Tensorflow入門一條龍
- 前景提要
- Tensorflow介紹
- Tensorflow安裝
- 梯度下降
- 處理結構
- Tensorflow結構
- Tensor 介紹
- Tensorflow 編程
- Session會話控制
- Variable 定義變數
- Placeholder 輸入值設定
- 激勵函式 (Activation Function)
- 激勵函式Activation Function
- 添加神經層 -- 激勵函式添加圖層
- 建立神經網路
- 結果可視化
- 加速神經網路訓練
- Stochastic Gradient Descent (SGD)
- Momentum
- AdaGrad
- RMSProp
- Adam
- 最后還是希望你們能給我點一波小小的關注,
- 奉上自己誠摯的愛心💖
前景提要
本想寫一期強化學習DQN的教程,害怕出現勸退的現象,那就先教一期Tensorflow,
根據前一期深度學習實戰手寫體識別上來看,有些人跟我說Tensorflow基礎沒打好,直接上戰場的話啥也看不懂,那這期從入門到入土的總結一下Tensorflow吧,
以往文章: 手寫體識別實戰教程
Tensorflow介紹
Tensorflow 是一個使用資料流圖進行數值計算的開放源代碼軟體庫, 圖中的節點代表數學運算,而圖中的邊則代表在這些節點之間傳遞的多維陣列(張量),借助這種靈活的架構,您可以通過一個 API 將計算作業部署到桌面設備、服務器或移動設備中的一個或多個 CPU 或 GPU,Tensorflow 最初是由 Google Brain 團隊(隸屬于 Google 機器智能研究部門)中的研究人員和工程師開發的,旨在用于進行機器學習和深度神經網路研究,但該系統具有很好的通用性,還可以應用于眾多其他領域,
Tensorflow安裝
Tensorflow分為GPU版本以及CPU版本
pip安裝CPU版本Tensorflow:pip install --upgrade --ignore-installed tensorflow

pip安裝GPU版本Tensorflow:pip install --upgrade --ignore-installed tensorflow-gpu
(前提是電腦需要支持GPU版本才可以安裝)
然后檢測安裝環境

梯度下降
梯度下降是迭代法的一種,可以用于求解最小二乘問題(線性和非線性都可以),在求解機器學習演算法的模型引數,即無約束優化問題時,梯度下降(Gradient Descent)是最常采用的方法之一,另一種常用的方法是最小二乘法,在求解損失函式的最小值時,可以通過梯度下降法來一步步的迭代求解,得到最小化的損失函式和模型引數值,反過來,如果我們需要求解損失函式的最大值,這時就需要用梯度上升法來迭代了,在機器學習中,基于基本的梯度下降法發展了兩種梯度下降方法,分別為隨機梯度下降法和批量梯度下降法,
梯度下降演算法(Gradient Descent Optimization)是神經網路模型訓練最常用的優化演算法,對于深度學習模型,基本都是采用梯度下降演算法來進行優化訓練的,梯度下降演算法背后的原理:目標函式J(θ) 關于引數θ的梯度將是目標函式上升最快的方向,對于最小化優化問題,只需要將引數沿著梯度相反的方向前進一個步長,就可以實作目標函式的下降,這個步長又稱為學習速率η,引數更新公式如下:
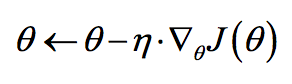
其中
?
\nabla
? J(θ) 是引數的梯度,根據計算目標函式J(θ)采用資料量的不同,梯度下降演算法又可以分為批量梯度下降演算法(Batch Gradient Descent),隨機梯度下降演算法(Stochastic GradientDescent)和小批量梯度下降演算法(Mini-batch Gradient Descent),對于批量梯度下降演算法,其J(θ)是在整個訓練集上計算的,如果資料集比較大,可能會面臨記憶體不足問題,而且其收斂速度一般比較慢,隨機梯度下降演算法是另外一個極端,J(θ)是針對訓練集中的一個訓練樣本計算的,又稱為在線學習,即得到了一個樣本,就可以執行一次引數更新,所以其收斂速度會快一些,但是有可能出現目標函式值震蕩現象,因為高頻率的引數更新導致了高方差,小批量梯度下降演算法是折中方案,選取訓練集中一個小批量樣本計算J(θ),這樣可以保證訓練程序更穩定,而且采用批量訓練方法也可以利用矩陣計算的優勢,這是目前最常用的梯度下降演算法,
神經網路中的 W 可不止一個, 如果只有一個 W, 我們就能畫出之前那樣的誤差曲線, 如果有兩個 W 也簡單, 我們可以用一個3D 圖來展示, 可是超過3個 W, 我們可就沒辦法很好的可視化出來啦. 這可不是最要命的. 在通常的神經網路中, 誤差曲線可沒這么優雅.
處理結構
Tensorflow結構
Tensorflow 首先要定義神經網路的結構, 然后再把資料放入結構當中去運算和 training,

