前面講完了 TCP 和 UDP 協議,還沒有上手過,這一節咱們講講基于 TCP 和 UDP 協議的 Socket 編程,
在講 TCP 和 UDP 協議的時候,我們分客戶端和服務端,在寫程式的時候,我們也同樣這樣分,
Socket 這個名字很有意思,可以作插口或者插槽講,雖然我們是寫軟體程式,但是你可以想象為弄一根網線,一頭插在客戶端,一頭插在服務端,然后進行通信,所以在通信之前,雙方都要建立一個 Socket,
在建立 Socket 的時候,應該設定什么引數呢?Socket 編程進行的是端到端的通信,往往意識不到中間經過多少局域網,多少路由器,因而能夠設定的引數,也只能是端到端協議之上網路層和傳輸層的,
在網路層,Socket 函式需要指定到底是 IPv4 還是 IPv6,分別對應設定為 AF_INET 和 AF_INET6,另外,還要指定到底是 TCP 還是 UDP,還記得咱們前面講過的,TCP 協議是基于資料流的,所以設定為 SOCK_STREAM,而 UDP 是基于資料報的,因而設定為 SOCK_DGRAM,
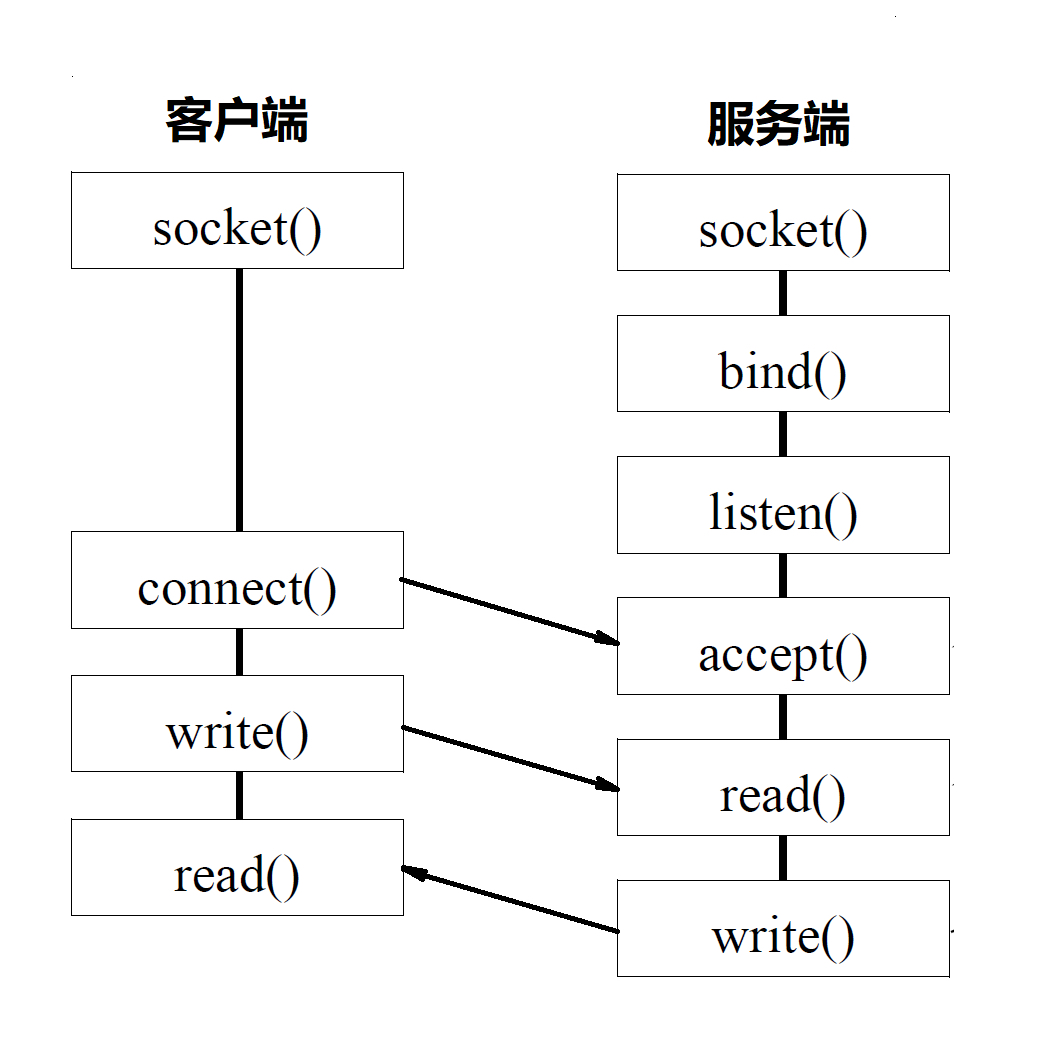
基于 TCP 協議的 Socket 程式函式呼叫程序
兩端創建了 Socket 之后,接下來的程序中,TCP 和 UDP 稍有不同,我們先來看 TCP,
