原來你是這樣的BERT,i了i了! —— 超詳細BERT介紹(一)BERT主模型的結構及其組件
BERT(Bidirectional Encoder Representations from Transformers)是谷歌在2018年10月推出的深度語言表示模型,
一經推出便席卷整個NLP領域,帶來了革命性的進步,
從此,無數英雄好漢競相投身于這場追劇(芝麻街)運動,
只聽得這邊G家110億,那邊M家又1750億,真是好不熱鬧!
然而大家真的了解BERT的具體構造,以及使用細節嗎?
本文就帶大家來細品一下,
前言
本系列文章分成三篇介紹BERT,本文主要介紹BERT主模型(BertModel)的結構及其組件相關知識,另有兩篇分別介紹BERT預訓練相關和如何將BERT應用到不同的下游任務,
文章中的一些縮寫:NLP(natural language processing)自然語言處理;CV(computer vision)計算機視覺;DL(deep learning)深度學習;NLP&DL 自然語言處理和深度學習的交叉領域;CV&DL 計算機視覺和深度學習的交叉領域,
文章公式中的向量均為行向量,矩陣或張量的形狀均按照PyTorch的方式描述,
向量、矩陣或張量后的括號表示其形狀,
本系列文章的代碼均是基于transformers庫(v2.11.0)的代碼(基于Python語言、PyTorch框架),
為便于理解,簡化了原代碼中不必要的部分,并保持主要功能等價,
在代碼最開始的地方,需要匯入以下包:
代碼
from math import inf, sqrt
import torch as tc
from torch import nn
from torch.nn import functional as F
from transformers import PreTrainedModel
閱讀本系列文章需要一些背景知識,包括Word2Vec、LSTM、Transformer-Base、ELMo、GPT等,由于本文不想過于冗長(其實是懶),以及相信來看本文的讀者們也都是沖著BERT來的,所以這部分內容還請讀者們自行學習,
本文假設讀者們均已有相關背景知識,
目錄
- 1、主模型
- 1.1、輸入
- 1.2、嵌入層
- 1.2.1、嵌入變換
- 1.2.2、層標準化
- 1.2.3、隨機失活
- 1.3、編碼器
- 1.3.1、隱藏層
- 1.3.1.1、線性變換
- 1.3.1.2、激活函式
- 1.3.1.2.1、tanh
- 1.3.1.2.2、softmax
- 1.3.1.2.3、GELU
- 1.3.1.3、多頭自注意力
- 1.3.1.4、跳躍連接
- 1.3.1、隱藏層
- 1.4、池化層
- 1.5、輸出
1、主模型
BERT的主模型是BERT中最重要組件,BERT通過預訓練(pre-training),具體來說,就是在主模型后再接個專門的模塊計算預訓練的損失(loss),預訓練后就得到了主模型的引數(parameter),當應用到下游任務時,就在主模型后接個跟下游任務配套的模塊,然后主模型賦上預訓練的引數,下游任務模塊隨機初始化,然后微調(fine-tuning)就可以了(注意:微調的時候,主模型和下游任務模塊兩部分的引數一般都要調整,也可以凍結一部分,調整另一部分),
主模型由三部分構成:嵌入層、編碼器、池化層,
如圖:

其中
- 輸入:一個個小批(mini-batch),小批里是
batch_size個序列(句子或句子對),每個序列由若干個離散編碼向量組成, - 嵌入層:將輸入的序列轉換成連續分布式表示(distributed representation),即詞嵌入(word embedding)或詞向量(word vector),
- 編碼器:對每個序列進行非線性表示,
- 池化層:取出
[CLS]標記(token)的表示(representation)作為整個序列的表示, - 輸出:編碼器最后一層輸出的表示(序列中每個標記的表示)和池化層輸出的表示(序列整體的表示),
下面具體介紹這些部分,
1.1、輸入
一般來說,輸入BERT的可以是一句話:
I'm repairing immortals.
也可以是兩句話:
I'm repairing immortals. ||| Me too.
