作者|Renu Khandelwal
編譯|VK
來源|Medium
什么是梯度下降?
梯度下降法是一種減少成本函式的迭代機器學習優化演算法,使我們的模型能夠做出準確的預測,
成本函式(C)或損失函式度量模型的實際輸出和預測輸出之間的差異,成本函式是一個凸函式,
為什么我們需要梯度下降?
在神經網路中,我們的目標是訓練模型具有最優的權值(w)來進行更好的預測,
我們用梯度下降法得到最優權值,
如何找到最優的權值?
這可以用一個經典的登山問題來最好地解釋,

在登山問題中,我們想要到達一座山的最低點,而我們的能見度為零,
我們不知道我們是在山頂上,還是在山的中間,還是非常接近底部,
我們最好的選擇是檢查我們附近的地形,并確定我們需要從哪里下降到底部,我們需要迭代地做這件事,直到沒有更多的下降空間,也就是我們到達底部的時候,
我們將在稍后的文章中討論,如果我們覺得已經到達了底部(區域最小值點),但是還有另一個山的最低點(全域最小值點),我們可以做什么,
梯度下降法幫助我們從數學上解決了同樣的問題,
我們將一個神經網路的所有權值隨機初始化為一個接近于0但不是0的值,
我們計算梯度,?c/?ω,它是成本相對于權重的偏導數,
α是學習率,有助于對梯度下降法調整權重
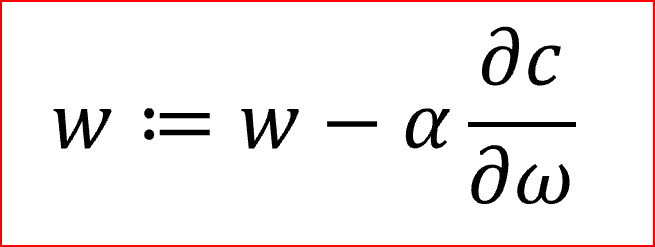
我們需要同時更新所有神經元的權重
學習速率
學習率控制著我們應該在多大程度上根據損失梯度調整權重,學習速率是隨機初始化的,
值越低,學習速度越慢,收斂到全域最小,
較高的學習率值不會使梯度下降收斂
