作者|Jacob Gursky
編譯|VK
來源|Towards Data Science

介紹
如果我告訴你訓練神經網路不需要計算梯度,只需要前項傳播你會怎么樣?這就是神經進化的魔力!同時,我要展示的是,所有這一切只用Numpy都可以很容易地做到!學習統計學你會學到很多關于基于梯度的方法,但是不久前我讀了Uber AI的人寫的一篇非常有趣的文章,他表明在解決Atari游戲時,簡單的遺傳演算法與最復雜的基于梯度的RL方法是挺有競爭力的,我鏈接了下面的來源,如果你對強化學習感興趣,我強烈建議你讀一讀,
什么是神經進化
首先,對于那些還不知道的人,神經進化描述了進化和遺傳演算法在訓練神經網路結構和權值方面的應用,它作為一種無梯度的替代方法!我們將在這里使用一個非常簡單的神經進化案例,只使用一個固定拓撲網路,只關注優化權重和偏差,神經進化程序可以定義為四個基本步驟,重復這些步驟直到達到收斂,首先是一個隨機生成的網路池,
- 評估種群的適應度
- 選擇最適合復制的個體
- 使用最適合網路的副本重新填充
- 在網路權值中引入正態分布突變
哇,這看起來很簡單!讓我們把一些術語分解一下:
-
適應度:這只是描述網路在特定任務中的表現,并允許我們確定要培育哪些網路,注意,因為進化演算法是非凸優化的一種形式,因此可以與任何損失函式一起使用,而不管其可微性(或缺乏可微性)如何
-
變異:這個可能是最簡單的!為了改進我們的子網路,我們必須對網路權值引入隨機變化,這些權值通常來自均勻或正態分布,有很多不同形式的突變:移位突變(將引數乘以亂數)、交換突變(將引數替換為亂數)、符號突變(更改引數的符號)等等,我們只會使用簡單的加性突變,但這里有很大的創新空間!
神經進化的優勢
我們還應該考慮神經進化模型的理論優勢,首先,我們只需要使用網路的前向傳遞,因為我們只需要計算損失,以確定要復制的網路,這意味著顯而易見,反向傳播通常是最昂貴的!其次,在給定足夠的迭代次數的情況下,進化演算法保證能找到損失曲面的全域最小值,而基于凸梯度的方法則陷入區域最小值,最后,更復雜的神經進化形式使我們不僅可以優化網路的權值,還可以優化結構本身!
那為什么不一直用神經進化呢?
這是一個復雜的問題,但它可以歸結為,當有足夠的梯度資訊時,精確的梯度下降法更有效,這意味著損失曲面越凸出,你就越想使用SGD之類的分析方法,而不是遺傳演算法,因此,在有監督的環境下使用遺傳演算法是非常罕見的,因為通常有足夠的梯度資訊可用,傳統的梯度下降方法將作業得很好,然而,如果你是在RL環境下作業,或者是在不規則的缺失面或低凸度的情況下(如連續的GAN),那么神經進化提供了一個可行的選擇!事實上,最近的許多研究發現,引數化神經進化模型在這些環境下可以做得更好,
實作
加載庫
正如介紹中所述,我們將嘗試在這個專案中只使用numpy,只定義我們需要的helper函式,
import numpy as np
import gym
關于資料
我們將使用來自gym的經典側手翻環境來測驗我們的網路,我們的目標是通過左右移動來觀察這個網路能讓桿子保持直立多久,作為一個RL任務,神經進化方法應該是一個很好的選擇!我們的網路將接收4個觀測結果作為輸入,并將左右輸出作為一個動作,
helper函式
首先,我們將定義幾個幫助函式來建立我們的網路,首先是relu激活函式,我們將使用它作為隱藏層的激活函式,使用softmax函式作為網路的輸出,以獲得網路輸出的概率估計!最后,我們需要定義一個函式,當我們需要計算分類交叉熵時,該函式生成回應向量的one-hot編碼,
def relu(x):
return np.where(x>0,x,0)
def softmax(x):
x = np.exp(x — np.max(x))
x[x==0] = 1e-15
return np.array(x / x.sum())
定義我們的網路
首先,我們將為總體中的各個網路定義一個類,我們需要定義一個初始化方法,它隨機分配權重和偏差,并以網路結構作為輸入,一個預測方法,這樣我們可以得到一個輸入的概率,最后一個評估方法,回傳給定輸入和回應的網路的分類交叉熵!同樣,我們只使用我們定義的函式或numpy中的函式,注意,初始化方法也可以將另一個網路作為輸入,這就是我們將如何在代之間執行突變!
