論文題目:基于SincNet的原始波形說話人識別
代碼地址:https://github.com/mravanelli/SincNet/
論文作者:Mirco Ravanelli, Yoshua Bengio
博客作者:凌逆戰
博客地址:https://www.cnblogs.com/LXP-Never/p/11729668.html
作為一種可行的替代i-vector的說話人識別方法,深度學習正日益受到歡迎,利用卷積神經網路(CNNs)直接對原始語音樣本進行處理,取得了良好的效果,而不是使用標準的手工制作的功能,后一種CNNs從波形中學習低電平的語音表示,潛在地允許網路更好地捕獲重要的窄帶揚聲器特性,如音高和共振峰,合理設計神經網路是實作這一目標的關鍵,
本文提出了一種新的CNN架構,稱為SincNet,它鼓勵第一個卷積層發現更有意義的過濾器,SincNet是基于引數化的sinc函式,實作帶通濾波器,與標準CNNs不同的是,該方法學習每個濾波器的所有元素,只直接從資料中學習低截止頻率和高截止頻率,這提供了一種非常緊湊和有效的方法來派生專門針對所需應用程式進行調優的自定義篩選器組,
我們在說話人識別和驗證任務上進行的實驗表明,該結構比標準的CNN在原始波形上收斂更快,性能更好,
介紹
說話人識別是一個非常活躍的研究領域,在生物認證、取證、安全、語音識別、說話人二值化等各個領域都有顯著的應用,這使得人們對這門學科[1]產生了濃厚的興趣,目前最先進的解決方案都是基于語音段[2]的i-vector表示,這對之前的高斯混合模型-通用背景模型(GMMUBMs)[3]有顯著的改進,深度學習已經在許多語音任務中顯示出顯著的成功[4 8],包括最近在說話人識別方面的研究[9,10],深度神經網路(DNNs)已在i-vector框架內用于計算Baum-Welch統計[11],或用于幀級特征提取[12],DNNs也被提議用于直接區別主格說話人的分類,最近關于這一主題的文獻[13 16]就證明了這一點,然而,過去的大多數嘗試使用手工制作的特性,如FBANK和MFCC系數[13,17,18],這些經過設計的特性最初是根據感知的證據設計的,并且不能保證這些表示對于所有與語音相關的任務都是最優的,例如,標準特征使語音頻譜平滑,這可能會妨礙提取關鍵的窄帶揚聲器特征,如音高和共振峰,為了緩解這一缺陷,最近的一些作業提出直接用光譜圖箱[19 21]或甚至用原始波形[22 34]來饋電網路,CNNs是處理原始語音樣本的最流行的架構,因為權重共享、local filters和pooling有助于發現健壯和不變的表示,
我們認為當前基于波形的CNNs最關鍵的部分之一是第一卷積層,這一層不僅處理高維輸入,而且更容易受到消失的梯度問題的影響,特別是在使用非常深的架構時,美國有線電視新聞網(CNN)學習的濾波器通常采用嘈雜且不協調的多頻帶形狀,特別是在可用的訓練樣本很少的情況下,這些濾波器對神經網路當然有一定的意義,但對人類的直覺沒有吸引力,似乎也不能有效地表示語音信號,
為了幫助CNNs在輸入層中發現更有意義的濾波器,本文提出在濾波器形狀上增加一些約束,與標準CNNs相比,SincNet將波形與實作帶通濾波器的一組引數化sinc函式進行卷積,而標準CNNs的濾波器組特征依賴于幾個引數(濾波器向量的每個元素都是直接學習的),低截止頻率和高截止頻率是濾波器從資料中得到的唯一引數,這個解決方案仍然提供了相當大的靈活性,但是迫使網路將重點放在對最終濾波器的形狀和帶寬有廣泛影響的高級可調引數上,
我們的實驗是在具有挑戰性和現實性的條件下進行的,和簡短的測驗句(持續2- 6秒),在各種資料集上取得的結果表明,本文提出的SincNet演算法比更標準的CNN演算法收斂速度更快,具有更好的末端任務性能,在考慮的實驗設定下,我們的體系結構也優于一個更傳統的基于i-vector的說話人識別系統,
論文的其余部分組織如下,SincNet體系結構在第2節中進行了描述,第3節討論了與先前作業的關系,實驗設定和結果分別在第4節和第5節中概述,最后,第6節討論了我們的結論,
2 SincNet結構
