作者|PRATEEK JOSHI
編譯|VK
來源|Analytics Vidhya
決策樹與隨機森林的簡單類比
讓我們從一個思維實驗開始,它將說明決策樹和隨機森林模型之間的區別,
假設銀行必須為客戶批準一筆小額貸款,而銀行需要迅速做出決定,銀行檢查此人的信用記錄和財務狀況,發現他們還沒有償還舊貸款,因此,銀行拒絕了申請,
但問題是,對于銀行龐大的金庫來說,貸款數額非常小,他們本可以在非常低風險的情況下批準貸款,因此,銀行失去了賺錢的機會,
現在,又一個貸款申請將在幾天內完成,但這一次銀行提出了一個不同的策略——多個決策程序,有時它先檢查信用記錄,有時它先檢查客戶的財務狀況和貸款金額,然后,銀行結合這些多個決策程序的結果,決定向客戶發放貸款,
即使這一程序比前一個程序花費更多的時間,銀行也可以利用這一方法獲利,這是一個典型的例子,集體決策優于單一決策程序,現在,你知道這兩個程序代表了什么吧?

這些分別代表決策樹和隨機森林!我們將在這里詳細探討這個想法,深入探討這兩種方法之間的主要區別,并回答關鍵問題,你應該使用哪種演算法?
目錄
-
決策樹簡介
-
隨機森林簡介
-
隨機森林與決策樹的沖突
-
為什么隨機森林優于決策樹?
-
決策樹與隨機森林—你什么時候應該選擇哪種演算法?
決策樹簡介
決策樹是一種有監督的機器學習演算法,可用于分類和回歸問題,決策樹僅僅是為了達到特定結果而做出的一系列順序決策,下面是一個正在運行的決策樹的示例(使用上面的示例):
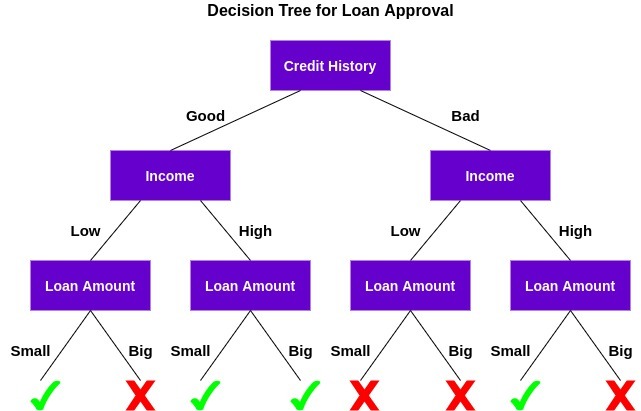
讓我們了解這棵樹是如何作業的,
首先,它檢查客戶是否有良好的信用記錄,在此基礎上,將客戶分為信用記錄良好的客戶和信用記錄不良的客戶兩類,然后,它檢查客戶的收入,并再次將他/她分為兩組,最后,它檢查客戶要求的貸款金額,根據檢查這三個特征的結果,決策樹決定是否應該批準客戶的貸款,
特征/屬性和條件可以根據資料和問題的復雜性而改變,但總體思路保持不變,因此,決策樹根據資料中的一組特征/屬性(在本例中為信用歷史、收入和貸款金額)做出一系列決策,
現在,你可能會想:
為什么決策樹首先檢查信用評分而不是收入?
這被稱為特征的重要性,要檢查的屬性序列是根據基尼系數或資訊增益等標準確定的,對這些概念的解釋超出了本文的討論范圍,但你可以參考以下任一資源來了解有關決策樹的所有資訊:
注:本文的思想是比較決策樹和隨機森林,因此,我不會詳細介紹基本概念,
隨機森林簡介
決策樹演算法易于理解和解釋,但通常,一棵樹不足以產生有效的結果,這就引入隨機森林的概念,

隨機森林是一種基于樹的機器學習演算法,它利用多個決策樹的能力進行決策,顧名思義,這是一片由樹組成的“森林”!