由于我們的目標是最小化成本函式以找到最優的權值,所以我們使用不同的權值運行多個迭代,并計算成本以獲得最小的成本,如下所示
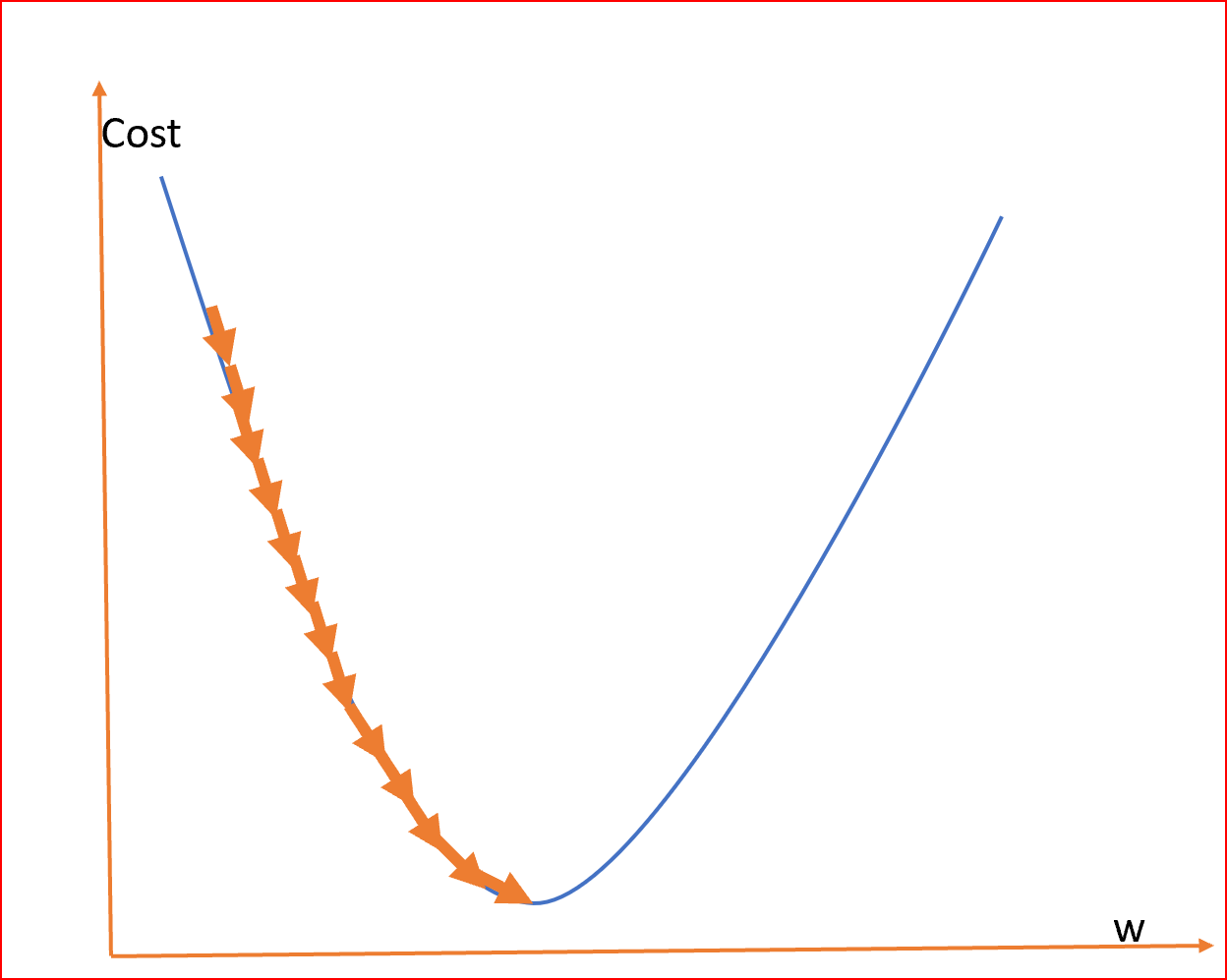
這座山可能有兩個不同的底部,用同樣的方法,我們也可以得到成本和權重之間的區域和全域最小點,
全域最小是整個域的最小點,區域最小是一個次優點,在這里我們得到一個相對最小的點,但不是如下所示的全域最小點,
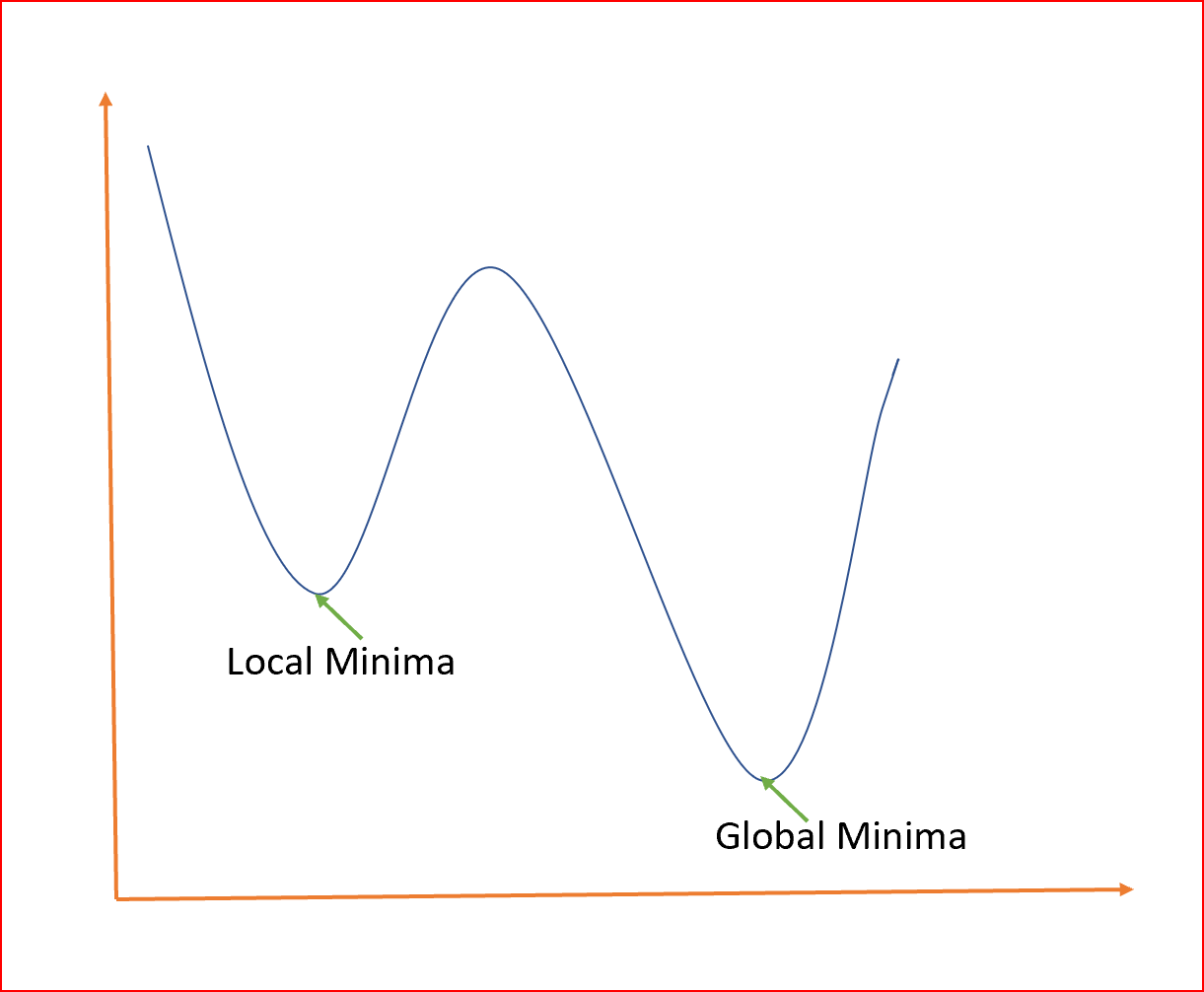
我們如何避免區域最小值,并始終嘗試得到基于全域最小值的最優權值?
首先我們來了解一下梯度下降的不同型別
不同型別的梯度下降是
- 批處理梯度下降
- 隨機梯度下降法
- 小批量梯度下降
批處理梯度下降
在批量梯度中,我們使用整個資料集來計算梯度下降每次迭代的代價函式的梯度,然后更新權值,
