EM演算法是一種迭代演算法,用于含有隱變數的概率模型引數的極大似然估計,
使用EM演算法的原因
首先舉李航老師《統計學習方法》中的例子來說明為什么要用EM演算法估計含有隱變數的概率模型引數,
假設有三枚硬幣,分別記作A, B, C,這些硬幣正面出現的概率分別是$\pi,p,q$,進行如下擲硬幣試驗:先擲硬幣A,根據其結果選出硬幣B或C,正面選硬幣B,反面邊硬幣C;然后擲選出的硬幣,擲硬幣的結果出現正面記作1,反面記作0;獨立地重復$n$次試驗,觀測結果為$\{y_1,y_2,...,y_n\}$,問三硬幣出現正面的概率,
三硬幣模型(也就是第二枚硬幣正反面的概率)可以寫作
$ \begin{aligned} &P(y|\pi,p,q) \\ =&\sum\limits_z P(y,z|\pi,p,q)\\ =&\sum\limits_z P(y|z,\pi,p,q)P(z|\pi,p,q)\\ =&\pi p^y(1-p)^{1-y}+(1-\pi)q^y(1-q)^{1-y} \end{aligned} $
其中$z$表示硬幣A的結果,也就是前面說的隱變數,通常我們直接使用極大似然估計,即最大化似然函式
$ \begin{gather}\begin{aligned} &\max\limits_{\pi,p,q}\prod\limits_{i=1}^n P(y_i|\pi,p,q) \\ =&\max\limits_{\pi,p,q}\prod\limits_{i=1}^n[\pi p^{y_i}(1-p)^{1-y_i}+(1-\pi)q^{y_i}(1-q)^{1-y_i}]\\ =&\max\limits_{\pi,p,q}\sum\limits_{i=1}^n\log[\pi p^{y_i}(1-p)^{1-y_i}+(1-\pi)q^{y_i}(1-q)^{1-y_i}]\\ =&\max\limits_{\pi,p,q}L(\pi,p,q)\end{aligned} \label{}\end{gather} $
分別對$\pi,p,q$求偏導并等于0,求解方程組來估計這三個引數,但是,由于它是帶有隱變數的,在獲取最終的隨機變數之前有一個分支選擇的程序,導致這個$\log$的內部是加和的形式,計算導數十分困難,而待求解的方程組不是線性方程組,當復雜度一高,解這種方程組幾乎成為不可能的事,以下推導EM演算法,它以迭代的方式來求解這些引數,它包含了一種“貪心”的思想,
演算法匯出與理解
對于引數為$\theta$且含有隱變數$Z$的概率模型,進行$n$次抽樣,假設隨機變數$Y$的觀察值為$\mathcal{Y} = \{y_1,y_2,...,y_n\}$,隱變數$Z$的$m$個可能的取值為$\mathcal{Z}=\{z_1,z_2,...,z_m\}$,
寫出似然函式:
$ \begin{aligned} L(\theta) &= \sum\limits_{Y\in\mathcal{Y}}\log P(Y|\theta)\\ &=\sum\limits_{Y\in\mathcal{Y}}\log \sum\limits_{Z\in \mathcal{Z}} P(Y,Z|\theta)\\ \end{aligned} $
EM演算法首先初始化引數$\theta = \theta^0$,然后每一步迭代都會使似然函式增大,即$L(\theta^{k+1})\ge L(\theta^k)$,如何做到不斷變大呢?考慮第$k+1$步迭代似然函式(這一步很重要!):
$ \begin{gather} \begin{aligned} L(\theta)=&\sum\limits_{Y\in \mathcal{Y}} \log\sum\limits_{Z\in \mathcal{Z}} P(Y,Z|\theta)\\ =&\sum\limits_{Y\in \mathcal{Y}} \log\sum\limits_{Z\in \mathcal{Z}} P(Z|Y,\theta^k)\frac{P(Y,Z|\theta)}{P(Z|Y,\theta^k)}\\ \end{aligned} \label{} \end{gather} $