其中|||是分隔兩個句子的分隔符,
BERT先用專門的標記器(tokenizer)來標記(tokenize)序列,雙句標記后如下(單句類似):
I ' m repair ##ing immortal ##s . ||| Me too .
標記器其實就是先對句子進行基于規則的標記化(tokenization),這一步可以把'm以及句號.等分割開,再進行子詞分割(subword segmentation),示例中帶##的就是被子詞分割開的部分,
子詞分割有很多好處,比如壓縮詞匯表、表示未登錄詞(out of vocabulary words, OOV words)、表示單詞內部結構資訊等,以后有時間專門寫一篇介紹這個,
資料集中的句子長度不一定相等,BERT采用固定輸入序列(長則截斷,短則填充)的方式來解決這個問題,
首先需要設定一個seq_length超引數(hyperparameter),然后判斷整個序列長度是否超出,如果超出:單句截掉最后超出的部分,雙句則先刪掉較長的那句話的末尾標記,如果兩句話長度相等,則輪流刪掉兩句話末尾的標記,直到總長度達到要求(即等長的兩句話刪掉的標記數量盡量相等);如果序列長度過小,則在句子最后添加[PAD]標記,使長度達到要求,
然后在序列最開始添加[CLS]標記,以及在每句話末尾添加[SEP]標記,
單句話添加一個[CLS]和一個[SEP],雙句話添加一個[CLS]和兩個[SEP],
[CLS]標記對應的表示作為整個序列的表示,[SEP]標記是專門用來分隔句子的,
注意:處理長度時需要考慮添加的[CLS]和[SEP]標記,使得最終總的長度=seq_length;[PAD]標記在整個序列的最末尾,
例如seq_length=12,則單句變為:
[CLS] I ' m repair ##ing immortal ##s . [SEP] [PAD] [PAD]
如果seq_length=10,則雙句變為:
[CLS] I ' m repair [SEP] Me too . [SEP]
分割完后,每一個空格分割的子字串(substring)都看成一個標記(token),標記器通過查表將這些標記映射成整數編碼,
單句如下:
[101, 146, 112, 182, 6949, 1158, 15642, 1116, 119, 102, 0, 0]
最后整個序列由四種型別的編碼向量表示,單句如下:
標記編碼:[101, 146, 112, 182, 6949, 1158, 15642, 1116, 119, 102, 0, 0]
位置編碼:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
句子位置編碼:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
注意力掩碼:[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]
其中,標記編碼就是上面的序列中每個標記轉成編碼后得到的向量;位置編碼記錄每個標記的位置;句子位置編碼記錄每個標記屬于哪句話,0是第一句話,1是第二句話(注意:[CLS]標記對應的是0);注意力掩碼記錄某個標記是否是填充的,1表示非填充,0表示填充,
雙句如下:
標記編碼:[101, 146, 112, 182, 6949, 102, 2508, 1315, 119, 102]
位置編碼:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
句子位置編碼:[0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
注意力掩碼:[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
上面的是英文的情況,中文的話BERT直接用漢字級別表示,即
我在修仙( ̄︶ ̄)↗
這樣的句子分割成
我 在 修 仙 (  ̄ ︶  ̄ ) ↗
然后每個漢字(包括中文標點)看成一個標記,應用上述操作即可,
1.2、嵌入層
嵌入層的作用是將序列的離散編碼表示轉換成連續分布式表示,
離散編碼只能表示A和B相等或不等,但是如果將其表示成連續分布式表示(即連續的N維空間向量),就可以計算\(A\)與\(B\)之間的相似度或距離了,從而表達更多資訊,
這個是詞嵌入或詞向量的知識,可以參考Word2Vec相關內容,本文不再贅述了,
嵌入層包含三種組件:嵌入變換(embedding)、層標準化(layer normalization)、隨機失活(dropout),
如圖:
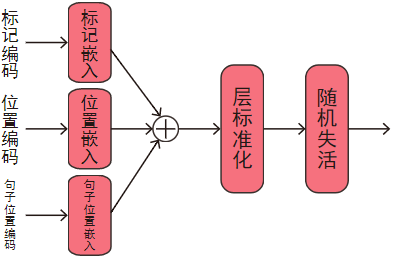
1.2.1、嵌入變換