TCP 的服務端要先監聽一個埠,一般是先呼叫 bind 函式,給這個 Socket 賦予一個 IP 地址和埠,為什么需要埠呢?要知道,你寫的是一個應用程式,當一個網路包來的時候,內核要通過 TCP 頭里面的這個埠,來找到你這個應用程式,把包給你,為什么要 IP 地址呢?有時候,一臺機器會有多個網卡,也就會有多個 IP 地址,你可以選擇監聽所有的網卡,也可以選擇監聽一個網卡,這樣,只有發給這個網卡的包,才會給你,
當服務端有了 IP 和埠號,就可以呼叫 listen 函式進行監聽,在 TCP 的狀態圖里面,有一個 listen 狀態,當呼叫這個函式之后,服務端就進入了這個狀態,這個時候客戶端就可以發起連接了,
在內核中,為每個 Socket 維護兩個佇列,一個是已經建立了連接的佇列,這時候連接三次握手已經完畢,處于 established 狀態;一個是還沒有完全建立連接的佇列,這個時候三次握手還沒完成,處于 syn_rcvd 的狀態,
接下來,服務端呼叫 accept 函式,拿出一個已經完成的連接進行處理,如果還沒有完成,就要等著,
在服務端等待的時候,客戶端可以通過 connect 函式發起連接,先在引數中指明要連接的 IP 地址和埠號,然后開始發起三次握手,內核會給客戶端分配一個臨時的埠,一旦握手成功,服務端的 accept 就會回傳另一個 Socket,
這是一個經常考的知識點,就是監聽的 Socket 和真正用來傳資料的 Socket 是兩個,一個叫作監聽 Socket,一個叫作已連接 Socket,
