這一篇將會舉兩個例子說明怎么應用遞回模型,包括文本情感分類和預測股價走勢,與前幾篇不同,這一篇使用的資料是現實存在的資料,我們將可以看到更高級的模型和手法??,
例子① - 文本感情分類
文本感情分類是一個典型的例子,簡單的來說就是給出一段話,判斷這段話是正面還是負面的,例如淘寶或者京東上對商品的評價,豆瓣上對電影的評價,更高級的情感分類還能對文本中的感情進行細分,因為涉及到自然語言,文本感情分類也屬于自然語言處理 (NLP, Nature Langure Processing),我們接下來將會使用 ami66 在 github 上公開的資料,來實作根據商品評論內容識別是正面評論還是負面評論,
在處理文本之前我們需要對文本進行切分,切分方法可以分為按字切分和按單詞切分,按單詞切分的精度更高但要求使用分詞類別庫,處理中文時我們可以使用開源的 jieba 類別庫來按單詞切分,執行 pip3 install jieba --user 即可安裝,使用例子如下:
# 按字切分
>>> words = [c for c in "我來到北京清華大學"]
>>> words
['我', '來', '到', '北', '京', '清', '華', '大', '學']
# 按單詞切分
>>> import jieba
>>> words = list(jieba.cut("我來到北京清華大學"))
>>> words
['我', '來到', '北京', '清華大學']
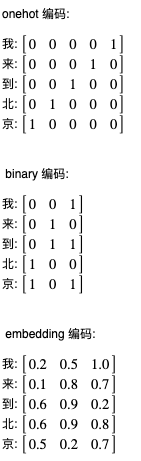
接下來我們需要使用數值來表示字或者單詞,這也有幾種方法,第一種方法是 onehot,即準備一個和字數量一樣的序列,然后用每個元素代表每個字,這種方法并不實用,因為如果要處理的文本里面有幾萬種不同的字,那么就需要幾萬長度的序列,處理起來將會非常非常慢;第二種方法是 binary,即使用二進制來表示每個字的索引值,這種方法可以減少序列長度但是會影響訓練效果;第三種方法是 embedding,使用向量 (浮點陣列成的序列) 來表示每個字或者單詞,這個向量可以預先根據某種規律生成,也可以在訓練程序中調整,這種方法是目前最流行的方法,預先根據某種規律生成的 embedding 編碼還會讓語意近似的單詞的值更接近,例如 蘋果 和 橙子 的向量將會比較接近,接下來的例子將會使用在訓練程序中調整的 embedding 編碼,然后再介紹幾種預先生成的 embedding 編碼庫,
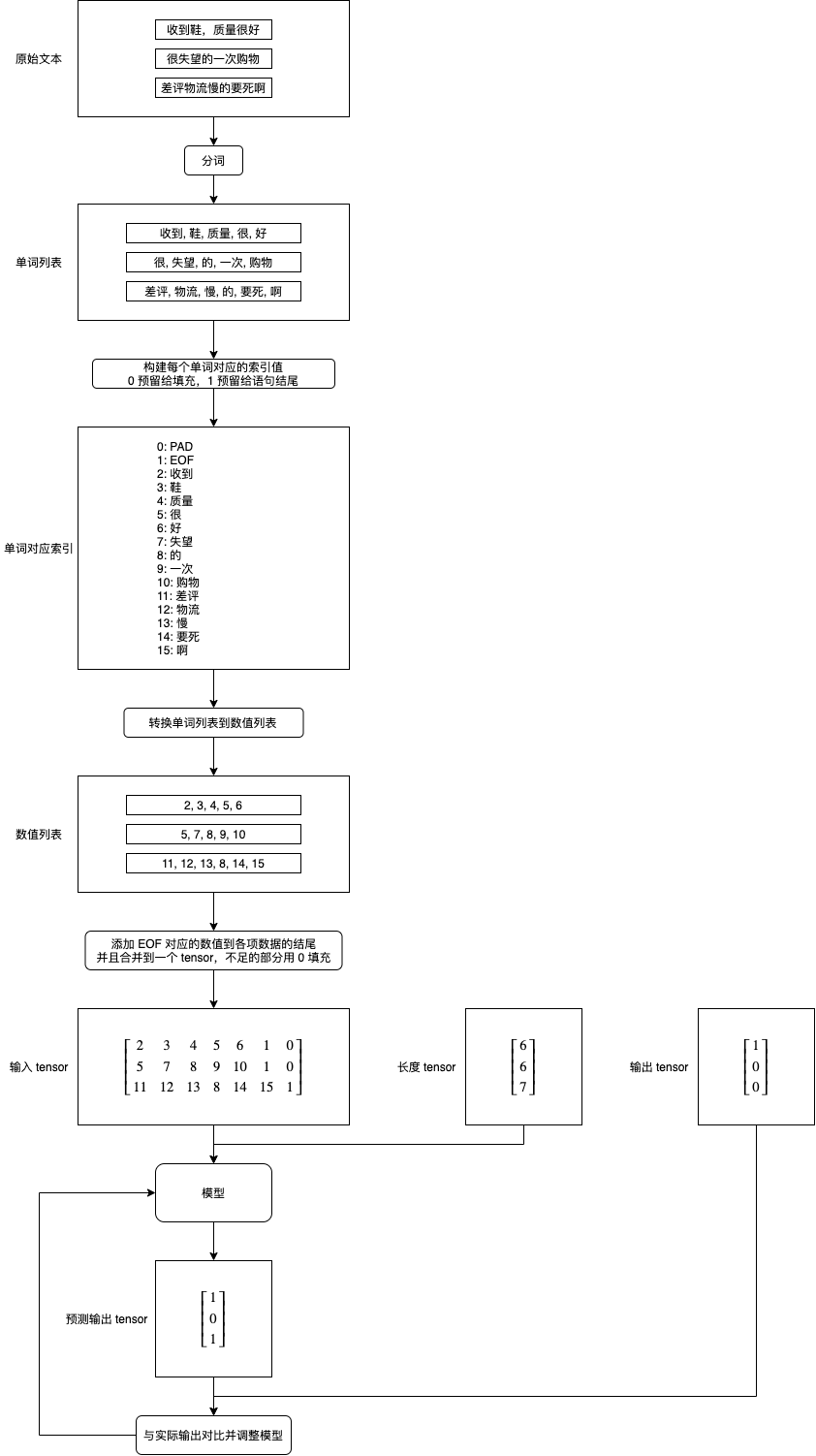
處理文本并傳給模型的流程如下,這里僅負責把單詞轉換為數值,embedding 處理在模型中 (后面介紹的預生成 embedding 編碼會在傳給模型前處理):
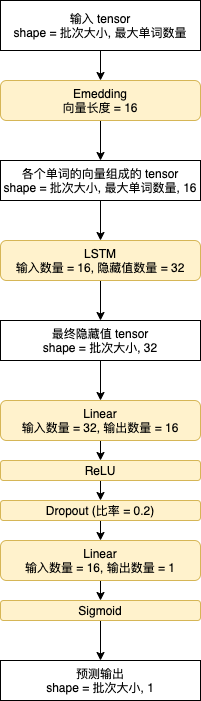
模型的結構如下,首先用 Embedding 負責轉換各個單詞的數值到向量,然后用 LSTM 處理各個單詞對應的向量,之后用兩層線性模型來識別 LSTM 回傳的最終隱藏值,最后用 sigmoid 函式把值轉換到 0 ~ 1 之間:
pytorch 中的 torch.nn.Embedding 會隨機給每個數值分配一個向量,序列中的值會在訓練程序中自動調整,最終這個向量會代表單詞的某些屬性,含義接近的單詞向量的值也會接近,
最終的 sigmoid 不僅用于控制值范圍,還可以讓調整引數更容易,試想兩個句子都是好評,如果沒有 sigmoid,那么則需要調整線性模型的輸出值接近 1,大于或小于都得調整,如果有 sigmoid,那么只需要調整線性模型的輸出值大于 6 即可,例如第一個句子輸出 8,第二個句子輸出 16,兩個經過 sigmoid 以后都是 1,
訓練和使用模型的代碼如下,與之前的代碼相比需要注意以下幾點:
- 預測輸出超過 0.5 的時候會判斷是好評,未超過 0.5 的時候會判斷是差評
- 計算正確率的時候會使用預測輸出和實際輸出的匹配數量和總數量之間的比例
- 需要保存單詞到數值的索引,用于計算總單詞數量和實際使用模型時轉換單詞到數值
- 為了加快訓練速度,引數調整器從 SGD 換成了 Adadelta
- Adadelta 是 SGD 的一個擴展,支持自動調整學習比例 (SGD 只能固定學習比例),你可以參考這篇文章了解作業原理
import os
import sys
import torch
import gzip
import itertools
import jieba
import json
import random
from torch import nn
from matplotlib import pyplot
class MyModel(nn.Module):
"""根據評論分析是好評還是差評"""
def __init__(self, total_words):
super().__init__()
self.embedding = nn.Embedding(
num_embeddings=total_words,
embedding_dim=16,
padding_idx=0
)
self.rnn = nn.LSTM(
input_size = 16,
hidden_size = 32,
num_layers = 1,
batch_first = True
)
self.linear = nn.Sequential(
nn.Linear(in_features=32, out_features=16),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(in_features=16, out_features=1),
nn.Sigmoid())
def forward(self, x, lengths):
# 轉換單詞對應的數值到向量
embedded = self.embedding(x)
# 附加長度資訊,避免 RNN 計算填充的資料
packed = nn.utils.rnn.pack_padded_sequence(
embedded, lengths, batch_first=True, enforce_sorted=False)
# 使用遞回模型計算,因為當前場景只需要最后一個輸出,所以直接使用 hidden
# 注意 LSTM 的第二個回傳值同時包含最新的隱藏狀態和細胞狀態
output, (hidden, cell) = self.rnn(packed)
# 轉換隱藏狀態的維度到 批次大小, 隱藏值數量
hidden = hidden.reshape(hidden.shape[1], hidden.shape[2])
# 使用多層線性模型識別遞回模型回傳的隱藏值
# 最后使用 sigmoid 把值范圍控制在 0 ~ 1
y = self.linear(hidden)
return y
def save_tensor(tensor, path):
"""保存 tensor 物件到檔案"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""從檔案讀取 tensor 物件"""
return torch.load(gzip.GzipFile(path, "rb"))
def save_word_to_index(word_to_index):
"""保存單詞到數值的索引"""
json.dump(word_to_index, open('data/word_to_index.json', 'w'), indent=2, ensure_ascii=False)
def load_word_to_index():
"""讀取單詞到數值的索引"""
return json.load(open('data/word_to_index.json', 'r'))
def prepare_save_batch(batch, pending_tensors):
"""準備訓練 - 保存單個批次的資料"""
# 打亂單個批次的資料
random.shuffle(pending_tensors)
# 劃分輸入和輸出 tensor,另外保存各個輸入 tensor 的長度
in_tensor_unpadded = [p[0] for p in pending_tensors]
in_tensor_lengths = torch.tensor([t.shape[0] for t in in_tensor_unpadded])
out_tensor = torch.tensor([p[1] for p in pending_tensors])