嵌入變換實際上就是一個線性變換(linear transformation),
傳統上,離散標記往往表示成一個獨熱碼(one-hot)向量,也叫標準基向量,即一個長度為\(V\)的向量,其中只有一位為\(1\),其他都為\(0\),
在NLP&DL領域,\(V\)一般是詞匯表的大小,
但是這種向量往往維數很高(詞匯表往往比較大)而且很稀疏(每個向量只有一位不為\(0\)),不好處理,
所以可以通過一個線性變換將這個向量轉換成低維稠密的向量,
假設\(v\)(\(V\))是標記\(t\)的獨熱碼向量,\(W\)(\(V \times H\))是一個\(V\)行\(H\)列的矩陣,則\(t\)的嵌入\(e\)為:
\[e = v W \]實際上\(W\)中每一行都可以看成一個詞嵌入,而這個矩陣乘就是把\(v\)中等于\(1\)的那個位置對應的\(W\)中的詞嵌入取出來,
在工程實踐中,由于獨熱碼向量比較占記憶體,而且矩陣乘效率也不高,所以往往用一個整數編碼來代替獨熱碼向量,然后直接用查表的方式取出對應的詞嵌入,
所以假設\(n\)是\(t\)的編碼,一般是在詞匯表中的編號,那么上面的公式就可以改成:
\[e = W_{n} \]其中下標表示取出對應的行,
那么一個標記化后的序列就可以表示成一個編碼向量,
假設序列\(T\)的編碼向量為\(s\)(\(L\)),\(L\)為序列的長度,即\(T\)中有\(L\)個標記,
如果詞嵌入長度為\(H\),那么經過嵌入變換,得到\(T\)的隱狀態(hidden state)\(h\)(\(L \times H\)),
1.2.2、層標準化
層標準化類似于批標準化(batch normalization),可以加速模型訓練,但其實作方式和批標準化不一樣,層標準化是沿著詞嵌入(通道)維進行標準化的,不需要在訓練時存盤統計量來估計整體資料集的均值和方差,訓練(training)和評估(evaluation)或推理(inference)階段的操作是相同的,
另外批標準化對小批大小有限制,而層標準化則沒有限制,
假設輸入的一個詞嵌入為\(e = [x_0, x_1, ..., x_{H-1}]\),\(x_k\)是\(e\)第\(k = 0, 1, ..., (H-1)\) 維的分量,\(H\)是詞嵌入長度,
那么層標準化就是
其中,\(y_{k}\)是輸出,\(\mu\)和\(\sigma^2\)分別是均值和方差:
\[ \mu = \frac{1}{H} \sum_{k=0}^{H-1} x_{k} \\ \sigma^2 = \frac{1}{H} \sum_{k=0}^{H-1} (x_{k}-\mu)^2 \\ \]\(\alpha_k\)和\(\beta_k\)是學習得到的引數,用于防止模型表示能力退化,
注意:\(\mu\)和\(\sigma^2\)是針對每個樣本每個位置的詞嵌入分別計算的,而\(\alpha_k\)和\(\beta_k\)對所有的詞嵌入都是共用的;\(\sigma^2\)的計算沒有使用貝塞爾校正(Bessel's correction),
1.2.3、隨機失活
隨機失活是DL領域非常著名且常用的正則化(regularization)方法(然而被谷歌注冊專利了),用來防止模型過擬合(overfitting),
具體來說,先設定一個超引數\(P \in [0, 1]\),表示按照概率\(P\)隨機將值置\(0\),
然后假設詞嵌入中某一維分量是\(x\),按照均勻隨機分布產生一個亂數\(r \in [0, 1]\),然后輸出值\(y\)為:
由于按照概率\(P\)置\(0\),相當于輸出值的期望變成原來的\((1-P)\)倍,所以再對輸出值除以\((1-P)\),就可以保持期望不變,
以上操作針對訓練階段,在評估階段,輸出值等于輸入值:
\[y = x \]嵌入層代碼如下:
代碼
# BERT之嵌入層
class BertEmb(nn.Module):
def __init__(self, config):
super().__init__()
# 標記嵌入,padding_idx=0:編碼為0的嵌入始終為零向量
self.tok_emb = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=0)
# 位置嵌入
self.pos_emb = nn.Embedding(config.max_position_embeddings, config.hidden_size)
# 句子位置嵌入
self.sent_pos_emb = nn.Embedding(config.type_vocab_size, config.hidden_size)
# 層標準化
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