連接建立成功之后,雙方開始通過 read 和 write 函式來讀寫資料,就像往一個檔案流里面寫東西一樣,
這個圖就是基于 TCP 協議的 Socket 程式函式呼叫程序,
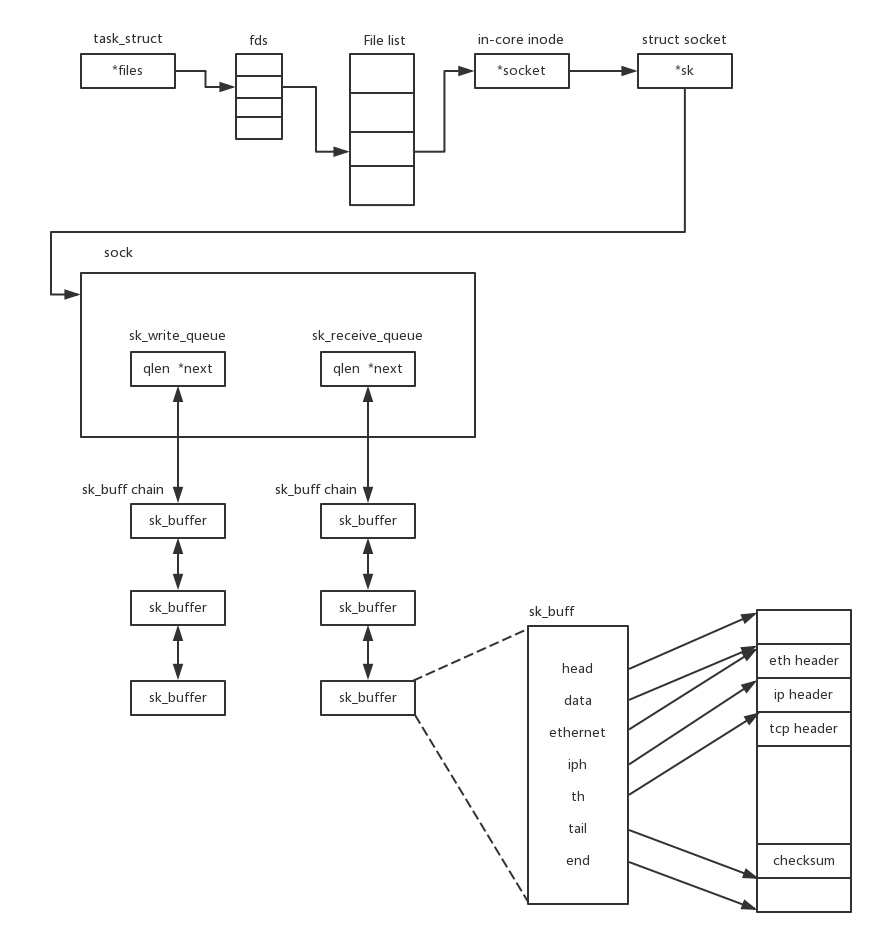
說 TCP 的 Socket 就是一個檔案流,是非常準確的,因為,Socket 在 Linux 中就是以檔案的形式存在的,除此之外,還存在檔案描述符,寫入和讀出,也是通過檔案描述符,
在內核中,Socket 是一個檔案,那對應就有檔案描述符,每一個行程都有一個資料結構 task_struct,里面指向一個檔案描述符陣列,來列出這個行程打開的所有檔案的檔案描述符,檔案描述符是一個整數,是這個陣列的下標,
這個陣列中的內容是一個指標,指向內核中所有打開的檔案的串列,既然是一個檔案,就會有一個 inode,只不過 Socket 對應的 inode 不像真正的檔案系統一樣,保存在硬碟上的,而是在記憶體中的,在這個 inode 中,指向了 Socket 在內核中的 Socket 結構,
在這個結構里面,主要的是兩個佇列,一個是發送佇列,一個是接收佇列,在這兩個佇列里面保存的是一個快取 sk_buff,這個快取里面能夠看到完整的包的結構,看到這個,是不是能和前面講過的收發包的場景聯系起來了?
