SCO模型閱讀筆記
論文:Learning Semantic Concepts and Order for Image and Sentence Matching
發表會議:CVPR2018
作者:
一、為什么看?
好多關于影像-文本檢索的文章,但是大多數都忽略了影像的語意順序,當語意順序被忽略時,會造成檢索不準確,影像和文本的語意完全相反,
看點:影像的語意順序如何構建
應用:于跨模態影像-文本檢索
二、論文思路
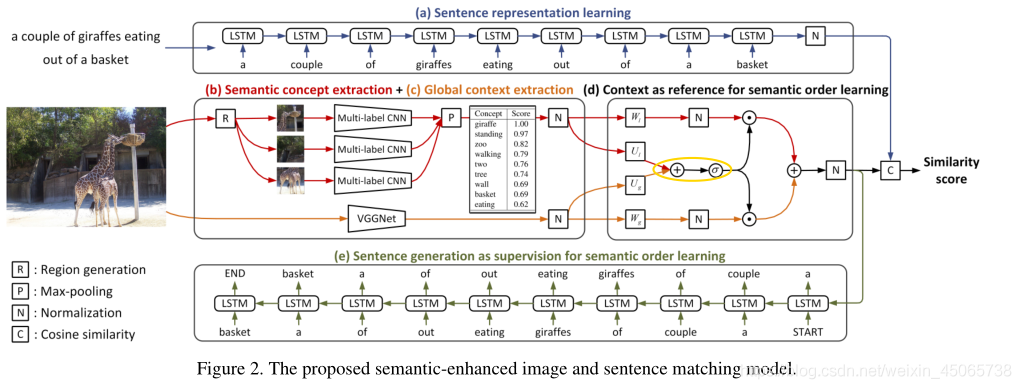
影像語意之間存在差距,特別是像素級影像缺乏語意資訊,本文提出語意增強影像和句子匹配模型,來通過學習語意概念和用一個正確的順序語意順序提高影像表示,
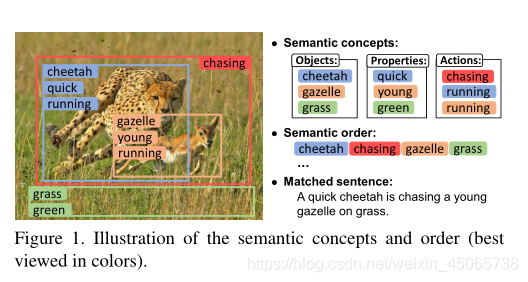
給定一張影像,用多區域多標簽CNN預測語意概念,包括物件、屬性、動作;
由于區域沒有順序,如何給這些語意概念排序,將全域背景關系和語意概念融合;
對應的句子用LSTM生成,并且對融合后的句子進行監督,對比相似度,
疑問?
為什么要提取語意概念?
語意概念是影像與句子匹配的基本內容,像素級無法完成;
為什么不直接用影像描述?
影像描述和匹配是有區別的,影像匹配重點實在細粒度上找最相似的,影像描述體現在語意上,它不一定能夠捕獲到影像的細節,
為什么不從語意概念上直接學習語意順序?
不同的順序就有不同的意義,語意上有意義但可能是錯誤的順序,
三、具體作業
句子表示學習:
一個完整的句子包括名詞、動詞和形容詞,分別對應語意概念中的物件、動作和屬性,對于一個句子,語意相關詞的概念本質上表現為句子的順序性,
采用傳統的LSTM來捕獲語意相關的詞和構建語意順序,
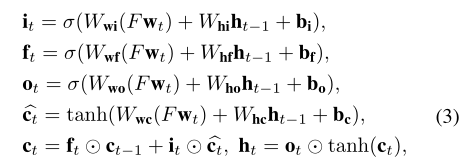
影像的語意概念提取:
目前存在的資料集中,只有影像和匹配的句子,資料集不能提供物件、屬性和動作的資訊,所以必須用多區域 多標簽的CNN進行預測,(被faster R-CNN取代) 預測語意概念等價于多標簽分類問題,
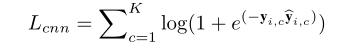
只挑選句子中的名詞、形容詞、動詞和數字,洗掉同一語意相關的詞,忽略頻率低的詞,
影像語意順序學習
使用影像全域背景關系為參考和句子生成為監督,
影像全域背景關系
將全域背景關系和語意概念全部疊加在一起,不可取,因為語意概念和全域是的重要性是不相同的,
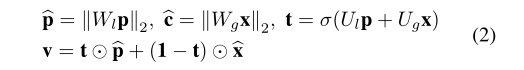
生成的句子為監督
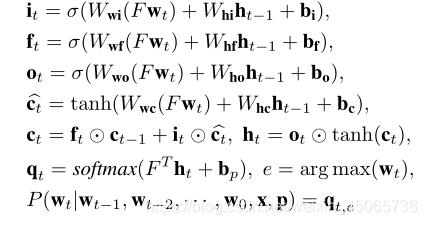
損失函式:
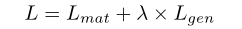
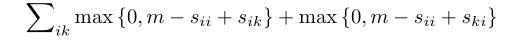
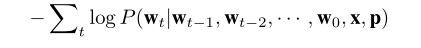
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/159306.html
標籤:其他
下一篇:學習方波有霍爾傳感的電機調速記錄