標準CNN的第一層在輸入波形和一些有限脈沖回應(FIR)濾波器[35]之間執行一組時域卷積,每個卷積定義如下(大多數深度學習工具包實際上計算的是相關性而不是卷積,得到的翻轉(鏡像)過濾器不會影響結果)
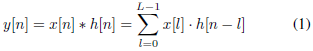
其中x[n]是語音信號的塊,h[n]是長度l的濾波器,y[n]是濾波輸出,在標準cnns中,每個濾波器的所有l元素(taps)都是從資料中學習的,相反,所提出的sincnet(如圖1所示)使用預定義的函式g執行卷積,該函式g僅依賴于幾個可學習的引數g,如下式中所示:
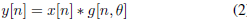
受數字信號處理中標準濾波的啟發,一個合理的選擇是定義一個由矩形帶通濾波器組成的濾波器組g,在頻域中,一般帶通濾波器的幅值可以寫成兩個低通濾波器的差值
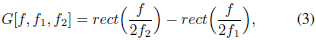
其中f1和f2是學習的低和高截止頻率,rect(·)是幅度頻率域中的矩形函式(rect(·)函式的相位被認為是線性的),在回傳到時域(使用逆傅里葉變換[35])之后,參考函式g變為:
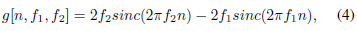
其中sinc函式定義為sinc(x) = sinx =x,
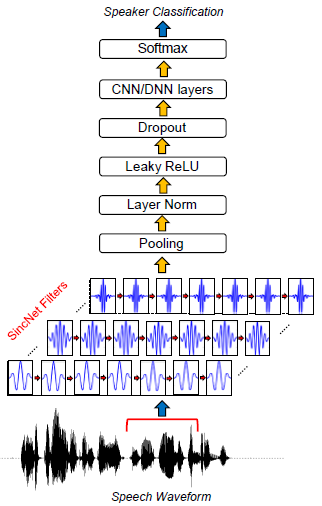
圖1 SincNet的結構框圖
關于說話人的身份被定位,為了確保$f1\geq 0$和$f2\geq f1$,前面的方程實際上由以下引數提供
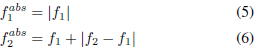
請注意,我們并沒有強制f2小于奈奎斯特頻率,因為我們觀察到這個約束在訓練期間自然地得到了滿足,此外,每個濾波器的增益不是在這個層次上學習的,此引數由后續層管理,它們可以輕松地為每個過濾器輸出賦予或多或少的重要性,
一個理想的帶通濾波器,,當通帶完全平坦且阻帶衰減無限大時,需要無限個元素l,g的任何截斷都不可避免地導致理想濾波器的近似,其特征是通帶波紋,阻帶衰減有限,緩解這個問題的一個流行的解決方案是[35]視窗,視窗化是通過將截斷的函式g與視窗函式w相乘來實作的,其目的是消除g末端的突變不連續
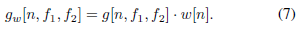
本文采用流行的漢明視窗[36],定義如下:
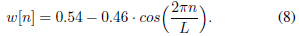
漢明窗特別適合實作高頻率選擇性[36],但是,這里沒有報告的結果顯示,在采用其他功能(如Hann、Blackman和Kaiser windows)時,沒有顯著的性能差異,還請注意,濾波器g是對稱的,因此不會引入任何相位畸變,由于對稱性,可以通過考慮濾波器的一邊并繼承另一半的結果來有效地計算濾波器,
SincNet中涉及的所有操作都是完全可微的,濾波器的截止頻率可以通過隨機梯度下降(SGD)或其他基于梯度的優化例程與其他CNN引數聯合優化,如圖1所示,第一次基于sincs的卷積后,可以使用標準的CNN管道(池化、歸一化、激活、退出),多個標準的convolutional、fully-connected或layers[3740]可以疊加在一起,最后使用softmax分類器對speaker進行分類,
2.1 模型屬性
提出的SincNet具有一些顯著的性質
快速收斂:SincNet迫使網路只關注對性能有重大影響的濾波器引數,所提出的方法實際上實作了一種自然的歸納偏差,它利用了有關濾波器形狀的知識(類似于這項任務中通常使用的特征提取方法),同時保留了適應資料的靈活性,這種先驗知識使得學習濾波器特性變得更加容易,幫助SincNet更快地收斂到一個更好的解決方案,
引數少:sincnet極大地減少了第一卷積層的引數個數,例如,如果我們考慮一個由長度為l的f濾波器組成的層,標準cnn使用f·l引數,而sincnet考慮的是2f,如果f=80和l=100,我們對cnn使用8k引數,而對sincnet使用160引數,此外,如果我們將濾波器長度l加倍,標準cnn將其引數計數加倍(例如,我們從8k變為16k),而sincnet的引數計數不變(每個濾波器只使用兩個引數,而不管其長度l如何),這就提供了一種可能性,可以在不實際添加