# 隨機失活
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self,
tok_ids, # 標記編碼(batch_size * seq_length)
pos_ids=None, # 位置編碼(batch_size * seq_length)
sent_pos_ids=None, # 句子位置編碼(batch_size * seq_length)
):
device = tok_ids.device # 設備(CPU或CUDA)
shape = tok_ids.shape # 形狀(batch_size * seq_length)
seq_length = shape[1]
# 默認:[0, 1, ..., seq_length-1]
if pos_ids is None:
pos_ids = tc.arange(seq_length, dtype=tc.int64, device=device)
pos_ids = pos_ids.unsqueeze(0).expand(shape)
# 默認:[0, 0, ..., 0],即所有標記都屬于第一個句子
if sent_pos_ids is None:
sent_pos_ids = tc.zeros(shape, dtype=tc.int64, device=device)
# 三種嵌入(batch_size * seq_length * hidden_size)
tok_embs = self.tok_emb(tok_ids)
pos_embs = self.pos_emb(pos_ids)
sent_pos_embs = self.sent_pos_emb(sent_pos_ids)
# 三種嵌入相加
embs = tok_embs + pos_embs + sent_pos_embs
# 層標準化嵌入
embs = self.layer_norm(embs)
# 隨機失活嵌入
embs = self.dropout(embs)
return embs # 嵌入(batch_size * seq_length * hidden_size)
其中,
config是BERT的組態檔物件,里面記錄了各種預先設定的超引數;
vocab_size是詞匯表大小;
hidden_size是詞嵌入長度,默認是768(bert-base-*)或1024(bert-large-*);
max_position_embeddings是允許的最大標記位置,默認是512;
type_vocab_size是允許的最大句子位置,即最多能輸入的句子數量,默認是2;
layer_norm_eps是一個>0并很接近0的小數\(\epsilon\),用來防止計算時發生除0等例外操作;
hidden_dropout_prob是隨機失活概率,默認是0.1;
batch_size是小批的大小,即一個小批里的樣本個數;
seq_length是輸入的編碼向量的長度,
1.3、編碼器
編碼器的作用是對嵌入層輸出的隱狀態進行非線性表示,提取出其中的特征(feature),它是由num_hidden_layers個結構相同(超引數相同)但引數不同(不共享引數)的隱藏層串連構成的,
如圖:
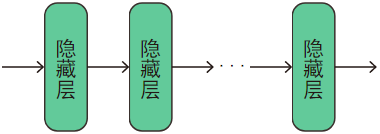
1.3.1、隱藏層
隱藏層包括線性變換、激活函式(activation function)、多頭自注意力(multi-head self-attention)、跳躍連接(skip connection),以及上面介紹過的層標準化和隨機失活,
如圖:
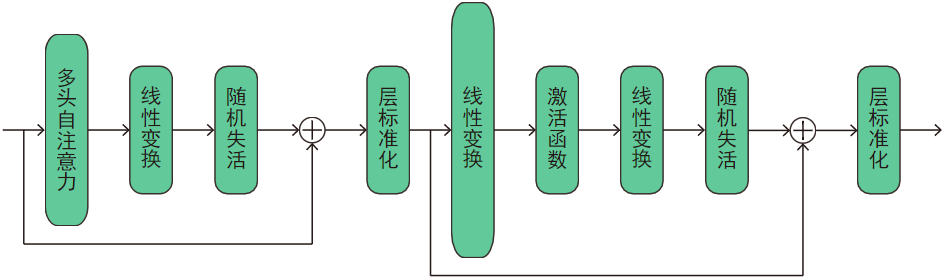
其中,激活函式默認是GELU,線性變換均是逐位置線性變換,即對不同樣本不同位置的詞嵌入應用相同的線性變換(類似于CV&DL領域的\(1 \times 1\)卷積),
1.3.1.1、線性變換
線性變換在CV&DL領域也叫全連接層(fully connected layer),即
\[y = x W^T + b \]其中,\(x\)(\(A\))是輸入向量,\(y\)(\(B\))是輸出向量,\(W\)(\(B \times A\))是權重(weight)矩陣,\(b\)(\(B\))是偏置(bias)向量;\(W\)和\(b\)是學習得到的引數,
另外,嚴格來說,當\(b = \vec 0\)時,上式為線性變換;當\(b \ne \vec 0\)時,上式為仿射變換(affine transformation),
但是在DL中,人們往往并不那么摳字眼,對于這兩種變換,一般都簡單地稱為線性變換,
1.3.1.2、激活函式
激活函式在DL中非常關鍵!