至于上式的第二個等式為什么取出$P(Z|Y,\theta^k)$而不是別的,正向的原因我想不出來,馬后炮原因在后面記錄,
考慮其中的求和
$ \sum\limits_{Z\in \mathcal{Z}} P(Z|Y,\theta^k)=1$
且由于$\log$函式是凹函式,因此由Jenson不等式得
$ \begin{gather} \begin{aligned} L(\theta) \ge&\sum\limits_{Y\in \mathcal{Y}}\sum\limits_{Z\in \mathcal{Z}} P(Z|Y,\theta^k)\log\frac{P(Y,Z|\theta)}{P(Z|Y,\theta^k)}\\ =&B(\theta,\theta^k) \end{aligned}\label{} \end{gather} $
當$\theta = \theta^k$時,有
$ \begin{gather} \begin{aligned} L(\theta^k) \ge& B(\theta^k,\theta^k)\\ =&\sum\limits_{Y\in \mathcal{Y}}\sum\limits_{Z\in \mathcal{Z}} P(Z|Y,\theta^k)\log\frac{P(Y,Z|\theta^k)}{P(Z|Y,\theta^k)}\\ =&\sum\limits_{Y\in \mathcal{Y}}\sum\limits_{Z\in \mathcal{Z}} P(Z|Y,\theta^k)\log P(Y|\theta^k)\\ =&\sum\limits_{Y\in \mathcal{Y}}\log P(Y|\theta^k)\\ =&L(\theta^k)\\ \end{aligned} \label{} \end{gather} $
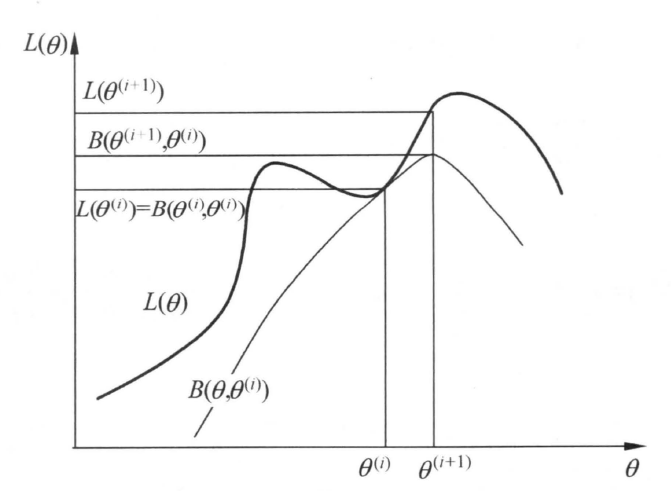
也就是在這時,$(2)$式取等,即$L(\theta^k) = B(\theta^k,\theta^k)$,另取
$ \begin{gather} \theta^*=\text{arg}\max\limits_{\theta}B(\theta,\theta^k)\label{} \end{gather} $
可得不等式
$L(\theta^*)\ge B(\theta^*,\theta^k)\ge B(\theta^k,\theta^k) = L(\theta^k)$
所以,我們只要優化$(4)$式,讓$\theta^{k+1} = \theta^*$,即可保證每次迭代的非遞減勢頭,有$L(\theta^{k+1})\ge L(\theta^k)$,而由于似然函式是概率乘積的對數,一定有$L(\theta) < 0$,所以迭代有上界并且會收斂,以下是《統計學習方法》中EM演算法一次迭代的示意圖:
進一步簡化$(4)$式,去掉優化無關項:
$ \begin{aligned} \theta^*=&\text{arg}\max\limits_{\theta}B(\theta,\theta^k) \\ =&\text{arg}\max\limits_{\theta}\sum\limits_{Y\in \mathcal{Y}}\sum\limits_{Z\in \mathcal{Z}} P(Z|Y,\theta^k)\log\frac{P(Y,Z|\theta)}{P(Z|Y,\theta^k)} \\ =&\text{arg}\max\limits_{\theta}\sum\limits_{Y\in \mathcal{Y}}\sum\limits_{Z\in \mathcal{Z}} P(Z|Y,\theta^k)\log P(Y,Z|\theta) \\ =&\text{arg}\max\limits_{\theta}Q(\theta,\theta^k) \\ \end{aligned} $
$Q$函式的對數內部沒有像$(1)$式一樣的和式,使用導數求極值的方程就與沒有隱變數的方程類似了,容易求解,另外,$Q$函式還可以寫成期望的形式(書上是不帶$Y$的求和的,我覺得加上更嚴謹一些,也容易理解一些):