引數少:SincNet大大減少了第一個卷積層的引數數量,例如,如果我們考慮一個長度為L的F過濾器組成的層,一個標準的CNN使用F·L引數,而SincNet考慮的是2F,如果F = 80, L = 100,我們對CNN使用8k引數,而對SincNet僅使用160,此外,如果我們濾波器長度的兩倍,一個標準的CNN雙打其引數計算(例如,從8 k到16 k),盡管SincNet不變引數計數(只有兩個引數是用于每個過濾器,不管它的長度L),這提供了可能性獲得非常挑剔和許多水龍頭過濾器,不添加引數優化問題,此外,SincNet體系結構的緊湊性使其適合于少數樣本的情況,
可解釋性:與其他方法相比,在第一個卷積層中獲得的SincNet feature map具有更好的解釋性和可讀性,事實上,濾波器組只依賴于具有明確物理意義的引數,
3 相關作業
最近有幾項研究探索了使用CNNs來處理音頻和語音的低水平語音表示,之前的大多數嘗試都利用了星等譜圖特征[1921,41 43],雖然光譜圖比標準手工制作的特征保留了更多的資訊,但它們的設計仍然需要仔細調整一些關鍵的超引數,比如幀視窗的持續時間、重疊和型別學,以及頻率箱的數量,因此,最近的趨勢是直接學習原始波形,從而完全避免任何特征提取步驟,該方法在語音[22,26]中顯示了良好的前景,包括情緒任務[27]、說話人識別[32]、欺騙檢測[31]和語音合成[28,29],與SincNet類似,之前的一些作業也提出了對CNN過濾器添加約束,例如強制它們在特定波段上作業[41,42],與提出的方法不同的是,后者的作業是根據譜圖特征進行操作,同時仍然學習CNN濾波器的所有L元素,在[43]中,使用了一組引數化高斯濾波器,探索了與所提方法相關的思想,該方法對譜圖域進行處理,而SincNet直接考慮原始時域波形,
據我們所知,這項研究是第一次顯示了使用卷積神經網路對原始波形進行時域音頻處理的sinc濾波器的有效性,過去的研究主要針對語音識別,而我們的研究主要針對語音識別的應用,SincNet學習的緊湊過濾器特別適合于說話人識別任務,特別是在每個說話人的訓練資料只有幾秒鐘和用于測驗的短句的現實場景中,
4 實驗設定
建議的SincNet已經在不同的語料庫上進行了評估,并與許多說話人識別基線進行了比較,本著可重復研究的精神,我們利用Librispeech等公共資料進行了大部分實驗,并在GitHub上發布了SincNet的代碼,在下面的部分中,將提供實驗設定的概述,
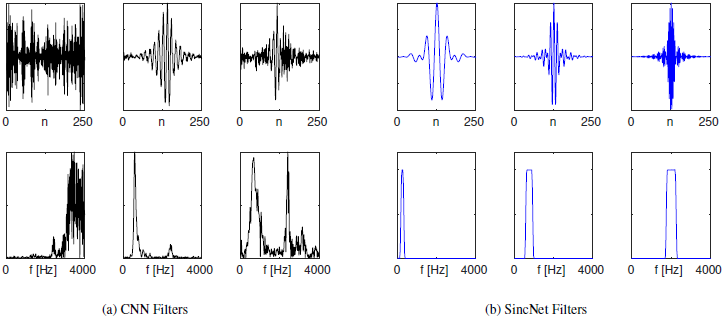
圖2:使用標準CNN和建議的SincNet(使用Librispeech語料庫)學習過濾器的示例,第一行顯示了濾波器的時域,第二行顯示它們的幅頻回應,
4.1 語料庫
為了對不同數量的說話者資料集提供實驗證據,本文考慮了TIMIT (462 spks, train chunk)[44]和Librispeech (2484 spks)[45]語料庫,去掉每個句子開頭和結尾的非語音間隔,內部沉默超過125毫秒的Librispeech陳述句被分成多個塊,為了解決文本無關的說話人識別,TIMIT的校準陳述句(即,所有說話者的文本相同)已被洗掉,對于后一個資料集,每個說話者使用5個句子進行訓練,其余3個句子用于測驗,在Librispeech語料庫中,培訓和測驗材料被隨機選擇,每個演講者使用12-15秒的訓練資料,測驗2-6秒的句子,
4.2 SincNet 設定
每個語音句子的波形被分割成200 ms的塊(有10 ms的重疊),并輸入到Sinc- Net體系結構中,第一層使用長度為L=251個樣本的80個過濾器,執行第2節中描述的基于sincs的卷積,該架構隨后使用了兩個標準的卷積層,都使用60個長度為5的過濾器,層歸一化[46]用于輸入樣本和所有卷積層(包括SincNet輸入層),接下來,我們使用三個由2048個神經元組成的全連接層,并使用批量歸一化[47]進行歸一化,所有的隱層使用漏- relu[48]非線性,使用mel-scale截止頻率初始化sincs層的引數,而使用眾所周知的Glorot初始化方案[49]初始化網路的其余部分,通過使用softmax分類器獲得幀級揚聲器分類,提供了一組目標揚聲器的后驗概率,一個句子級別的分類是簡單地通過平均幀預測和投票給說話者而得到的,這樣可以最大化平均后驗,