整個資料結構我也畫了一張圖,
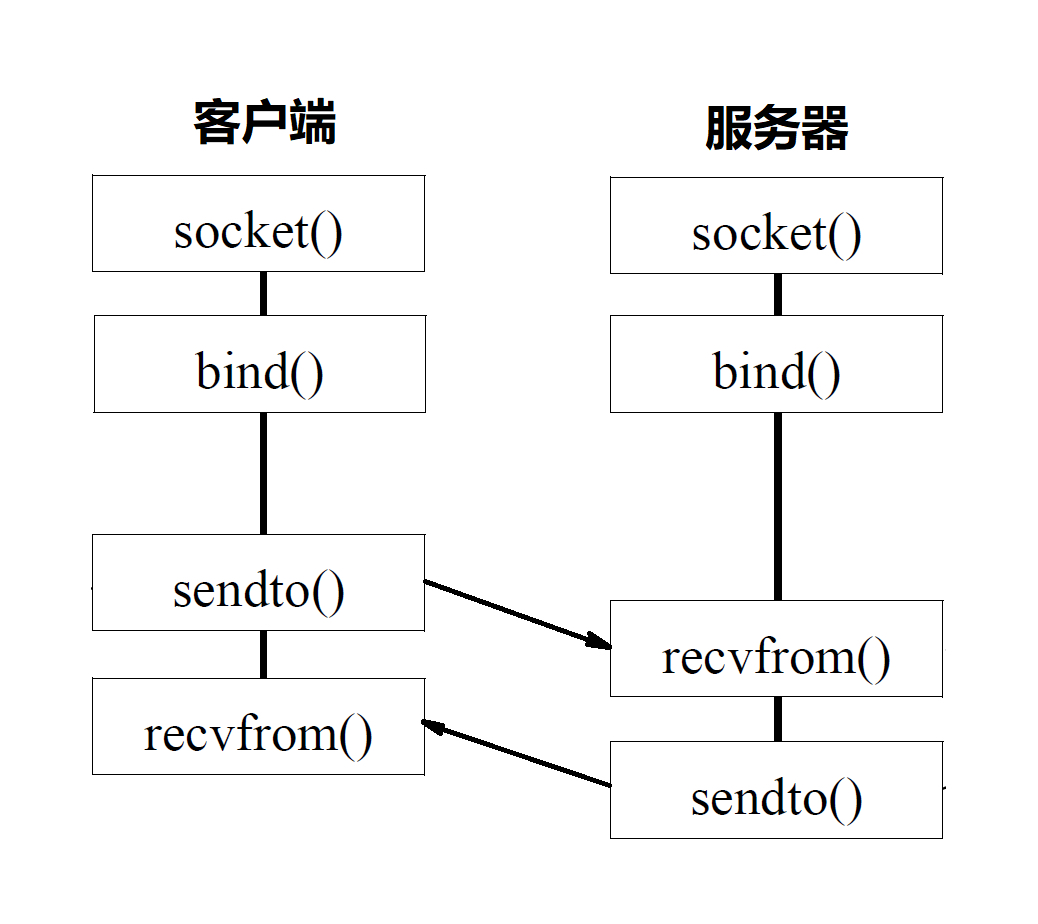
基于 UDP 協議的 Socket 程式函式呼叫程序
對于 UDP 來講,程序有些不一樣,UDP 是沒有連接的,所以不需要三次握手,也就不需要呼叫 listen 和 connect,但是,UDP 的互動仍然需要 IP 和埠號,因而也需要 bind,UDP 是沒有維護連接狀態的,因而不需要每對連接建立一組 Socket,而是只要有一個 Socket,就能夠和多個客戶端通信,也正是因為沒有連接狀態,每次通信的時候,都呼叫 sendto 和 recvfrom,都可以傳入 IP 地址和埠,
這個圖的內容就是基于 UDP 協議的 Socket 程式函式呼叫程序,
服務器如何接更多的專案?