$\displaystyle Q(\theta,\theta^k) = \sum\limits_{Y\in \mathcal{Y}}E_{Z\in \mathcal{Z}}[\log P(Y,Z|\theta)|Y,\theta^k]$
綜上,EM演算法的流程為:
1. 設定$\theta^0$的初值,EM演算法對初值是敏感的,不同初值迭代出來的結果可能不同,
2. 更新$\theta^k = \text{arg}\max\limits_{\theta}Q(\theta,\theta^{k-1})$,理解上來說,通常將這一步分為計算$Q$與極大化$Q$兩步,即求期望E與求極大M,但在代碼中并不會將它們分出來,因此這里濃縮為一步,另外,如果這個優化很難計算的話,因為有不等式的保證,可以直接取$\theta^k$為某個$\hat{\theta}$,只要有$Q(\hat{\theta},\theta^{k-1})\ge Q(\theta^{k-1},\theta^{k-1})$即可,
3. 比較$\theta^k$與$\theta^{k-1}$的差異,比如求它們的差的二范數,若小于一定閾值就結束迭代,否則重復步驟2,
下面記錄一下我對$(1)$式取出$P(Z|Y,\theta^k)$而不取別的$P$的理解:
經過以上的推導,我認為這是為了給不等式取等創造條件,如果不能確定$L(\theta^k)$與$Q(\theta^k,\theta^k)$能否取等,那么取$Q$的最大值$Q(\theta^*,\theta^k)$時,盡管有$Q(\theta^*,\theta^k)\ge Q(\theta^k,\theta^k)$,但并不能保證$L(\theta^*)\ge L(\theta^k)$,迭代的不減性質就就沒了,
我這里暫且把它看做一種巧合,是研究EM演算法的大佬,碰巧想用Jenson不等式來迭代而構造出來的一種做法,本人段位還太弱,無法正向理解其中的緣故,只能以這種方式來揣度大佬的思路了,知乎大佬發的EM演算法九層理解(點擊鏈接),我當前只能到第3層,有時間一定要拜讀一下深度學習之父的著作,
高斯混合模型的應用
迭代式推導
假設高斯混合模型混合了$m$個高斯分布,引數為$\theta = (\alpha_1,\theta_1,\alpha_2,\theta_2,...,\alpha_m,\theta_m),\theta_i=(\mu_i,\sigma_i)$則整個概率分布為:
$\displaystyle P(y|\theta) = \sum\limits_{i=1}^m\alpha_i \phi(y|\theta_i) = \sum\limits_{i=1}^m\frac{\alpha_i }{\sqrt{2\pi}\sigma_i}\exp\left(-\frac{(y-\mu_i)^2}{2\sigma_i^2}\right),\;\text{where}\;\sum\limits_{j=1}^m\alpha_j = 1$
對混合分布抽樣$n$次得到$\{y_1,...,y_n\}$,則在第$k+1$次迭代,待優化式為:
$\begin{gather}\begin{aligned} &\max\limits_{\theta}Q(\theta,\theta^k) \\ =&\max\limits_{\theta}\sum\limits_{Y\in \mathcal{Y}}\sum\limits_{Z\in \mathcal{Z}} P(Z|Y,\theta^k)\log P(Y,Z|\theta) \\ =&\max\limits_{\theta}\sum\limits_{Y\in \mathcal{Y}}\sum\limits_{Z\in \mathcal{Z}} \frac{P(Z,Y|\theta^k)}{P(Y|\theta^k)}\log P(Y,Z|\theta) \\ =&\max\limits_{\theta}\sum\limits_{i=1}^n\sum\limits_{j=1}^m \frac{\alpha_j^k\phi(y_i|\theta_j^k)} {\sum\limits_{l=1}^m \alpha_l^k\phi(y_i|\theta_l^k)} \log \left[\alpha_j\phi(y_i|\theta_j)\right] \\ =&\max\limits_{\theta}\sum\limits_{i=1}^n\sum\limits_{j=1}^m \frac{\alpha_j^k\phi(y_i|\theta_j^k)} {\sum\limits_{l=1}^m \alpha_l^k\phi(y_i|\theta_l^k)} \log \left[ \frac{\alpha_j}{\sqrt{2\pi}\sigma_j}\exp\left(-\frac{(y_i-\mu_j)^2}{2\sigma_j^2}\right) \right]\\ =&\max\limits_{\theta}\sum\limits_{j=1}^m \sum\limits_{i=1}^n \frac{\alpha_j^k\phi(y_i|\theta_j^k)} {\sum\limits_{l=1}^m \alpha_l^k\phi(y_i|\theta_l^k)} \left[ \log \alpha_j - \log \sigma_j-\frac{(y_i-\mu_j)^2}{2\sigma_j^2} \right]\\ \end{aligned} \label{}\end{gather}$
計算α
定義
$\displaystyle n_j = \sum\limits_{i=1}^n \frac{\alpha_j^k\phi(y_i|\theta_j^k)} {\sum\limits_{l=1}^m \alpha_l^k\phi(y_i|\theta_l^k)}$
則對于$\alpha$,優化式為
$\begin{gather} \begin{aligned} \max\limits_{\alpha}\sum\limits_{j=1}^m n_j \log \alpha_j \end{aligned} \label{}\end{gather}$
又因為$\sum\limits_{j=1}^m \alpha_j=1$,所以只需優化$m-1$個引數,上式變為:
$ \max\limits_\alpha \left[ \begin{matrix} n_1&n_2&\cdots &n_{m-1}&n_{m}\\ \end{matrix} \right] \cdot \left[ \begin{matrix} \log\alpha_1\\ \log\alpha_2\\ \vdots\\ \log\alpha_{m-1}\\ \log(1-\alpha_1-\cdots-\alpha_{m-1})\\ \end{matrix} \right] $
對每個$\alpha_j$求導并等于0,得到線性方程組:
$\left[\begin{matrix}n_1+n_m&n_1&n_1&\cdots&n_1\\n_2&n_2+n_m&n_2&\cdots&n_2\\n_3&n_3&n_3+n_m&\cdots&n_3\\&&&\vdots&\\n_{m-1}&n_{m-1}&n_{m-1}&\cdots&n_{m-1}+n_m\\\end{matrix}\right]\cdot\left[\begin{matrix}\alpha_1\\\alpha_2\\\alpha_3\\\vdots\\\alpha_{m-1}\\\end{matrix}\right]=\left[\begin{matrix}n_1\\n_2\\n_3\\\vdots\\n_{m-1}\\\end{matrix}\right]$
求解這個爪形線性方程組,得到
$\left[\begin{matrix}\sum_{j=1}^mn_j/n_1&0&0&\cdots&0\\-n_2/n_1&1&0&\cdots&0\\-n_3/n_1&0&1&\cdots&0\\&&&\vdots&\\-n_{m-1}/n_1&0&0&\cdots&1\\\end{matrix}\right]\cdot\left[\begin{matrix}\alpha_1\\\alpha_2\\\alpha_3\\\vdots\\\alpha_{m-1}\\\end{matrix}\right]=\left[\begin{matrix}1\\0\\0\\\vdots\\0\\\end{matrix}\right]$
