作者|PRANAV DAR
編譯|VK
來源|Analytics Vidhya
概述
-
利用這段時間,用這些頂級的開源專案來制作你的資料科學簡歷
-
從Facebook AI的計算機視覺框架到OpenAI的GPT-3模型,我們涵蓋了廣泛的開源資料科學專案
介紹
“到目前為止,你完成了多少資料科學專案?”
這是面試者在資料科學面試中經常問的問題,我曾進行了幾次這樣的面試,這個問題基本上開門見山就會詢問,如果你是一個資料科學的新手,尤其需要注意
僅僅學習課程或獲得證書是不夠的,我認識的幾乎每個人都持有資料科學各個方面的證書,如果你不把它和實際經驗結合起來,它就不會給你的簡歷增加任何價值,
而這正是開源資料科學專案發揮如此關鍵作用的地方,面試者喜歡那些接手這些專案并提出解決方案的申請人,這顯示了你對這個領域的好奇心、熱情和熱情,相信我,在簡歷中加入資料科學專案會增加你被錄用的機會,

但你應該選擇哪些資料科學專案呢?我收集了前幾個月最好的專案并把它們帶給你,在本月的版本中,我們將涵蓋廣泛的主題,從Facebook人工智能的game-changing DEtection TRansformer(DETR)框架到OpenAI的GPT-3,

Facebook AI的DEtection TRansformer (DETR)
鏈接:https://github.com/facebookresearch/detr
Facebook人工智能的DETR很容易成為5月份發布的最有趣的開源專案,它在一周內積累了近3000顆star,這一事實很能說明問題,
DETR(DEtection TRansformer的縮寫)是計算機視覺空間中的一個變化轉換器,該框架是解決目標檢測問題的一種創新和有效的方法,DETR速度極快,效率極高,

正如我們的常駐資料科學家Prateek Joshi所說:
“DETR模型非常簡單,不需要安裝任何庫就可以使用它,借助于基于transformers的編碼器-解碼器體系結構,DETR將目標檢測問題視為直接集合預測問題,”
我們在這里詳細介紹了DETR,以幫助你了解它在下面是如何作業的,以及如何將它用于物件檢測任務,你還可以查看Facebook人工智能團隊發布的Colab Notebook,查看DETR模型的實際應用,
https://colab.research.google.com/github/facebookresearch/detr/blob/colab/notebooks/detr_demo.ipynb
Real-Time Image Animation
實時影像影片:https://github.com/anandpawara/Real_Time_Image_Animation
另一個有趣的開源計算機視覺專案,顧名思義,是讓我們使用OpenCV實時執行影像影片,看看我從專案的GitHub存盤庫中獲取的這個示例:

模型模擬了人在鏡頭前的表情,并相應地改變了影像,這是計算機視覺的一個杰出應用,我們肯定會在內部嘗試這個專案,這類專案將在業界有大量的應用,從時裝和零售到營銷和廣告,
最初的開發人員已經很友好地發布了源代碼以及Colab Notebook,去嘗試下吧
https://colab.research.google.com/github/AliaksandrSiarohin/first-order-model/blob/master/demo.ipynb
OpenAI的GPT-3
鏈接:https://github.com/openai/gpt-3
OpenAI又實作了一個!在去年發布了GPT-2并掀起了一股熱潮之后,他們已經開放了他們最新的自然語言處理(NLP)框架GPT-3!
簡單地說,GPT-3是同類中最大的NLP模型,它有1750億個引數(沒錯,你讀得沒錯),而且體積龐大,幾乎有350GB,GPT-3幾乎是歷史上最昂貴的模型之一(訓練費用約為1200萬美元),