因為TensorFlow是采用資料流圖(data flow graphs)來計算,所以首先我們得創建一個資料流流圖, 然后再將我們的資料(資料以張量(tensor)的形式存在)放在資料流圖中計算. 節點(Nodes)在圖中表示數學操作,圖中的線(edges)則表示在節點間相互聯系的多維資料陣列, 即張量(tensor). 訓練模型時tensor會不斷的從資料流圖中的一個節點flow到另一節點, 這就是TensorFlow名字的由來.
Tensor 介紹
張量(Tensor): 張量有多種. 零階張量為 純量或標量 (scalar) 也就是一個數值. 比如 [1] 一階張量為 向量 (vector), 比如 一維的 [1, 2, 3] 二階張量為 矩陣 (matrix), 比如 二維的 [[1, 2, 3],[4, 5, 6],[7, 8, 9]] 以此類推, 還有 三階 三維的 …
Tensorflow 編程
首先加載 tensorflow 和 numpy 兩個模塊,
# 為了防止2.x的Tensorflow報錯,在這里直接使用兼容版本
# 此次教程中均適用該兼容版本
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
# 匯入Numpy
import numpy as np
使用 numpy 來創建我們的資料
# 生成一百個亂數列,以float32資料定制
x_data = np.random.rand(100).astype(np.float32)
# 預測W和b的值
y_data = x_data*0.1 + 0.3
接著, 我們用 tf.Variable 來創建描述 y 的引數. 我們可以把 y_data = x_data*0.1 + 0.3 想象成 y=Weights * x + biases, 然后神經網路也就是學著把 Weights 變成 0.1, biases 變成 0.3.
# tf中定義變數需要使用Variable,使用亂數列生成方式生成一維結構,-1到1之間
Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
# 初始給b的值為0,訓練結尾盡量靠近3
biases = tf.Variable(tf.zeros([1]))
# 預測值Y定義
y = Weights*x_data + biases
# 計算預測值與真實值之間的差別
loss = tf.reduce_mean(tf.square(y-y_data))
# 使用梯度下降優化器減少誤差,提高引數準確度,學習度為0.5
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# 初始化Variable這個變數,不初始化無法定義新變數
init = tf.global_variables_initializer()
接著,我們再創建會話 Session. 我們用 Session 來執行 init 初始化步驟. 并且, 用 Session 來 run 每一次 training 的資料. 逐步提升神經網路的預測準確性.
# 定義一個Session物件
with tf.Session() as sess:
# 運行初始化,激活整個神經網路
sess.run(init)
# 訓練兩百次
for step in range(200):
# 訓練train梯度下降
sess.run(train)
# 每二十步列印一次變數,每次使用tf中引數都需要run
if step % 20 == 0:
print(step, sess.run(Weights), sess.run(biases))
運行結果展示,我們能發現隨機產生的資料在經過兩百次的訓練之下,線性回歸于y_data = x_data*0.1 + 0.3結果值,說明此次梯度下降成功,