因為
$\displaystyle \sum\limits_{j=1}^m n_j = \sum\limits_{j=1}^m\sum\limits_{i=1}^n \frac{\alpha_j^k\phi(y_i|\theta_j^k)} {\sum\limits_{l=1}^m \alpha_l^k\phi(y_i|\theta_l^k)}=\sum\limits_{i=1}^n \sum\limits_{j=1}^m \frac{\alpha_j^k\phi(y_i|\theta_j^k)} {\sum\limits_{l=1}^m \alpha_l^k\phi(y_i|\theta_l^k)} =\sum\limits_{i=1}^n 1 = n$
解得
$\displaystyle\alpha_j = \frac{n_j}{n} = \frac{1}{n}\sum\limits_{i=1}^n \frac{\alpha_j^k\phi(y_i|\theta_j^k)} {\sum\limits_{l=1}^m \alpha_l^k\phi(y_i|\theta_l^k)}$
計算σ與μ
與$\alpha$不同,它的方程組是所有$\alpha_j$之間聯立的;而$\sigma,\mu$的方程組則是$\sigma_j$與$\mu_j$之間聯立的,定義
$\displaystyle p_{ji} = \frac{\alpha_j^k\phi(y_i|\theta_j^k)} {\sum\limits_{l=1}^m \alpha_l^k\phi(y_i|\theta_l^k)}$
則對于$\sigma_j,\mu_j$,優化式為(比較$(6),(7)$式的區別)
$\begin{gather}\displaystyle\min\limits_{\sigma_j,\mu_j}\sum\limits_{i=1}^n p_{ji} \left(\log \sigma_j+\frac{(y_i-\mu_j)^2}{2\sigma_j^2} \right)\label{}\end{gather}$
對上式求導等于0,解得
$ \begin{aligned} &\mu_j = \frac{\sum\limits_{i=1}^np_{ji}y_i}{\sum\limits_{i=1}^np_{ji}} = \frac{\sum\limits_{i=1}^np_{ji}y_i}{n_j} = \frac{\sum\limits_{i=1}^np_{ji}y_i}{n\alpha_j}\\ &\sigma^2_j = \frac{\sum\limits_{i=1}^np_{ji}(y_i-\mu_j)^2}{\sum\limits_{i=1}^np_{ji}} = \frac{\sum\limits_{i=1}^np_{ji}(y_i-\mu_j)^2}{n_j} = \frac{\sum\limits_{i=1}^np_{ji}(y_i-\mu_j)^2}{n\alpha_j} \end{aligned} $
代碼實作
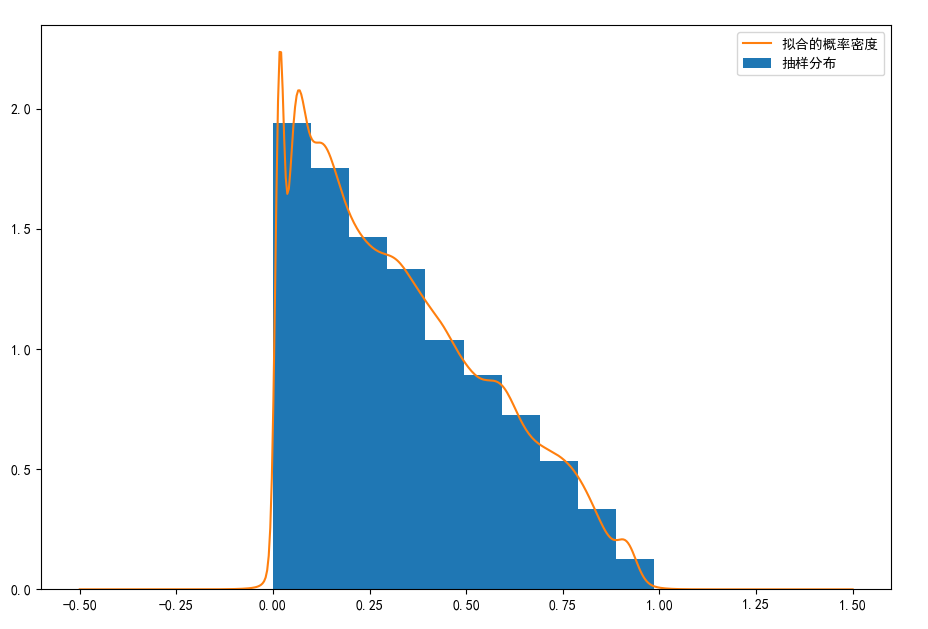
對于概率密度為$P(x) = ?2x+2,x\in (0,1)$的隨機變數,以下代碼實作GMM對這一概率密度的的擬合,共10000個抽樣,GMM混合了100個高斯分布,