訓練使用RMSprop優化器,學習率lr=0:001,a=0:95,e=10-7,小批量128,架構的所有超引數都是在timit上調整的,然后也被librispeech繼承,
揚聲器驗證系統是由揚聲器識別神經網路考慮兩種可能的設定,首先,我們考慮d-vector framework[13, 21],它依賴于最后一個隱含層的輸出,計算測驗和宣告的speaker dvectors之間的余弦距離,作為另一種解決方案(下稱DNN-class),說話人驗證系統可以直接取與宣告身份對應的softmax后驗分數,這兩種方法將在第5節中進行比較,
從冒名頂替者中隨機選出10個話語,每個句子都來自一個真正的演講者,請注意,為了評估我們在標準的開放集揚聲器id任務中的方法,所有的冒名頂替者都來自一個與用于培訓揚聲器id DNN不同的揚聲器池,
4.3 基線設定
我們比較了SincNet與幾個備選系統,首先,我們考慮由原始波形提供的標準CNN,這個網路基于與SincNet相同的架構,但是用一個標準的來代替基于SincNet的卷積,
還與流行的手工制作功能進行了比較,To end, 我們 計算 39 MFCCs (13 static++) 40 FBANKs 使用 Kaldi 工具包 [50].這些特征每25毫秒計算一次,有10毫秒的重疊,收集起來形成一個約200毫秒的背景關系視窗(即,與考慮的基于波形的神經網路的背景關系相似),FBANK使用CNN, MFCCs4使用多層感知器(MLP),FBANK網路采用層歸一化,MFCC網路采用批量歸一化,這些網路的超引數也使用上述方法進行了調整,
對于說話人驗證實驗,我們也考慮了i-vector基線,i-vector系統是用SIDEKIT工具包[51]實作的,在Librispeech資料(避免測驗和登記陳述句)上訓練GMM-UBM模型、總變率(TV)矩陣和概率線性判別分析(PLDA),GMM-UBM由2048個高斯分量組成,TV和PLDA特征語音矩陣的秩為400,注冊和測驗階段在Librispeech上進行,使用與DNN實驗相同的語音片段集,
5 結果
本節報告所提出的SincNet的實驗驗證,首先,我們將使用SincNet學習的過濾器與使用標準CNN學習的過濾器進行比較,然后,我們將我們的體系結構與其他競爭系統在說話人識別和驗證任務方面進行比較
5.1 濾波器的分析
檢查學習過的過濾器是一種有價值的實踐,可以洞察網路實際上正在學習什么,圖2展示了使用Librispeech資料集(頻率回應繪制在0到4khz之間)通過標準CNN(圖2a)和建議的SincNet(圖2b)學習濾波器的一些示例,從圖中可以看出,標準的CNN并不總是學習具有明確頻率回應的濾波器,在某些情況下,頻響看起來有噪聲(見圖2a的第一個濾波器),而在另一些情況下,假設有多頻帶形狀(見CNN圖的第三個濾波器),相反,SincNet是專門設計來實作矩形帶通濾波器,導致更有意義的CNN濾波器,
除了定性的檢查外,重要的是要強調哪些頻帶被所學習的濾波器覆寫,圖3為SincNet和CNN學習的濾波器的累積頻響,有趣的是,在SincNet圖中有三個明顯突出的主要峰值(參見圖中的紅線),第一個對應于音高區域(男性的平均音高為133赫茲,女性為234赫茲),第二個峰值(大約位于500hz)主要捕捉第一個共振峰,其在各種英語元音上的平均值確實是500hz,最后,第三個峰(從900到1400赫茲)捕捉到一些重要的第二共振峰,如元音/a/的第二共振峰,平均位于1100赫茲,此篩選器組配置表明,SincNet已經成功地調整了其特性來處理說話人標識,相反,標準的CNN沒有表現出這樣一種有意義的模式:CNN過濾器傾向于正確地聚焦在頻譜的較低部分,但是調諧到第一和第二共振峰的峰值并沒有清晰地出現,從圖3可以看出,CNN曲線位于SincNet曲線之上,實際上,SincNet學習的過濾器,平均來說,比CNN的更有效,可能更好地捕捉窄帶揚聲器的線索,
