預測系數高度相關,因此,具有較少相關特征的表征更有效,LPCC就是一個典型的例子,LPC與LPCC的關系最早是由Atal在1974年推匯出來的,從理論上講,在相位信號[32]最小的情況下,將LPC轉換為LPCC相對容易,
4.1 演算法說明,優缺點
在語音處理中,LPCC類似于LPC,由語音波形的采樣點計算得到,橫軸是時間軸,縱軸是振幅軸[31],
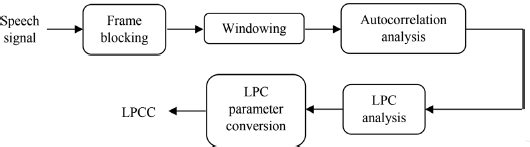
圖3,LPCC處理器的框圖,
LPCC處理器如圖3所示,它形象地解釋了獲得LPCC的程序,LPCC可以用[7,15,33]來計算

其中am為線性預測系數,Cm為倒譜系數,
LPCC對噪聲[30]的脆弱性較低,與LPC特性[31]相比,LPCC特性的錯誤率更低,高階倒譜系數在數學上是有限的,因此從低階倒譜系數轉移到高階[34]倒譜系數時,產生了極為廣泛的方差陣列,類似地,LPCC估計對量化噪聲[35]非常敏感,高頻語音信號的倒譜分析給出了低頻域[29]的小原始碼波器可分性,低階倒譜系數對譜斜率敏感,而高階倒譜系數對噪聲[15]敏感,
5 線譜頻率(LSF)
線譜對(LSP)的單線稱為線譜頻率(LSF),LSF定義了發生在人類聲道內連接管模型中的兩種共振情況,該模型考慮了鼻腔和口腔的形狀,為線性預測的基本生理重要性奠定了基礎,這兩種共振情況定義了聲門[36]處聲道要么完全打開要么完全閉合,這兩種情況產生兩組共振頻率,每組共振頻率的數目由連接管的數量來推斷,每一種情況下的共振都是相應的奇偶線譜,并交織成一個奇異上升的LSF[36]群,
LSF表示法是由Itakura[37,38]提出的,用來代替線性預測引數表示法,在語音編碼領域,人們已經認識到該演算法比其他線性預測引數化演算法(LAR和RC)具有更好的量化特性,LSF圖能夠在不影響合成語音質量的前提下,將傳輸線性預測資訊的位元率降低25% ~ 30%[3840],除量子化外,預測器的LSF圖也適用于插值,從理論上講,將lsf域平方量化誤差與感知相關的對數譜相聯系的靈敏度矩陣是對角的[41,42],這可以從這一點得到啟發,
5.1 演算法說明,優缺點
LP建立在語音信號可以由式(3)定義的點上
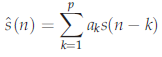
其中k是時間指數,p是線性預測的階數,$\hat{s}(n)$是預測信號,$a_k$是LPC系數,
通過自相關或協方差的方法確定$a_k$系數以減小預測誤差,公式(3)可以在頻域中用z-Transform進行修改,因此,語音信號的一小部分預計將作為輸出給全極點濾波器H(z),新公式是
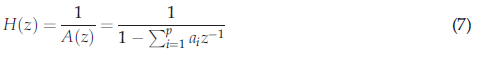
其中H(z)是全極點濾波器,A(z)是LPC分析濾波器
為了計算LSF系數,一個逆多項式濾波器被分成兩個多項式P(z)和Q(z)[36,38,40,41]:
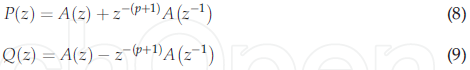
其中P(z)是聲門閉合的聲道,Q(z)是階P的LPC分析過濾器,為了將LSF轉換回LPC,使用以下公式[36,41,43,44]

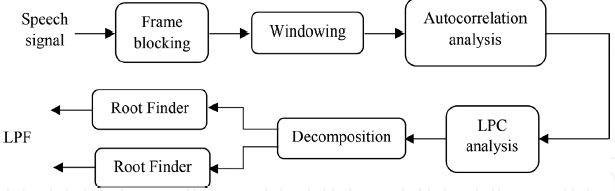
圖4.LSF處理器框圖,
