什么是正則運算式?
簡單地說,正則運算式就是處理字串的方法,它以行為單位來進行字串的處理操作,正則運算式通過一些特殊符號的輔助,可以讓用戶輕易地完成【查找、洗掉、替換】某特定字串的處理程序,
正則運算式基本上是一種**【表示法】**,只要程式支持這種表示法,那么該程式就可以用來作為正則運算式的字串處理,
正則運算式的字串表示方式依照不同的嚴謹度分為:基礎正則運算式、擴展正則運算式,
用途:郵件服務器
注意:正則運算式與通配符是完全不一樣的東西,因為【通配符代表的是bash操作介面的一個功能】,但是正則運算式則是一種字串處理的方式,使用正則運算式的時候,需要特別注意當時環境的語系,否則可能會發現選取的結果不合人意,
一、基礎正則運算式
1、符號的含義
“ [:alnum:] ”代表英文大小寫字符及數字,亦即 0 ~ 9、A ~ Z、a ~ z
“ [:alpha:] ”代表任何英文大小寫字符,亦即 A ~ Z、a ~ z
“ [:blank:] ”代表空格鍵與[Tab]鍵
“ [:cntrl:] ”代表鍵盤上面 控制鍵,包括CR、LF、Tab、Del
“ [:digit:] ”代表數字,亦即 0 ~ 9
“ [:graph:] ”代表空格符以外的所有按鍵
“ [:lower:] ”代表英文小寫字符,亦即 a ~ z
“ [:print:] ”代表任何可以被列印出來的字符
“ [:punct:] ”代表標點字符,亦即 " ’ ? ! ; : # $
“ [:upper:] ”代表英文大寫字符,亦即 A ~ Z
“ [:space:] ”代表任何會產生的空白的字符,包括空格、Tab鍵、CR等
“ [:xdigit:] ”代表十六進制的數字型別
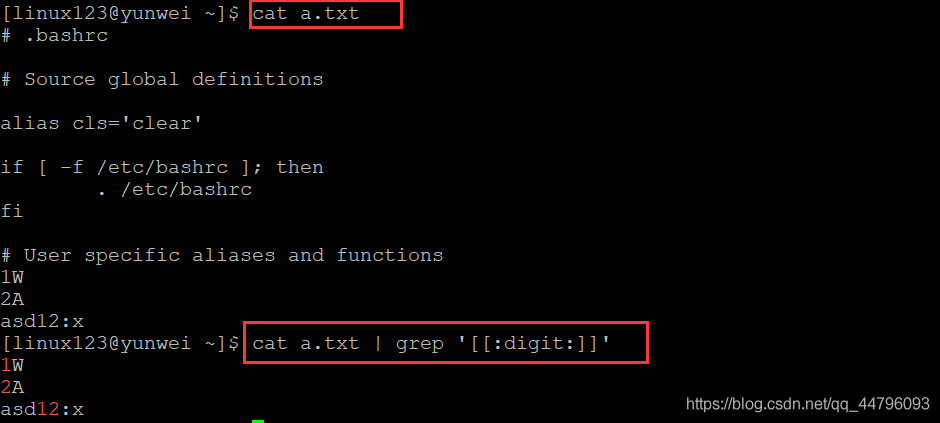
案例一:查看a.txt檔案中所有含有數字的行
語法:cat a.txt | grep '[[:digit:]]'
2、行首字符 ’ ^ ’ 與行為字符 ’ $ ',“ ^ ”在字符集合符號([ ])中是表示反向,在外面表示定位在行首的意思
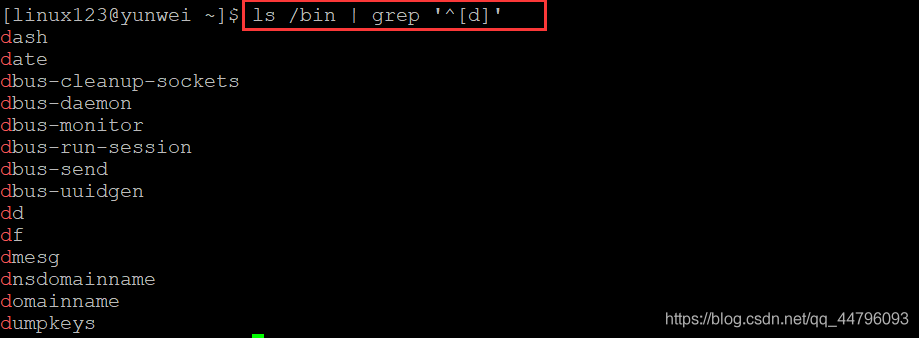
案例二:列出 /bin 目錄下所有以d開頭的檔案
3、任意一個字符
“ . ”表示【一定有一個任意字符】
“ * ”表示【重復前一個字符0次或N次】
注意:【.*代表零個或者多個任意字符】