# 整合長度不等的 in_tensor_unpadded 到單個 tensor,不足的長度會填充 0
in_tensor = nn.utils.rnn.pad_sequence(in_tensor_unpadded, batch_first=True)
# 切分訓練集 (60%),驗證集 (20%) 和測驗集 (20%)
random_indices = torch.randperm(in_tensor.shape[0])
training_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
training_set = (in_tensor[training_indices], in_tensor_lengths[training_indices], out_tensor[training_indices])
validating_set = (in_tensor[validating_indices], in_tensor_lengths[validating_indices], out_tensor[validating_indices])
testing_set = (in_tensor[testing_indices], in_tensor_lengths[testing_indices], out_tensor[testing_indices])
# 保存到硬碟
save_tensor(training_set, f"data/training_set.{batch}.pt")
save_tensor(validating_set, f"data/validating_set.{batch}.pt")
save_tensor(testing_set, f"data/testing_set.{batch}.pt")
print(f"batch {batch} saved")
def prepare():
"""準備訓練"""
# 資料集轉換到 tensor 以后會保存在 data 檔案夾下
if not os.path.isdir("data"):
os.makedirs("data")
# 準備詞語到數值的索引
# 預留 PAD 為填充,EOF 為陳述句結束
word_to_index = { '<PAD>': 0, '<EOF>': 1 }
# 從 txt 讀取原始資料集,分批每次處理 2000 行
# 這里使用原始方法讀取,最后一個標注為 1 代表好評,為 0 代表差評
batch = 0
pending_tensors = []
for line in open('goods_zh.txt', 'r'):
parts = line.split(',')
phase = ",".join(parts[:-2])
positive = int(parts[-1])
# 使用 jieba 分詞,然后轉換單詞到索引
words = jieba.cut(phase)
word_indices = []
for word in words:
if word.isascii() or word in (',', ',', '!'):
continue # 過濾標點符號
if word in word_to_index:
word_indices.append(word_to_index[word])
else:
new_index = len(word_to_index)
word_to_index[word] = new_index
word_indices.append(new_index)
word_indices.append(1) # 代表陳述句結束
# 輸入是各個單詞對應的索引,輸出是是否正面評價
pending_tensors.append((torch.tensor(word_indices), torch.tensor([positive])))
if len(pending_tensors) >= 2000:
prepare_save_batch(batch, pending_tensors)
batch += 1
pending_tensors.clear()
if pending_tensors:
prepare_save_batch(batch, pending_tensors)
batch += 1
pending_tensors.clear()
# 保存詞語到單詞的索引
save_word_to_index(word_to_index)
def train():
"""開始訓練"""
# 創建模型實體
total_words = len(load_word_to_index())
model = MyModel(total_words)
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
optimizer = torch.optim.Adadelta(model.parameters())
# 記錄訓練集和驗證集的正確率變化
training_accuracy_history = []
validating_accuracy_history = []
# 記錄最高的驗證集正確率
validating_accuracy_highest = 0
validating_accuracy_highest_epoch = 0
# 讀取批次的工具函式
def read_batches(base_path):
for batch in itertools.count():
path = f"{base_path}.{batch}.pt"
if not os.path.isfile(path):
break
yield load_tensor(path)
# 計算正確率的工具函式
def calc_accuracy(actual, predicted):
return ((actual >= 0.5) == (predicted >= 0.5)).sum().item() / actual.shape[0]
# 劃分輸入和輸出的工具函式
def split_batch_xy(batch, begin=None, end=None):
# shape = batch_size, input_size
batch_x = batch[0][begin:end]
# shape = batch_size, 1
batch_x_lengths = batch[1][begin:end]
# shape = batch_size, 1
batch_y = batch[2][begin:end].reshape(-1, 1).float()
return batch_x, batch_x_lengths, batch_y
# 開始訓練程序
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
training_accuracy_list = []
for batch in read_batches("data/training_set"):
# 切分小批次,有助于泛化模型
for index in range(0, batch[0].shape[0], 100):
# 劃分輸入和輸出
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch, index, index+100)
# 計算預測值
predicted = model(batch_x, batch_x_lengths)
# 計算損失
loss = loss_function(predicted, batch_y)
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄這一個批次的正確率,torch.no_grad 代表臨時禁用自動微分功能
with torch.no_grad():
training_accuracy_list.append(calc_accuracy(batch_y, predicted))
training_accuracy = sum(training_accuracy_list) / len(training_accuracy_list)
training_accuracy_history.append(training_accuracy)
print(f"training accuracy: {training_accuracy}")
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
validating_accuracy_list = []
for batch in read_batches("data/validating_set"):