Session會話控制
Tensorflow 中的 Session, Session 是 Tensorflow 為了控制,和輸出檔案的執行的陳述句. 運行 session.run() 可以獲得你要得知的運算結果, 或者是你所要運算的部分.
# 定義兩個常量
matrix1 = tf.constant([[3,3]])
matrix2 = tf.constant([[2],
[2]])
# tf內部的矩陣乘法,相當于np.dot(matrix1,matrix2)
product = tf.matmul(matrix1,matrix2)
當我們使用之后,我們列印一次該變數值,我們會發現他是個 tf變數,也就是在這個時候,Tensorflow并沒有進行該運算
print(product)
# tf.Tensor([[12]], shape=(1, 1), dtype=int32)
當我們使用Session運行該變數時,列印該結果,我們會發現他會為我們計算矩陣乘法
with tf.Session() as sess:
print(sess.run(product))
# [[12]]
Variable 定義變數
Tensorflow 中定義變數與Python中定義變數有一些不一樣,
- tf中定義了某字串是變數,它才是變數,否則他就是常量,
- tf中定義變數后必須需要初始化才可以使用,
定義語法: state = tf.Variable()
# 定義變數,初始值為0,給該變數一個名字為counter
state = tf.Variable(0, name='counter')
# print(state.name)
# -> counter
# 定義常量
one = tf.constant(1)
# 定義加法步驟 (注: 此步并沒有直接計算)
new_value = tf.add(state, one)
# 將 state 更新成 new_value
update = tf.assign(state, new_value)
# 當你創建變數之后,一定要初始化創建函式才能使用!
# 一定要定義 init = tf.global_variables_initializer()
init = tf.global_variables_initializer()
# 使用 Session
with tf.Session() as sess:
sess.run(init)
for _ in range(3):
sess.run(update)
print(sess.run(state))
運行結果展示,我們會發現回圈三遍,每次都運行一次update功能,列印state也必須寫在sess.run()中才能正常輸出,否則輸出無效,
Placeholder 輸入值設定
placeholder 是 Tensorflow 中的占位符,暫時儲存變數,相當于 Python 中的 input() 方法,
Tensorflow 如果想要從外部傳入data, 那就需要用到 tf.placeholder(), 然后以這種形式傳輸資料 sess.run(***, feed_dict={input: **})
#在 Tensorflow 中需要定義 placeholder 的 type ,一般為 float32 形式
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
# mul = multiply 是將input1和input2 做乘法運算,并輸出為 output
ouput = tf.multiply(input1, input2)
接下來, 傳值的作業交給了 sess.run() , 需要傳入的值放在了feed_dict={} 并一一對應每一個 input. placeholder 與 feed_dict={} 是系結在一起出現的,
with tf.Session() as sess:
print(sess.run(ouput, feed_dict={input1: [9.], input2: [3.]}))
# [ 27.]
激勵函式 (Activation Function)
神經網路中激勵函式的作用通俗上講就是將多個線性輸入轉換為非線性的關系,如果不使用激勵函式的話,神經網路的每層都只是做線性變換,即使是多層輸入疊加后也還是線性變換,通過激勵函式引入非線性因素后,使神經網路的表示能力更強了,
介紹幾個常用的激勵函式:
-
sigmoid 函式
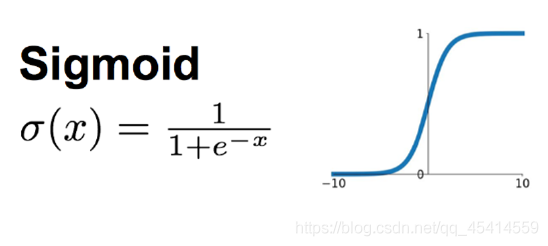
這應該是神經網路中使用最頻繁的激勵函式了,它把一個實數壓縮至0到1之間,當輸入的數字非常大的時候,結果會接近1,當輸入非常大的負數時,則會得到接近0的結果,在早期的神經網路中使用得非常多,因為它很好地解釋了神經元受到刺激后是否被激活和向后傳遞的場景(0:幾乎沒有被激活,1:完全被激活),不過近幾年在深度學習的應用中比較少見到它的身影,因為使用sigmoid函式容易出現梯度彌散或者梯度飽和,當神經網路的層數很多時,如果每一層的激勵函式都采用sigmoid函式的話,就會產生梯度彌散的問題,因為利用反向傳播更新引數時,會乘以它的導數,所以會一直減小,如果輸入的是比較大或者比較小的數(例如輸入100,經Sigmoid函式后結果接近于1,梯度接近于0),會產生飽和效應,導致神經元類似于死亡狀態,