但為什么我們稱之為“隨機”森林?那是因為它是一個由隨機創建的決策樹組成的森林,決策樹中的每個節點對隨機的特征子集進行運算以計算輸出,然后,隨機森林將各個決策樹的輸出組合起來生成最終的輸出,
簡單地說:
隨機森林演算法將多個(隨機創建的)決策樹的輸出組合起來生成最終輸出,
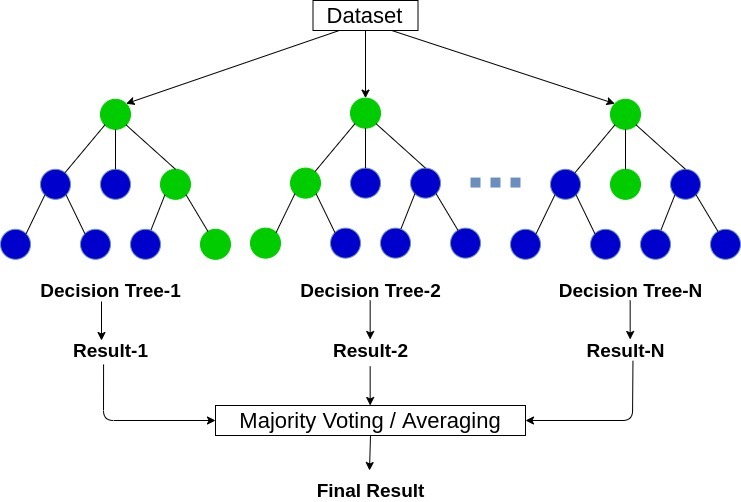
將多個個體模型(也稱為弱學習者)的輸出結合起來的程序稱為集成學習,
現在的問題是,我們如何決定在決策樹和隨機森林之間選擇哪種演算法?在我們做出任何結論之前,讓我們看看他們在實踐中是什么樣子的!
隨機森林與決策樹的沖突
在本節中,我們將使用Python來解決使用決策樹和隨機森林的二分類問題,然后我們將比較他們的結果,看看哪一個最適合我們的問題,
我們將開發貸款預測資料集,這是一個二元分類問題,在這個問題上,我們必須根據一組特定的特征來確定一個人是否應該獲得貸款,
資料集地址:https://datahack.analyticsvidhya.com/contest/practice-problem-loan-prediction-iii/?utm_source=blog&utm_medium=decision-tree-vs-random-forest-algorithm
步驟1:加載庫和資料集
首先匯入所需的Python庫和資料集:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
# 匯入資料集
df=pd.read_csv('dataset.csv')
df.head()

該資料集由614行和13個特征組成,包括信用記錄、婚姻狀況、貸款金額和性別,這里,目標變數是Loan_Status,它指示是否應該向某人提供貸款,
步驟2:資料預處理
現在,是任何資料科學專案中最關鍵的部分——資料預處理和特征工程,在這一節中,我將處理資料中的分類變數,并輸入缺失的值,
我將用模式來估算分類變數中的缺失值,對于連續變數,用平均值(對于各個列)來估算,另外,我們將對資料中的分類值進行標簽編碼,
#資料預處理與空值插補
# 標簽編碼
df['Gender']=df['Gender'].map({'Male':1,'Female':0})
df['Married']=df['Married'].map({'Yes':1,'No':0})
df['Education']=df['Education'].map({'Graduate':1,'Not Graduate':0})
df['Dependents'].replace('3+',3,inplace=True)
df['Self_Employed']=df['Self_Employed'].map({'Yes':1,'No':0})
df['Property_Area']=df['Property_Area'].map({'Semiurban':1,'Urban':2,'Rural':3})
df['Loan_Status']=df['Loan_Status'].map({'Y':1,'N':0})
#零值插補
rev_null=['Gender','Married','Dependents','Self_Employed','Credit_History','LoanAmount','Loan_Amount_Term']
df[rev_null]=df[rev_null].replace({np.nan:df['Gender'].mode(),
np.nan:df['Married'].mode(),
np.nan:df['Dependents'].mode(),
np.nan:df['Self_Employed'].mode(),
np.nan:df['Credit_History'].mode(),
np.nan:df['LoanAmount'].mean(),
np.nan:df['Loan_Amount_Term'].mean()})

步驟3:創建訓練和測驗集
現在,我們將資料集按80:20的比例分別拆分為訓練集和測驗集:
X=df.drop(columns=['Loan_ID','Loan_Status']).values
Y=df['Loan_Status'].values
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 42)
讓我們看看創建的訓練集和測驗集的形狀:
print('Shape of X_train=>',X_train.shape)
print('Shape of X_test=>',X_test.shape)
print('Shape of Y_train=>',Y_train.shape)
print('Shape of Y_test=>',Y_test.shape)
太好了!現在我們準備好進入下一個階段,在那里我們將建立決策樹和隨機森林模型!