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch)
predicted = model(batch_x, batch_x_lengths)
validating_accuracy_list.append(calc_accuracy(batch_y, predicted))
validating_accuracy = sum(validating_accuracy_list) / len(validating_accuracy_list)
validating_accuracy_history.append(validating_accuracy)
print(f"validating accuracy: {validating_accuracy}")
# 記錄最高的驗證集正確率與當時的模型狀態,判斷是否在 20 次訓練后仍然沒有重繪記錄
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 20:
# 在 20 次訓練后仍然沒有重繪記錄,結束訓練
print("stop training because highest validating accuracy not updated in 20 epoches")
break
# 使用達到最高正確率時的模型狀態
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 檢查測驗集
testing_accuracy_list = []
for batch in read_batches("data/testing_set"):
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch)
predicted = model(batch_x, batch_x_lengths)
testing_accuracy_list.append(calc_accuracy(batch_y, predicted))
testing_accuracy = sum(testing_accuracy_list) / len(testing_accuracy_list)
print(f"testing accuracy: {testing_accuracy}")
# 顯示訓練集和驗證集的正確率變化
pyplot.plot(training_accuracy_history, label="training")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用訓練好的模型"""
# 讀取詞語到單詞的索引
word_to_index = load_word_to_index()
# 創建模型實體,加載訓練好的狀態,然后切換到驗證模式
model = MyModel(len(word_to_index))
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 詢問輸入并預測輸出
while True:
try:
phase = input("Review: ")
# 分詞
words = list(jieba.cut(phase))
# 轉換到數值串列
word_indices = [word_to_index[w] for w in words if w in word_to_index]
word_indices.append(word_to_index['EOF'])
# 構建輸入
x = torch.tensor(word_indices).reshape(1, -1)
lengths = torch.tensor([len(word_indices)])
# 預測輸出
y = model(x, lengths)
print("Positive Score:", y[0, 0].item(), "\n")
except Exception as e:
print("error:", e)
def main():
"""主函式"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓程序可重現,你也可以選擇不這樣做
random.seed(0)
torch.random.manual_seed(0)
# 根據命令列引數選擇操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
執行以下命令即可準備資料集和訓練模型:
python3 example.py prepare
python3 example.py train
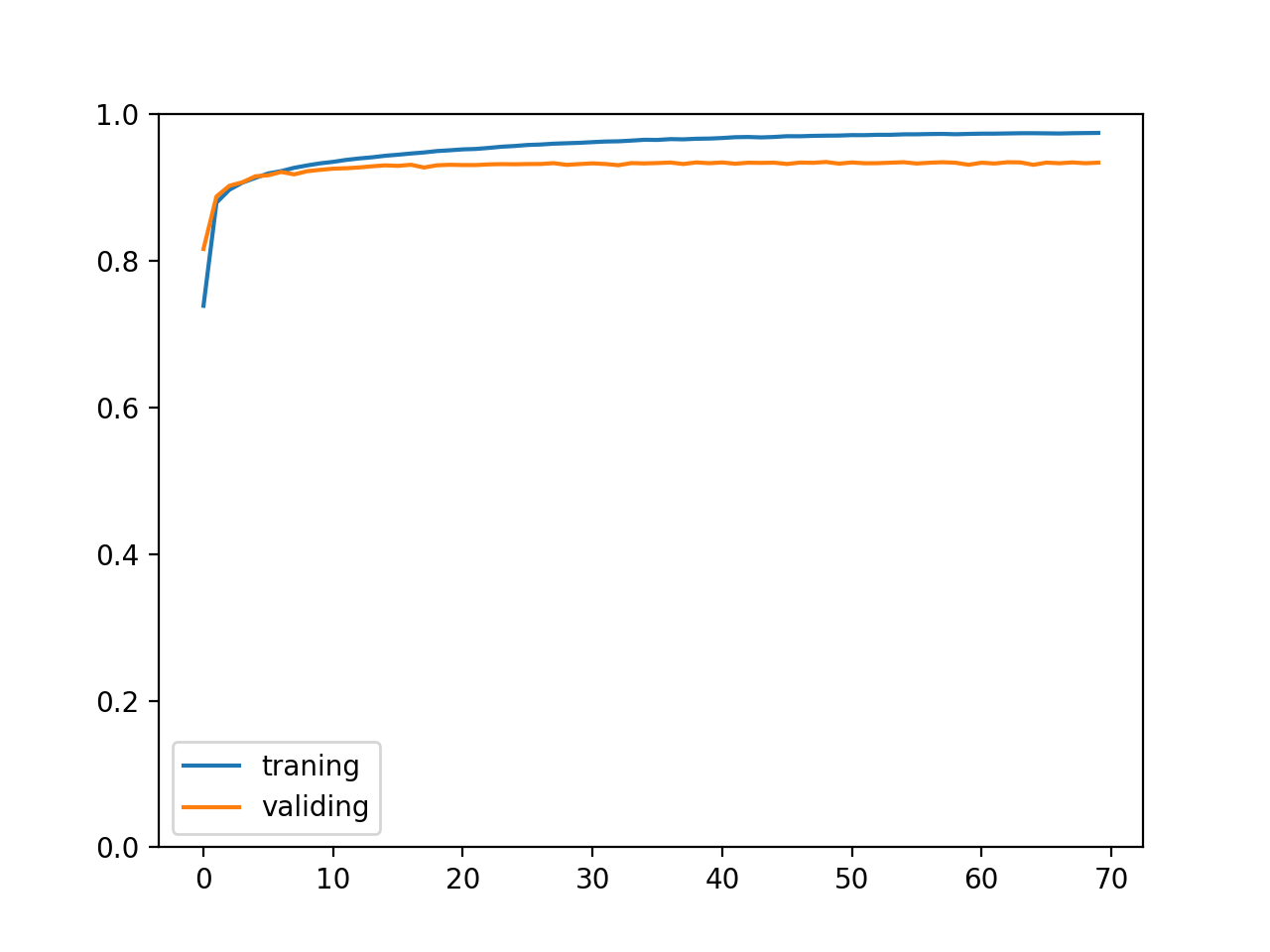
訓練成功以后的輸出如下,我們可以看到驗證集和測驗集正確率都達到了 93%:
epoch: 70
training accuracy: 0.9745314468456309
validating accuracy: 0.9339881613022567
stop training because highest validating accuracy not updated in 20 epoches
highest validating accuracy: 0.9348816130225674 from epoch 49
testing accuracy: 0.933661672216056
正確率的變化如下:
執行以下命令即可使用訓練好的模型:
python3 example.py eval
使用例子如下:
Review: 這手機吃后臺特別嚴重,不建議購買
Positive Score: 0.010371988639235497
Review: 這樣很好,穿著特別舒適,很喜歡的一雙鞋子,夏天也比較透氣
Positive Score: 1.0
Review: 性價比還是不錯的,使用到現在還沒有出現問題
Positive Score: 1.0
Review: 服務態度差,物流慢
Positive Score: 0.009614041075110435
Review: 這手機有問題,反應到客服沒人理
Positive Score: 0.00456244358792901
Review: 強烈建議購買
Positive Score: 0.9984269142150879
Review: 強烈不建議購買
Positive Score: 0.03579584136605263
注意如果使用的單詞不在索引中那么這個單詞會被忽略,要解決這個問題可以增加資料量涵蓋盡量多的單詞,或者使用接下來介紹的預生成 embedding 編碼庫,
現在我們有一個程式可以智能判斷對方說的是好話還是壞話了??,因為現實中的商城或者電影評價網站一般都會同時要求用戶打分所以這個例子的實用價值不大,但它仍然是一個很好的例子幫助我們理解怎樣使用遞回模型處理自然語言,
使用預生成 embedding 編碼庫
以上的例子會在訓練程序中調整 embedding 編碼,這種做法很方便,但只能識別在索引中的單詞 (資料集中包含的單詞),如果使用了未知的單詞那么模型有可能無法正確預測結果,我們可以使用預生成的 embedding 編碼庫來解決這個問題,這些庫是根據海量資料生成的(通常使用百科問答或者新聞等公開資料),包含了非常非常多的單詞,并且語意接近的單詞的向量也會很接近,訓練的時候只要使用部分單詞就可以同時適用于語意接近的更多單詞,
注意使用這些庫不需要在訓練程序中調整向量,torch.nn.Embedding.from_pretrained 支持匯入預先訓練好的編碼庫,并且不會在訓練程序中調整它們,
word2vec
使用 word2vec 首先我們需要安裝 gensim 庫,使用以下命令即可安裝:
pip3 install gensim --user
接下來我們需要一個預先生成好的編碼庫,你可以在 github 上搜索 word2vec chinese 或者 word2vec 中文,也可以用自己的語料庫生成,這里我簡單介紹怎樣使用自己的語料庫生成,來源是上面的評論資料,你也可以試著從這里下載更大的文本資料,
第一步是使用 jieba 分詞,然后全部寫到一個檔案,單詞之間用空格隔開:
import jieba
f = open('chinese.text8', 'w')
for line in open('goods_zh.txt', 'r'):
line = "".join(line.split(',')[:-2])
words = jieba.cut(line)
words = [w for w in words if not (w.isascii() or w in (",", ",", "!"))]