LSF處理器的框圖如圖4所示,LSF在語音壓縮領域的應用最為突出,并擴展到說話人識別和語音識別領域,這項技術在其他領域的應用也受到限制,LSF已被研究用于樂器識別和編碼,LSF還被應用于動物噪音識別、個人工具識別和金融市場分析,LSF的優點包括其對光譜靈敏度的定位能力,它們可以表征帶寬和共振位置,并強調了譜峰定位的重要方面,在大多數情況下,LSF表示為后續的分類[36]提供了一個幾乎最小的資料集,
由于LSF以低于原始輸入樣本的資料速率表示光譜形狀資訊,因此,在LSP領域中仔細使用處理和分析方法可以降低對原始輸入資料本身進行操作的替代技術的復雜性,LSF在聲道資訊從語音編碼器到解碼器的傳輸中起著重要的作用,其良好的量化特性使其得到了廣泛的應用,LSP引數的生成可以使用多種復雜的方法來完成,主要的問題是求出Eqs中定義的P和Q多項式的根,(8)和(9),這可以通過標準的根解法或更模糊的方法得到,通常在余弦域[36]中執行,
6 離散小波變換
小波變換(WT)理論的核心是在[45]的時域和頻域使用不同尺度的信號分析,在理論物理學家Alex Grossmann的支持下,Jean Morlet引入了小波變換,該變換允許以增強的時間解析度識別高頻事件[45 47],小波是一種有效的有限持續時間的波形,其平均值為零,許多小波也表現出正交性,這是緊湊信號表示[46]的理想特征,小波變換是一種信號處理技術,可以高效地表示現實生活中的非平穩信號[33,46],它能夠在時域和頻域同時從瞬態信號中挖掘資訊[33,45,48],
利用連續小波變換(CWT)將連續時間函式分解成小波,然而,由于存在資訊冗余,計算CWT所有可能的尺度和平移需要大量的計算作業,因此限制了它的使用[45],離散小波變換(DWT)是小波變換(WT)的擴展,提高了分解程序[48]的靈活性,它是一種非常靈活和高效的信號子帶擊穿方法[46,49],在早期的應用中,線性離散化用于連續小波變換的離散化,Daubechies和其他人開發了一種正交DWT,專門用于分析尺度集(二元離散化)[47]上的有限觀測集,
6.1 演算法說明,優缺點
小波變換將信號分解成一組稱為小波的基本函式,小波由一個稱為母波的原型小波通過擴展和移位得到,小波變換的主要特點是利用可變視窗掃描頻譜,提高了分析的時間解析度[45,46,50],
wt將信號分解到經過翻譯和擴展的母波上,母波是一個能量有限且衰減快的時間函式,單個小波的不同版本是互相正交的,連續小波變換(CWT)由[33,45,50]給出
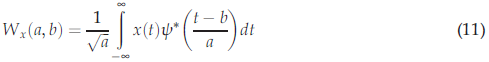
其中$\psi (t)$是母小波,a和b是連續引數,
小波變換系數是一個展開式,一個特定的位移代表原始信號與經過平移和放大的母波的對應程度,因此,與特定信號相關的CWT (a, b)的系數群是原始信號相對于母波[45]的小波表示,由于連續小波變換具有較高的冗余度,因此利用小尺度分析信號,每個尺度上的平移量各不相同,即離散化尺度和a 2j、b 2jk的平移引數,得到DWT,DWT理論需要[33]給出的尺度函式和小波函式兩組相關函式:
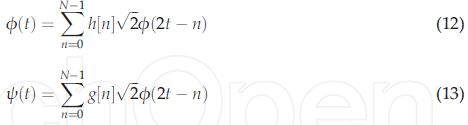
其中$\phi (t)$是標度函式,$\psi (t)$是小波函式,h[n]是低通濾波器的脈沖回應,g[n]是高通濾波器的脈沖回應,