會了這幾個基本的 Socket 函式之后,你就可以輕松地寫一個網路互動的程式了,就像上面的程序一樣,在建立連接后,進行一個 while 回圈,客戶端發了收,服務端收了發,
當然這只是萬里長征的第一步,因為如果使用這種方法,基本上只能一對一溝通,如果你是一個服務器,同時只能服務一個客戶,肯定是不行的,這就相當于老板成立一個公司,只有自己一個人,自己親自上來服務客戶,只能干完了一家再干下一家,這樣賺不來多少錢,
那作為老板你就要想了,我最多能接多少專案呢?當然是越多越好,
我們先來算一下理論值,也就是最大連接數,系統會用一個四元組來標識一個 TCP 連接,
{本機IP, 本機埠, 對端IP, 對端埠}
服務器通常固定在某個本地埠上監聽,等待客戶端的連接請求,因此,服務端端 TCP 連接四元組中只有對端 IP, 也就是客戶端的 IP 和對端的埠,也即客戶端的埠是可變的,因此,最大 TCP 連接數 = 客戶端 IP 數×客戶端埠數,對 IPv4,客戶端的 IP 數最多為 2 的 32 次方,客戶端的埠數最多為 2 的 16 次方,也就是服務端單機最大 TCP 連接數,約為 2 的 48 次方,
當然,服務端最大并發 TCP 連接數遠不能達到理論上限,首先主要是檔案描述符限制,按照上面的原理,Socket 都是檔案,所以首先要通過 ulimit 組態檔描述符的數目;另一個限制是記憶體,按上面的資料結構,每個 TCP 連接都要占用一定記憶體,作業系統是有限的,
所以,作為老板,在資源有限的情況下,要想接更多的專案,就需要降低每個專案消耗的資源數目,
方式一:將專案外包給其他公司(多行程方式)
這就相當于你是一個代理,在那里監聽來的請求,一旦建立了一個連接,就會有一個已連接 Socket,這時候你可以創建一個子行程,然后將基于已連接 Socket 的互動交給這個新的子行程來做,就像來了一個新的專案,但是專案不一定是你自己做,可以再注冊一家子公司,招點人,然后把專案轉包給這家子公司做,以后對接就交給這家子公司了,你又可以去接新的專案了,