5.2 說話人辨別
與標準CNN相比,SincNet的學習曲線如圖4所示,在TIMIT資料集上得到的這些結果突出了使用SincNet時幀錯誤率(FER%)的更快降低,此外,SincNet收斂到更好的性能,導致一個33.0%的FER與一個37.7%的FER實作與CNN的基線,
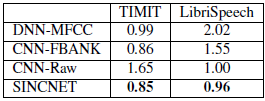
表1:在TIMIT (462 spks)和Librispeech (2484 spks)資料集上訓練的說話人識別系統的分類錯誤率(CER%),我們的產品比競爭對手的性能好,
表1報告了實作的分類錯誤率(CER%),該表顯示,SincNet在TIMIT和Librispeech資料集上都優于其他系統,在TIMIT上,原始波形與標準CNN的差距特別大,這證實了SincNet在訓練資料較少的情況下的有效性,雖然LibriSpeech的使用減少了這一差距,我們仍然觀察到4%的相對改善,也獲得了更快的收斂(1200對1800年代),標準FBANKs只在TIMIT上提供了與SincNet相當的結果,但在使用Librispech時比我們的架構差得多,在訓練資料很少的情況下,網路不能比fbank更好地發現過濾器,但是在資料較多的情況下,可以學習和利用定制的過濾器庫來提高性能,
5.3,說話人驗證
作為最后一個實驗,我們將驗證擴展到說話人驗證,表2報告了使用Librispeech語料庫獲得的相同錯誤率(EER%),所有DNN模型都顯示出良好的性能,導致所有病例的EER均低于1%,該表還強調了SincNet的表現優于其他模型,顯示了相對于標準CNN模型約11%的性能改進,dnn類模型的性能明顯優于d-vector,盡管后一種方法很有效,但是必須為每一個添加到[32]池中的新揚聲器訓練(或調整)一個新的DNN模型,這使得該方法的性能更好,但與d-vector相比靈活性更差,
為了完整起見,還對標準i-vector進行了實驗,雖然與此技術的詳細比較超出了本文的范圍,但值得注意的是,我們最好的i-vector系統實作了EER=1.1%,遠遠低于DNN系統,眾所周知,在文獻中,當每個說話者使用更多的訓練材料和使用更長的測驗陳述句時,i-vector能夠提供競爭性的表現[52 54],在這項作業所面臨的挑戰條件下,神經網路可以實作更好的泛化,
6 結論和未來的作業
提出了一種直接處理波形音頻的神經網路結構SincNet,我們的模型受到數字信號處理中濾波方式的啟發,通過有效的引數化對濾波形狀施加約束,SincNet已經廣泛地評估了挑戰性的說話人識別和驗證任務,顯示性能效益為所有考慮的語料庫,
除了性能的提高,SincNet也大大提高了收斂速度超過一個標準的CNN,并由于利用濾波器的對稱性計算效率更高,對SincNet濾波器的分析表明,所學習的濾波器組被調優,以精確地提取一些已知的重要揚聲器特性,如音高和共振峰,在未來的作業中,我們將評估SincNet在其他流行的揚聲器識別任務,如VoxCeleb,雖然本研究僅針對說話人識別,但我們認為所提出的方法定義了處理時間序列的一般范式,可以應用于許多其他領域,因此,我們未來的努力將致力于擴展到其他任務,如語音識別、情感識別、語音分離和音樂處理,
感謝
我們要感謝高塔姆·巴塔查里亞、凱爾·卡斯特納、蒂圖安·帕科利特、德米特里·謝爾約克、莫里齊奧·奧莫洛戈和雷納托·德·莫里,這項研究在一定程度上得到了Calcul Qu ebec和Compute Canada的支持,
參考文獻
[1] H. Beigi, Fundamentals of Speaker Recognition, Springer, 2011.
[2] N. Dehak, P. J. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet, Front-end factor analysis for speaker verification, IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 788 798, 2011.
