1、希爾排序演算法
希爾排序演算法是根據它的發明者康納德.希爾的名字命名的,此演算法從根本上而言就是插入排序演算法的一種改進,如同在插入排序中所做的那樣,本演算法的關鍵內容是對遠距離而非相鄰的資料項進行比較,當演算法回圈遍歷資料集合的時候,每個資料項間的距離會縮短,直到演算法對相鄰資料項進行比較時才終止,
希爾排序演算法采用升序方式對遠距離的元素進行排序,序列必須從1開始,但是可以按照任意數量進行自增,一種好的可用的自增方法時基于下列代碼段的:
while(h<-numElements/3); h=h*3+1;
這里的numElements表示了資料集合內代拍元素的數量,例如一個陣列,
例如,如果上述代碼產生的序列數是4,那么就是對資料集合內每次第4個元素進行排序,接著采用下列代碼來選擇一個新的序列數:
h=(h-1)/3;
然后,對后續的h個元素進行排序,一次類推,
陣列類:


public class CArray { private int[] arr; private int upper; private int numElements; public CArray(int size) { arr = new int[size]; upper = size - 1; numElements = 0; } public void Insert(int item) { arr[numElements] = item; numElements++; } public void DisplayElements() { for (int i = 0; i <= upper; i++) { Console.Write($"{arr[i]} "); } Console.WriteLine("\r"); } public void Clear() { for (int i = 0; i <= upper; i++) { arr[i] = 0; } numElements = 0; } }View Code
下面就來看一看希爾排序演算法的代碼,
public void ShellSort() { int inner, temp; int h = 3; while (h > 0) { for (int outer = h; outer <= numElements - 1; outer++) { temp = arr[outer]; inner = outer; while ((inner > h - 1) && arr[inner - h] >= temp) { arr[inner] = arr[inner - h]; inner -= h; } arr[inner] = temp; } h = (h - 1) % 3; } }
測驗此演算法的代碼如下所示:
const int SIZE = 19; CArray theArray = new CArray(SIZE); Random random = new Random(); for (int index = 0; index < SIZE; index++) { theArray.Insert(random.Next(100) + 1); } Console.WriteLine(); theArray.DisplayElements(); Console.WriteLine(); theArray.ShellSort(); theArray.DisplayElements();
運行結果如下:

希爾排序演算法經常被認為是一種很好的高級排序演算法,這是因為它十分容易實作,甚至是對包含好幾萬個元素的資料集合而言其性能也是可以接受的,
2、歸并排序演算法
歸并排序演算法是一個非常好的遞回演算法的實體,這個演算法把資料集合分成兩個部分,然后對每部分遞回地進行排序,當兩個部分都排序好時,再用合并程式把他們組合在一起,
在堆資料集合進行排序的時候,操作十分簡單,假設在資料集合內有下列這些資料:71、54、58、29、31、78、2和77,首先,這里會把資料集合分成兩個獨立的子集合,即子集合71、54、58、29,以及子集合31、78、2、77.接著就是對每一部分進行排序,即子集合29、54、58、71,以及子集合2、31、77、78.然后把兩個子集合進行合并,即2、29、31、54、58、71、77和78,合并程序會比較兩個資料子集合(存盤在臨時陣列內)中的第一個元素,并且把較小值復制給另外一個陣列,而沒有被添加到第三個陣列內的元素隨后會與另一個陣列內的下一個元素進行比較,當然還是會把較小的元素添加到第三個陣列內,而且這個程序會持續到兩個陣列內都沒有資料了為止,
但是,如果其中一個陣列的元素比另外一個陣列的元素先用完,那么會怎么樣呢?這種情況很可能會發生,因而演算法對這種情況進行了規定,在主回圈結束以后,當且僅當兩個陣列的其中一個還留有資料時可以使用兩個額外的回圈用來解決這個問題,
現在就來看看執行合并排序的代碼,首先是兩個方法MergeSort和RecMergeSort,第一個方法簡單呼叫了遞回子程式RecMergeSort,而這個子程式對陣列進行排序:
public void MergeSort() { var tempArray = new int[numElements]; RecMergeSort(tempArray, 0, numElements - 1); } public void RecMergeSort(int[] tempArray, int lbound, int ubound) { if (lbound == ubound) { return; } var mid = (int)(lbound + ubound) / 2; RecMergeSort(tempArray, lbound, mid); RecMergeSort(tempArray, mid + 1, ubound); Merge(tempArray, lbound, mid + 1, ubound); }
在RecMergeSort方法中,第一個if陳述句是基于遞歸情況的,當條件為真時,就會回傳到呼叫它的程式,否則,就要找到陣列的中間位置,并且在陣列的后半部分(第一個呼叫RecMergeSort)遞回地呼叫子程式,然后是在陣列的前半部分(第二個呼叫RecMergeSort)遞回地呼叫子程式,最終,通過呼叫Merge方法來把兩個部分合并成在一個完整的陣列,下面就是Merge方法的實作代碼:
public void Merge(int[] tempArray, int lowp, int highp, int ubound) { int lbound = lowp; int mid = highp - 1; int n = (ubound - lbound) + 1; int j = 0; while ((lowp <= mid) && (highp <= ubound)) { if (arr[lowp] < arr[highp]) { tempArray[j] = arr[lowp]; j++; lowp++; } else { tempArray[j] = arr[highp]; j++; highp++; } } while (lowp <= mid) { tempArray[j] = arr[lowp]; j++; lowp++; } while (highp <= ubound) { tempArray[j] = arr[highp]; j++; highp++; } for (j = 0; j <= n - 1; j++) { arr[lbound + j] = tempArray[j]; } }
這個方法每次由RecMergeSort子程式呼叫來執行一個初步的排序,為了更好地實體說明這個方法時如何與RecMergeSort一起操作的,這里在Merge方法的末尾添加了這樣一行代碼:
this.DisplayElements();
用了這行代碼,在排序完成之前就可以觀察到在不同臨時狀態下陣列的情況,輸出如下圖所示:
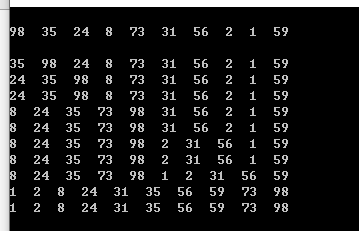
第一行顯示了初始狀態的陣列,第二行則顯示正在對陣列的前半部分開始進行排序,一直到第五行,前半部分的排序才全部完成,第六行顯示正在對陣列的后半部分開始進行排序,而第九行顯示對陣列兩個部分的排序都全部完成了,第十行是最終合并后的輸出結果,而第十一行只是對另外一個堆ShowArray方法的呼叫,
3、堆排序演算法
堆排序演算法利用了一種被稱為堆的資料結構,堆和二叉樹比較類似,但是又有一些顯著的差異,
3.1、堆構造
堆資料類似于二叉樹,但是又不完全相同,首先,通常采用陣列而不是節點參考的方式來構造堆,并且,堆有兩個非常重要的條件:
1、堆必須是完整的,這就意味著每一行都必須有資料填充
2、每個節點所包含的資料要大于或等于此節點下方孩子節點們所包含的資料
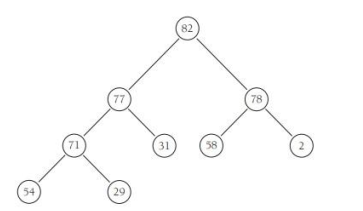
下圖顯示了堆的一個實體:
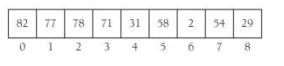
下圖則說明了存盤堆的陣列:
存盤在堆內的資料由Node類來創建,然而,這個特殊的Node類將只存盤一種資料,即它的主值或者鍵值,這里不需要對其他節點的任何參考,但是會希望用到適合此資料的類,這樣在需要的時候就可以很容易地改變存盤在堆內的資料的型別,Node類的代碼如下:
public class Node { public int data; public Node(int key) { data = key; } }
通過把節點插入到堆陣列內的方式可以構造堆,而堆陣列的元素就是堆的節點,這里始終要把新節點放置在陣列末尾的空元素內,問題是這樣做很可能會打破對的構造條件,因為新節點的資料值可能會大于它上面某些節點的值,為了恢復陣列從而達到正確的堆構造條件,需要把新節點向上移動,一直要把它移動到陣列內合適的位置上為止,這里使用被稱為ShiftUp的方法來實作此操作,代碼如下所示:
public class Heap { Node[] heapArray = null; private int maxSize = 0; private int currSize = 0; public Heap(int maxSize) { this.maxSize = maxSize; heapArray = new Node[maxSize]; } public bool InsertAt(int pos, Node nd) { heapArray[pos] = nd; return true; } public void ShowArray() { for (int i = 0; i < maxSize; i++) { if (heapArray[i] != null) { Console.Write(heapArray[i].data + " "); } } } }
public void ShiftUp(int index) { var parent = (index - 1) / 2; Node bottom = heapArray[index]; while ((index > 0) && (heapArray[parent].data < bottom.data)) { heapArray[index] = heapArray[parent]; index = parent; parent = (parent - 1) / 2; } heapArray[index] = bottom; }
而且下面是Insert方法的實作代碼:
public bool Insert(int key) { if (currSize == maxSize) { return false; } heapArray[currSize] = new Node(key); currSize++; return true; }
這里會把新節點添加到陣列的末尾,這樣做會立刻打破堆構造的條件,所以通過ShiftUp方法來找到新節點在陣列內的正確位置,此方法的引數就是新節點的索引,方法的第一行會計算出此節點的父節點,接著方法會把新節點保存到一個名為bottom的Node變數內,隨后,while回圈會找到新節點的正確位置,方法的最后一行會把新節點從臨時放置的bottom內復制到陣列中正確的位置上,
從堆中移除掉節點始終意味著洗掉最大的節點,這是很容易實作的,因為最大值始終在根節點上,問題是一旦移除掉根節點,堆就不完整了,就需要對其進行重組,下面這個演算法用來使堆再次完整:
1、移除掉根節點,
2、把最后位置上的節點移動到根上,
3、把最后的節點向下移動,直到它在底下為止,
當連續應用這個演算法的時候,就會按照排序順序把資料從堆中移除掉,下面就是Remove方法和ShiftDown方法的實作代碼:
public Node Remove() { Node root = heapArray[0]; currSize--; heapArray[0] = heapArray[currSize]; ShiftDown(0); return root; } public void ShiftDown(int index) { int largerChild; Node top = heapArray[index]; while (index < (int)(currSize / 2)) { int leftChild = 2 * index + 1; int rightChild = leftChild + 1; if ((rightChild < currSize) && heapArray[leftChild].data < heapArray[rightChild].data) { largerChild = rightChild; } else { largerChild = leftChild; } if (top.data >= heapArray[largerChild].data) { break; } heapArray[index] = heapArray[largerChild]; index = largerChild; } heapArray[index] = top; }
呼叫一下:
const int SIZE = 9; Heap heap = new Heap(SIZE); Random random = new Random(); for (int i = 0; i < SIZE; i++) { int ran = random.Next(1, 100); heap.Insert(ran); } Console.WriteLine("Random:"); heap.ShowArray(); Console.WriteLine(); Console.WriteLine("Heap:"); for (int i = (int)SIZE/2-1; i >= 0; i--) { heap.ShiftDown(i); } heap.ShowArray(); for (int i = SIZE-1; i >= 0; i--) { Node node = heap.Remove(); heap.InsertAt(i, node); } Console.WriteLine(); Console.WriteLine("Sorted:"); heap.ShowArray();

第一個for回圈通過向堆內插入亂數的方式開始了構造堆的程序,第二個回圈是恢復堆,而隨后的第三個for回圈則是用Remove方法和ShiftDown方法來重新構造有序的堆,
堆排序的效率還是蠻高的,下面要介紹的快速排序演算法比此演算法速度更快,
4、快速排序演算法
快速排序演算法的效率是實至名歸的,當然這只是針對于大量且通常無序的資料集而言是正確的,如果資料集合很小(含有100個元素或者更少),或者資料是相對有序的,那么就需要采用之前介紹的基礎排序演算法就夠了,
為了理解快速排序演算法的作業原理,假設你是一名教師,現在要把一堆學生的論文按照字母順序進行排序,你可能會選取字母表中間的一個字母,比如字母M,接著把學生名字以字母A到字母M的論文放在一起,再把學生名字以字母N到字母Z開頭的論文放到另外一堆,然后你要利用相同的方法把A~M這堆再分成兩堆,并且把N~Z這堆也再分成兩堆,你要反復這樣的操作直到所有小堆(A~C,D~F,……,X~Z)包含易于排序的兩個元素或三個元素時為止,一旦所有小堆都有序了,你只需要簡單地把這些小堆放在一起就會得到一個有序的論文集合,
如上你已經注意到的那樣,這個程序是遞回,因為每一個堆都會被分成更小的堆,一旦把堆分裂成只包含一個元素,那么這個堆就不能繼續分裂了,而遞回操作也就終止了,
那么人們如何決定在什么位置把陣列一分為二的呢?雖然有很多種選擇,但那是這里將只會選取第一個陣列元素作為開始:
mv = arr[first];
快速排序演算法的代碼:
public void QSort() { RecQSort(0, numElements - 1); } public void RecQSort(int first, int last) { if ((last - first) <= 0) { return; } int part = this.Partition(first, last); RecQSort(first, part - 1); RecQSort(part + 1, last); } public int Partition(int first, int last) { int pivotVal = arr[first]; int theFirst = first; bool okSide; first++; do { okSide = true; while (okSide) { if (arr[first] > pivotVal) { okSide = false; } else { first++; okSide = (first <= last); } } okSide = true; while (okSide) { if (arr[last] <= pivotVal) { okSide = false; } else { last--; okSide = (first <= last); } } if (first < last) { Swap(first, last); this.DisplayElements(); first++; last--; } } while (first <= last); Swap(theFirst, last); this.DisplayElements(); return last; } public void Swap(int item1, int item2) { int temp = arr[item1]; arr[item1] = arr[item2]; arr[item2] = temp; }
快速排序演算法的改進:
如果陣列內的資料是隨機的,俺么選取第一個數值作為“中心點”或者“分割”值是完全合理的,然后,繁殖情況做這樣的選擇將會降低演算法的性能,
一種比較流行的選擇此數值的方法時在陣列內確定中間值,通過把取到的陣列上限除以2的方法就可以得到這個中間值,例如:
theFirst = arr[(int)arr.GetUpperBound(0) / 2];
研究表明使用這種策略可以減少此演算法運行時間的大約5個百分點,
小結
這些演算法比基礎排序演算法在執行速度上快很多,人們普遍認為快速排序是最快的排序演算法,而且應該把它用于大多數排序情況里,構建在幾個.Net框架類別庫中的Sort方法就是用快速排序演算法實作的,這就說明快速排序比其他排序演算法具有優勢,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/138120.html
標籤:其他
上一篇:一些常用的語音特征提取演算法