f.write(" ".join(words))
f.write(" ")
第二步是使用 word2vec 生成并保存編碼庫:
from gensim.models import word2vec
sentences = word2vec.Text8Corpus('chinese.text8')
model = word2vec.Word2Vec(sentences, size=200)
model.save("chinese.model")
試著使用生成好的編碼庫:
# 尋找語意接近的單詞,挺準確的吧??
>>> from gensim.models import word2vec
>>> w = word2vec.Word2Vec.load("chinese.model")
>>> w.wv.most_similar(["手機"])
[('機子', 0.6180450916290283), ('新手機', 0.5946457386016846), ('新機', 0.4700007736682892), ('機器', 0.4531888961791992), ('榮耀', 0.4304167628288269), ('紅米', 0.42995956540107727), ('電腦', 0.4163869023323059), ('筆記本', 0.4093247652053833), ('堅果', 0.4016817808151245), ('產品', 0.3963530957698822)]
>>> w.wv.most_similar(["物流"])
[('送貨', 0.8435776233673096), ('快遞', 0.7946128249168396), ('發貨', 0.7307696342468262), ('遞給', 0.7279399037361145), ('配送', 0.6557953357696533), ('處理速度', 0.6505168676376343), ('用電', 0.6292495131492615), ('速遞', 0.6150853633880615), ('貨發', 0.6149879693984985), ('反應速度', 0.5916593074798584)]
# 定位單詞對應的數值
>>> w.wv.vocab.get("手機").index
5
# 定位單詞對應的數值對應的向量
>>> w.wv.vectors[5]
array([-1.4774184e-01, 5.9569430e-01, 9.1274220e-01, 8.2012570e-01,
省略途中輸出
-7.7284634e-01, -8.3093870e-01, 9.6443129e-01, -1.6938221e+00],
dtype=float32)
在前面的例子中使用這個編碼庫的代碼如下,改動了 prepare 和模型部分,雖然模型使用了 torch.nn.Embedding 但預生成的編碼庫不會隨著訓練而變化,此外這份代碼不會在陳述句結尾添加 EOF 對應的向量 (在這個例子中不影響效果):
import os
import sys
import torch
import gzip
import itertools
import jieba
import json
import random
from gensim.models import word2vec
from torch import nn
from matplotlib import pyplot
class MyModel(nn.Module):
"""根據評論分析是好評還是差評"""
def __init__(self, w2v):
super().__init__()
self.embedding = nn.Embedding.from_pretrained(
torch.FloatTensor(w2v.wv.vectors))
self.rnn = nn.LSTM(
input_size = 200,
hidden_size = 32,
num_layers = 1,
batch_first = True
)
self.linear = nn.Sequential(
nn.Linear(in_features=32, out_features=16),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(in_features=16, out_features=1),
nn.Sigmoid())
def forward(self, x, lengths):
# 轉換單詞對應的數值到向量
embedded = self.embedding(x)
# 附加長度資訊,避免 RNN 計算填充的資料
packed = nn.utils.rnn.pack_padded_sequence(
embedded, lengths, batch_first=True, enforce_sorted=False)
# 使用遞回模型計算,因為當前場景只需要最后一個輸出,所以直接使用 hidden
# 注意 LSTM 的第二個回傳值同時包含最新的隱藏狀態和細胞狀態
output, (hidden, cell) = self.rnn(packed)
# 轉換隱藏狀態的維度到 批次大小, 隱藏值數量
hidden = hidden.reshape(hidden.shape[1], hidden.shape[2])
# 使用多層線性模型識別遞回模型回傳的隱藏值
# 最后使用 sigmoid 把值范圍控制在 0 ~ 1
y = self.linear(hidden)
return y
def save_tensor(tensor, path):
"""保存 tensor 物件到檔案"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""從檔案讀取 tensor 物件"""
return torch.load(gzip.GzipFile(path, "rb"))
def load_word2vec_model():
"""讀取 word2vec 編碼庫"""
return word2vec.Word2Vec.load("chinese.model")
def prepare_save_batch(batch, pending_tensors):
"""準備訓練 - 保存單個批次的資料"""
# 打亂單個批次的資料
random.shuffle(pending_tensors)
# 劃分輸入和輸出 tensor,另外保存各個輸入 tensor 的長度
in_tensor_unpadded = [p[0] for p in pending_tensors]
in_tensor_lengths = torch.tensor([t.shape[0] for t in in_tensor_unpadded])
out_tensor = torch.tensor([p[1] for p in pending_tensors])
# 整合長度不等的 in_tensor_unpadded 到單個 tensor,不足的長度會填充 0
in_tensor = nn.utils.rnn.pad_sequence(in_tensor_unpadded, batch_first=True)
# 切分訓練集 (60%),驗證集 (20%) 和測驗集 (20%)
random_indices = torch.randperm(in_tensor.shape[0])
training_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
training_set = (in_tensor[training_indices], in_tensor_lengths[training_indices], out_tensor[training_indices])
validating_set = (in_tensor[validating_indices], in_tensor_lengths[validating_indices], out_tensor[validating_indices])
testing_set = (in_tensor[testing_indices], in_tensor_lengths[testing_indices], out_tensor[testing_indices])
# 保存到硬碟
save_tensor(training_set, f"data/training_set.{batch}.pt")
save_tensor(validating_set, f"data/validating_set.{batch}.pt")
save_tensor(testing_set, f"data/testing_set.{batch}.pt")
print(f"batch {batch} saved")
def prepare():
"""準備訓練"""
# 資料集轉換到 tensor 以后會保存在 data 檔案夾下
if not os.path.isdir("data"):
os.makedirs("data")
# 準備詞語到數值的索引
w2v = load_word2vec_model()
# 從 txt 讀取原始資料集,分批每次處理 2000 行
# 這里使用原始方法讀取,最后一個標注為 1 代表好評,為 0 代表差評
batch = 0
pending_tensors = []
for line in open('goods_zh.txt', 'r'):
parts = line.split(',')
phase = ",".join(parts[:-2])
positive = int(parts[-1])
# 使用 jieba 分詞,然后轉換單詞到索引
words = jieba.cut(phase)
word_indices = []
for word in words:
if word.isascii() or word in (',', ',', '!'):
continue # 過濾標點符號
vocab = w2v.wv.vocab.get(word)
if vocab:
word_indices.append(vocab.index)
if not word_indices:
continue # 沒有單詞在編碼庫中
# 輸入是各個單詞對應的索引,輸出是是否正面評價
pending_tensors.append((torch.tensor(word_indices), torch.tensor([positive])))
if len(pending_tensors) >= 2000:
prepare_save_batch(batch, pending_tensors)
batch += 1
pending_tensors.clear()
if pending_tensors:
prepare_save_batch(batch, pending_tensors)
batch += 1
pending_tensors.clear()
def train():
"""開始訓練"""
# 創建模型實體
w2v = load_word2vec_model()
model = MyModel(w2v)
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
optimizer = torch.optim.Adadelta(model.parameters())
# 記錄訓練集和驗證集的正確率變化
training_accuracy_history = []
validating_accuracy_history = []
# 記錄最高的驗證集正確率
validating_accuracy_highest = 0
validating_accuracy_highest_epoch = 0
# 讀取批次的工具函式
def read_batches(base_path):
for batch in itertools.count():
path = f"{base_path}.{batch}.pt"
if not os.path.isfile(path):
break
yield load_tensor(path)
# 計算正確率的工具函式
def calc_accuracy(actual, predicted):
return ((actual >= 0.5) == (predicted >= 0.5)).sum().item() / actual.shape[0]
# 劃分輸入和輸出的工具函式
def split_batch_xy(batch, begin=None, end=None):
# shape = batch_size, input_size
batch_x = batch[0][begin:end]
# shape = batch_size, 1
batch_x_lengths = batch[1][begin:end]
# shape = batch_size, 1
batch_y = batch[2][begin:end].reshape(-1, 1).float()
return batch_x, batch_x_lengths, batch_y
# 開始訓練程序
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
training_accuracy_list = []
for batch in read_batches("data/training_set"):
# 切分小批次,有助于泛化模型
for index in range(0, batch[0].shape[0], 100):
# 劃分輸入和輸出
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch, index, index+100)
# 計算預測值
predicted = model(batch_x, batch_x_lengths)
# 計算損失
loss = loss_function(predicted, batch_y)
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄這一個批次的正確率,torch.no_grad 代表臨時禁用自動微分功能
with torch.no_grad():
training_accuracy_list.append(calc_accuracy(batch_y, predicted))
training_accuracy = sum(training_accuracy_list) / len(training_accuracy_list)
training_accuracy_history.append(training_accuracy)
print(f"training accuracy: {training_accuracy}")