[3] D. A. Reynolds, T. F. Quatieri, and R. B. Dunn, Speaker verification using adapted Gaussian mixture models, Digital Signal Processing, vol. 10, no. 1 3, pp. 19 41, 2000. [4] I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning, MIT Press, 2016.
[5] D. Yu and L. Deng, Automatic Speech Recognition - A Deep Learning Approach, Springer, 2015.
[6] G. Dahl, D. Yu, L. Deng, and A. Acero, Contextdependent pre-trained deep neural networks for large vocabulary speech recognition, IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 1, pp. 30 42, 2012.
[7] M. Ravanelli, Deep learning for Distant Speech Recognition, PhD Thesis, Unitn, 2017.
[8] M. Ravanelli, P. Brakel, M. Omologo, and Y. Bengio, A network of deep neural networks for distant speech recognition, in Proc. of ICASSP, 2017, pp. 4880 4884.
[9] M. McLaren, Y. Lei, and L. Ferrer, Advances in deep neural network approaches to speaker recognition, in Proc. of ICASSP, 2015, pp. 4814 4818.
[10] F. Richardson, D. Reynolds, and N. Dehak, Deep neural network approaches to speaker and language recognition, IEEE Signal Processing Letters, vol. 22, no. 10, pp. 1671 1675, 2015.
[11] P. Kenny, V. Gupta, T. Stafylakis, P. Ouellet, and J. Alam, Deep neural networks for extracting baumwelch statistics for speaker recognition, in Proc. of Speaker Odyssey, 2014.
[12] S. Yaman, J. W. Pelecanos, and R. Sarikaya, Bottleneck features for speaker recognition, in Proc. of Speaker Odyssey, 2012, pp. 105 108.
[13] E. Variani, X. Lei, E. McDermott, I. L. Moreno, and J. Gonzalez-Dominguez, Deep neural networks for small footprint text-dependent speaker verification, in Proc. of ICASSP, 2014, pp. 4052 4056.
