作者|Karthik Deivasigamani
編譯|VK
來源|Medium
介紹
電子商務目錄是通過從賣家、供應商/品牌獲取資料而創建的,合作伙伴(銷售商、供應商、品牌)提供的資料往往不完整,有時會遺漏我們客戶正在尋找的關鍵資訊,盡管合作伙伴遵循一個規范(一種發送產品資料的約定格式),但在標題、描述和影像中隱藏著大量資料,除了我們的合作伙伴提供的資料外,互聯網上還有許多非結構化資料,如產品手冊、產品評論、博客、社交媒體網站等,
沃爾瑪正致力于構建一個零售圖譜(Retail Graph),捕捉有關產品及其相關物體的知識,以幫助我們的客戶更好地發現產品,它是一個產品知識圖譜,可以在零售環境中回答有關產品和相關知識的問題,可用于語意搜索、推薦系統等,本文進一步闡述了什么是零售圖譜、如何構建零售圖譜、圍繞圖模型的技術選擇、資料庫和一些用例,
沃爾瑪的零售圖譜是什么
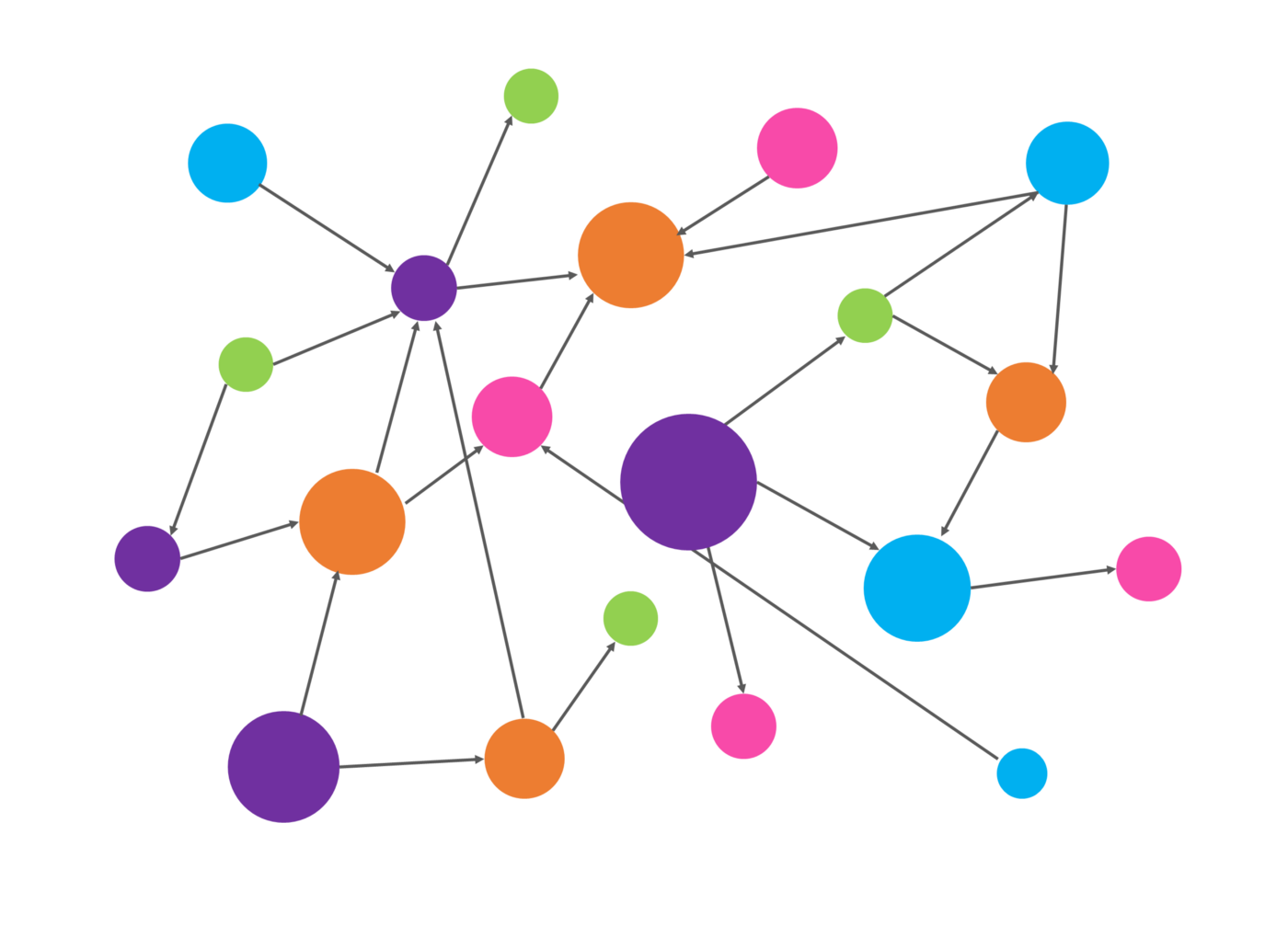
零售圖譜捕獲了零售世界中存在的產品和物體之間的連接,物體是存在的物體、事物、概念或抽象,例如客廳、野生動物攝影、顏色、農舍風格,我們關注的物體大致有兩種:抽象的和具體的,前者幫助我們回答諸如“夏日游泳池派對用品”、“農家客廳家具”、“野生動物攝影鏡頭”之類的問題,而后者幫助我們回答諸如“藍色牛仔褲褲子”、“木制餐桌”之類的問題,該圖譜還將產品之間的關系捕獲到兩個類別,替代品和補充品(附件、兼容產品等),它還試圖將抽象概念(如亮色)映射到具體的產品屬性,
在研究過沃爾瑪的產品目錄后,我們知道在構建這樣一個系統時會遇到一些挑戰,最大的挑戰是缺乏產品資料的唯一權威來源,此外,我們的目錄中也有來自我們合作伙伴的錯誤資料,所以,我們首先:
- 建立二分圖,一邊是生成的,另一邊是相關物體
- 利用我們現有的分類方法在發現新的物體時豐富物體,
- 連接產品與物體,
構建零售圖譜
在較高層次上,我們主要關注以下關系來構建我們的零售圖譜:
- 產品<->物體
- 產品<->產品(大致分為替代品和補充品)
1.產品<->物體
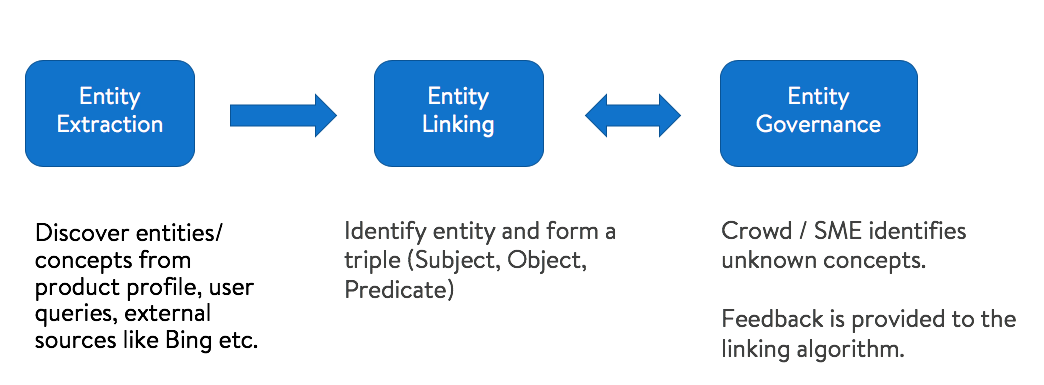
為了構建產品到物體圖,我們首先從產品內容中提取物體,然后將它們鏈接到抽象或具體的概念,形成三元組,我們添加了一個管理層,允許人們在一定的置信水平下得到有效的三元組,以保持高質量標準,
a.物體提取
物體提取模塊的目標是從產品標題和描述中提取“物體”,產品描述內容多種多樣,有時內容很冗長,有時可能是要點中的小短語,考慮到這一點,我們開發了兩種從產品內容中提取物體的演算法:
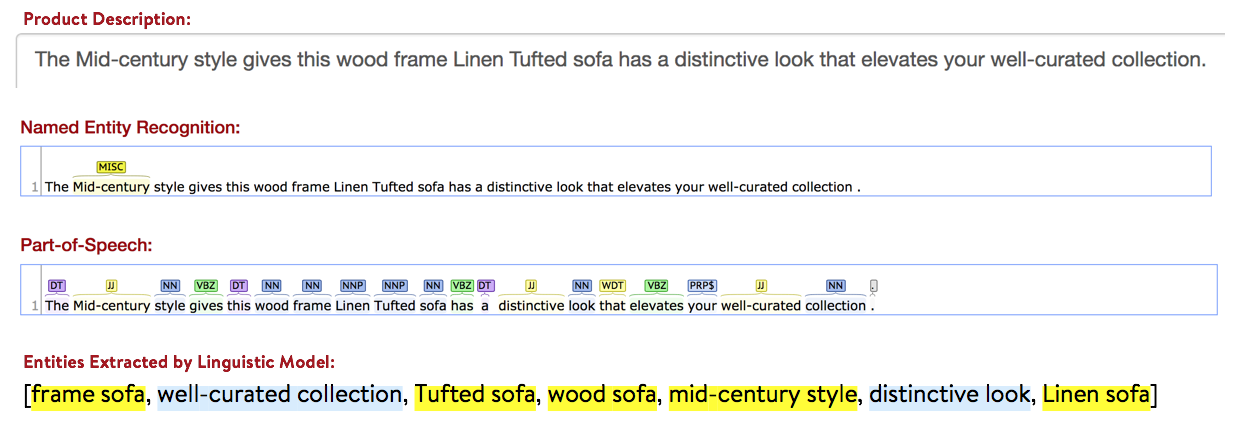
i.基于NLP的模型
我們首先從產品標題、描述和其他元資料中提取物體,這是通過建立一個語言模型來實作的,該模型利用了Standford Core NLP提供的POS標記,這個模型更適合我們的用例,因為產品標題和描述通常是以專案符號的形式出現的,以產品亮點為特征,而不是構造良好的句子,下面是我們基于NLP的模型的輸出示例,
ii.啟發式模型
我們采取的另一種方法產生了良好的結果,就是使用規則來決議描述,賣家/供應商使用某些格式(HTML標記)來突出產品的關鍵特性,我們通過對關鍵資訊應用一組啟發式方法,建立了關于如何決議和提取關鍵資訊的規則,以下是示例產品說明及其輸出:

在生產中,我們可以同時使用上述兩種,這可以給我們一個很好的平衡,啟發式模型非常準確而NLP模型給我們更大的覆寫,
b.物體鏈接
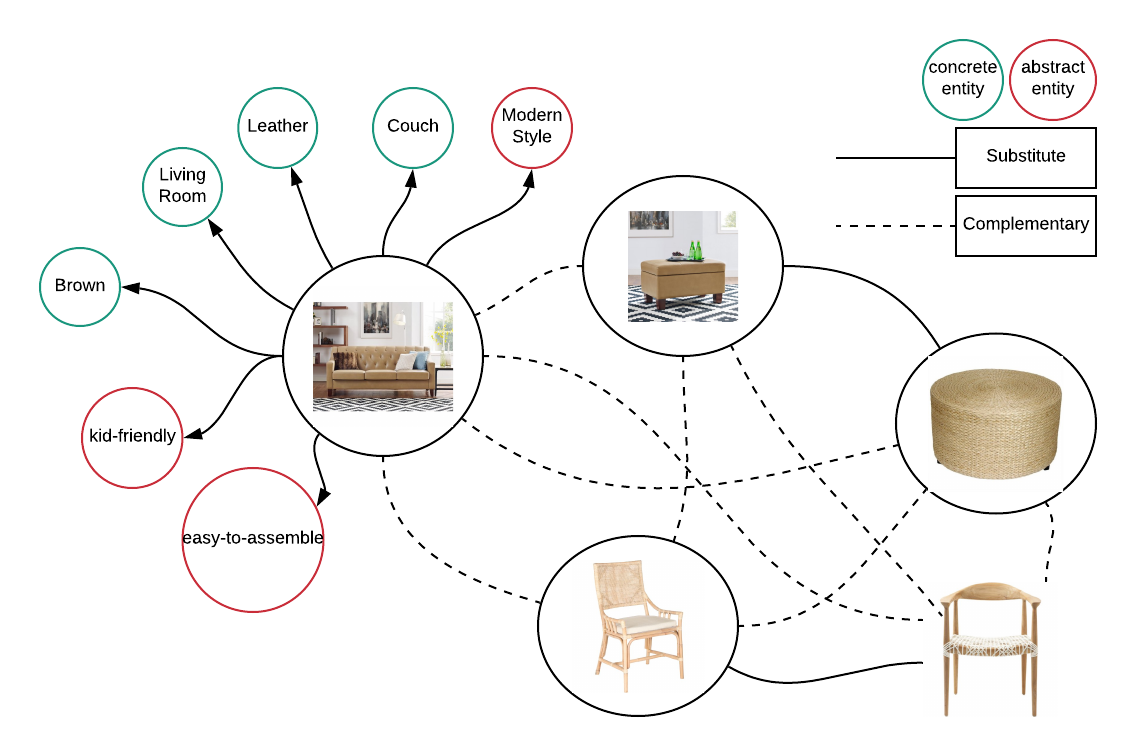
一旦物體被提取出來,我們需要識別它們所代表的內容以及它們與產品的關系,例如,對于“中世紀沙發”這樣的物體,我們必須確定在沙發的背景關系中,中世紀代表什么,這是通過一個稱為物體鏈接的程序來實作的,在這個程序中,我們試圖找到提取的物體與其產品之間的關系,物體鏈接模塊的另一個重要功能是消除給定背景關系的歧義,例如,“cherry(櫻桃)”可以指蠟燭的香味,果汁的香味,家具的香味,布料的顏色,或者櫻桃這種水果,這里所指的背景關系通常是產品類別或產品型別,
聯結器將背景關系(產品型別)和物體作為輸入,并生成一個三元組(主語-賓語謂詞),由于產品資料沒有一個準確的真實來源,連接物體的任務變得很困難,我們首先從一組最暢銷的產品(我們假設最暢銷的產品有更準確的資料)創建一個產品型別、屬性名和屬性值三元組的字典,第一步是使用這個字典,在背景關系不可知的時候確定可能的候選串列,然后運行第二個模型,通過使用背景關系對它們進行排序,
對于上面提取的物體,聯結器輸出如下所示:
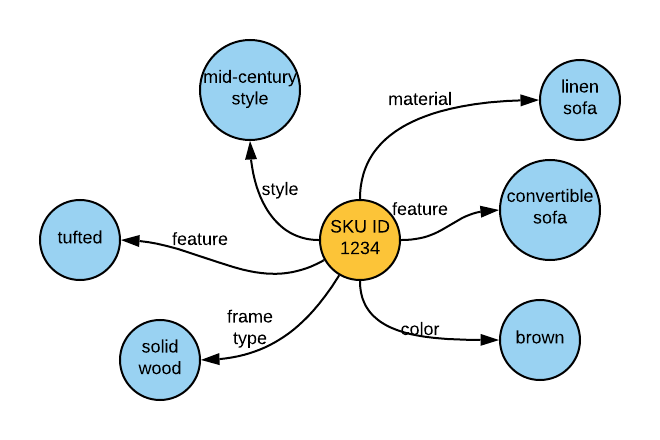
c.物體管理
作為物體提取的一部分,也會提取大量的“噪聲”,我們使用現有的產品元資料構建了一個字典,作為將提取的物體分類為噪聲或“未知”概念的參考,然后,我們添加了一個管理模塊,該模塊可以使用啟發式和手動標記的組合來消除噪聲,這確保了進入知識圖譜的資料總是干凈可靠的,