# 讓我們定義一個新的神經網路類,可以與gym互動
class NeuralNet():
def __init__(self, n_units=None, copy_network=None, var=0.02, episodes=50, max_episode_length=200):
# 測驗我們是否需要復制一個網路
if copy_network is None:
# Saving attributes
self.n_units = n_units
# 初始化空串列以容納矩陣
weights = []
biases = []
# 填充串列
for i in range(len(n_units)-1):
weights.append(np.random.normal(loc=0,scale=1,size=(n_units[i],n_units[i+1])))
biases.append(np.zeros(n_units[i+1]))
# 創建引數字典
self.params = {'weights':weights,'biases':biases}
else:
self.n_units = copy_network.n_units
self.params = {'weights':np.copy(copy_network.params['weights']),
'biases':np.copy(copy_network.params['biases'])}
# 突變權重
self.params['weights'] = [x+np.random.normal(loc=0,scale=var,size=x.shape) for x in self.params['weights']]
self.params['biases'] = [x+np.random.normal(loc=0,scale=var,size=x.shape) for x in self.params['biases']]
def act(self, X):
# 獲取權重和偏置
weights = self.params['weights']
biases = self.params['biases']
# 第一個輸入
a = relu((X@weights[0])+biases[0])
# 在其他層傳播
for i in range(1,len(weights)):
a = relu((a@weights[i])+biases[i])
#獲取概率
probs = softmax(a)
return np.argmax(probs)
# 定義評估方法
def evaluate(self, episodes, max_episode_length, render_env, record):
# 為獎勵創建空串列
rewards = []
# 首先,我們需要建立我們的gym環境
env=gym.make('CartPole-v0')
# 如果需要的話,我們可以錄像
if record is True:
env = gym.wrappers.Monitor(env, "recording")
env._max_episode_steps=1e20
for i_episode in range(episodes):
observation = env.reset()
for t in range(max_episode_length):
if render_env is True:
env.render()
observation, _, done, _ = env.step(self.act(np.array(observation)))
if done:
rewards.append(t)
break
# 關倍訓境
env.close()
# 獲取最終獎勵
if len(rewards) == 0:
return 0
else:
return np.array(rewards).mean()
定義我們的遺傳演算法類
最后,我們需要定義一個類來管理我們的種群,以執行神經進化的四個關鍵步驟!我們需要三個方法,首先,創建一個隨機網路池并設定屬性的初始化方法,接下來,我們需要一個fit方法,給定一個輸入,重復執行上面列出的步驟:首先評估網路,然后選擇最合適的網路,創建子網路,最后修改子網路!最后,我們需要一個預測的方法,這樣我們就可以使用最好的網路訓練類,讓我們開始測驗吧!