有幾種方法可以使CWT離散化,連續信號的dwt也可由[45]給出:
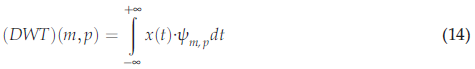
其中$\psi _{m,p}$是小波函式基,m是擴張引數,p是平移引數,
因此$\psi _{m,p}$被定義為:

離散信號的DWT來源于CWT,定義為
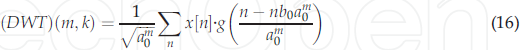
其中$g(*)$是母小波,x[n]是離散信號,母小波可以通過選擇縮放引數$a=a_0^m$和平移引數$b=nb_0a_0^m$(常數取$a_0>1$,$b_0>1$,而m和n被賦予一組正整數)來離散地放大和平移,
利用一對濾波器h[n]和g[n],即具有$g[n]=(-1)^{1-n}h[n]$性質的正交鏡濾波器(quadrature mirror filters),可以有效地實作尺度變換和小波函式,輸入信號經過低通濾波和高通濾波,分別得到近似分量和細節分量,圖5總結了這一點,利用相同的低通濾波器和高通濾波器對各階段的近似信號進行進一步分解,得到下一階段的近似分量和細節分量,這種分解稱為二元分解[33],
DWT引數包含不同頻率尺度的資訊,這增強了在相應頻段[33]中獲得的語音資訊,DWT能夠按比例對輸入元素的方差進行磁區,這是一個額外的優勢,這種劃分導致了尺度相關小波方差的觀點,它在很多方面等價于我們更熟悉的頻率相關的傅里葉功率譜[47],經典的離散分解方案是二元的,不能滿足直接用于引數化的所有要求,DWT確實為有效的語音分析[51]提供了足夠的頻帶數,由于輸入信號的長度是有限的,由于邊界[50]處的不連續性,使得小波系數在邊界處的變化非常大,
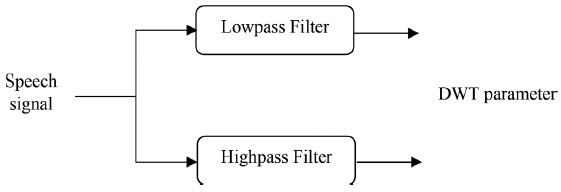
圖5 DWT的方框圖
7. 感知線性預測(PLP)
感知線性預測(PLP)技術將關鍵頻帶、強度-響度壓縮和等響度預強調相結合,用于語音相關資訊的提取,它植根于非線性樹皮規模,最初是打算用于語音識別任務中消除說話人相關的特征[11],PLP給出了一個符合平滑的短期頻譜的表示,該短期頻譜已被均衡和壓縮,類似于人類的聽覺,使其類似于MFCC,在PLP方法中,我們復制了聽覺的幾個顯著特征,然后用自回歸全極點模型[52]近似地表示類似聽覺的語音頻譜,PLP給出了高頻下的最小解析度,這意味著基于聽覺濾波器組的方法,同時給出了與倒譜分析相似的正交輸出,它使用線性預測來平滑光譜,因此,它的名字是感知線性預測[28],PLP是光譜分析和線性預測分析的結合,
7.1 演算法說明,優缺點
為了計算語音的PLP特征,計算了語音的快速傅里葉變換(FFT)和幅度的平方,這給出了功率譜估計,然后在1樹皮間隔上應用梯形濾波器,將重疊的臨界帶濾波器回應整合到功率譜中,這能有效地把高頻壓縮成窄帶,在樹皮扭曲的頻率尺度上的對稱頻域卷積允許低頻掩蓋高頻,同時平滑頻譜,頻譜隨后被預先強調,以近似人類聽覺在各種頻率下的不均勻靈敏度,對譜振幅進行壓縮,減小了譜共振的振幅變化,通過離散傅里葉反變換(IDCT)得到自相關系數,進行譜平滑,求解自回歸方程,將自回歸系數轉換為倒譜變數[28],計算樹皮鱗片頻率的公式為
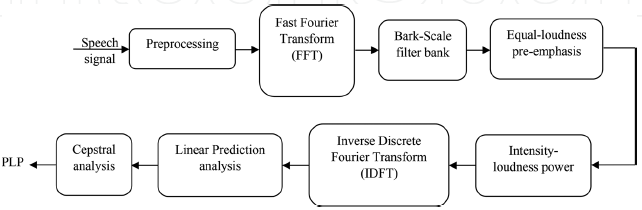