案例三:獲取 /bin 目錄下以a開頭h結尾且位數為四位的目錄
語法:ls /bin | grep '^a…h$'

案例四:獲取 /bin 目錄下最少含有兩個連續ee的目錄
語法:ls /bin | grep ‘eee*’

4、限定連續RE字符范圍{}
如果想要限制次數獲取的范圍,可以使用{},但是因為 { 和 } 在shell中是有特殊意義的,所有需要轉義符 \ 來使它們有意義,
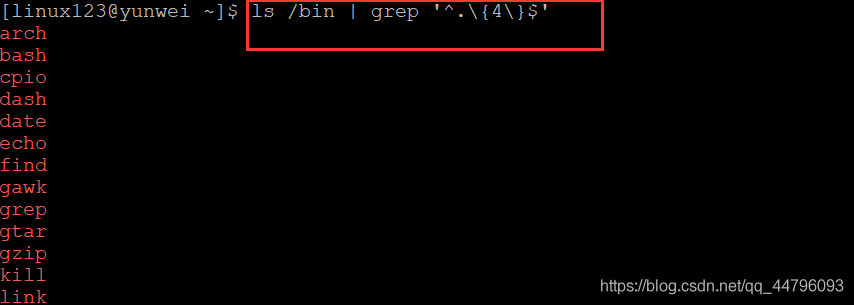
案例五:獲取 /bin 目錄下含有四個字符的目錄
語法:ls | grep '^.{4} $'
5、sed工具(重點)
當我們分析日志檔案的時候,絕大部分需要分析關鍵詞的使用、統計等,可以使用sed工具來實作,sed本身也是一個管道命令,可以分析標準輸入,而且sed還可以將資料進行替換、洗掉、新增、選取特定行等功能,
語法:sed [-nefr] [操作]
“ -n ”表示只有經過sed特殊處理的那一行才會被列出
“ -e ”表示直接在命令列模式上進行sed的操作編輯
“ -f ”表示直接將sed的操作卸載一個檔案內
“ -r ”表示使用擴展性正則運算式(默認是基礎正則運算式)
操作說明: [n1,n2] function
“ n1,n2 表示行號 ”
“ a ”表示新增,后面可以接字符,這些字符會顯示在新的一行
“ c ”表示替換,后面接字符,這些字符會替換n1,n2之間的行
“ d ”表示洗掉
“ i ”表示插入,后面接字符,這些字符會在新的一行出現
“ p ”表示列印
“ s ”表示可以直接進行替換操作
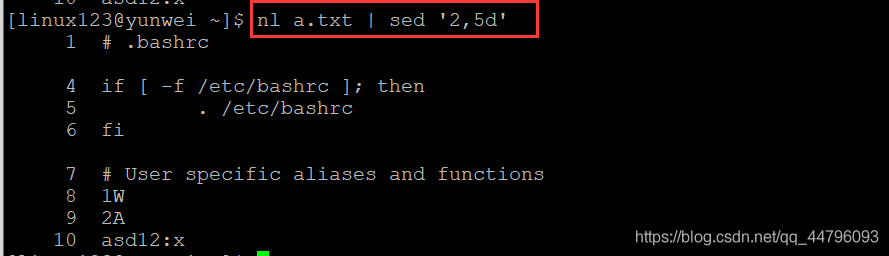
案例六:列出a.txt檔案并列印行號,同時洗掉2-5行的內容
 如果需要洗掉第3行開始到最后一行,可以使用 nl a.txt | sed '3,
d
′
,
d',
d′, 表示最后一行
如果需要洗掉第3行開始到最后一行,可以使用 nl a.txt | sed '3,
d
′
,
d',
d′, 表示最后一行
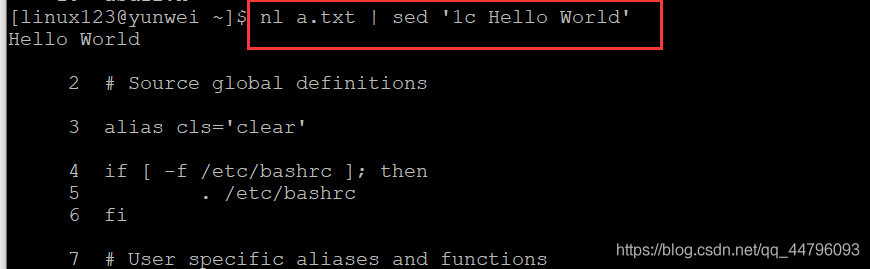
案例七:替換a.txt檔案中第一行的內容為Hello World
語法:nl a.txt | sed '1c Hello World’
部分資料的查找并替換的功能(重點):