語言模型需要大量的資料來訓練人類在幾秒鐘內就能完成的任務,這已經不是什么秘密了,升級–GPT-3,在討論GPT-3如何在引擎蓋下作業的官方論文中,OpenAI展示了擴展語言模型如何極大地提高任務無關性和少量鏡頭的性能,
現在這一部分可能會涉及到很多資料科學倫理人士——GPT-3可以很容易地生成新聞文章的樣本,而人類很難將其識別為假新聞,在當今相互關聯的世界,這可能是災難性的,為了公平起見,他們在論文中討論了這個問題,
基于PyAudio的實時音頻分析
鏈接:https://github.com/tr1pzz/Realtime_PyAudio_FFT
這個開源的資料科學專案是個人的最愛,這個Python庫由Xander Steenbrugge創建并發布,他是前兩次DataHack峰會上備受尊敬的演講者,它使我們能夠執行實時音頻分析,
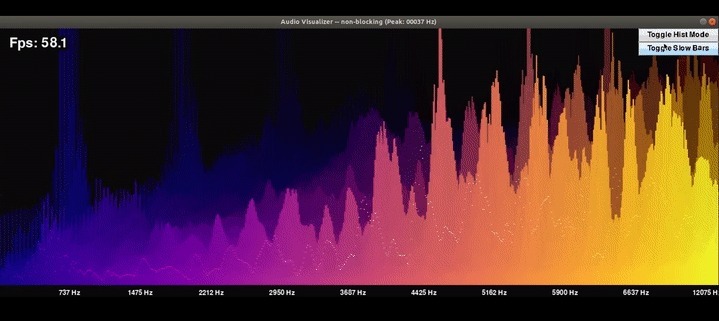
正如Xander在他的GitHub存盤庫中所說:
這是一個簡單的包,用于在本機Python中進行實時音頻分析,它使用PyAudio和Numpy從實時音頻流中提取和可視化FFT特征
這里的FFT代表快速傅立葉變換,它是一個出色的工具,在你的資料科學技能集,因為它解答了廣泛的問題,你可以使用它,
TextShot,獲取文本的Python工具
鏈接:https://github.com/ianzhao05/textshot
你有沒有遇到過圖片或截圖有文字,但不能完全提取文字?我知道有一些工具是為這個目的而存在的,但我不想在我的機器上安裝任何額外的軟體,
現在,我們可以簡單地使用這個Python工具抓取螢屏截圖并從中提取文本,稱為TextShot(好名字),這是一個很好的工具,可以快速收集我們的資料科學專案所需的任何文本資料,以下是一個演示TextShot的作業原理:
TextShot要求你在計算機上安裝谷歌的Tesseract,
Machine Learning Visuals-資料科學專業人士交流的絕佳方式
鏈接:https://github.com/dair-ai/ml-visuals
我喜歡這個開源存盤庫,許多新來的人(甚至是有經驗的人)經常在技術和科學交流上有矛盾,
ML Visuals是一個開源的協作專案,旨在幫助資料科學界理解和改進技術交流,這個出色的存盤庫提供了大量的視覺、模板和圖形,幫助你構建一個完美的演示文稿或研究論文,
這個專案最棒的部分是你可以在谷歌的幻燈片上找到所有東西,看看我從這些幻燈片中拍攝的幾張圖片:
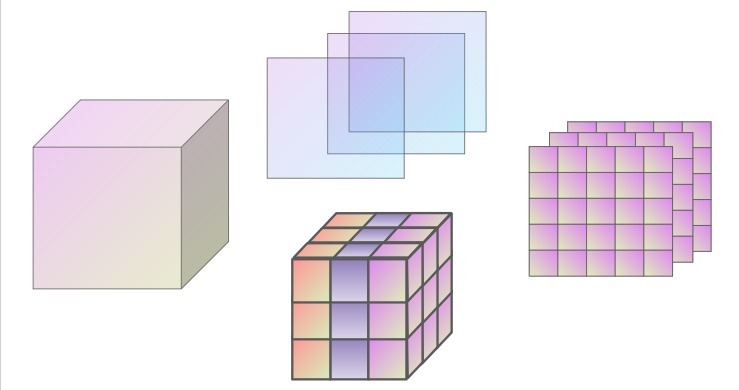
很棒!
結尾
在這個月我收集了很多有趣的開源資料科學專案!例如Facebook人工智能的DETR上和OpenAI的GPT-3,
原文鏈接:https://www.analyticsvidhya.com/blog/2020/06/6-open-source-data-science-projects-interviewer/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14696.html
標籤:其他
上一篇:機器學習:梯度下降