步驟4:建立和評估模型
由于我們有訓練集和測驗集,現在是時候訓練我們的模型并對貸款申請進行分類了,首先,我們將在此資料集上訓練決策樹:
# 建立決策樹
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(criterion = 'entropy', random_state = 42)
dt.fit(X_train, Y_train)
dt_pred_train = dt.predict(X_train)
接下來,我們將使用F1分數來評估這個模型,F1分數是精度和召回率的調和平均值,公式如下:
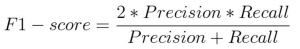
讓我們使用F1分數來評估我們的模型的性能:
#訓練集評估
dt_pred_train = dt.predict(X_train)
print('Training Set Evaluation F1-Score=>',f1_score(Y_train,dt_pred_train))
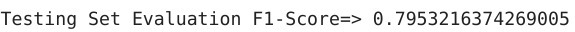
在這里,你可以看到決策樹在樣本內評估時表現良好,但在樣本外評估時其性能急劇下降,你覺得為什么會這樣?這里發生了過擬合,隨機森林能解決這個問題嗎?
建立隨機森林模型
讓我們看看一個正在運行的隨機森林模型:
# 建立隨機森林分類器
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(criterion = 'entropy', random_state = 42)
rfc.fit(X_train, Y_train)
#訓練集評估
rfc_pred_train = rfc.predict(X_train)
print('Training Set Evaluation F1-Score=>',f1_score(Y_train,rfc_pred_train))

在這里,我們可以清楚地看到,在樣本外評估中,隨機森林模型比決策樹表現得更好,讓我們在下一節討論這背后的原因,
為什么隨機森林模型優于決策樹?
隨機森林利用了多個決策樹的能力,它不依賴于單一決策樹給出的特征重要性,讓我們來看看不同演算法對不同特征所賦予的特征重要性:
feature_importance=pd.DataFrame({
'rfc':rfc.feature_importances_,
'dt':dt.feature_importances_
},index=df.drop(columns=['Loan_ID','Loan_Status']).columns)