#%%定義引數、函式、抽樣 import numpy as np import matplotlib.pyplot as plt dis_num = 100 #用于擬合的分布數量 sample_num = 10000 #用于擬合的分布數量 alphas = np.random.rand(dis_num) alphas /= np.sum(alphas) mus = np.random.rand(dis_num) sigmas = np.random.rand(dis_num)**2#方差,不是標準差 samples = 1-(1-np.random.rand(sample_num))**0.5 #樣本 C_pi = (2*np.pi)**0.5 dis_val = np.zeros([sample_num,dis_num]) #每個樣本在每個分布成員上都有值,形成一個sample_num*dis_num的矩陣 pij = np.zeros([sample_num,dis_num]) #pij矩陣 def calc_dis_val(sample,alpha,mu,sigma,c_pi): return alpha*np.exp(-(sample[:,np.newaxis]-mu)**2/(2*sigma))/(c_pi*sigma**0.5) def calc_pij(dis_v): return dis_v / dis_v.sum(axis = 1)[:,np.newaxis] #%%優化 for i in range(1000): print(i) dis_val = calc_dis_val(samples,alphas,mus,sigmas,C_pi) pij = calc_pij(dis_val) nj = pij.sum(axis = 0) alphas_before = alphas alphas = nj / sample_num mus = (pij*samples[:,np.newaxis]).sum(axis=0)/nj sigmas = (pij*(samples[:,np.newaxis] - mus)**2 ).sum(axis=0)/nj a = np.linalg.norm(alphas_before - alphas) print(a) if a< 0.001: break #%%繪圖 plt.rcParams['font.sans-serif']=['SimHei'] #用來正常顯示中文標簽 plt.rcParams['axes.unicode_minus']=False #用來正常顯示負號 def get_dis_val(x,alpha,sigma,mu,c_pi): y = np.zeros([len(x)]) for a,s,m in zip(alpha,sigma,mu): y += a*np.exp(-(x-m)**2/(2*s))/(c_pi*s**0.5) return y def paint(alpha,sigma,mu,c_pi,samples): x = np.linspace(-1,2,500) y = get_dis_val(x,alpha,sigma,mu,c_pi) fig = plt.figure() ax = fig.add_subplot(111) ax.hist(samples,density = True,label = '抽樣分布') ax.plot(x,y,label = "擬合的概率密度") ax.legend(loc = 'best') plt.show() paint(alphas,sigmas,mus,C_pi,samples)
以下是擬合結果圖,有點像是核函式估計,但是完全不同:
EM演算法的推廣
EM演算法的推廣是對EM演算法的另一種解釋,最終的結論是一樣的,它可以使我們對EM演算法的理解更加深入,它也解釋了我在$(1)$式下方提出的疑問:為什么取出$P(Z|Y,\theta^k)$而不是別的,
定義$F$函式,即所謂Free energy自由能(自由能具體是啥先不研究了):
$ \begin{aligned} F(\tilde{P},\theta) &= E_{\tilde{P}}(\log P(Y,Z|\theta)) + H(\tilde{P})\\ &= \sum\limits_{Z\in \mathcal{Z}} \tilde{P}(Z)\log P(Y,Z|\theta) - \sum\limits_{Z\in \mathcal{Z}} \tilde{P}(Z)\log \tilde{P}(Z)\\ \end{aligned} $
其中$\tilde{P}$是$Z$的某個概率分布(不一定是單獨的分布,可能是在某個條件下的分布),$E_{\tilde{P}}$表示分布$\tilde{P}$下的期望,$H$表示資訊熵,