-
tanh 函式
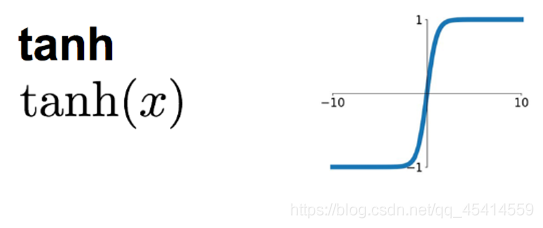
tanh函式將輸入值壓縮至-1到1之間,該函式與Sigmoid類似,也存在著梯度彌散或梯度飽和的缺點, -
ReLU函式
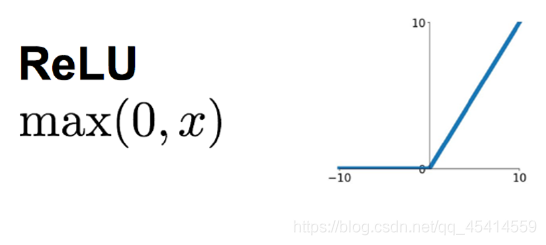
ReLU是修正線性單元(The Rectified Linear Unit)的簡稱,近些年來在深度學習中使用得很多,可以解決梯度彌散問題,因為它的導數等于1或者就是0,相對于sigmoid和tanh激勵函式,對ReLU求梯度非常簡單,計算也很簡單,可以非常大程度地提升隨機梯度下降的收斂速度,(因為ReLU是線性的,而sigmoid和tanh是非線性的)
但ReLU的缺點是比較脆弱,隨著訓練的進行,可能會出現神經元死亡的情況,例如有一個很大的梯度流經ReLU單元后,那權重的更新結果可能是,在此之后任何的資料點都沒有辦法再激活它了,如果發生這種情況,那么流經神經元的梯度從這一點開始將永遠是0,也就是說,ReLU神經元在訓練中不可逆地死亡了, -
Leaky ReLU 函式