由于我們使用整個資料集來計算梯度收斂速度較慢,
如果資料集很大,包含數百萬或數十億個資料點,那么它就需要大記憶體和并且是計算密集的,
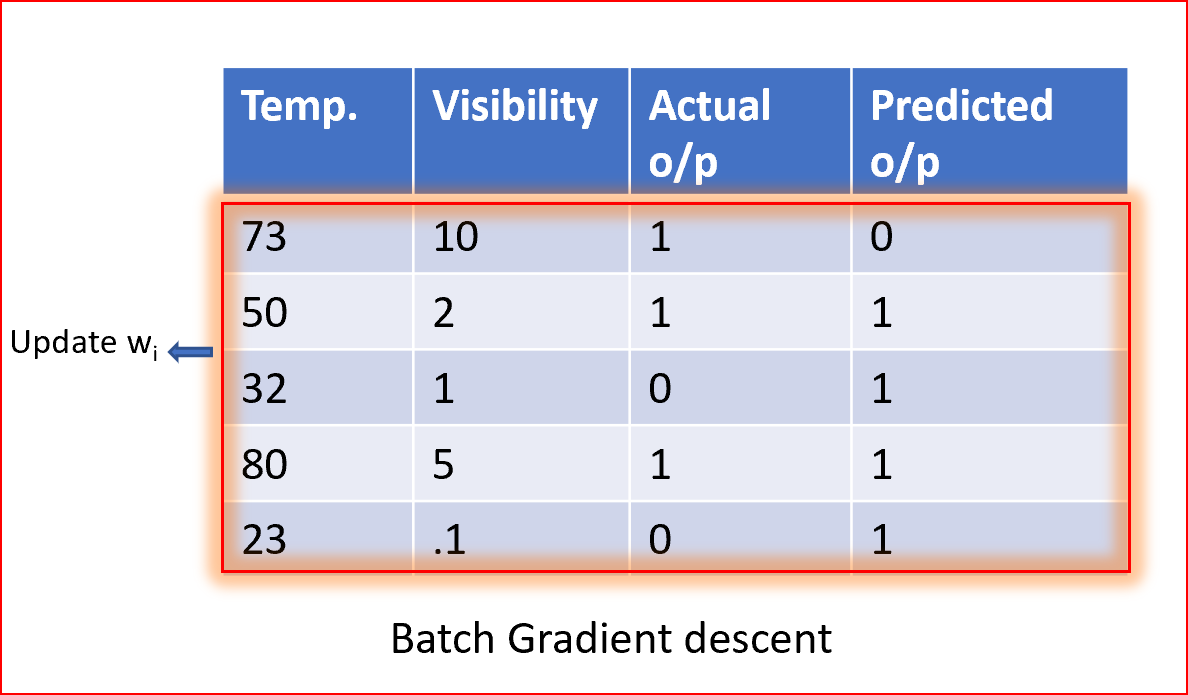
批量梯度下降的優點
- 權值和收斂速度的理論分析很容易理解
批量梯度下降的缺點
- 對大型資料集的相同訓練示例執行冗余計算
- 可能是非常緩慢和棘手的大資料集可能不適合在記憶體
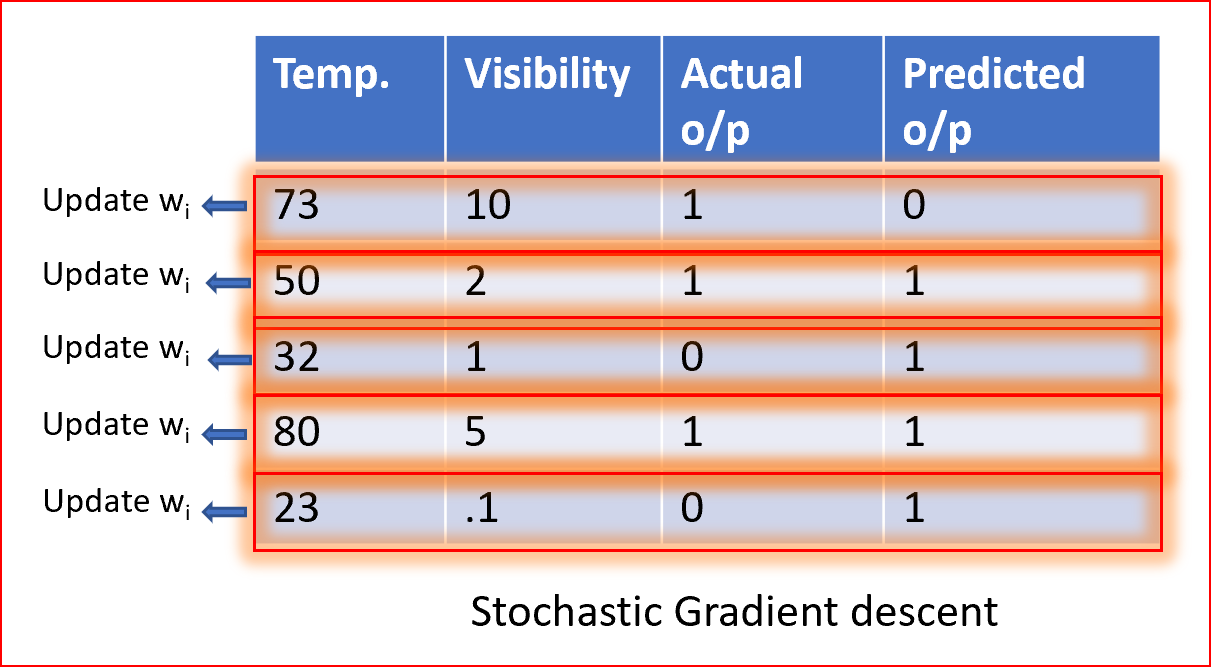
隨機梯度下降法
在隨機梯度下降法中,我們使用單個資料點或實體來計算梯度,并在每次迭代中更新權值,
我們首先需要將資料集的樣本隨機排列,這樣我們就得到了一個完全隨機的資料集,由于資料集是隨機的,并且每個示例的權值都是可以更新的,所以權值和代價函式的更新將是到處亂跳的,如下所示