這里有一個問題是,如何創建子公司,并如何將專案移交給子公司呢?
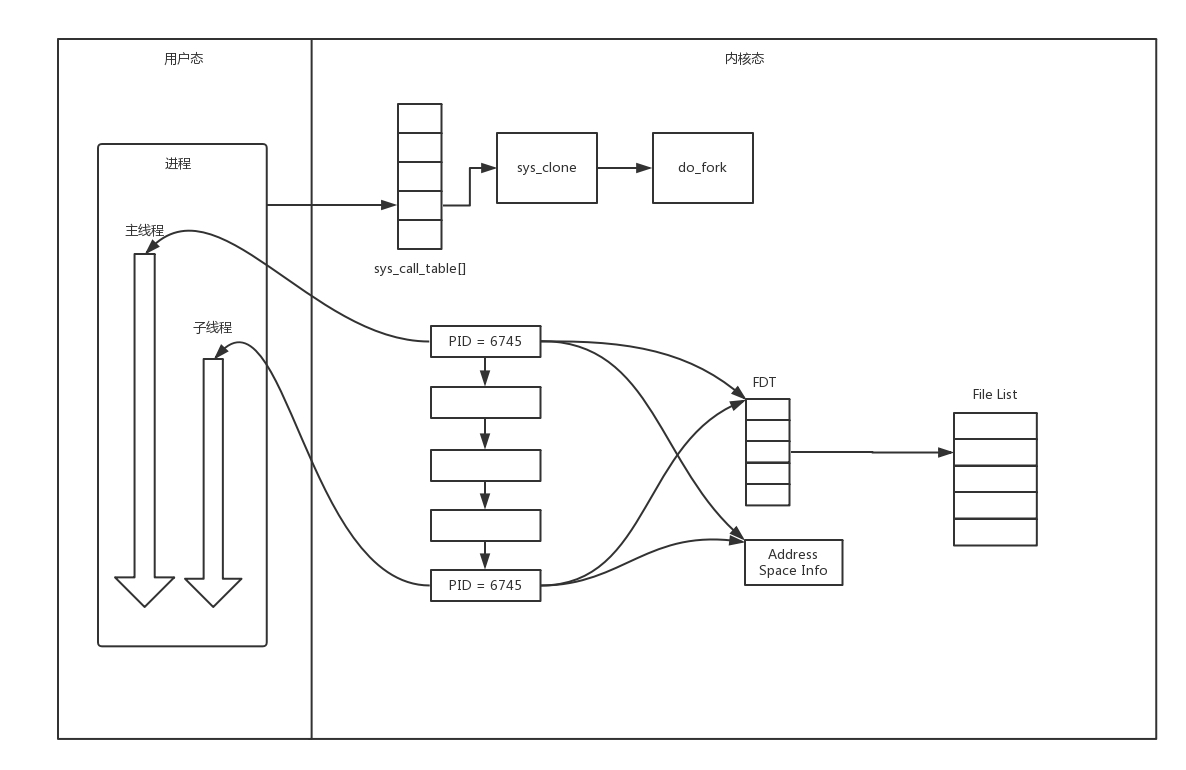
在 Linux 下,創建子行程使用 fork 函式,通過名字可以看出,這是在父行程的基礎上完全拷貝一個子行程,在 Linux 內核中,會復制檔案描述符的串列,也會復制記憶體空間,還會復制一條記錄當前執行到了哪一行程式的行程,顯然,復制的時候在呼叫 fork,復制完畢之后,父行程和子行程都會記錄當前剛剛執行完 fork,這兩個行程剛復制完的時候,幾乎一模一樣,只是根據 fork 的回傳值來區分到底是父行程,還是子行程,如果回傳值是 0,則是子行程;如果回傳值是其他的整數,就是父行程,
行程復制程序我畫在這里,
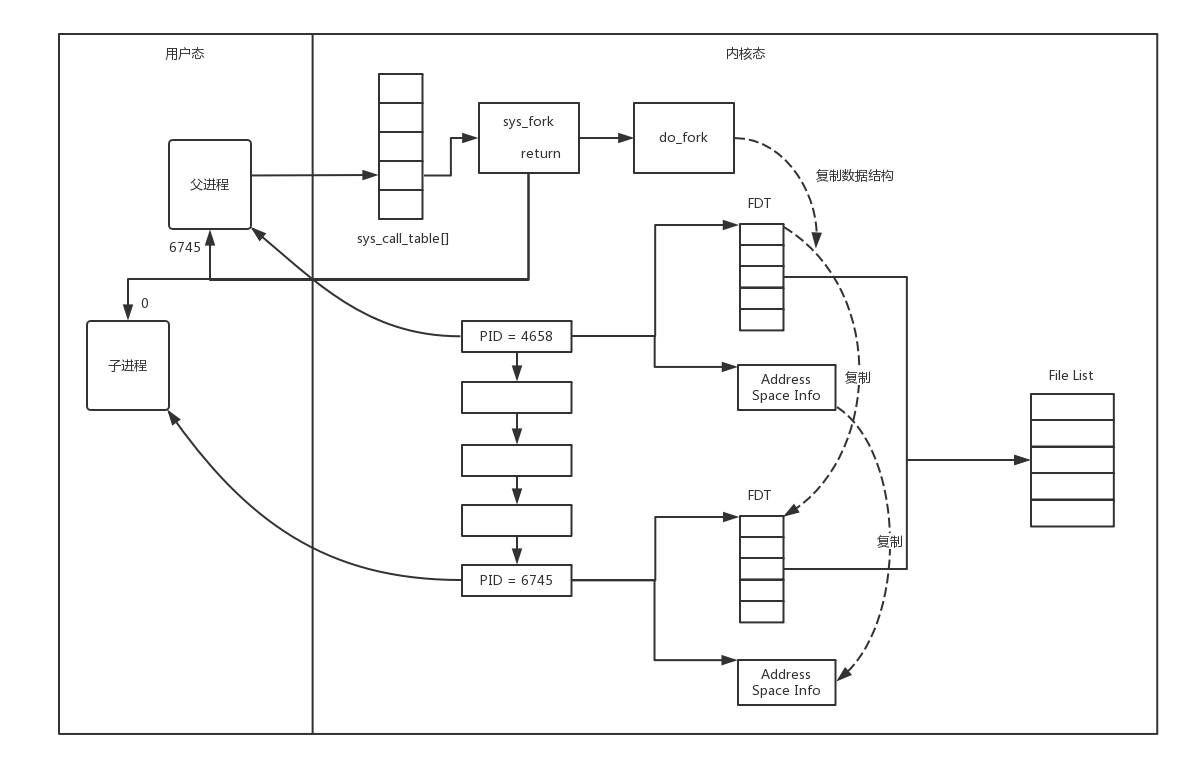
因為復制了檔案描述符串列,而檔案描述符都是指向整個內核統一的打開檔案串列的,因而父行程剛才因為 accept 創建的已連接 Socket 也是一個檔案描述符,同樣也會被子行程獲得,
接下來,子行程就可以通過這個已連接 Socket 和客戶端進行互通了,當通信完畢之后,就可以退出行程,那父行程如何知道子行程干完了專案,要退出呢?還記得 fork 回傳的時候,如果是整數就是父行程嗎?這個整數就是子行程的 ID,父行程可以通過這個 ID 查看子行程是否完成專案,是否需要退出,
方式二:將專案轉包給獨立的專案組(多執行緒方式)
上面這種方式你應該也能發現問題,如果每次接一個專案,都申請一個新公司,然后干完了,就注銷掉這個公司,實在是太麻煩了,畢竟一個新公司要有新公司的資產,有新的辦公家具,每次都買了再賣,不劃算,
于是你應該想到了,我們可以使用執行緒,相比于行程來講,這樣要輕量級的多,如果創建行程相當于成立新公司,購買新辦公家具,而創建執行緒,就相當于在同一個公司成立專案組,一個專案做完了,那這個專案組就可以解散,組成另外的專案組,辦公家具可以共用,