2.產品<->產品
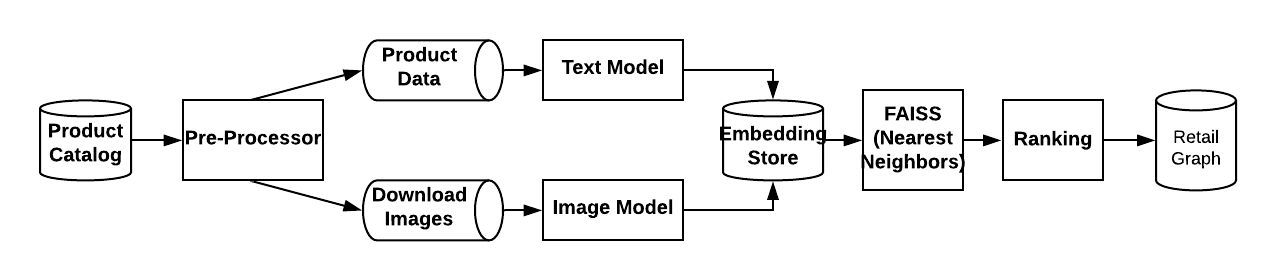
為了識別給定產品的替代品,我們同時利用文本資料和影像資料,在家具、服裝等產品類別中,視覺相似性在識別替代品方面起著重要作用,我們為我們的產品構建了影像嵌入和文本嵌入,并將它們放入FAISS索引中(FAISS是Facebook開發的一個高效相似性搜索和向量聚類別庫),對于每個產品,我們從文本嵌入和影像嵌入兩方面生成其KNN(k近鄰),以得到候選集,在那之后,我們應用一個類別特定的排名邏輯來得出最終的結果,例如,在家具類別的情況下,“家居裝飾風格”(中世紀/沿海/農舍)在確定可替代性方面起著關鍵作用,
架構
當我們開始構建零售圖譜的旅程時,我們不太確定系統的最終狀態會是什么樣子,我們只知道我們需要一個組件來提取物體,鏈接它們,然后存盤它們,考慮到我們產品目錄的規模,我們知道每一個都必須擴展到100億個產品,此外,還需要快速試驗、構建并快速迭代以獲得反饋,我們決定采用進化架構原則來構建我們的系統(https://evolutionaryarchitecture.com),
一個進化的體系結構支持增量的、有指導的變化,這是跨越多個維度的首要原則,
物體提取和鏈接被構建為簡單的庫,然后作為REST風格的API公開給其他系統集成,我們還在物體提取和物體聯結器庫之上構建了Hive udf,以便在我們的Hadoop集群上按比例運行它們,
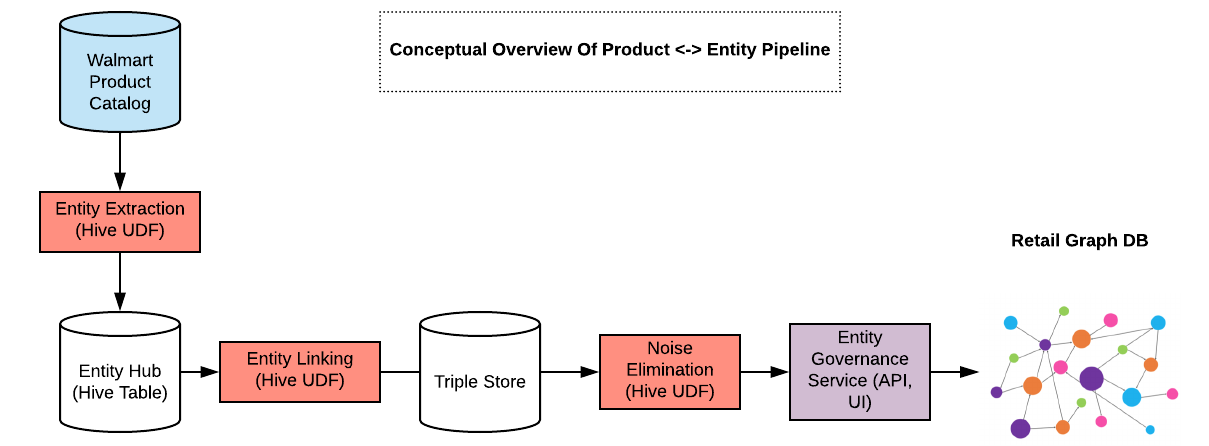
資料處理管道