因為如果要提高一個神經網路(neural network)的表示能力,往往需要加深網路的深度,
然而如果只疊加多個線性變換的話,這等價于一個線性變換(大家可以推推看)!
所以只有在線性變換后接一個非線性變換(nonlinear transformation),即激活函式,才能逐漸加深網路并提高表示能力,
激活函式有很多,常見的包括sigmoid、tanh、softmax、ReLU、GELU、Swish、Mish等,
本文只講和BERT相關的激活函式:tanh、softmax、GELU,
1.3.1.2.1、tanh
激活函式的一個功能是調整輸入值的取值范圍,
tanh即雙曲正切函式,可以將\((-\infty, +\infty)\)的數映射到\((-1, 1)\),并且嚴格單調,
函式影像如圖:

tanh在NLP&DL領域用得比較多,
1.3.1.2.2、softmax
softmax顧名思義,它可以對輸入的一組數值根據其大小給出每個數值的概率,數值越大,概率越高,且概率求和為\(1\),
假設輸入\(x_k\),\(k = 0, 1, ..., (N-1)\),則輸出值\(y_k\)為:
\[y_k = \frac{exp(x_k)}{\sum_{i=0}^{N-1} exp(x_i)} \]實際上,對于任意一個對數幾率(logit)\(x \in (-\infty, +\infty)\),\(x\)越大,表示某個事件發生的可能性越大,softmax可以將其轉化為概率,即將取值范圍映射到\((0, 1)\),
1.3.1.2.3、GELU
GELU(Gaussian Error Linear Units)是2016年6月提出的一個激活函式,
GELU相比ReLU曲線更為光滑,允許梯度更好地傳播,
GELU的想法類似于隨機失活,隨機失活是按照0-1分布,又叫兩點分布,也叫伯努利分布(Bernoulli distribution),隨機通過輸入值;而GELU則是將這個概率分布改成正態分布(Normal distribution),也叫高斯分布(Gaussian distribution),然后輸出期望,
假設輸入值是\(x\),輸出值是\(y\),那么GELU就是:
\[y = x P(X \le x) \]其中,\(X \sim \mathcal{N}(0, 1)\),\(P\)為概率,
GELU的函式影像如圖:

其中藍線為ReLU函式影像,橙線為GELU函式影像,
1.3.1.3、多頭自注意力
多頭自注意力是Transformer的一大特色,
多頭自注意力的名字可以分成三個詞:多頭、自、注意力:
- 注意力:是DL領域近年來最重要的創新之一!可以使模型以不同的方式對待不同的輸入(即分配不同的權重),而無視空間(即輸入向量排成線形、面形、樹形、圖形等拓撲結構)的形狀、大小、距離,
- 自:是在普通的注意力基礎上修改而來的,可以表示輸入與自身的依賴關系,
- 多頭:是對注意力中涉及的向量分別拆分計算,從而提高表示能力,
對于一般的多頭注意力,假設計算\(x\)(\(H\))對\(y_i\)(\(H\)),\(i = 0, 1, ..., (L-1)\),的多頭注意力,則首先計算\(q\)(H)、\(k_i\)(H)、\(v_i\)(H):
\[ q = x W_q^T + b_q \\ k_i = y_i W_k^T + b_k \\ v_i = y_i W_v^T + b_v \\ \]其中,\(W_z\)(\(H \times H\))和\(b_z\)(\(H\))分別為權重矩陣和偏置向量,\(z \in \{ q, k, v \}\),
然后將這三種向量等長度拆分成\(S\)個向量,稱為頭向量:
上式中的分號為串連操作,即把多個向量拼接起來組成一個更長的向量,
其中,每個頭向量長度都為\(D\),且\(S \times D = H\),
然后計算\(q_j\)對\(k_{ij}\)的注意力分數\(s_{ij}\):
\[s_{ij} = \frac{q_j k_{ij}^T}{\sqrt{D}} \]之后可以添加注意力掩碼(也可以不加),即令\(s_{mj} = -\infty\),\(m\)是需要添加掩碼的位置,
然后通過softmax計算注意力概率\(p_{ij}\):
之后對注意力概率進行隨機失活:
\[\hat{p}_{ij} = dropout(p_{ij}) \]再之后計算輸出向量\(r_j\)(\(D\)):
\[r_j = \sum_{i=0}^{L-1} \hat{p}_{ij} v_{ij} \]最終的輸出向量是把每一頭的輸出向量串連起來:
\[r = [r_0; r_1; ...; r_{S-1}] \]其中\(r\)(\(H\))為最終的輸出向量,