# 定義處理網路種群的類
class GeneticNetworks():
#定義我們的初始化方法
def __init__(self, architecture=(4,16,2),population_size=50, generations=500,render_env=True, record=False,
mutation_variance=0.02,verbose=False,print_every=1,episodes=10,max_episode_length=200):
# 創建我們的網路串列
self.networks = [NeuralNet(architecture) for _ in range(population_size)]
self.population_size = population_size
self.generations = generations
self.mutation_variance = mutation_variance
self.verbose = verbose
self.print_every = print_every
self.fitness = []
self.episodes = episodes
self.max_episode_length = max_episode_length
self.render_env = render_env
self.record = record
# 定義我們的fiting方法
def fit(self):
# 遍歷所有代
for i in range(self.generations):
# 評估
rewards = np.array([x.evaluate(self.episodes, self.max_episode_length, self.render_env, self.record) for x in self.networks])
# 跟蹤每一代的最佳得分
self.fitness.append(np.max(rewards))
# 選擇最佳網路
best_network = np.argmax(rewards)
# 創建子網路
new_networks = [NeuralNet(copy_network=self.networks[best_network], var=self.mutation_variance, max_episode_length=self.max_episode_length) for _ in range(self.population_size-1)]
#設定新網路
self.networks = [self.networks[best_network]]+new_networks
# 如果必要輸出結果
if self.verbose is True and (i%self.print_every==0 or i==0):
print('Generation:',i+1,'| Highest Reward:',rewards.max().round(1),'| Average Reward:',rewards.mean().round(1))
# 回傳最佳網路
self.best_network = self.networks[best_network]
測驗演算法