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
validating_accuracy_list = []
for batch in read_batches("data/validating_set"):
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch)
predicted = model(batch_x, batch_x_lengths)
validating_accuracy_list.append(calc_accuracy(batch_y, predicted))
validating_accuracy = sum(validating_accuracy_list) / len(validating_accuracy_list)
validating_accuracy_history.append(validating_accuracy)
print(f"validating accuracy: {validating_accuracy}")
# 記錄最高的驗證集正確率與當時的模型狀態,判斷是否在 20 次訓練后仍然沒有重繪記錄
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 20:
# 在 20 次訓練后仍然沒有重繪記錄,結束訓練
print("stop training because highest validating accuracy not updated in 20 epoches")
break
# 使用達到最高正確率時的模型狀態
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 檢查測驗集
testing_accuracy_list = []
for batch in read_batches("data/testing_set"):
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch)
predicted = model(batch_x, batch_x_lengths)
testing_accuracy_list.append(calc_accuracy(batch_y, predicted))
testing_accuracy = sum(testing_accuracy_list) / len(testing_accuracy_list)
print(f"testing accuracy: {testing_accuracy}")
# 顯示訓練集和驗證集的正確率變化
pyplot.plot(training_accuracy_history, label="training")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用訓練好的模型"""
# 讀取詞語到單詞的索引
w2v = load_word2vec_model()
# 創建模型實體,加載訓練好的狀態,然后切換到驗證模式
model = MyModel(w2v)
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 詢問輸入并預測輸出
while True:
try:
phase = input("Review: ")
# 分詞
words = list(jieba.cut(phase))
# 轉換到數值串列
word_indices = []
for word in words:
if word.isascii() or word in (',', ',', '!'):
continue # 過濾標點符號
vocab = w2v.wv.vocab.get(word)
if vocab:
word_indices.append(vocab.index)
if not word_indices:
raise ValueError("No known words")
# 構建輸入
x = torch.tensor(word_indices).reshape(1, -1)
lengths = torch.tensor([len(word_indices)])
# 預測輸出
y = model(x, lengths)
print("Positive Score:", y[0, 0].item(), "\n")
except Exception as e:
print("error:", e)
def main():
"""主函式"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓程序可重現,你也可以選擇不這樣做
random.seed(0)
torch.random.manual_seed(0)
# 根據命令列引數選擇操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
如果你試著用這份代碼來訓練會發現第一個 epoch 就已經達到 90% 以上的正確率,并且繼續訓練下去可以達到比直接使用 torch.nn.Embedding 更高的正確率,使用預生成編碼庫的效果驚人呀??,
如果你對 word2vec 的原理感興趣可以參考這篇文章,同樣在博客園上,
transfomers (BERT)
transfomers 是一個用于處理自然語言的類別庫,包含了目前世界上最先進的模型,我們將會看到如何使用其中的 BERT 模型來處理中文,
使用以下命令安裝:
pip3 install transformers
transfomers 支持自動下載和使用預先訓練好的模型,以下是使用 BERT 中文模型的代碼 (第一次使用時會自動下載),有分詞器和模型兩部分:
>>> from transformers import AutoTokenizer, AutoModel
>>> tt = AutoTokenizer.from_pretrained("bert-base-chinese")
>>> tm = AutoModel.from_pretrained("bert-base-chinese")
# 轉換中文陳述句到數值串列
>>> tt.encode("五星好評贊")
[101, 758, 3215, 1962, 6397, 6614, 102]
# 生成各個單詞對應的向量
>>> codes, hidden = tm(torch.tensor([[101, 758, 3215, 1962, 6397, 6614, 102]]))
>>> codes.shape
torch.Size([1, 7, 768])
>>> hidden.shape
torch.Size([1, 768])
如果你細心觀察可能會發現上面并沒有實際分詞,而是根據每個字單獨生成了索引,這是因為 bert-base-chinese 是按字來劃分的,你可以試試其他模型 (我不確定是否有這樣的現成模型??),另外轉換為向量時,第二個回傳值代表了最終的內部狀態,這點跟遞回模型比較像,第二個回傳值還可以用來代表整個句子的編碼,盡管精度會有所降低,
在前面的例子中使用 transfomers 的代碼如下,注意準備資料集和訓練都需要相當長的時間,這可以說是用牛刀殺雞??:
import os
import sys
import torch
import gzip
import itertools
import json
import random
from transformers import AutoTokenizer, AutoModel
from torch import nn
from matplotlib import pyplot
class MyModel(nn.Module):
"""根據評論分析是好評還是差評"""
def __init__(self):
super().__init__()
self.rnn = nn.LSTM(
input_size = 768,
hidden_size = 32,
num_layers = 1,
batch_first = True
)
self.linear = nn.Sequential(
nn.Linear(in_features=32, out_features=16),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(in_features=16, out_features=1),
nn.Sigmoid())
def forward(self, x, lengths):
# transformers 已經幫我們轉換為向量
embedded = x
# 附加長度資訊,避免 RNN 計算填充的資料
packed = nn.utils.rnn.pack_padded_sequence(
embedded, lengths, batch_first=True, enforce_sorted=False)
# 使用遞回模型計算,因為當前場景只需要最后一個輸出,所以直接使用 hidden
# 注意 LSTM 的第二個回傳值同時包含最新的隱藏狀態和細胞狀態
output, (hidden, cell) = self.rnn(packed)
# 轉換隱藏狀態的維度到 批次大小, 隱藏值數量
hidden = hidden.reshape(hidden.shape[1], hidden.shape[2])
# 使用多層線性模型識別遞回模型回傳的隱藏值
# 最后使用 sigmoid 把值范圍控制在 0 ~ 1
y = self.linear(hidden)
return y
def save_tensor(tensor, path):
"""保存 tensor 物件到檔案"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""從檔案讀取 tensor 物件"""
return torch.load(gzip.GzipFile(path, "rb"))
def load_transfomer_tokenizer():
"""獲取 transformers 的分詞器"""
return AutoTokenizer.from_pretrained("bert-base-chinese")
def load_transfomer_model():
"""獲取 transofrmers 的模型"""
return AutoModel.from_pretrained("bert-base-chinese")
def prepare_save_batch(batch, pending_tensors):
"""準備訓練 - 保存單個批次的資料"""
# 打亂單個批次的資料
random.shuffle(pending_tensors)
# 劃分輸入和輸出 tensor,另外保存各個輸入 tensor 的長度
in_tensor_unpadded = [p[0] for p in pending_tensors]
in_tensor_lengths = torch.tensor([t.shape[0] for t in in_tensor_unpadded])
out_tensor = torch.tensor([p[1] for p in pending_tensors])
# 整合長度不等的 in_tensor_unpadded 到單個 tensor,不足的長度會填充 0
in_tensor = nn.utils.rnn.pad_sequence(in_tensor_unpadded, batch_first=True)
# 切分訓練集 (60%),驗證集 (20%) 和測驗集 (20%)
random_indices = torch.randperm(in_tensor.shape[0])
training_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
training_set = (in_tensor[training_indices], in_tensor_lengths[training_indices], out_tensor[training_indices])
validating_set = (in_tensor[validating_indices], in_tensor_lengths[validating_indices], out_tensor[validating_indices])
testing_set = (in_tensor[testing_indices], in_tensor_lengths[testing_indices], out_tensor[testing_indices])
# 保存到硬碟
save_tensor(training_set, f"data/training_set.{batch}.pt")
save_tensor(validating_set, f"data/validating_set.{batch}.pt")
save_tensor(testing_set, f"data/testing_set.{batch}.pt")
print(f"batch {batch} saved")
def prepare():
"""準備訓練"""
# 資料集轉換到 tensor 以后會保存在 data 檔案夾下
if not os.path.isdir("data"):
os.makedirs("data")
# 加載 transformer 分詞器和模型
tt = load_transfomer_tokenizer()
tm = load_transfomer_model()
# 從 txt 讀取原始資料集,分批每次處理 2000 行
# 這里使用原始方法讀取,最后一個標注為 1 代表好評,為 0 代表差評
batch = 0
pending_tensors = []
for line in open('goods_zh.txt', 'r'):
parts = line.split(',')
phase = ",".join(parts[:-2])
positive = int(parts[-1])
# 使用 transformer 分詞,然后轉換各個數值到向量
word_indices = tt.encode(phase)
word_indices = word_indices[:510] # bert-base-chinese 不支持過長的序列
words_tensor, hidden = tm(torch.tensor([word_indices]))
words_tensor = words_tensor.reshape(words_tensor.shape[1], words_tensor.shape[2])
# 輸入是各個單詞對應的向量,輸出是是否正面評價
pending_tensors.append((words_tensor, torch.tensor([positive])))
if len(pending_tensors) >= 500:
prepare_save_batch(batch, pending_tensors)
batch += 1
pending_tensors.clear()
if pending_tensors:
prepare_save_batch(batch, pending_tensors)
batch += 1
pending_tensors.clear()
def train():
"""開始訓練"""
# 創建模型實體
model = MyModel()
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
optimizer = torch.optim.Adadelta(model.parameters())
# 記錄訓練集和驗證集的正確率變化
training_accuracy_history = []
validating_accuracy_history = []
# 記錄最高的驗證集正確率
validating_accuracy_highest = 0
validating_accuracy_highest_epoch = 0
# 讀取批次的工具函式
def read_batches(base_path):
for batch in itertools.count():
path = f"{base_path}.{batch}.pt"
if not os.path.isfile(path):
break
yield load_tensor(path)
# 計算正確率的工具函式
def calc_accuracy(actual, predicted):
return ((actual >= 0.5) == (predicted >= 0.5)).sum().item() / actual.shape[0]
# 劃分輸入和輸出的工具函式
def split_batch_xy(batch, begin=None, end=None):
# shape = batch_size, input_size
batch_x = batch[0][begin:end]
# shape = batch_size, 1
batch_x_lengths = batch[1][begin:end]
# shape = batch_size, 1
batch_y = batch[2][begin:end].reshape(-1, 1).float()
return batch_x, batch_x_lengths, batch_y
# 開始訓練程序
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
training_accuracy_list = []
for batch in read_batches("data/training_set"):
# 切分小批次,有助于泛化模型
for index in range(0, batch[0].shape[0], 100):
# 劃分輸入和輸出
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch, index, index+100)
# 計算預測值
predicted = model(batch_x, batch_x_lengths)
# 計算損失
loss = loss_function(predicted, batch_y)
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄這一個批次的正確率,torch.no_grad 代表臨時禁用自動微分功能
with torch.no_grad():
training_accuracy_list.append(calc_accuracy(batch_y, predicted))
training_accuracy = sum(training_accuracy_list) / len(training_accuracy_list)
training_accuracy_history.append(training_accuracy)
print(f"training accuracy: {training_accuracy}")
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
validating_accuracy_list = []
for batch in read_batches("data/validating_set"):
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch)
predicted = model(batch_x, batch_x_lengths)
validating_accuracy_list.append(calc_accuracy(batch_y, predicted))
validating_accuracy = sum(validating_accuracy_list) / len(validating_accuracy_list)
validating_accuracy_history.append(validating_accuracy)
print(f"validating accuracy: {validating_accuracy}")
# 記錄最高的驗證集正確率與當時的模型狀態,判斷是否在 20 次訓練后仍然沒有重繪記錄
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 20:
# 在 20 次訓練后仍然沒有重繪記錄,結束訓練
print("stop training because highest validating accuracy not updated in 20 epoches")
break
# 使用達到最高正確率時的模型狀態
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 檢查測驗集
testing_accuracy_list = []
for batch in read_batches("data/testing_set"):
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch)
predicted = model(batch_x, batch_x_lengths)
testing_accuracy_list.append(calc_accuracy(batch_y, predicted))
testing_accuracy = sum(testing_accuracy_list) / len(testing_accuracy_list)
print(f"testing accuracy: {testing_accuracy}")
# 顯示訓練集和驗證集的正確率變化
pyplot.plot(training_accuracy_history, label="training")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用訓練好的模型"""
# 加載 transformer 分詞器和模型
tt = load_transfomer_tokenizer()
tm = load_transfomer_model()
# 創建模型實體,加載訓練好的狀態,然后切換到驗證模式
model = MyModel()
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 詢問輸入并預測輸出
while True:
try:
phase = input("Review: ")
# 使用 transformer 分詞,然后轉換各個數值到向量
word_indices = tt.encode(phase)
word_indices = word_indices[:510] # bert-base-chinese 不支持過長的序列
words_tensor, hidden = tm(torch.tensor([word_indices]))
# 構建輸入
x = words_tensor
lengths = torch.tensor([len(word_indices)])
# 預測輸出
y = model(x, lengths)
print("Positive Score:", y[0, 0].item(), "\n")
except Exception as e:
print("error:", e)
def main():
"""主函式"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓程序可重現,你也可以選擇不這樣做
random.seed(0)
torch.random.manual_seed(0)
# 根據命令列引數選擇操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
如果你實際訓練使用會發現它不僅能判斷商品評論是正面還是負面的,也能判斷普通陳述句是好話還是壞話,可以說相當的神奇,
transfomers 還可以用來做翻譯和文本自動生成,因為里面的模型太高級了所以我目前沒有理解它們是怎么作業的??,希望以后有機會可以詳細介紹,
例子② - 預測股價走勢
如果你是一個股民,你可能會試圖找出那些漲漲跌跌之間的規律,包括使用 MACD, KDJ 等指標,這里我們試試應用機器學習預測股價走勢,看看結果如何,
訓練和驗證使用的資料是中國銀行 (601988) 的每日收盤價和交易量,可以從以下地址下載:
- (最新資料) https://finance.yahoo.com/quote/601988.SS/history?period1=1152057600&period2=1589500800&interval=1d&filter=history&frequency=1d
- (這篇文章使用的資料) https://github.com/303248153/BlogArchive/tree/master/ml-06/601988.SS.csv
csv 中包含了 日期,開盤價,最高價,最低價,收盤價,調整后收盤價,交易量,輸入和輸出規定如下
- 輸入: 收盤價 (標準化除以 100), 交易量 (標準化除以 1 億)
- 輸出: T+2 的漲跌 (漲 1 跌 0, T+2 指下下個交易日)
模型是 GRU + 2 層線性模型,最終使用 sigmoid 轉換輸出到 0 ~ 1 之間的值,資料劃分訓練集包含 1500 條資料,驗證集和測驗集包含 100 條資料,時序按 訓練集 => 驗證集 => 測驗集 排列,
注意傳遞資料給模型的時候會按 32 條資料分批傳遞,模型需要保留隱藏狀態使得分批傳遞與完整傳遞可以得出相同的結果,
訓練和使用模型的代碼如下:
import os
import sys
import torch
import gzip
import itertools
import random
import pandas
import math
from torch import nn
from matplotlib import pyplot
CSV_FILENAME = "601988.SS.csv"
TRAINING_RECORDS = 1500
VALIDATING_RECORDS = 100
TESTING_RECORDS = 100
class MyModel(nn.Module):
"""根據歷史收盤價和成交量預測股價走勢"""
def __init__(self):
super().__init__()
self.rnn = nn.GRU(
input_size = 2,
hidden_size = 50,
num_layers = 1,
batch_first = True
)
self.linear = nn.Sequential(
nn.Linear(in_features=50, out_features=20),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(in_features=20, out_features=1),
nn.Sigmoid())
self.reset_hidden()
def forward(self, x):
# 調整維度
x = x.reshape(1, x.shape[0], x.shape[1])
# 使用遞回模型計算,需要所有輸出,并且還需要保存隱藏狀態
# 保存隱藏狀態時需要使用 detach 切斷內部的計算路徑
output, hidden = self.rnn(x, self.rnn_hidden)
self.rnn_hidden = hidden.detach()
# 轉換輸出的維度到 批次大小, 隱藏值數量
output = output.reshape(output.shape[1], output.shape[2])
# 使用多層線性模型計算遞回模型回傳的輸出
y = self.linear(output)
return y
def reset_hidden(self):
"""重置隱藏狀態"""
self.rnn_hidden = torch.zeros(1, 1, 50)
def save_tensor(tensor, path):
"""保存 tensor 物件到檔案"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""從檔案讀取 tensor 物件"""
return torch.load(gzip.GzipFile(path, "rb"))
def prepare():
"""準備訓練"""
# 資料集轉換到 tensor 以后會保存在 data 檔案夾下
if not os.path.isdir("data"):
os.makedirs("data")
# 從 csv 讀取原始資料集
df = pandas.read_csv(CSV_FILENAME)
in_list = [] # 收盤價和成交量作為輸入
out_list = [] # T+2 的漲跌作為輸出
for value in df.values:
volume = value[-1] / 100000000 # 成交量除以一億
price = value[-3] / 100 # 收盤價除以 100
if math.isnan(volume) or math.isnan(price):
continue # 原始資料中是 null
in_list.append((price, volume))
for index in range(len(in_list)-2):
price_t0 = in_list[index][0]
price_t2 = in_list[index+2][0]
out_list.append(1. if price_t2 > price_t0 else 0.)