feature_importance.sort_values(by='rfc',ascending=True,inplace=True)
index = np.arange(len(feature_importance))
fig, ax = plt.subplots(figsize=(18,8))
rfc_feature=ax.barh(index,feature_importance['rfc'],0.4,color='purple',label='Random Forest')
dt_feature=ax.barh(index+0.4,feature_importance['dt'],0.4,color='lightgreen',label='Decision Tree')
ax.set(yticks=index+0.4,yticklabels=feature_importance.index)
ax.legend()
plt.show()
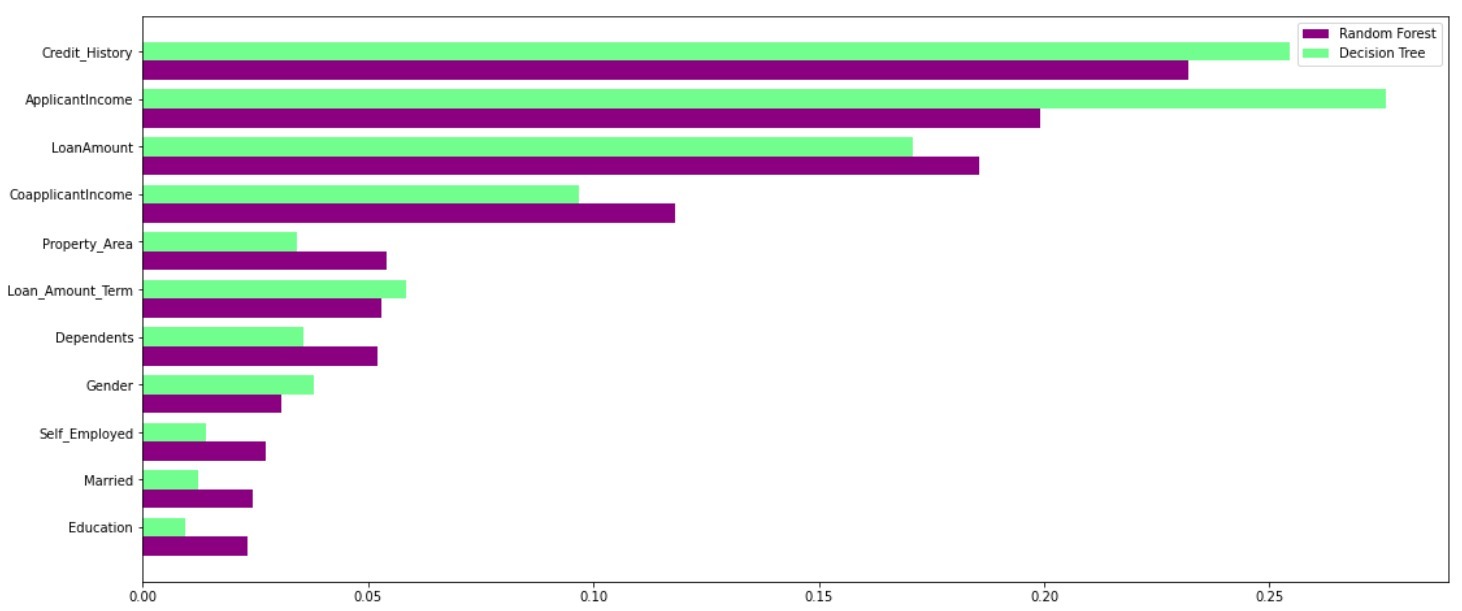
如上圖所示,決策樹模型高度重視一組特定的特征,但在訓練程序中隨機選擇特征,因此,它不高度依賴于任何特定的特性集,這是隨機森林的一個特殊效果,
因此,隨機森林可以更好地對資料進行泛化,這種隨機特征選擇使得隨機森林比決策樹更加精確,
所以你應該選擇哪一個,決策樹還是隨機森林?
當我們有一個大的資料集時,隨機森林是合適的,可解釋性不是主要的關注點,
決策樹更容易解釋和理解,由于一個隨機森林結合了多個決策樹,因此它變得更加難以解釋,好訊息是,要解釋一個隨機的森林并非不可能,
而且,隨機森林比單一決策樹具有更高的訓練時間,你應該考慮到這一點,因為當我們增加隨機森林中的樹木數量時,訓練每一棵樹所需的時間也會增加,當你在機器學習專案中的DDL很緊的時候,這通常是至關重要的,
但我要說的是,盡管不穩定和依賴于一組特定的特性,決策樹還是非常有用的,因為它們更容易解釋,也更容易訓練,任何對資料科學知之甚少的人也可以使用決策樹快速做出資料驅動的決策,
結尾
決策樹和隨機森林的辯論,這是你需要知道的,當你對機器學習還不熟悉的時候,它可能會變得很棘手,但是本文應該為你澄清這些差異和相似之處,
原文鏈接:https://www.analyticsvidhya.com/blog/2020/05/decision-tree-vs-random-forest-algorithm/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14705.html
標籤:其他
上一篇:寫給程式員的機器學習入門 (六) - 應用遞回模型的例子
下一篇:使用OpenCV進行實時車道檢測