[14] G. Heigold, I. Moreno, S. Bengio, and N. Shazeer, End-to-end text-dependent speaker verification, in Proc. of ICASSP, 2016, pp. 5115 5119.
[15] D. Snyder, P. Ghahremani, D. Povey, D. Romero, Y. Carmiel, and S. Khudanpur, Deep neural networkbased speaker embeddings for end-to-end speaker verification, in Proc. of SLT, 2016, pp. 165 170.
[16] D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudanpur, X-vectors: Robust dnn embeddings for speaker recognition, in Proc. of ICASSP, 2018.
[17] F. Richardson, D. A. Reynolds, and N. Dehak, A unified deep neural network for speaker and language recognition, in Proc. of Interspeech, 2015, pp. 1146 1150.
[18] D. Snyder, D. Garcia-Romero, D. Povey, and S. Khudanpur, Deep neural network embeddings for textindependent speaker verification, in Proc. of Interspeech, 2017, pp. 999 1003.
[19] C. Zhang, K. Koishida, and J. Hansen, Textindependent speaker verification based on triplet convolutional neural network embeddings, IEEE/ACM Trans. Audio, Speech and Lang. Proc., vol. 26, no. 9, pp. 1633 1644, 2018.
[20] G. Bhattacharya, J. Alam, and P. Kenny, Deep speaker embeddings for short-duration speaker verification, in Proc. of Interspeech, 2017, pp. 1517 1521.
[21] A. Nagrani, J. S. Chung, and A. Zisserman, Voxceleb: a large-scale speaker identification dataset, in Proc. of Interspech, 2017.
[22] D. Palaz, M. Magimai-Doss, and R. Collobert, Analysis of CNN-based speech recognition system using raw speech as input, in Proc. of Interspeech, 2015.
[23] T. N. Sainath, R. J. Weiss, A. W. Senior, K. W. Wilson, and O. Vinyals, Learning the speech front-end with raw waveform CLDNNs, in Proc. of Interspeech, 2015.
[24] Y. Hoshen, R.Weiss, and K.W.Wilson, Speech acoustic modeling from raw multichannel waveforms, in Proc. of ICASSP, 2015.
[25] T. N. Sainath, R. J. Weiss, K. W. Wilson, A. Narayanan, M. Bacchiani, and A. Senior, Speaker localization and microphone spacing invariant acoustic modeling from raw multichannel waveforms, in Proc. of ASRU, 2015.
[26] Z. T uske, P. Golik, R. Schl uter, and H. Ney, Acoustic modeling with deep neural networks using raw time signal for LVCSR, in Proc. of Interspeech, 2014.
[27] G. Trigeorgis, F. Ringeval, R. Brueckner, E. Marchi, M. A. Nicolaou, B. Schuller, and S. Zafeiriou, Adieu features? end-to-end speech emotion recognition using a deep convolutional recurrent network, in Proc. of ICASSP, 2016, pp. 5200 5204.
[28] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, Wavenet: A generative model for raw audio, in Arxiv, 2016.
[29] S. Mehri, K. Kumar, I. Gulrajani, R. Kumar, S. Jain, J. Sotelo, A. C. Courville, and Y. Bengio, Samplernn: An unconditional end-to-end neural audio generation model, CoRR, vol. abs/1612.07837, 2016.
[30] P. Ghahremani, V. Manohar, D. Povey, and S. Khudanpur, Acoustic modelling from the signal domain using CNNs, in Proc. of Interspeech, 2016.
[31] H. Dinkel, N. Chen, Y. Qian, and K. Yu, End-toend spoofing detection with raw waveform CLDNNS, Proc. of ICASSP, pp. 4860 4864, 2017.
[32] H. Muckenhirn, M. Magimai-Doss, and S. Marcel, Towards directly modeling raw speech signal for speaker verification using CNNs, in Proc. of ICASSP, 2018.
[33] J.-W. Jung, H.-S. Heo, I.-H. Yang, H.-J. Shim, , and H.- J. Yu, A complete end-to-end speaker verification system using deep neural networks: From raw signals to verification result, in Proc. of ICASSP, 2018.