in_list = in_list[:len(out_list)]
# 生成輸入和輸出
in_tensor = torch.tensor(in_list)
out_tensor = torch.tensor(out_list).reshape(-1, 1)
# 劃分訓練集,驗證集和測驗集
testing_start = -TESTING_RECORDS
validating_start = testing_start - VALIDATING_RECORDS
training_start = validating_start - TRAINING_RECORDS
training_in = in_tensor[training_start:validating_start]
training_out = out_tensor[training_start:validating_start]
validating_in = in_tensor[validating_start:testing_start]
validating_out = out_tensor[validating_start:testing_start]
testing_in = in_tensor[testing_start:]
testing_out = out_tensor[testing_start:]
# 保存到硬碟
save_tensor((training_in, training_out), f"data/training_set.pt")
save_tensor((validating_in, validating_out), f"data/validating_set.pt")
save_tensor((testing_in, testing_out), f"data/testing_set.pt")
print("saved dataset")
def train():
"""開始訓練"""
# 創建模型實體
model = MyModel()
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
optimizer = torch.optim.Adadelta(model.parameters())
# 記錄訓練集和驗證集的正確率變化
training_accuracy_history = []
validating_accuracy_history = []
# 記錄最高的驗證集正確率
validating_accuracy_highest = 0
validating_accuracy_highest_epoch = 0
# 計算正確率的工具函式
def calc_accuracy(actual, predicted):
return ((actual >= 0.5) == (predicted >= 0.5)).sum().item() / actual.shape[0]
# 開始訓練程序
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 重置模型的隱藏狀態
model.reset_hidden()
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
training_accuracy_list = []
training_in, training_out = load_tensor("data/training_set.pt")
for index in range(0, training_in.shape[0], 32):
# 劃分輸入和輸出
batch_x = training_in[index:index+32]
batch_y = training_out[index:index+32]
# 計算預測值
predicted = model(batch_x)
# 計算損失
loss = loss_function(predicted, batch_y)
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄這一個批次的正確率,torch.no_grad 代表臨時禁用自動微分功能
with torch.no_grad():
training_accuracy_list.append(calc_accuracy(batch_y, predicted))
training_accuracy = sum(training_accuracy_list) / len(training_accuracy_list)
training_accuracy_history.append(training_accuracy)
print(f"training accuracy: {training_accuracy}")
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
validating_in, validating_out = load_tensor("data/validating_set.pt")
predicted = model(validating_in)
validating_accuracy = calc_accuracy(validating_out, predicted)
validating_accuracy_history.append(validating_accuracy)
print(f"validating accuracy: {validating_accuracy}")
# 記錄最高的驗證集正確率與當時的模型狀態,判斷是否在 200 次訓練后仍然沒有重繪記錄
# 因為資料量很少,僅在訓練集正確率超過 70% 時執行這里的邏輯
if training_accuracy > 0.7:
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 200:
# 在 200 次訓練后仍然沒有重繪記錄,結束訓練
print("stop training because highest validating accuracy not updated in 200 epoches")
break
# 使用達到最高正確率時的模型狀態
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 檢查測驗集
testing_in, testing_out = load_tensor("data/testing_set.pt")
predicted = model(testing_in)
testing_accuracy = calc_accuracy(testing_out, predicted)
print(f"testing accuracy: {testing_accuracy}")
# 顯示訓練集的誤差變化
pyplot.plot(training_accuracy_history, label="training")