圖6,PLP處理器的方框圖
| 濾波器系數 | 濾波器的形狀 | 建模方法 | 速度的計算 | 系數型別 | 抗噪聲能力 | 對量化/附加噪聲的靈敏度 | 可靠性 | 捕獲頻率 | |
|
Mel倒頻譜系數(MFCC) |
Mel | 三角形 | 人類聽覺系統 | 高 | 倒頻譜 | 中等 | 中等 | 高 | 低 |
|
線性預測系數(LPC) |
線性預測 | 線性 | 人類聲道 | 高 | 自相關系數 | 高 | 高 | 高 | 低 |
| 線性預測倒譜系數(LPCC) | 線性預測 | 線性 | 人類聲道 | 中等 | 倒頻譜 | 高 | 高 | 中等 | 低&中等 |
| 譜線頻率(LSF) | 線性預測 | 線性 | 人類聲道 | 中等 | 頻譜 | 高 | 高 | 中等 | 低&中等 |
| 離散小波變換(DWT) | 低通&高通 | - | - | 高 | 小波 | 中等 | 中等 | 中等 | 低&中等 |
| 感知線性預測(PLP) | Bark | 梯形 | 人類聽覺系統 | 中等 | 倒頻譜&自相關 | 中等 | 中等 | 中等 | 低&中等 |
表1 特征提取技術的比較,

其中,bark(f)為頻率(bark), f為頻率(Hz),
PLP的識別效果優于LPC[28],因為它有效地抑制了說話人相關資訊[52],是對傳統LPC的改進,此外,它還增強了與揚聲器無關的識別性能,并且對噪聲、信道變化和麥克風[53]具有魯棒性,PLP精確重構了自回歸噪聲分量[54],基于PLP的前端對共振峰頻率的任何變化都很敏感,
圖6顯示了PLP處理器,顯示了獲取PLP系數所需的所有步驟,PLP對譜傾斜的敏感性較低,這與我們的研究結果一致,即對譜傾斜的語音判斷相對不敏感,此外,PLP分析依賴于整體光譜平衡(共振峰振幅)的結果,共振峰振幅易受記錄設備、通信信道和附加噪聲[52]等因素的影響,此外,時間-頻率解析度和有效采樣的短期表現在一個特設的方式解決了[54],
表1顯示了上述六種特征提取技術的比較,盡管用于研究的特征提取演算法的選擇是獨立的,但是本表能夠根據選擇任何特征提取演算法時的主要考慮因素來描述這些技術,這些考慮因素包括計算速度,抗噪聲性和對附加噪聲的敏感性,該表還可作為考慮在所討論的任何兩個或多個演算法之間進行選擇時的指南,
8. 結論
MFCC、LPC、LPCC、LSF、PLP和DWTare是一些用于提取語音信號中相關資訊的特征提取技術,用于語音識別和識別,這些技術經受住了時間的考驗,并在語音識別系統中得到了廣泛的應用,語音信號是一種慢時變的準平穩信號,當在5 ~ 100毫秒的足夠短的時間內觀察到它時,它的行為是相對平穩的,因此,包括MFCC、LPCC和PLP在內的短時譜分析常被用于從語音信號中提取重要資訊,噪聲是特征提取以及說話人識別程序中所面臨的一個嚴峻挑戰,隨后,研究人員對上述討論的技術進行了一些修改,使它們更不受噪音影響,更健壯,消耗的時間更少,這些方法也被用于聲音的識別,提取的資訊將被輸入分類器進行識別,上述特征提取方法可以用MATLAB實作,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/138119.html
標籤:其他
上一篇:leetcode - 反轉鏈表
下一篇:高級排序演算法