[34] J.-W. Jung, H.-S. Heo, I.-H. Yang, H.-J. Shim, and H.-J. Yu, Avoiding Speaker Overfitting in End-to- End DNNs using Raw Waveform for Text-Independent Speaker Verification, in Proc. of Interspeech, 2018.
[35] L. R. Rabiner and R. W. Schafer, Theory and Applications of Digital Speech Processing, Prentice Hall, NJ, 2011.
[36] S. K. Mitra, Digital Signal Processing, McGraw-Hill, 2005.
[37] J. Chung, C . G ulc ehre, K. Cho, and Y. Bengio, Empirical evaluation of gated recurrent neural networks on sequence modeling, in Proc. of NIPS, 2014.
[38] M. Ravanelli, P. Brakel, M. Omologo, and Y. Bengio, Improving speech recognition by revising gated recurrent units, in Proc. of Interspeech, 2017.
[39] M. Ravanelli, P. Brakel, M. Omologo, and Y. Bengio, Light gated recurrent units for speech recognition, IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 2, no. 2, pp. 92 102, April 2018.
[40] M. Ravanelli, D. Serdyuk, and Y. Bengio, Twin regularization for online speech recognition, in Proc. of Interspeech, 2018.
[41] T. N. Sainath, B. Kingsbury, A. R. Mohamed, and B. Ramabhadran, Learning filter banks within a deep neural network framework, in Proc. of ASRU, 2013, pp. 297 302.
[42] H. Yu, Z. H. Tan, Y. Zhang, Z. Ma, and J. Guo, DNN Filter Bank Cepstral Coefficients for Spoofing Detection, IEEE Access, vol. 5, pp. 4779 4787, 2017.
[43] H. Seki, K. Yamamoto, and S. Nakagawa, A deep neural network integrated with filterbank learning for speech recognition, in Proc. of ICASSP, 2017, pp. 5480 5484.
[44] J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, D. S. Pallett, and N. L. Dahlgren, DARPA TIMIT Acoustic Phonetic Continuous Speech Corpus CDROM, 1993.
[45] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, Librispeech: An ASR corpus based on public domain audio books, in Proc. of ICASSP, 2015, pp. 5206 5210.
[46] J. Ba, R. Kiros, and G. E. Hinton, Layer normalization, CoRR, vol. abs/1607.06450, 2016.
[47] S. Ioffe and C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, in Proc. of ICML, 2015, pp. 448 456.
[48] A. L. Maas, A. Y. Hannun, and A. Y. Ng, Rectifier nonlinearities improve neural network acoustic models, in Proc. of ICML, 2013.
[49] X. Glorot and Y. Bengio, Understanding the difficulty of training deep feedforward neural networks, in Proc. of AISTATS, 2010, pp. 249 256.
[50] D. Povey et al., The Kaldi Speech Recognition Toolkit, in Proc. of ASRU, 2011.
[51] A. Larcher, K. A. Lee, and S. Meignier, An extensible speaker identification sidekit in python, in Proc. of ICASSP, 2016, pp. 5095 5099.
[52] A. K. Sarkar, D Matrouf, P.M. Bousquet, and J.F. Bonastre, Study of the effect of i-vector modeling on short and mismatch utterance duration for speaker verification, in Proc. of Interspeech, 2012, pp. 2662 2665.
[53] R. Travadi, M. Van Segbroeck, and S. Narayanan, Modified-prior i-Vector Estimation for Language Identification of Short Duration Utterances, in Proc. of Interspeech, 2014, pp. 3037 3041.
[54] A. Kanagasundaram, R. Vogt, D. Dean, S. Sridharan, and M. Mason, i-vector based speaker recognition on short utterances, in Proc. of Interspeech, 2011, pp. 2341 2344.
專案地址:https://github.com/grausof/keras-sincnet
論文:https://arxiv.org/pdf/1808.00158v3.pdf
paperwithcode地址:https://paperswithcode.com/paper/speaker-recognition-from-raw-waveform-with#
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/151113.html
標籤:其他
上一篇:論文翻譯:2015_A Deep Neural Network Approach To Speech Bandwidth Expansion
下一篇:Opencv影像處理基礎