我們計算一下,對于固定的$\theta$,什么樣的$\tilde{P}$會使$F(\tilde{P},\theta) $最大,也就是找到一個函式$\tilde{P}_{\theta}$,使$F$極大,寫成優化的形式就是(這里是找函式而不是找引數哦,理解上可能要用到泛函分析變分法的內容):
$ \begin{aligned} &\max\limits_{\tilde{P}} \sum\limits_{Z\in \mathcal{Z}} \tilde{P}(Z)\log P(Y,Z|\theta) - \sum\limits_{Z\in \mathcal{Z}} \tilde{P}(Z)\log \tilde{P}(Z)\\ &\;\text{s.t.}\; \sum\limits_{Z\in \mathcal{Z}}\tilde{P}(Z) = 1 \end{aligned} $
拉格朗日函式(拉格朗日對偶性,點擊鏈接)為:
$ \begin{aligned} L = \sum\limits_{Z\in \mathcal{Z}} \tilde{P}(Z)\log P(Y,Z|\theta) - \sum\limits_{Z\in \mathcal{Z}} \tilde{P}(Z)\log \tilde{P}(Z)+ \lambda\left(1-\sum\limits_{Z\in \mathcal{Z}}\tilde{P}(Z)\right) \end{aligned} $
因為每個$\tilde{P}(Z)$之間都是求和,沒有其它其它諸如乘積的操作,所以可以直接令$L$對某個$\tilde{P}(Z)$求導等于$0$來計算極值:
$ \begin{aligned} \frac{\partial L}{\partial \tilde{P}(Z)} = \log P(Y,Z|\theta) - \log \tilde{P}(Z) -1 -\lambda = 0 \end{aligned} $
于是可以推出:
$ \begin{aligned} P(Y,Z|\theta) = e^{1+\lambda}\tilde{P}(Z) \end{aligned} $
又由約束$\sum\limits_{Z\in \mathcal{Z}}\tilde{P}(Z) = 1$:
$P(Y|\theta) = e^{1+\lambda}$
于是得到
$\begin{gather}\tilde{P}_{\theta}(Z) = P(Z|Y,\theta)\label{}\end{gather}$
代回$F(\tilde{P},\theta)$,得到
$ \begin{aligned} F(\tilde{P}_\theta,\theta) &= \sum\limits_{Z\in \mathcal{Z}} P(Z|Y,\theta)\log P(Y,Z|\theta) - \sum\limits_{Z\in \mathcal{Z}} P(Z|Y,\theta)\log P(Z|Y,\theta)\\ &= \sum\limits_{Z\in \mathcal{Z}} P(Z|Y,\theta)\log \frac{P(Y,Z|\theta)}{P(Z|Y,\theta)}\\ &= \log P(Y|\theta)\\ \end{aligned} $
也就是說,對$F$關于$\tilde{P}$進行最大化后,$F$就是待求分布的對數似然;然后再關于$\theta$最大化,也就算得了最終要估計的引數$\hat{\theta}$,所以,EM演算法也可以解釋為$F$的極大-極大演算法,優化結果$(8)$式也解釋了我之前在$(1)$式下方的提問,
那么,怎么使用$F$函式進行估計呢?還是要用迭代來算,迭代方式是和前面介紹的一樣的(懶得記錄了,統計學習方法上直接看吧),實際上,$F$函式的方法只是提供了EM演算法的另一種解釋,具體方法上并沒有提升之處,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/14723.html
標籤:其他