在 Linux 下,通過 pthread_create 創建一個執行緒,也是呼叫 do_fork,不同的是,雖然新的執行緒在 task 串列會新創建一項,但是很多資源,例如檔案描述符串列、行程空間,還是共享的,只不過多了一個參考而已,
新的執行緒也可以通過已連接 Socket 處理請求,從而達到并發處理的目的
上面基于行程或者執行緒模型的,其實還是有問題的,新到來一個 TCP 連接,就需要分配一個行程或者執行緒,一臺機器無法創建很多行程或者執行緒,有個 C10K,它的意思是一臺機器要維護 1 萬個連接,就要創建 1 萬個行程或者執行緒,那么作業系統是無法承受的,如果維持 1 億用戶在線需要 10 萬臺服務器,成本也太高了,
其實 C10K 問題就是,你接專案接的太多了,如果每個專案都成立單獨的專案組,就要招聘 10 萬人,你肯定養不起,那怎么辦呢?
方式三:一個專案組支撐多個專案(IO 多路復用,一個執行緒維護多個 Socket)
當然,一個專案組可以看多個專案了,這個時候,每個專案組都應該有個專案進度墻,將自己組看的專案列在那里,然后每天通過專案墻看每個專案的進度,一旦某個專案有了進展,就派人去盯一下,
由于 Socket 是檔案描述符,因而某個執行緒盯的所有的 Socket,都放在一個檔案描述符集合 fd_set 中,這就是專案進度墻,然后呼叫 select 函式來監聽檔案描述符集合是否有變化,一旦有變化,就會依次查看每個檔案描述符,那些發生變化的檔案描述符在 fd_set 對應的位都設為 1,表示 Socket 可讀或者可寫,從而可以進行讀寫操作,然后再呼叫 select,接著盯著下一輪的變化,
方式四:一個專案組支撐多個專案(IO 多路復用,從“派人盯著”到“有事通知”)