pyplot.plot(validating_accuracy_history, label="validating")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用訓練好的模型"""
# 創建模型實體,加載訓練好的狀態,然后切換到驗證模式
model = MyModel()
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 加載歷史資料
training_in, _ = load_tensor("data/training_set.pt")
model(training_in)
# 預測未來資料
price_list = []
trend_list = []
df = pandas.read_csv(CSV_FILENAME)
for value in df.values[-TESTING_RECORDS-VALIDATING_RECORDS:]:
volume = float(value[-1])
price = float(value[-3])
if math.isnan(volume) or math.isnan(price):
continue # 原始資料中是 null
in_tensor = torch.tensor([[price / 100, volume / 100000000]])
trend = model(in_tensor)[0].item()
price_list.append(price)
trend_list.append(trend)
# 根據預測資料模擬買賣 100 萬
# 規則為預測 T+2 漲則買入,預測 T+2 跌則賣出,不計算印花稅和分紅
money = 1000000
stock = 0
matched = 0
total = 0
buy_list = []
sell_list = []
for index in range(len(price_list)):
price = price_list[index]
trend = trend_list[index]
will_rise = trend > 0.5
will_drop = trend < 0.5
if stock == 0 and will_rise:
unit = int(money / price / 100) # 1 手 100 股
money -= price * unit * 100
stock += unit
buy_list.append(price)
sell_list.append(0)
print(f"buy {unit}, money {money}, stock {stock}")
elif stock != 0 and will_drop:
unit = stock
money += price * unit * 100
stock -= unit
buy_list.append(0)
sell_list.append(price)
print(f"sell {unit}, money {money}, stock {stock}")
else:
buy_list.append(0)
sell_list.append(0)
money_final = money + price_list[-1] * stock * 100
print(f"final money {money_final}")
print(f"stock price goes from {price_list[0]} to {price_list[-1]} in this range")
# 顯示為圖表
pyplot.plot(price_list, label="price")
pyplot.plot(buy_list, label="buy", marker="$b$", linestyle = "None")
pyplot.plot(sell_list, label="sell", marker="$s$", linestyle = "None")
pyplot.ylim(min(price_list) - 0.05, max(price_list) + 0.05)
pyplot.legend()
pyplot.show()
def main():
"""主函式"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓程序可重現,你也可以選擇不這樣做
random.seed(0)
torch.random.manual_seed(0)
# 根據命令列引數選擇操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
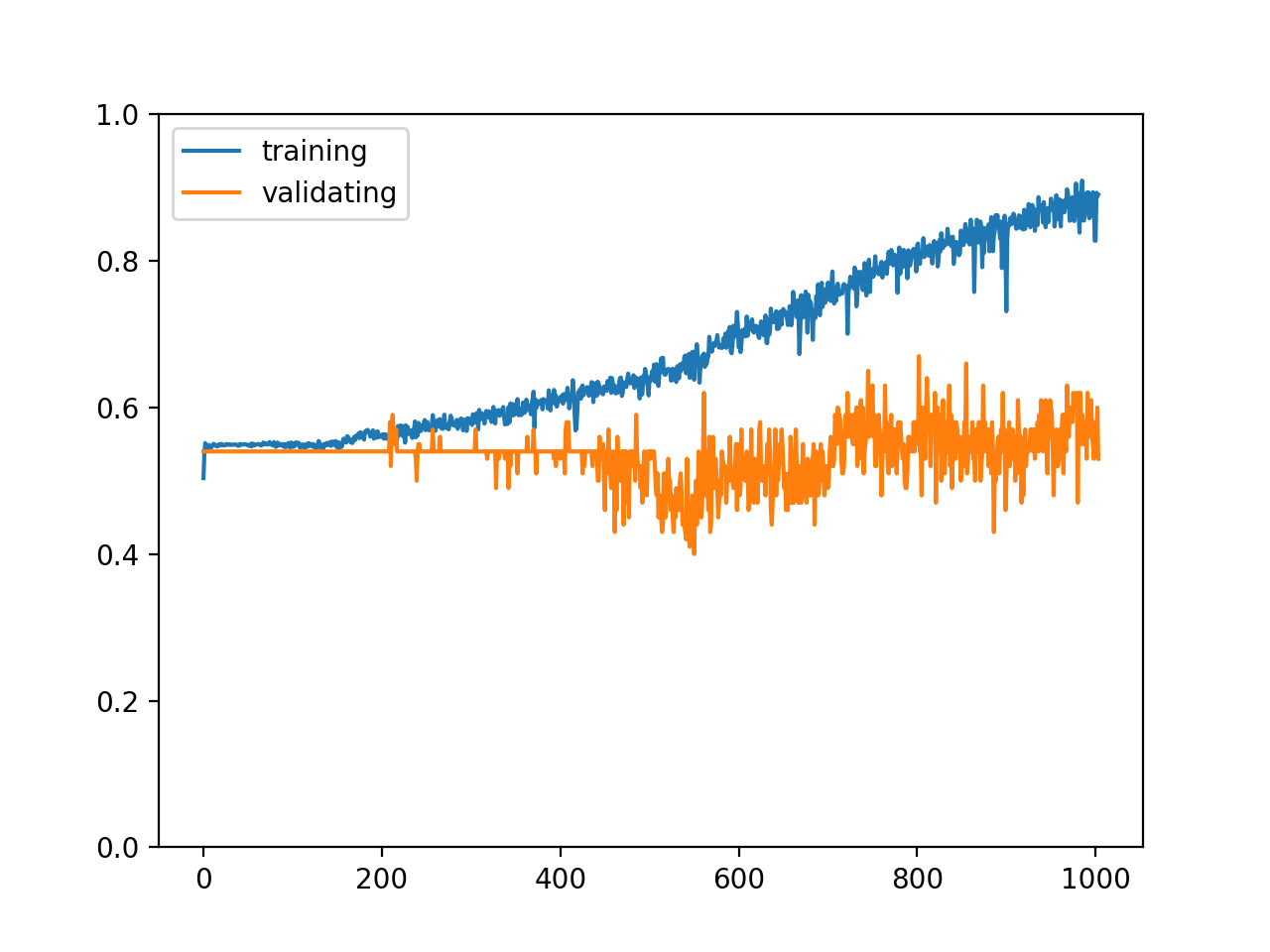
訓練結束以后的輸出如下,這不是一個理想的結果??:
epoch: 1004
training accuracy: 0.8902925531914894
validating accuracy: 0.53
stop training because highest validating accuracy not updated in 200 epoches
highest validating accuracy: 0.67 from epoch 803
testing accuracy: 0.5
訓練集和驗證集的正確率變化如下:
驗證模型的部分會基于沒有訓練過的未知資料 (合計 200 條) 模擬交易,首先準備 100 萬,預測 T+2 漲就買,預測 T+2 跌就賣,一天只操作一次,每次買賣都是最大數量,不考慮印花稅和分紅,模擬結果如下:
final money 1089605.9999999998
stock price goes from 3.67 to 3.45 in this range
模擬交易的圖表表現如下:
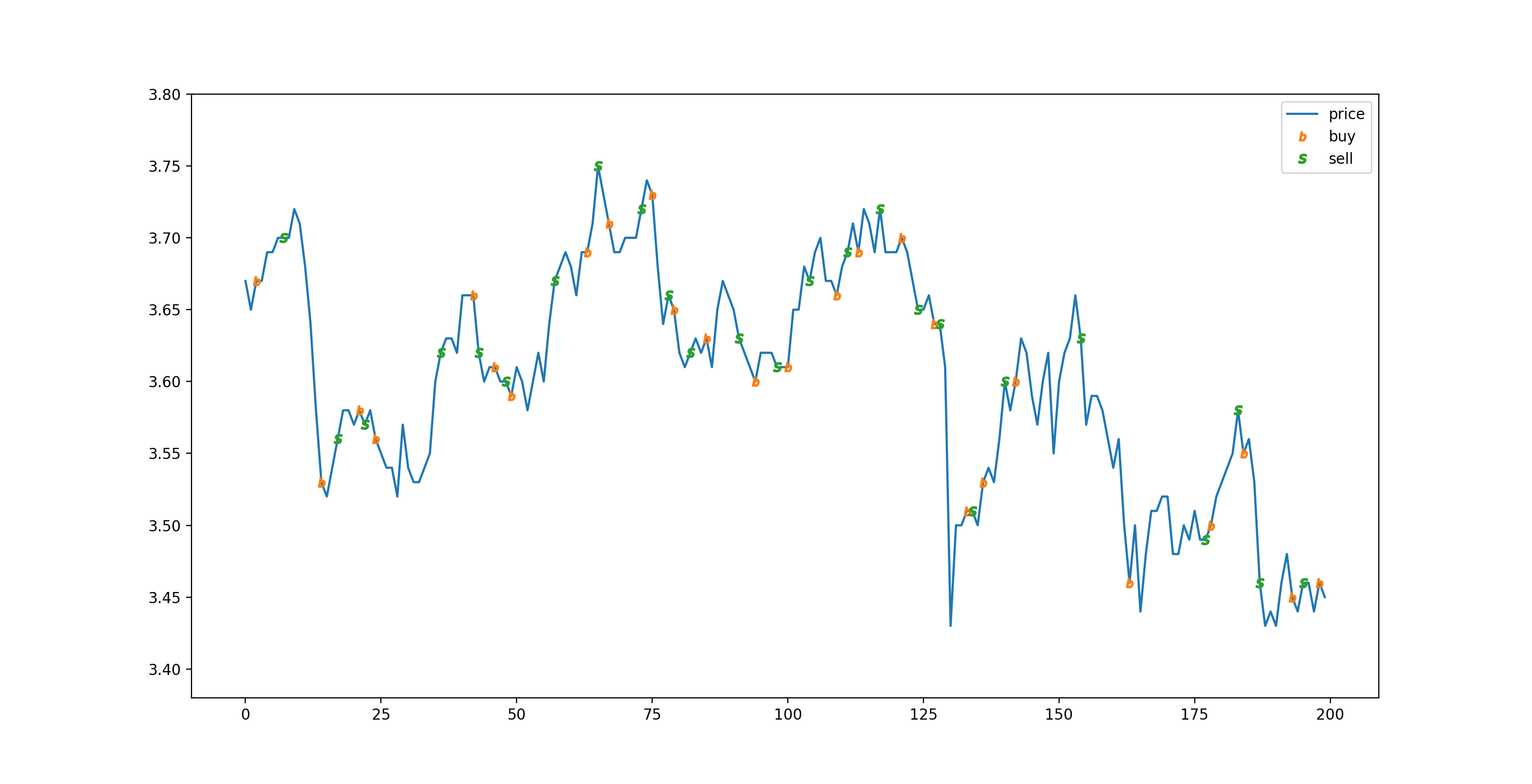
只看模擬結果可能會覺得模型很厲害,但實際上這只是個偶然,這次訓練不能算是成功,因為正確率不高,和瞎猜差不多??,訓練沒有成功的原因有下:
- 股價的不確定因素太多了,只靠每天的收盤價和交易量是沒有辦法正確預測出趨勢的
- 一般來說股價趨勢短期預測比長期預測的準確率要高很多,因為短期預測的不確定因素比較少,但我沒有找到公開的高頻股價資料
- 單只股票的資料量很少,而且每只股票的股性都不一樣 (依賴于操盤手),很難訓練出通用的模型
除了上面的模型以外我還試了很多方式,例如把漲跌幅作為輸入或者輸出與加大減少模型的結構,但都沒有找到可以確切預測出走勢的模型,
你可能會忍不住去試試更多方式,甚至找到效果比較好的模型,但我作為一個老股民勸你一句,股海無邊,回頭是岸呀??,
寫在最后
這篇本來還準備介紹雙向遞回模型的例子,但遇到一些技術問題加上機器配置較低所以拖了半個月都未能完成??,預計下一篇還是介紹遞回模型的例子,再下一篇開始就會介紹處理影像的 CNN 模型,敬請期待,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14700.html
標籤:其他
上一篇:6個開源資料科學專案
下一篇:決策樹和隨機森林