論文地址:一種用于語音帶寬擴展的深度神經網路方法
論文作者:Kehuang Li;Chin-Hui Lee
代碼地址:github
博客作者:凌逆戰
博客地址:https://www.cnblogs.com/LXP-Never/p/10932353.html
摘要
本文提出了一種基于深度神經網路(DNN)的語音帶寬擴展(BWE)方法,利用對數譜功率作為輸入輸出特征進行所需的非線性變換,訓練神經網路來實作這種高維映射函式,在10小時的大型測驗集上對該方法進行評估時,我們發現與傳統的基于高斯混合模型(GMMs)的BWE相比,DNN擴展語音信號在信噪比和對數譜失真方面具有很好的客觀質量度量,在假定相位資訊已知的情況下,主觀聽力測驗對DNN擴展語音的偏愛度為69%,對GMM的偏愛度為31%,對于實際運行中的測驗,當相位資訊從給定的窄帶信號imaged(成像)時,首選項的比較上升到84%,而不是16%,正確的相位恢復可以進一步提高該方法的BWE性能,
關鍵詞:深度神經網路,語音帶寬擴展,頻譜映射,相位估計
1 引言
將語音帶寬從窄帶(4khz帶寬)擴展到寬帶(8khz帶寬)已經研究了幾十年,因為帶寬在早期是一種昂貴的資源,即使現在語音傳輸的帶寬不再受到緊張的限制,我們在現有的公共交換電話網(PSTN)系統中仍然面臨著低帶寬的限制,為了提高語音在PSTN上的收聽質量,人們一直在努力人為地擴展帶寬,
早期對帶寬擴展(BWE)的研究多集中于估計高頻帶的頻譜包絡線,利用低頻帶產生的激勵恢復高頻頻譜[1],早期作業探討了線性映射[2]、分段線性映射[3,4]、碼本映射[5,6]、神經網路[7,8]、高斯混合模型[9,10]、隱馬爾可夫模型[11,12]和非負隱馬爾可夫模型[13]等技術,線性預測系數(LPCs)或線譜頻率(LSFs)[14,15]被廣泛用于表示頻譜包絡,而激勵可以通過LPCs對信號進行反濾波、調制技術、非線性處理以及函式生成器[1]的應用來發現,
與包絡估計方法相比,由于建立原始低頻頻譜和目標高頻頻譜映射函式的的維度都很高,因此對缺失高頻頻譜的直接估計沒有得到廣泛的研究,然而,目前仍有一些研究,如折疊頻譜調整[8]和稀疏概率狀態映射[16],前者對窄帶頻譜進行折疊,調整寬帶頻譜的水平,嘗試以不同的方式估計頻譜包絡線,后者假設映射的傳輸矩陣是稀疏的,這通常是不準確的,然而,這些技術表明,直接估計缺失帶的頻譜具有一定的優勢,值得進一步研究,
綜上所述,我們建議使用DNN進行頻譜映射來估計缺失的高頻頻譜,在10小時的大型測驗集上進行的實驗表明,與傳統的基于GMM的映射技術相比,提出的DNN框架在分段信噪比[17]和對數譜失真[18]方面具有更好的客觀測量效果,當相位資訊是已知的,主觀偏好聽力測驗也給出69%的分數,而GMM的偏好評分是31%,對于實際運行測驗,當相位資訊從給定的窄帶信號成像時,首選項的比較上升到84%,GMM是16%,正確的相位恢復可以進一步提高所提出的DNN方法的BWE性能,
2 基于DNN的語音頻帶擴展
2.1 特征提取
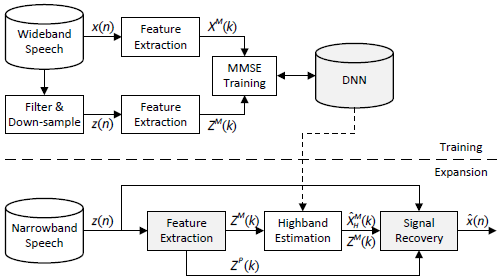
圖1 提出的DNN-BWE系統框圖
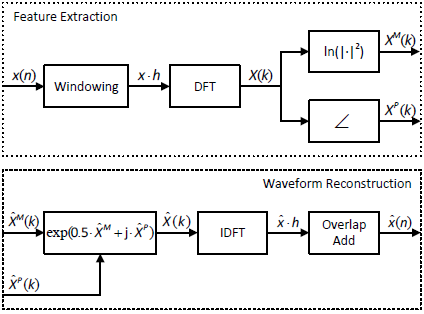
圖2 特征提取和波形重建的流程圖
圖1給出了基于DNN的BWE系統的框圖,給定一個寬帶語音信號x,我們將其加視窗得到重疊幀,并在加窗后的語音幀上執行短時傅里葉變換(STFT) [19],
$$公式1:X(l,k)=\sum_{n=0}^{N-1}x(l*\Delta +n)h(n)e^{\frac{-j2\pi nk}{N}}$$
其中$l$為幀索引,$k=0,...,L-1$為離散頻率索引,$\Delta$為窗移,N為窗長,$h(·)$為窗函式,這里為漢明窗,我們將在文章的其余部分省略$l$,因為我們將重點放在每幀語音的特征上,提取對數譜功率值[20]
$$公式2:X^M(k)=In|X(k)|^2$$