Leaky ReLU主要是為了避免梯度消失,當神經元處于非激活狀態時,允許一個非0的梯度存在,這樣不會出現梯度消失,收斂速度快,它的優缺點跟ReLU類似, -
ELU 函式
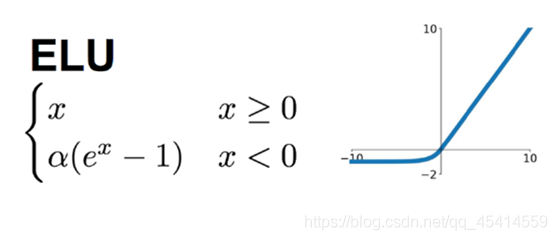
ELU在正值區間的值為x本身,這樣減輕了梯度彌散問題(x>0區間導數處處為1),這點跟ReLU、Leaky ReLU相似,而在負值區間,ELU在輸入取較小值時具有軟飽和的特性,提升了對噪聲的魯棒性 -
Maxout 函式
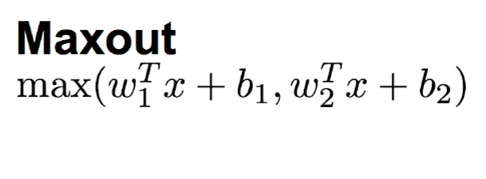
Maxout也是近些年非常流行的激勵函式,簡單來說,它是ReLU和Leaky ReLU的一個泛化版本,當w1、b1設定為0時,便轉換為ReLU公式,
因此,Maxout繼承了ReLU的優點,同時又沒有“一不小心就掛了”的擔憂,但相比ReLU,因為有2次線性映射運算,因此計算量也會翻倍,
激勵函式Activation Function
激勵函式運行時激活神經網路中某一部分神經元,將激活資訊向后傳入下一層的神經系統,激勵函式的實質是非線性方程, Tensorflow 的神經網路 里面處理較為復雜的問題時都會需要運用激勵函式 activation function,
添加神經層 – 激勵函式添加圖層
定義添加神經層的函式def add_layer(),它有四個引數:輸入值、輸入的大小、輸出的大小和激勵函式,我們設定默認的激勵函式是None,
因為在生成初始引數時,隨機變數(normal distribution)會比全部為0要好很多,所以我們這里的weights為一個in_size行, out_size列的隨機變數矩陣,
在機器學習中,biases的推薦值不為0,所以我們這里是在0向量的基礎上又加了0.1,
定義Wx_plus_b, 即神經網路未激活的值,其中,tf.matmul()是矩陣的乘法,
# 定義函式,四個引數值
def add_layer(inputs, in_size, out_size, activation_function=None):
# 定義一個in_size行out_size列的矩陣
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
# 定義一個一行out_size列的均為0.1的矩陣
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
# 定義預測值為Wx+b
Wx_plus_b = tf.matmul(inputs, Weights) + biases
# 如果是線性關系的話,只需要保留現狀就好
if not activation_function:outputs = Wx_plus_b
# 如果是非線性方程,我們只需要將值傳入激勵函式中即可
else:outputs = activation_function(Wx_plus_b)
# 回傳outputs
return outputs
建立神經網路
我們現在需要建立一個神經網路層,運算出和真實值的對比再準備提升這個預測值,
包括添加神經層,計算誤差,訓練步驟,判斷是否在學習,
我們所構建的x_data和y_data并不是嚴格的一元二次函式的關系,因為我們多加了一個noise,這樣看起來會更像真實情況,
# 建立一個-1到1的區間,含有三百行的等引數列
x_data = np.linspace(-1,1,300, dtype=np.float32)[:, np.newaxis]
# 添加一個正態分布的噪點,均值為0,標準差為0.05,shape與x_data相同
noise = np.random.normal(0, 0.05, x_data.shape).astype(np.float32)
# 建立一個x的二次方 - 0.5,并加上一個噪點
y_data = np.square(x_data) - 0.5 + noise
利用占位符定義我們所需的神經網路的輸入, tf.placeholder()就是代表占位符,這里的None代表無論輸入有多少都可以,因為輸入只有一個特征,所以這里是1,
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
接下來,我們就可以開始定義神經層了, 通常神經層都包括輸入層、隱藏層和輸出層,這里的輸入層只有一個屬性, 所以我們就只有一個輸入;隱藏層我們可以自己假設,這里我們假設隱藏層有10個神經元; 輸出層和輸入層的結構是一樣的,所以我們的輸出層也是只有一層, 所以,我們構建的是——輸入層1個、隱藏層10個、輸出層1個的神經網路,
# 定義隱藏層,使用 Tensorflow 自帶的激勵函式tf.nn.relu
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
# 定義輸出層,此時的輸入就是隱藏層的輸出——l1,輸入有10層(隱藏層的輸出層),輸出有1層,
prediction = add_layer(l1, 10, 1, activation_function=None)
# 計算損失函式---預測值prediction和真實值的誤差,對二者差的平方求和再取平均,
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
# 在這里提高學習準確率,我們仍然使用隨機梯度下降方法,以0.1的效率來最小化誤差loss
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 初始化變數,很重要
init = tf.global_variables_initializer()
這次實驗學習1000次,機器學習的內容是train_step, 用 Session 來 run 每一次 training 的資料,逐步提升神經網路的預測準確性,
with tf.Session() as sess:
sess.run(init)
for i in range(1000):
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
if i % 50 == 0:
print(sess.run(loss, feed_dict={xs: x_data, ys: y_data}))
運行結果展示,誤差在逐漸減小,這說明機器學習是有積極的效果的,

結果可視化
我們這次使用的是matplotlib模塊
下載:pip install matplotlib

構建圖形,用散點圖描述真實資料之間的關系,
# 生成一個圖片框
fig = plt.figure()
# 生成一個連續性的圖片集合,制作一個1*1的位置圖集
ax = fig.add_subplot(1,1,1)
# 制作散點圖,將x和y傳入其中
ax.scatter(x_data, y_data)
# 打開互動模式
plt.ion()#本次運行請注釋,全域運行不要注釋
# 輸出圖片
plt.show()
輸出的可視化:
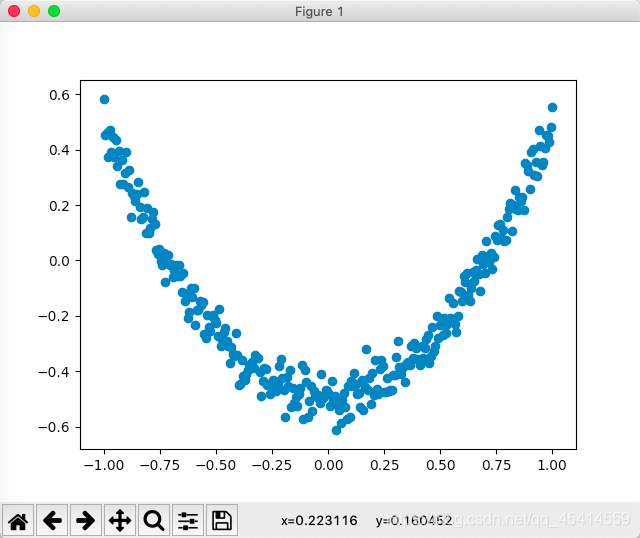
接下來,我們來顯示預測資料,
每隔50次訓練重繪一次圖形,用紅色、寬度為5的線來顯示我們的預測資料和輸入之間的關系,并暫停0.1s,
for i in range(1000):
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
if i % 50 == 0:
# 繪制之后開始畫下一條線,將上個線抹除掉
try:ax.lines.remove(lines[0])
except Exception:pass
prediction_value = sess.run(prediction, feed_dict={xs: x_data})
# 繪制曲線,x,預測y的資料,紅色的線,寬度為5
lines = ax.plot(x_data, prediction_value, 'r-', lw=5)
# 暫停0.1秒,查看結果
plt.pause(0.1)
加速神經網路訓練