如上所述,我們將在CartPole問題上測驗我們的網路,只使用一個包含16個節點的隱含層和兩個表示向左或向右移動的輸出節點,我們還需要多次迭代中平均,這樣我們就不會不小心為下一代選擇了一個糟糕的網路!我在經過一些嘗試和錯誤之后選擇了許多這樣的引數,所以你的情況可能會有所不同!此外,我們將只引入方差為0.05的突變,以免破壞網路的功能,
# 讓我們訓練一個網路種群
from time import time
start_time = time()
genetic_pop = GeneticNetworks(architecture=(4,16,2),
population_size=64,
generations=5,
episodes=15,
mutation_variance=0.1,
max_episode_length=10000,
render_env=False,
verbose=True)
genetic_pop.fit()
print('Finished in',round(time()-start_time,3),'seconds')
Generation: 1 | Highest Reward: 309.5 | Average Reward: 29.2
Generation: 2 | Highest Reward: 360.9 | Average Reward: 133.6
Generation: 3 | Highest Reward: 648.2 | Average Reward: 148.0
Generation: 4 | Highest Reward: 616.6 | Average Reward: 149.9
Generation: 5 | Highest Reward: 2060.1 | Average Reward: 368.3
Finished in 35.569 seconds
最初的隨機網路
首先,讓我們看看一個隨機初始化的網路是如何執行這個任務的,很明顯,這里沒有策略,桿子幾乎馬上就倒了,請忽略下面gif圖中的游標
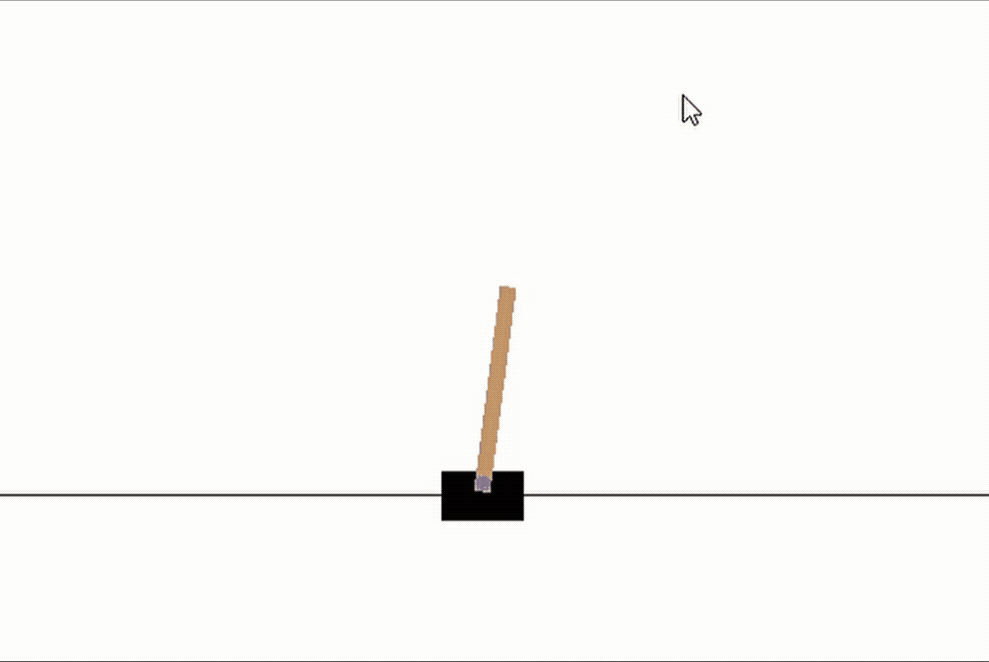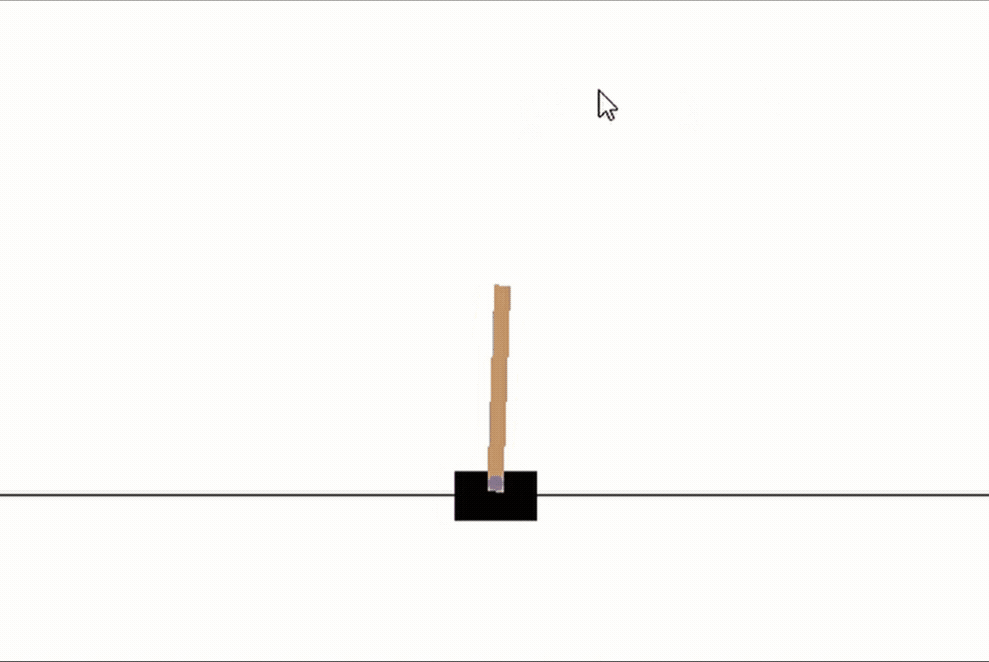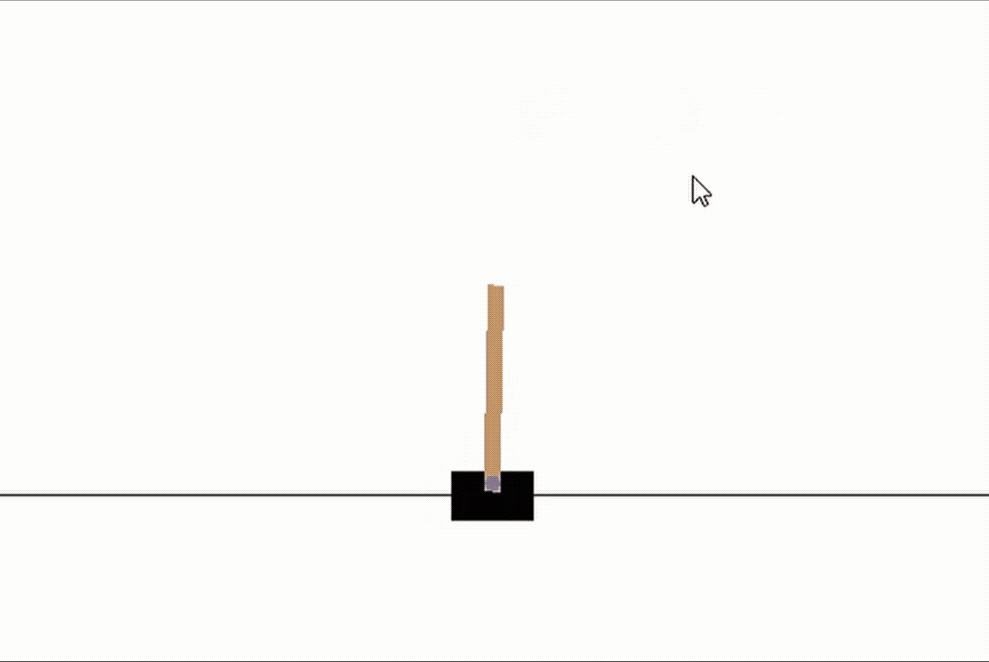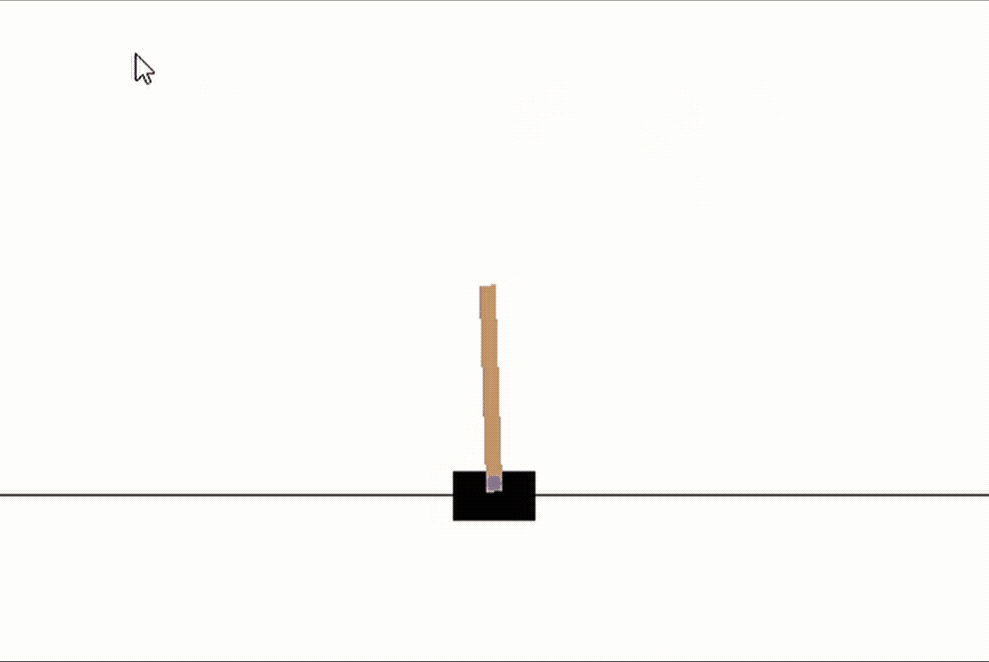
random_network = NeuralNet(n_units=(4,16,2))
random_network.evaluate(episodes=1, max_episode_length=int(1e10), render_env=True, record=False)
5代之后……
僅僅經過5代,我們可以看到我們的網路已經幾乎完全掌握了CartPole!而且只花了大約30秒的訓練時間!請注意,隨著進一步的訓練,網路學習保持它完全直立,幾乎所有的時間都是這樣,但目前我們只是感興趣的速度,5代是相當短的!我們應該把這看作是神經進化力量的一個很好的例子,
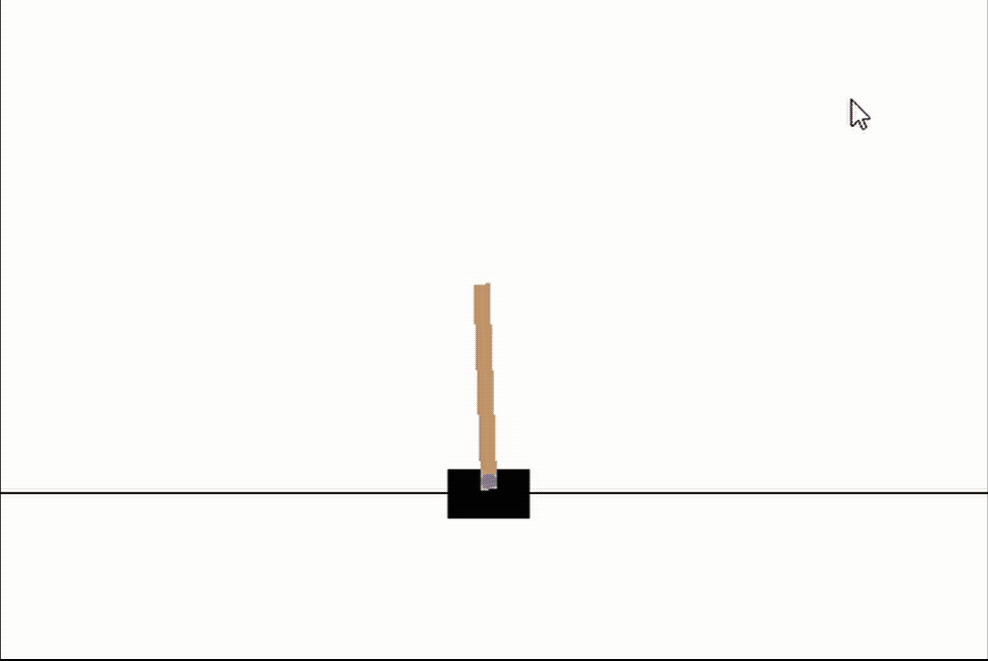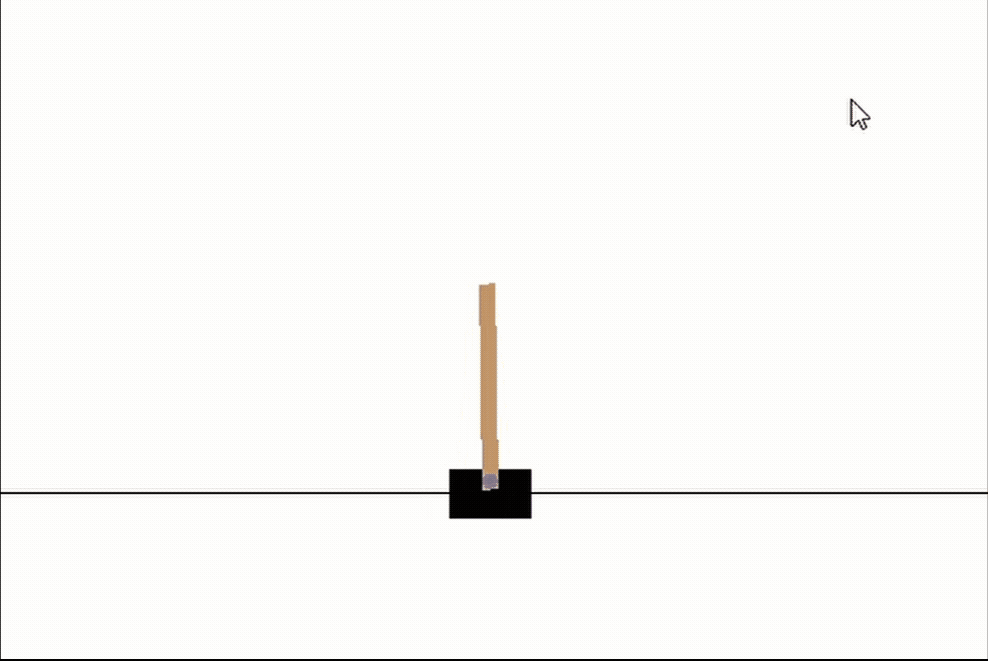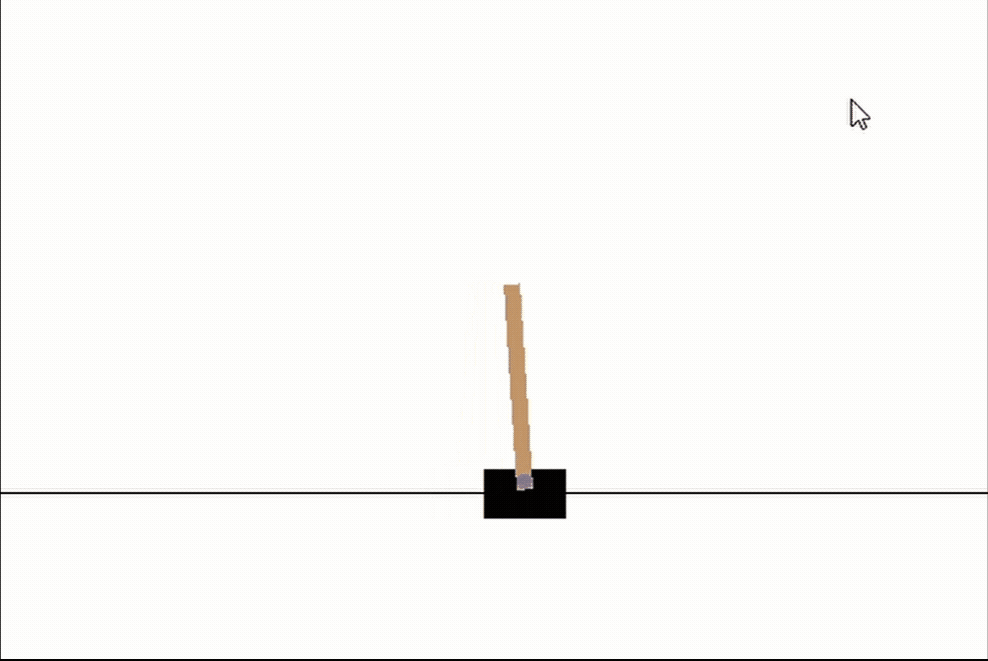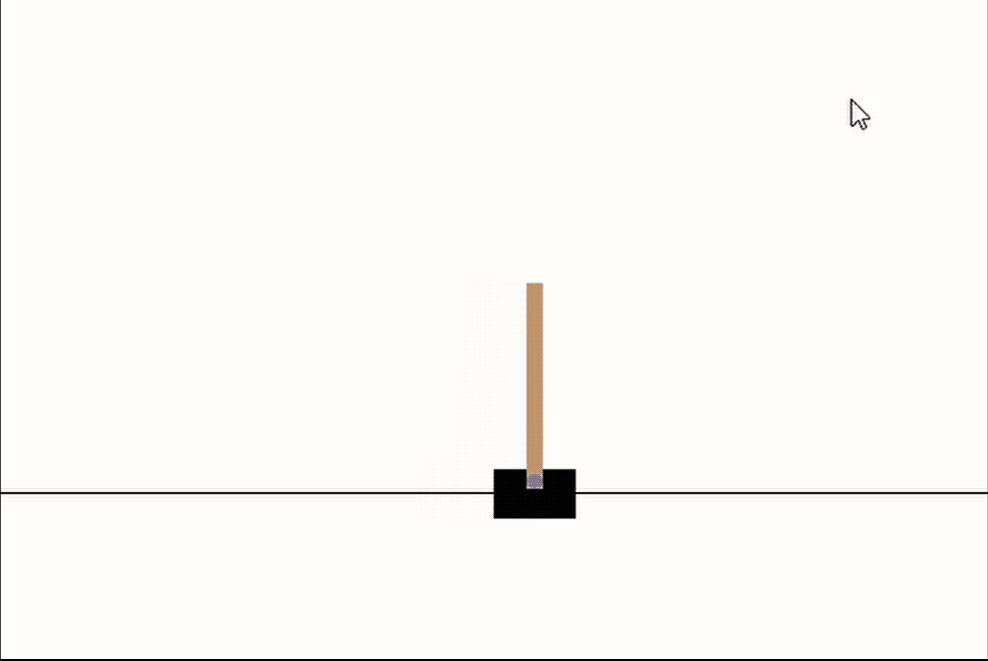