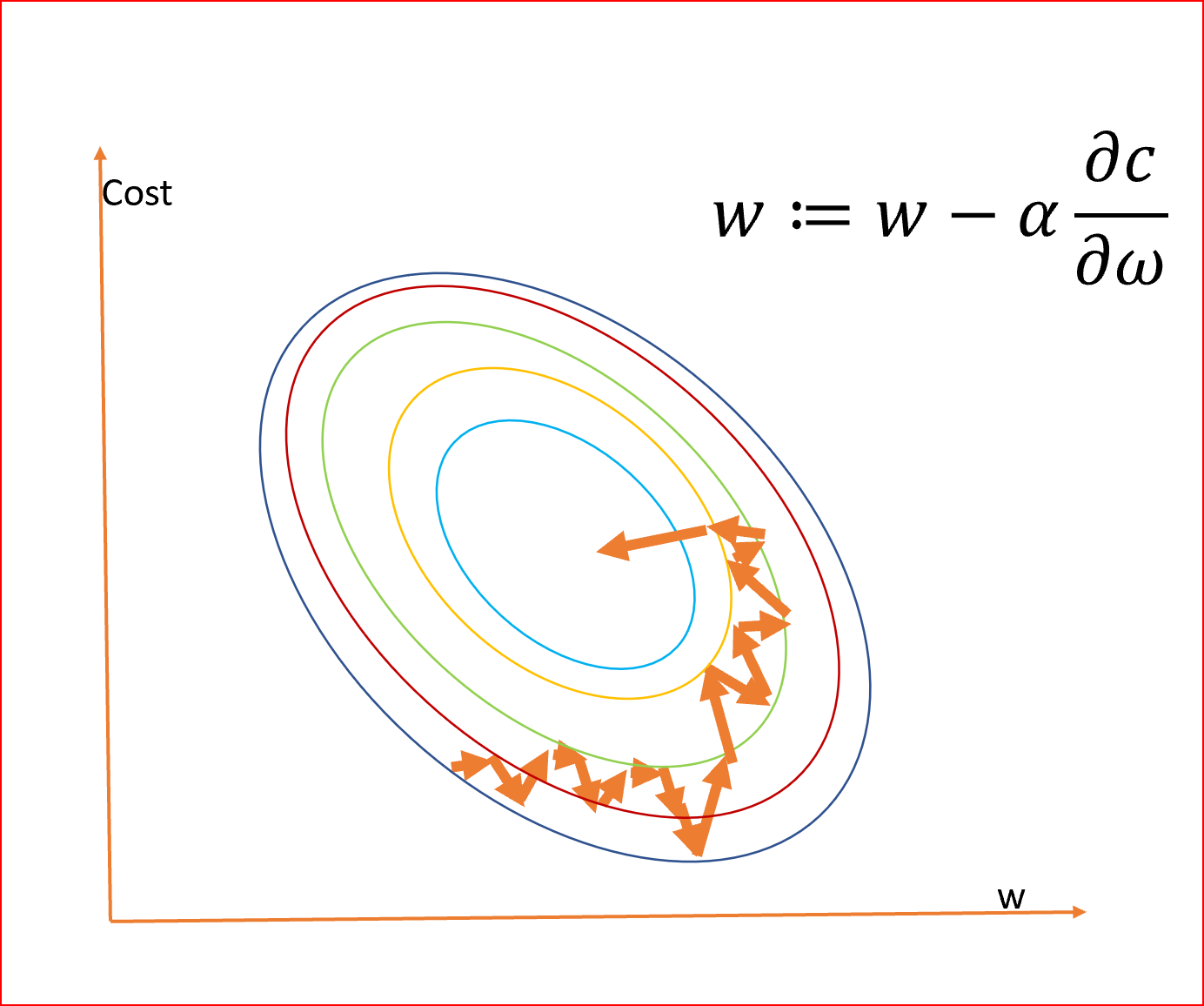
隨機樣本有助于得到全域的最小值,避免陷入區域的最小值,
對于非常大的資料集,學習要快得多,收斂也快得多,
隨機梯度下降法的優點
- 學習比批量梯度下降快得多
- 當我們一次抽取一個訓練樣本進行計算時,冗余的計算被移除
- 當我們一次抽取一個訓練樣本進行計算時,可以動態更新新資料樣本的權重
隨機梯度下降法的缺點
- 隨著權重的頻繁更新,成本函式波動較大
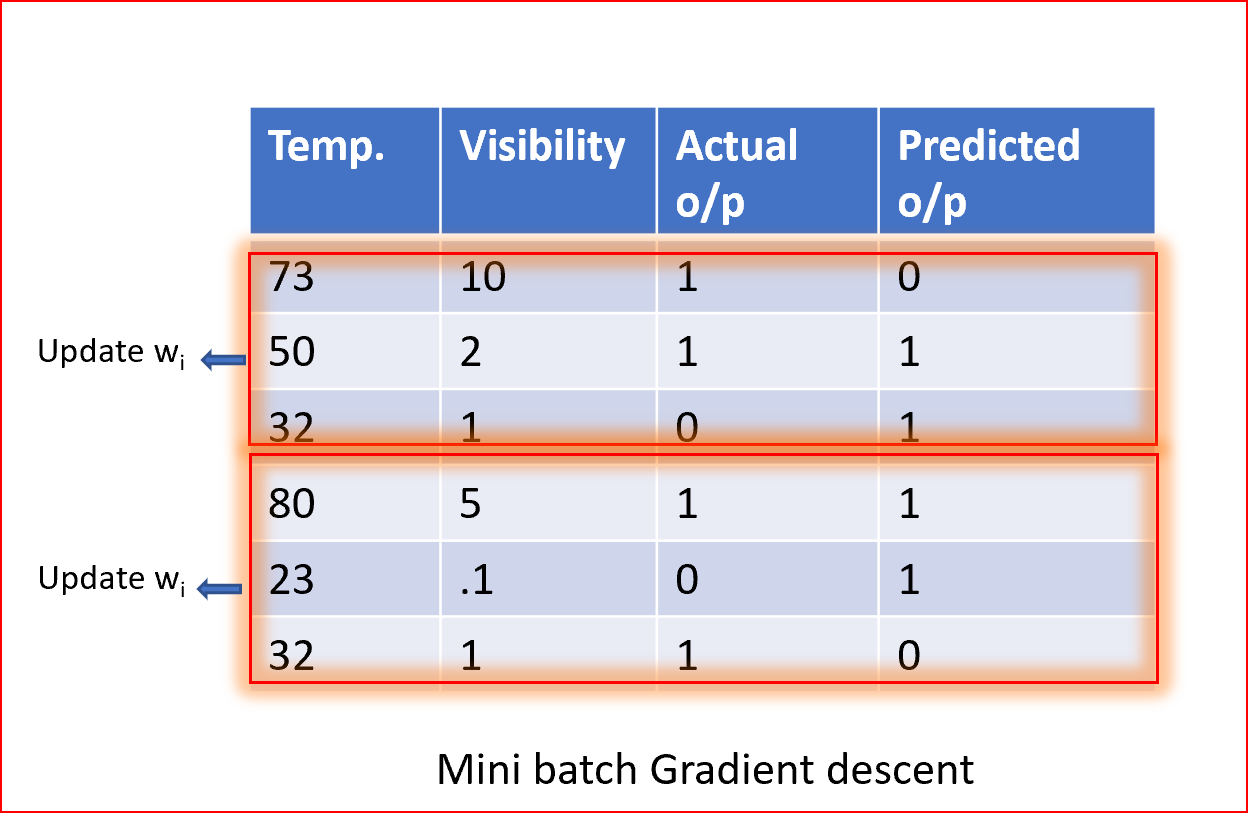
小批量梯度下降
摘要小批量梯度法是一種隨機梯度下降法,它不采用單一訓練樣本,而是采用小批量樣本,
小批量梯度下降法應用廣泛,收斂速度快,穩定性好,
批處理大小可以根據資料集的不同而有所不同,
當我們取一批不同的樣本時,它減少了權值更新的方差噪聲,有助于更快地獲得更穩定的收斂,
小批量梯度下降的優點
- 減少了引數更新的方差,從而達到穩定收斂的目的
- 學習速度快
- 有助于估計實際最小值的近似位置
小批量梯度下降的缺點
- 每一個小批都要計算損失,因此所有小批都要累計總損失
原文鏈接:https://medium.com/@arshren/gradient-descent-5a13f385d403
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14693.html
標籤:其他
上一篇:YOLO V4的模型訓練
下一篇:6個開源資料科學專案