因為$x$是一個真實信號,$X$是共軛對稱的,僅由$\frac{N}{2}+1$點決定,因此,我們使用$k=0,...,\frac{N}{2}$的$X^M(k)$作為特征,對于寬帶信號,進一步將$X^M$分為低頻譜$X_L^M=[X^M(0),...,X^M(\frac{N}{4})]$,高頻譜$X_H^M=[X^M(\frac{N}{4}+1),...,X^M(\frac{N}{2})]$,其中$X_H^M$由DNN根據窄帶(低頻)譜恢復,
除傅里葉系數的大小外,相位資訊提取如下
$$公式3:X^P(k)=\angle X(k)$$
對于寬帶信號,將$X^P$按其對應的$X^M$大小分別分解為$X_L^P$和$X_H^P$,
對寬帶信號$x$進行濾波和降采樣,得到窄帶信號對應的對數譜幅值和相位$z$,$Z^M$和$Z^P$,
2.2 DNN訓練
如圖3所示,DNN的輸入為窄帶信號的對數譜,輸出為寬帶信號的高頻對數譜,為了保證神經網路的正常作業,對所有訓練樣本的神經網路輸入輸出的各個維度進行歸一化處理,保證其均值為零,方差為1,因此,在帶寬擴展的應用階段,需要對輸入特征向量執行相同的歸一化操作,對輸出執行相反的操作,
我們使用Kaldi工具包[21]來訓練DNNs,首先對受限玻爾茲曼機(RBM)進行無監督預訓練,然后,在判別微調中,采用最小均方誤差準則(MMSE),試圖使預測的高頻對數譜與期望寬帶信號的真實高頻對數譜之間的歐氏距離最小化,設Y為DNN的輸出,MMSE的目標函式為
$$公式4:min\frac{1}{2}||(X_H^M-\mu_H)\sum_H^{-1}-Y||_2^2$$
其中$\mu_H$和$\sum_H^{-1}$為訓練資料所有高頻對數譜的均值向量和對角逆協方差矩陣,
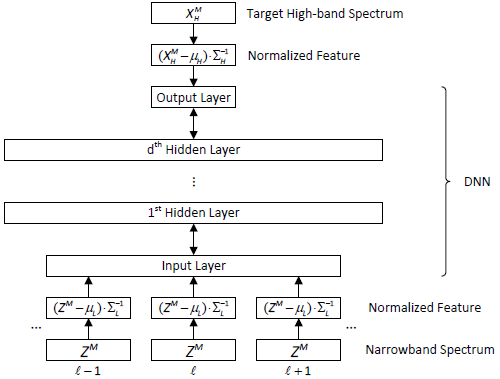
圖3 DNN架構和訓練
2.3 波形重建
即使可以精確的獲得寬帶頻譜的大小,在前面的步驟中也會丟失相位資訊,DNN模型輸出的是高頻頻譜估計$\hat{X}_H^M=(Y+\mu_H)\sum_H$,因此我們可以計算出擴展的寬帶頻譜估計:$\hat{X}^M=[Z^M+2In2,\hat{X}_H^M]$,其中$2In2$補償了由于僅使用寬帶信號的一半點來計算窄帶頻譜而引起的能量損失,為了防止的質量下降,窄帶譜不做修改[7],對于相位,我們對低頻相位$\hat{X}_L^P=Z^P$進行了估計,高頻相位未知,Imaged(成像)相位是一個簡單的估計$\hat{X}^P=[Z^P,-flip(Z^P)]$,其中$flip(Z^P)$,或簡稱為$Z_F^P$,定義為$k-0,1...,\frac{N}{4}-1$時$Z_F^P(k)=Z^P(\frac{N}{4}-1-k)$,然后進行了離散傅里葉反變換(IDFT)
$$公式5:\hat{X}(k)=exp\{\frac{1}{2}\hat{X}^M(k)+j\hat{X}^P(k)\}$$
反轉步驟(2)和(3),用[23]中給出的重疊加法和相同的漢明窗進行特征提取重建信號$\hat{x}$,
3 實驗與結果
3.1 實驗步驟
我們在華爾街日報(WSJ0)語料庫[24]上進行了實驗,在16位解析度下以16KHz采樣率采樣的麥克風語音,與其他技術進行直接比較并不容易,相反,我們在WSJ0上進行了大規模的測驗,訓練集中有31166潭訓語(訓練約50小時,驗證約10小時),測驗4137潭訓語(約10小時),STFT的視窗大小為512個樣本,在寬帶信號上的偏移長度為256個樣本,而窄帶信號的視窗大小為256,偏移量為128,將MMSE訓練的基本學習率設定為$10^{-5}$,采用"newbob"方法[25],當均方誤差減小到小于0.1時學習率減半,當均方誤差減小到小于0.01停止,采用小批量訓練[26],批量大小為32個話語,作為比較,我們建立了2045種混合的全協方差GMM模型,并利用該模型進行了與DNN相同的回歸分析,