如果令\(x = y_n\),\(n \in \{ 0, 1, ..., L-1 \}\),即\(x\)是\(y_i\)中的某一個向量,那么多頭注意力就變為多頭自注意力,
代碼如下:
代碼
# BERT之多頭自注意力
class BertMultiHeadSelfAtt(nn.Module):
def __init__(self, config):
super().__init__()
# 注意力頭數
self.num_heads = config.num_attention_heads
# 注意力頭向量長度
self.head_size = config.hidden_size // config.num_attention_heads
self.query = nn.Linear(config.hidden_size, config.hidden_size)
self.key = nn.Linear(config.hidden_size, config.hidden_size)
self.value = https://www.cnblogs.com/wangzb96/p/nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
# 輸入(batch_size * seq_length * hidden_size)
# 輸出(batch_size * num_heads * seq_length * head_size)
def shape(self, x):
shape = (*x.shape[:2], self.num_heads, self.head_size)
return x.view(*shape).transpose(1, 2)
# 輸入(batch_size * num_heads * seq_length * head_size)
# 輸出(batch_size * seq_length * hidden_size)
def unshape(self, x):
x = x.transpose(1, 2).contiguous()
return x.view(*x.shape[:2], -1)
def forward(self,
inputs, # 輸入(batch_size * seq_length * hidden_size)
att_masks=None, # 注意力掩碼(batch_size * seq_length * hidden_size)
):
mixed_querys = self.query(inputs)
mixed_keys = self.key(inputs)
mixed_values = self.value(inputs)
querys = self.shape(mixed_querys)
keys = self.shape(mixed_keys)
values = self.shape(mixed_values)
# 注意力分數(batch_size * num_heads * seq_length * seq_length)
att_scores = querys.matmul(keys.transpose(2, 3))
# 縮放注意力分數
att_scores = att_scores / sqrt(self.head_size)
# 添加注意力掩碼
if att_masks is not None:
att_scores = att_scores + att_masks
# 注意力概率(batch_size * num_heads * seq_length * seq_length)
att_probs = att_scores.softmax(dim=-1)
# 隨機失活注意力概率
att_probs = self.dropout(att_probs)
# 輸出(batch_size * num_heads * seq_length * head_size)
outputs = att_probs.matmul(values)
outputs = self.unshape(outputs)
return outputs # 輸出(batch_size * seq_length * hidden_size)
其中,
num_attention_heads是注意力頭數,默認是12(bert-base-*)或16(bert-large-*);
attention_probs_dropout_prob是注意力概率的隨機失活概率,默認是0.1,
1.3.1.4、跳躍連接
跳躍連接也是DL領域近年來最重要的創新之一!
