一.梯度下降
梯度下降就是最簡單的用于神經網路當中用于更新引數的用法,計算loss的公式如下:
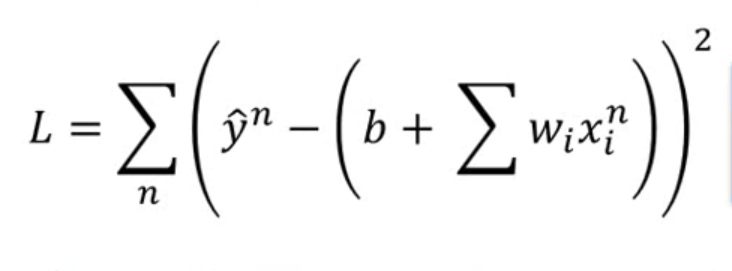
有了loss function之后,我們立馬通過這個loss求解出梯度,并將梯度用于引數theta的更新,如下所示:
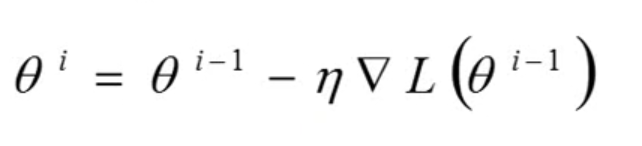
這樣做之后,我們只需要遍歷所有的樣本,就可以得到一個最終的引數theta了,這個引數可能是全域最小值,也可能不是,因為很有可能走入了一個loss的區域最小值當中,
二.隨機梯度下降(SGD)
隨機梯度下降與梯度下降相比,其實也會遍歷全部的樣本,但是只會梯度在遍歷同樣樣本數量的情況下會下降得更快,因為我們首先將全部樣本切分成m個樣本,然后對這m個樣本進行遍歷,更新引數,用一個一個切分后的樣本更新完引數之后,保留目前的theta的值,基于這個theta的值,繼續用下一個樣本進行引數theta的優化,
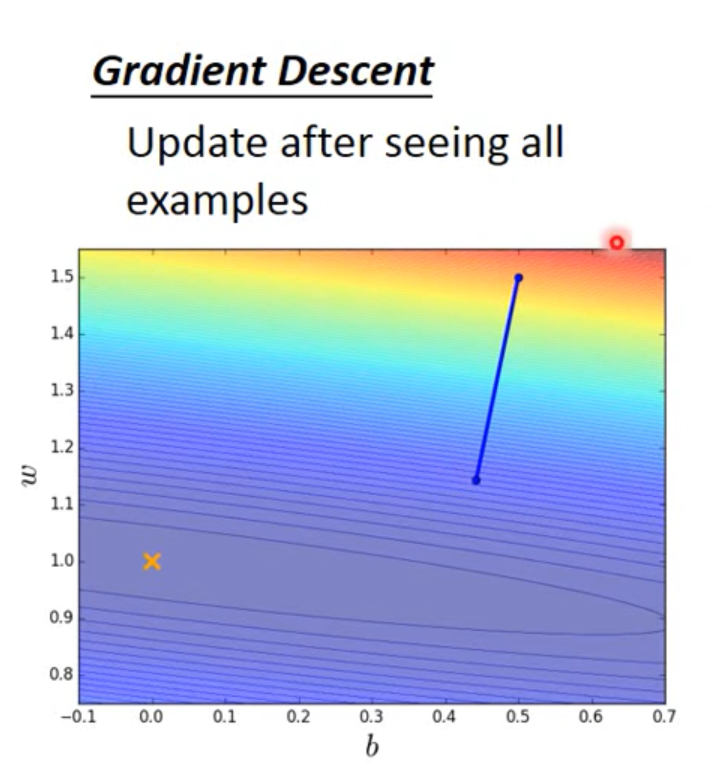
下面是梯度下降的loss在影像當中的表示:
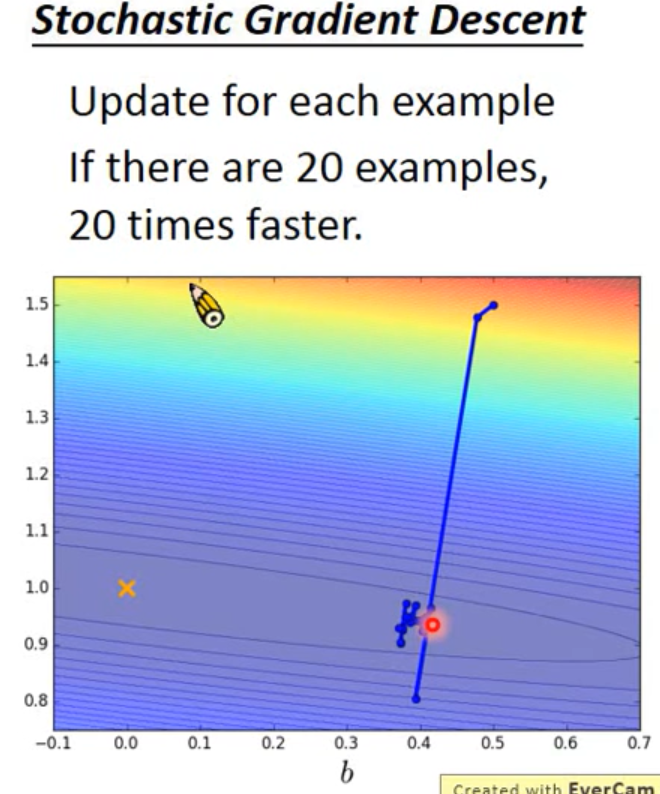
這是SGD,將樣本進行切分之后的loss的變化:
三.mini-batch梯度下降
mini-batch和SGD稍微有點不同,那就是mini-batch每次進行引數更新的同時,使用了多個樣本繼續引數的更新,loss下降的速度會比SGD更慢,但是結果回避SGD更加準確,
這就是我們常用的用于梯度下降的方法啦!希望大家有所識訓,有疑問的話可以在下方的疑問區提出!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/173537.html
標籤:其他
上一篇:知識圖譜介紹
下一篇:Mask R-CNN