3.3.1 客觀質量度量
本實驗采用的客觀質量指標為分段信噪比[17](segmental SNR, SegSNR)和對數頻譜失真(log-spectrum distortion,LSD)[18],定義如下
$$公式6:SegSNR=\frac{1}{L}\sum_{l=0}^{L-1}\{10lg\frac{\sum_{n=0}^{N-1}[x(l,n)]^2}{\sum_{n=0}^{N-1}[x(l,n)-\hat{x}(l,n)]^2}\}$$
其中$l$表示第$l$幀,L表示語音中的幀數,
$$公式7:LSD=\frac{1}{L}\sum_{l=0}^{L-1}\{{\frac{1}{\frac{N}{2}+1}}\sum_{k=0}^{\frac{N}{2}}[X^M(l,k)-\hat{X}^M(l,k)]^2\}^{\frac{1}{2}}$$
為了測量高頻段頻譜估計的性能,我們還引入了$LSD_H$,我們還引入了僅用離散頻率指數求和高半帶失真的$LSD_H$,$k=|frac{N}{4}+1,...,\frac{N}{2}$,
3.1.2 主觀測驗
除上述客觀測量外,還進行了主觀聽力測驗,10名志愿者被要求隨機聽10對測驗話語,他們的偏好被記錄下來并總結出來,以表明總體偏好,
3.2 結果與討論
3.2.1 DNN結構
神經網路的大小和形狀會影響神經網路的性能,為了簡單起見,我們將重點放在DNN中具有相同寬度的隱藏層上,我們采用了[27]中的結構設定,如圖4所示,在我們對WSJ0資料集的實驗中,具有9幀、3個隱層和每層2048個隱層節點的DNN是一個區域最優的引數設定,這里9幀表示將4個前幀和4個后幀與當前幀 連接到DNNs的輸入層,結果表明,該性能對小引數差異不敏感,
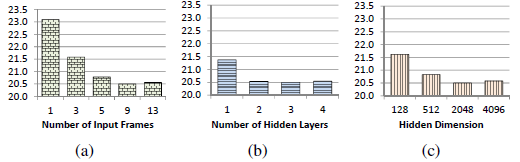
圖4 不同DNNs的MSE,默認引數為9幀、3層和每層2048個隱藏節點,每次比較只有一個引數是變化的
3.2.2 客觀表現
表1列出了不同方法和相位重構信號的分段信噪比和LSD結果,每個方法的第一行是CP,表示我們使用了“cheated phase(欺騙相位)”,即,我們使用的是在輸入窄帶信號時不可用的原寬帶信號的高半帶相位,每一種方法的第二行是IP,表示使用了“Imaged phase”,即,我們將輸入窄帶信號的相位翻轉到上半帶,并給它們加上一個負號,與傳統的想法相反,如果使用不正確的相位進行重構,重構信號的分段信噪比會大大降低(GMM從15.42 dB降至12.12 dB, DNN從16.47 dB降至12.78 dB),被欺騙相位的LSD始終比Image phase的LSD好1 dB以上,對于高頻段的LSD,在約$1.3dB~2dB$左右的衰減情況下,始終比整個頻段的LSD更為嚴重,此外,DNN在CP和IP案例以及所有三項指標上都優于GMM,
表1 對重構信號的客觀度量
| SegSNR(dB) | LSD(dB) | $LSD_H$(dB) | ||
| GMM | CP | 15.42 | 6.34 | 8.28 |
| IP | 12.12 | 7.29 | 9.72 | |
| DNN | CP | 16.47 | 5.32 | 6.69 |
| IP | 12.78 | 6.44 | 8.44 |
圖5給出了一個女性和一個男性測驗話語的例子,直接預測高頻頻譜的一個問題是低頻頻譜與高頻頻譜之間存在不連續,
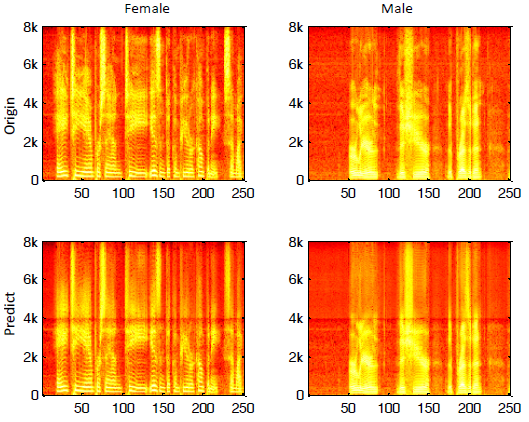
圖5:,一個女性測驗話語和一個男性測驗話語的語譜圖,頂行:原始,底行:重構信號,左列:女性,右列:男性,
3.2.3 主觀表現
當與窄帶信號競爭時,GMM和DNN都有100%的優勢,表2顯示了GMM和DNN之間的競爭結果,在相位資訊已知的情況下,他們對GMM擴展語音給出了69%的評分,高于31%,對于實際操作測驗,當從給定窄帶信號成像相位資訊時,首選項的比較上升到84%,而不是16%,良好的相位估計資訊可以進一步提高所提出的DNN方法的BWE性能,