跳躍連接也叫殘差連接(residual connection),
一般來說,傳統的神經網路往往是一層接一層串連而成,前一層輸出作為后一層輸入,
而跳躍連接則是某一層的輸出,跳過若干層,直接輸入某個更深的層,
例如BERT的每個隱藏層中有兩個跳躍連接,
跳躍連接的作用是防止神經網路梯度消失或梯度爆炸,使損失曲面(loss surface)更平滑,從而使模型更容易訓練,使神經網路可以設定得更深,
按我個人的理解,一般來說,線性變換是最能保持輸入資訊的,而非線性變換則往往會損失一部分資訊,但是為了網路的表示能力不得不線性變換與非線性變換多次堆疊,這樣網路深層接收到的資訊與最初輸入的資訊比可能已經面目全非,而跳躍連接則可以讓輸入資訊原汁原味地傳播得更深,
隱藏層代碼如下:
代碼
# BERT之隱藏層
class BertLayer(nn.Module):
# noinspection PyUnresolvedReferences
def __init__(self, config):
super().__init__()
# 多頭自注意力
self.multi_head_self_att = BertMultiHeadSelfAtt(config)
self.linear = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
# 升維線性變換
self.linear_1 = nn.Linear(config.hidden_size, config.intermediate_size)
# 激活函式,默認:GELU
self.act_fct = F.gelu
# 降維線性變換,使向量大小保持不變
self.linear_2 = nn.Linear(config.intermediate_size, config.hidden_size)
self.dropout_1 = nn.Dropout(config.hidden_dropout_prob)
self.layer_norm_1 = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self,
inputs, # 輸入(batch_size * seq_length * hidden_size)
att_masks=None, # 注意力掩碼(batch_size * seq_length * hidden_size)
):
outputs = self.multi_head_self_att(inputs, att_masks=att_masks)
outputs = self.linear(outputs)
outputs = self.dropout(outputs)
att_outputs = self.layer_norm(outputs + inputs) # 跳躍連接
outputs = self.linear_1(att_outputs)
outputs = self.act_fct(outputs)
outputs = self.linear_2(outputs)
outputs = self.dropout_1(outputs)
outputs = self.layer_norm_1(outputs + att_outputs) # 跳躍連接
return outputs # 輸出(batch_size * seq_length * hidden_size)
其中,
intermediate_size是中間一個升維線性變換升維后的長度,默認是3072(bert-base-*)或4096(bert-large-*),
編碼器代碼如下:
代碼
# BERT之編碼器
class BertEnc(nn.Module):
def __init__(self, config):
super().__init__()
# num_hidden_layers個隱藏層
self.layers = nn.ModuleList([BertLayer(config)
for _ in range(config.num_hidden_layers)])
# noinspection PyTypeChecker
def forward(self,
inputs, # 輸入(batch_size * seq_length * hidden_size)
att_masks=None, # 注意力掩碼(batch_size * seq_length)
):
# 調整注意力掩碼的值和形狀
if att_masks is not None:
device = inputs.device # 設備(CPU或CUDA)
dtype = inputs.dtype # 資料型別(float16、float32或float64)
shape = att_masks.shape # 形狀(batch_size * seq_length)
t = tc.zeros(shape, dtype=dtype, device=device)
t[att_masks<=0] = -inf # exp(-inf) = 0
t = t[:, None, None, :]
att_masks = t
outputs = inputs
for layer in self.layers:
outputs = layer(outputs, att_masks=att_masks)
return outputs # 輸出(batch_size * seq_length * hidden_size)
其中,
num_hidden_layers是隱藏層數量,默認是12(bert-base-*)或24(bert-large-*),
1.4、池化層
池化層是將[CLS]標記對應的表示取出來,并做一定的變換,作為整個序列的表示并回傳,以及原封不動地回傳所有的標記表示,
如圖:
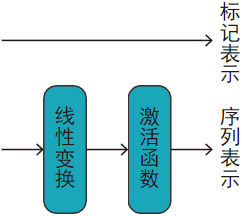
其中,激活函式默認是tanh,
池化層代碼如下:
代碼
# BERT之池化層
class BertPool(nn.Module):
def __init__(self, config):
super().__init__()