越復雜的神經網路 , 越多的資料 , 我們需要在訓練神經網路的程序上花費的時間也就越多. 原因很簡單, 就是因為計算量太大了. 可是往往有時候為了解決復雜的問題, 復雜的結構和大資料又是不能避免的, 所以我們需要尋找一些方法, 讓神經網路聰明起來, 快起來,
加速訓練包括以下幾種模式:
- Stochastic Gradient Descent (SGD)
- Momentum
- AdaGrad
- RMSProp
- Adam
Stochastic Gradient Descent (SGD)

所以, 最基礎的方法就是 SGD 啦, 想像紅色方塊是我們要訓練的 data, 如果用普通的訓練方法, 就需要重復不斷的把整套資料放入神經網路 NN訓練, 這樣消耗的計算資源會很大,
SGD 并不是最快速的訓練方法, 紅色的線是 SGD, 但它到達學習目標的時間是在這些方法中最長的一種. 我們還有很多其他的途徑來加速訓練,
Momentum

大多數其他途徑是在更新神經網路引數那一步上動動手腳. 傳統的引數 W 的更新是把原始的 W 累加上一個負的學習率(learning rate) 乘以校正值 (dx). 這種方法可能會讓學習程序曲折無比, 看起來像 喝醉的人回家時, 搖搖晃晃走了很多彎路,

所以我們把這個人從平地上放到了一個斜坡上, 只要他往下坡的方向走一點點, 由于向下的慣性, 他不自覺地就一直往下走, 走的彎路也變少了. 這就是 Momentum 引數更新. 另外一種加速方法叫AdaGrad,
AdaGrad

這種方法是在學習率上面動手腳, 使得每一個引數更新都會有自己與眾不同的學習率, 他的作用和 momentum 類似, 不過不是給喝醉酒的人安排另一個下坡, 而是給他一雙不好走路的鞋子, 使得他一搖晃著走路就腳疼, 鞋子成為了走彎路的阻力, 逼著他往前直著走. 他的數學形式是這樣的. 接下來又有什么方法呢? 如果把下坡和不好走路的鞋子合并起來, 是不是更好呢? 沒錯, 這樣我們就有了 RMSProp 更新方法,
RMSProp

有了 momentum 的慣性原則 , 加上 adagrad 的對錯誤方向的阻力, 我們就能合并成這樣. 讓 RMSProp同時具備他們兩種方法的優勢. 不過細心的同學們肯定看出來了, 似乎在 RMSProp 中少了些什么. 原來是我們還沒把 Momentum合并完全, RMSProp 還缺少了 momentum 中的 這一部分. 所以, 我們在 Adam 方法中補上了這種想法,
Adam

計算m 時有 momentum 下坡的屬性, 計算 v 時有 adagrad 阻力的屬性, 然后再更新引數時 把 m 和 V 都考慮進去. 實驗證明, 大多數時候, 使用 adam 都能又快又好的達到目標, 迅速收斂. 所以說, 在加速神經網路訓練的時候, 一個下坡, 一雙破鞋子, 功不可沒,
最后還是希望你們能給我點一波小小的關注,
奉上自己誠摯的愛心💖
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/168171.html
標籤:其他
上一篇:(槍版非官方正式發布)2020 年TI 杯大學生電子設計競賽——繞障飛行器(D 題)
下一篇:國慶后的第一天上班