語法:sed 's/要被替換的字符/新的字符/g’
案例八:獲取 /etc/man_db.conf 中MAN存在的幾條資料,但是含義#在內的注釋不
要,而且空白行不要
語法:*cat /etc/man_db.conf | grep ‘MAN’ | sed '/#.s//g’ | sed ‘/^$/d’
二、擴展正則運算式
符號含義
“ + ”表示重復【一個或一個以上】的前一個RE字符
“ ? ”表示【零個或一個】前一個RE字符
“ | ”表示【或(or)的方式找出字串】
“ () ”表示找出【群組】字串
“ ()+ ”表示多個重復群組的判別
三、檔案的格式化與相關處理
1、格式化列印
語法:printf ‘列印內容’ 實際內容
特殊格式:
“ \a ”表示警告聲音輸出
“ \b ”表示退格鍵
“ \f ”表示清除螢屏
“ \n ”表示輸出新的一行
“ \r ”表示回車按鍵
“ \t ”表示水平的tab鍵
“ \v ”表示垂直的tab鍵
“ \xNN ”表示NN為兩位數,可以轉換數字成字符
2、資料處理工具:awk
sed常常用于一整行的處理,awk更傾向于一行當中分成數個欄位來處理,awk主要處理每一行的欄位內的資料(欄位為最小的處理單位),而默認的欄位的分隔符為空格鍵或者Tab鍵,
語法:awk ‘條件型別1{操作1} 條件型別2{操作2}’
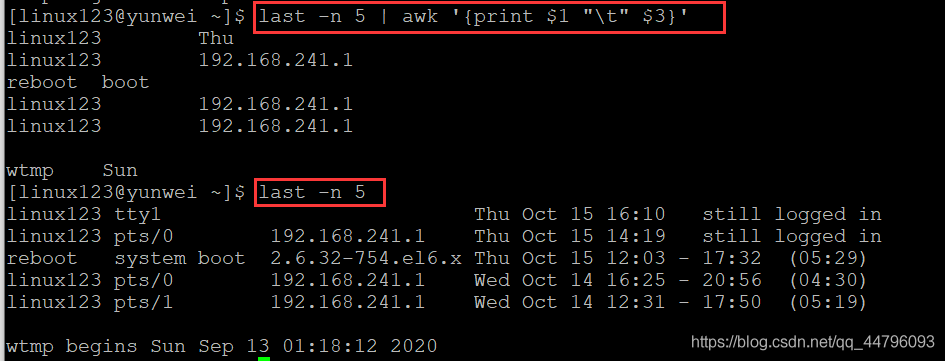
案例九:列出最后5位登錄用戶并列印出第一個、第三個欄位
語法:last -n 5 | awk ‘{print $1 “\t” $3}’
四、檔案比對工具
1、比對兩個檔案之間的差距
語法:diff [-bBi] 檔案1 檔案2
“ -b ”表示忽略一行當中,僅有多個空白的差異
“ -B ”忽略空白行的差異
“ -i ”忽略大小寫
 “ 12,14d11 ”表示左邊第12,14行被洗掉(d)掉了,基準是右邊的第11行
“ 12,14d11 ”表示左邊第12,14行被洗掉(d)掉了,基準是右邊的第11行
“ < ”表示左邊的內容
“ > ”表示右邊的內容
2、cmp(主要用于對比檔案,主要利用位元組單位對比,也可以對比二進制檔案)
語法:cmp 檔案1 檔案2

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/177084.html
標籤:其他
下一篇:NS-3安裝配置