我們有兩條管道-一條用于生成產品<->物體,另一條用于生成產品<->產品,它們定期在我們的資料平臺團隊管理的Hadoop集群上運行,以下是對資料處理管道的高度概述:
圖資料模型和圖資料庫
在聚合到LPG(標記屬性圖)之前,我們已經為讀寫用例測驗了LPG和RDF圖資料模型,在對內部的圖形資料庫進行了一些實驗之后,我們縮小了對圖資料模型的范圍,我們與Azure團隊密切合作,為我們提供Java支持,以實作資料的大容量接收,對于圖形遍歷,我們使用gremlin,
沃爾瑪內部應用程式
為沃爾瑪產品目錄的大小構建產品知識圖譜需要相當長的時間,我們在構建這個模型時,一次只使用一個類別,然后學習并擴展到其他類別,我們開始這項作業的重點是家庭類和花園類,我們在沃爾瑪產品頁面上做了一個a/B測驗,與使用產品關系的商品推薦團隊一起作業,
我們的電子商務語意搜索團隊正與我們緊密合作,利用零售圖譜中的關系構建一個新的查詢理解系統,我們目前正在運行交錯測驗,A/B測驗,以收集客戶對我們的新語意搜索實作的反饋,
結尾
很難在一篇文章中詳細介紹零售圖譜的各個細節,但我希望這能提供一個不錯的概述,我們還有很長的路要走,像這樣的計劃需要快速的迭代、大量的實驗,我很幸運,有一個偉大的工程師和資料科學家的團隊來合作這個有趣的專案!
原文鏈接:https://medium.com/walmartlabs/retail-graph-walmarts-product-knowledge-graph-6ef7357963bc
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14715.html
標籤:其他
上一篇:使用OpenCV進行實時車道檢測