表2 重構信號的測驗表現
| CP | IP | |
| GMM | 31% | 16% |
| DNN | 69% | 84% |
3.2.4 計算復雜度比較
我們的實驗使用一臺32 2.93 GHz CPU核和一張GTX480顯卡的作業站,表3為DNN和GMM在訓練和擴展階段的計算時間,測驗資料本身的大小約為600分鐘,即擴展階段可以實時進行,然而,DNNs的延遲時間取決于引數設定,使用上述實驗設定,lag time(滯后時間)為96 ms((4幀移位* 128點/移位+ 1當前幀* 256點/幀)/ 8 kHz),
表3 訓練和測驗的時間消耗
| Train | Test | |
| DNN | 1501 min | 93 min |
| GMM | 358 min | 367 min |
4. 結論及未來作業
提出了一種基于深度神經網路的語音帶寬擴展框架,利用深度學習能力,DNN能夠將輸入窄帶信號的幅度譜映射到寬帶信號的高頻段,實驗結果表明,與基于GMM的BWE方法相比,本文提出的DNN框架能夠有效地估計高頻頻譜,獲得更高的分段信噪比和更低的對數譜失真,主觀測驗也證實了我們提出的框架比其他基于GMM的系統表現出更高的聽力偏好,對于進一步的作業,我們打算處理圖5中提到的頻譜不連續問題,此外,通過正確的相位恢復,我們觀察到系統性能可以進一步提高,這將在另一篇即將發表的論文中進行研究,
5 參考文獻
[1] B. Iser and G. Schmidt, “Bandwidth extension of telephony speech,” in Speech and Audio Processing in Adverse Environments,pp. 135–184. Springer, 2008.
[2] Y. Nakatoh, M. Tsushima, and T. Norimatsu, “Generation of broadband speech from narrowband speech based on linear mapping,” Electronics and Communications in Japan (Part II:Electronics), vol. 85, no. 8, pp. 44–53, 2002.
[3] Y. Nakatoh, M. Tsushima, and T. Norimatsu, “Generation of broadband speech from narrowband speech using piecewise linear mapping,” in Proc. EUROSPEECH, 1997, pp. 1643–1646.
[4] J. Epps and W. H. Holmes, “A new technique for wideband enhancement of coded narrowband speech,” in Proc. IEEE Workshop on Speech Coding, 1999, pp. 174–176.
[5] U. Kornagel, “Spectral widening of telephone speech using an extended classification approach,” in Proc. EUSIPCO, 2002,vol. 2, pp. 339–342.
[6] S. Vaseghi, E. Zavarehei, and Q. Yan, “Speech bandwidth extension: extrapolations of spectral envelop and harmonicity quality of excitation,” in Proc. ICASSP, 2006, vol. 3.