上面 select 函式還是有問題的,因為每次 Socket 所在的檔案描述符集合中有 Socket 發生變化的時候,都需要通過輪詢的方式,也就是需要將全部專案都過一遍的方式來查看進度,這大大影響了一個專案組能夠支撐的最大的專案數量,因而使用 select,能夠同時盯的專案數量由 FD_SETSIZE 限制,
如果改成事件通知的方式,情況就會好很多,專案組不需要通過輪詢挨個盯著這些專案,而是當專案進度發生變化的時候,主動通知專案組,然后專案組再根據專案進展情況做相應的操作,
能完成這件事情的函式叫 epoll,它在內核中的實作不是通過輪詢的方式,而是通過注冊 callback 函式的方式,當某個檔案描述符發送變化的時候,就會主動通知,
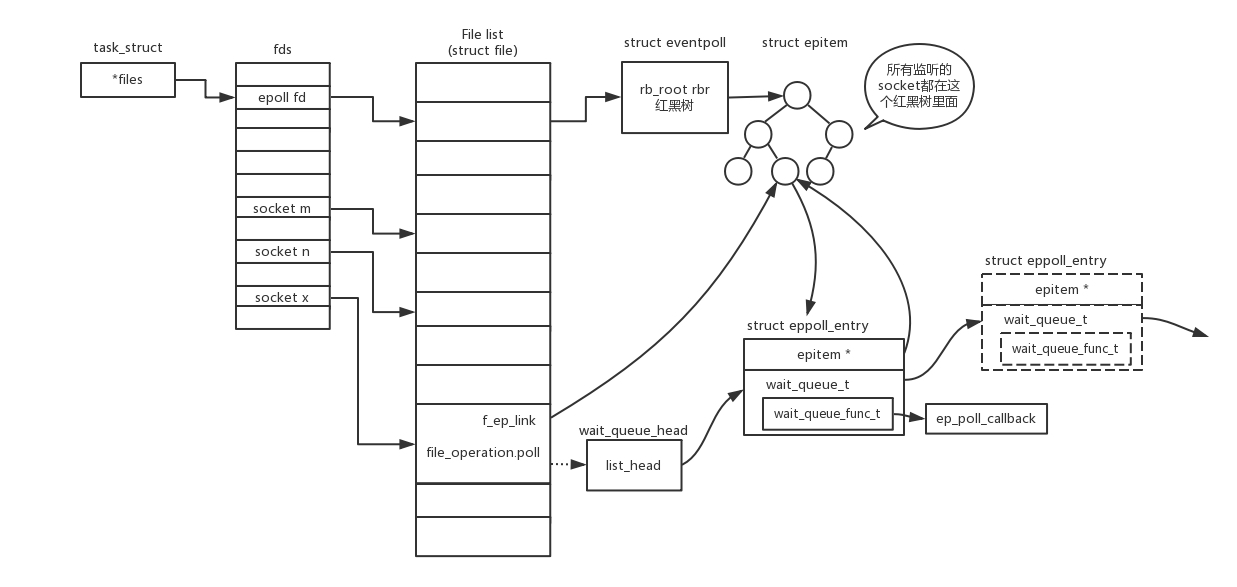
如圖所示,假設行程打開了 Socket m, n, x 等多個檔案描述符,現在需要通過 epoll 來監聽是否這些 Socket 都有事件發生,其中 epoll_create 創建一個 epoll 物件,也是一個檔案,也對應一個檔案描述符,同樣也對應著打開檔案串列中的一項,在這項里面有一個紅黑樹,在紅黑樹里,要保存這個 epoll 要監聽的所有 Socket,
當 epoll_ctl 添加一個 Socket 的時候,其實是加入這個紅黑樹,同時紅黑樹里面的節點指向一個結構,將這個結構掛在被監聽的 Socket 的事件串列中,當一個 Socket 來了一個事件的時候,可以從這個串列中得到 epoll 物件,并呼叫 call back 通知它,
這種通知方式使得監聽的 Socket 資料增加的時候,效率不會大幅度降低,能夠同時監聽的 Socket 的數目也非常的多了,上限就為系統定義的、行程打開的最大檔案描述符個數,因而,epoll 被稱為解決 C10K 問題的利器,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/172563.html
標籤:其他
下一篇:DNS作業原理