# 讓我們看看我們最好的網路
genetic_pop.best_network.evaluate(episodes=3, max_episode_length=int(1e10), render_env=True, record=False)
結尾
很明顯,我們可以在未來添加很多東西來進一步檢驗神經進化的有效性,首先,研究不同的突變操作如交叉操作的影響是很有趣的,
轉移到像TensorFlow或PyTorch這樣的現代深度學習平臺也是一個明智的想法,請注意,遺傳演算法是高度并行的,因為我們所要做的就是在一個前項傳播的設備上運行每個網路,不需要反映權重或復雜的分配策略!因此,每增加一個處理單元,我們的運行時間幾憾訓直線下降,
最后,我們應該在不同的強化學習任務中探索神經進化,甚至在梯度難以評估的其他情況下,例如在生成對抗網路或長序列LSTM網路中,
進一步的閱讀
如果你對神經進化及其應用感興趣,Uber在幾篇論文中有一個精彩的頁面,展示了神經進化在強化學習方面的現代優勢:
https://eng.uber.com/tag/deep-neuroevolution/
這個專案的源代碼可以在GitHub庫中找到:
https://github.com/gursky1/Numpy-Neuroevolution
原文鏈接:https://towardsdatascience.com/gradient-free-reinforcement-learning-neuroevolution-using-numpy-7377d6f6c3ea
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14720.html
標籤:其他