[7] B. Iser and G. Schmidt, “Neural networks versus codebooks in an application for bandwidth extension of speech signals,” in Proc. INTERSPEECH, 2003, pp. 565–568.
[8] J. Kontio, L. Laaksonen, and P. Alku, “Neural network-based artificial bandwidth expansion of speech,” IEEE Trans. on Audio,Speech, and Lang. Process., vol. 15, no. 3, pp. 873–881,2007.
[9] K.-Y. Park and H. S. Kim, “Narrowband to wideband conversion of speech using GMM based transformation,” in Proc.ICASSP, 2000, vol. 3, pp. 1843–1846.
[10] H. Seo, H.-G. Kang, and F. Soong, “A maximum a posteriorbased reconstruction approach to speech bandwidth expansion in noise,” in Proc. ICASSP, 2014, pp. 6087–6091.
[11] P. Jax and P. Vary, “Artificial bandwidth extension of speech signals using MMSE estimation based on a hidden Markov model,” in Proc. ICASSP, 2003, vol. 1, pp. I–680.
[12] G.-B. Song and P. Martynovich, “A study of HMM-based bandwidth extension of speech signals” Signal Processing,vol. 89, no. 10, pp. 2036–2044, 2009.
[13] J. Han, G. J. Mysore, and B. Pardo, “Language informed bandwidth expansion,” in Proc. IEEE Workshop on Machine Learning for Signal Processing, 2012, pp. 1–6.
[14] W. P. LeBlanc, B. Bhattacharya, S. A. Mahmoud, and V. Cuperman,“Efficient search and design procedures for robust multi-stage VQ of LPC parameters for 4 kb/s speech coding,”IEEE Trans. Speech Audio Process., vol. 1, no. 4, pp. 373–385,1993.
[15] F. K. Soong and B.-H. Juang, “Optimal quantization of LSP parameters,” IEEE Trans. Speech Audio Process., vol. 1, no. 1,pp. 15–24, 1993.
[16] K. Kalgaonkar and M. A. Clements, “Sparse probabilistic state mapping and its application to speech bandwidth expansion,”in Proc. ICASSP, 2009, pp. 4005–4008.
[17] S. R. Quackenbush, T. P. Barnwell, and M. A. Clements, Objective measures of speech quality, Prentice Hall Englewood Cliffs, NJ, 1988.
[18] I. Cohen and S. Gannot, “Spectral enhancement methods,”in Springer Handbook of Speech Processing, pp. 873–902.Springer, 2008.
[19] J. B. Allen and L. Rabiner, “A unified approach to short-time Fourier analysis and synthesis,” Proc. of the IEEE, vol. 65, no.11, pp. 1558–1564, 1977.
[20] J. Du and Q. Huo, “A speech enhancement approach using piecewise linear approximation of an explicit model of environmental distortions.,” in Proc. INTERSPEECH, 2008, pp.569–572.
[21] D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek,N. Goel, M. Hannemann, P. Motlicek, Y. Qian, P. Schwarz,et al., “The Kaldi speech recognition toolkit,” in Proc. ASRU,2011, pp. 1–4.
[22] D. H. Ackley, G. E. Hinton, and T. J. Sejnowski, “A learning algorithm for Boltzmann machines,” Cognitive Science, vol. 9,no. 1, pp. 147–169, 1985.
[23] D. Griffin and J. S. Lim, “Signal estimation from modified short-time Fourier transform,” IEEE Trans. Acoust., Speech,Signal Process., vol. 32, no. 2, pp. 236–243, 1984.
[24] D. B. Paul and J. M. Baker, “The design for the Wall Street Journal-based CSR corpus,” in HLT ’91 Proceedings of the workshop on Speech and Natural Language, 1992, pp. 357–362.
[25] ICSI QuickNet toolbox. Newbob approach is implemented in the toolbox. [Online]. Available:http://www1.icsi.berkeley.edu/Speech/qn.html
[26] G. E. Hinton, “A practical guide to training restricted Boltzmann machines,” Tech. rep. utml tr 2010–003, Dept. Comput.Sci., Univ. Toronto, 2010.
[27] Y. Xu, J. Du, L. Dai, and C.-H. Lee, “An experimental study on speech enhancement based on deep neural networks,” IEEE Signal Process. Lett., pp. 65–68, 2014.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/151111.html
標籤:其他
上一篇:Cooperation、Collaboration與Coordination的區別
下一篇:論文翻譯:2018_speaker recognition from raw waveform with SincNet