self.linear = nn.Linear(config.hidden_size, config.hidden_size)
self.act_fct = F.tanh
def forward(self,
inputs, # 輸入(batch_size * seq_length * hidden_size)
):
# 取[CLS]標記的表示
outputs = inputs[:, 0]
outputs = self.linear(outputs)
outputs = self.act_fct(outputs)
return outputs # 輸出(batch_size * hidden_size)
1.5、輸出
主模型最后輸出所有的標記表示和整體的序串列示,分別用于針對每個標記的預測任務和針對整個序列的預測任務,
主模型代碼如下:
代碼
# BERT之預訓練模型抽象基類
class BertPreTrainedModel(PreTrainedModel):
from transformers import BertConfig
from transformers import BERT_PRETRAINED_MODEL_ARCHIVE_MAP
from transformers import load_tf_weights_in_bert
config_class = BertConfig
pretrained_model_archive_map = BERT_PRETRAINED_MODEL_ARCHIVE_MAP
load_tf_weights = load_tf_weights_in_bert
base_model_prefix = 'bert'
# 注意力頭剪枝
def _prune_heads(self, heads_to_prune):
pass
# 引數初始化
def _init_weights(self, module):
config = self.config
f = lambda x: x is not None and x.requires_grad
if isinstance(module, nn.Embedding):
if f(module.weight):
# 正態分布隨機初始化
module.weight.data.normal_(mean=0.0, std=config.initializer_range)
elif isinstance(module, nn.Linear):
if f(module.weight):
# 正態分布隨機初始化
module.weight.data.normal_(mean=0.0, std=config.initializer_range)
if f(module.bias):
# 初始為0
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
if f(module.weight):
# 初始為1
module.weight.data.fill_(1.0)
if f(module.bias):
# 初始為0
module.bias.data.zero_()
# BERT之主模型
class BertModel(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.config = config
# 嵌入層
self.emb = BertEmb(config)
# 編碼器
self.enc = BertEnc(config)
# 池化層
self.pool = BertPool(config)
# 引數初始化
self.init_weights()
# noinspection PyUnresolvedReferences
def get_input_embeddings(self):
return self.emb.tok_emb
def set_input_embeddings(self, embs):
self.emb.tok_emb = embs
def forward(self,
tok_ids, # 標記編碼(batch_size * seq_length)
pos_ids=None, # 位置編碼(batch_size * seq_length)
sent_pos_ids=None, # 句子位置編碼(batch_size * seq_length)
att_masks=None, # 注意力掩碼(batch_size * seq_length)
):
outputs = self.emb(tok_ids, pos_ids=pos_ids, sent_pos_ids=sent_pos_ids)
outputs = self.enc(outputs, att_masks=att_masks)
pooled_outputs = self.pool(outputs)
return (
outputs, # 輸出(batch_size * seq_length * hidden_size)
pooled_outputs, # 池化輸出(batch_size * hidden_size)
)
其中,
BertPreTrainedModel是預訓練模型抽象基類,用于完成一些初始化作業,
后記
本文詳細地介紹了BERT主模型的結構及其組件,了解它的構造以及代碼實作對于理解以及應用BERT有非常大的幫助,
后續兩篇文章會分別介紹BERT預訓練和下游任務相關,
從BERT主模型的結構中,我們可以發現,BERT拋棄了RNN架構,而只用注意力機制來抽取長距離依賴(這個其實是Transformer架構的特點),
由于注意力可以并行計算,而RNN必須串行計算,這就使得模型計算效率大大提升,于是BERT這類模型也能夠堆得很深,
BERT為了能夠同時做單句和雙句的序列和標記的預測任務,設計了[CLS]和[SEP]等特殊標記分別作為序串列示以及標記不同的句子邊界,整體采用了桶狀的模型結構,即輸入時隱狀態的形狀與輸出時隱狀態的形狀相等(只是在每個隱藏層有升維與降維操作,整體上詞嵌入長度保持不變),
由于注意力機制對距離不敏感,所以BERT額外添加了位置特征,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14718.html
標籤:其他
上一篇:沃爾瑪的產品知識圖譜