參考文獻 :《資訊奧賽一本通》,《演算法競賽進階指南》
根據一位大佬模仿下排版....
介紹:
字典樹也叫做Trie或者字母樹,指的是某個字串集合,如{AAA,AAG,T.TCA,TG}這樣的
集合對應的形的有根樹,用圖片解釋食用更香:
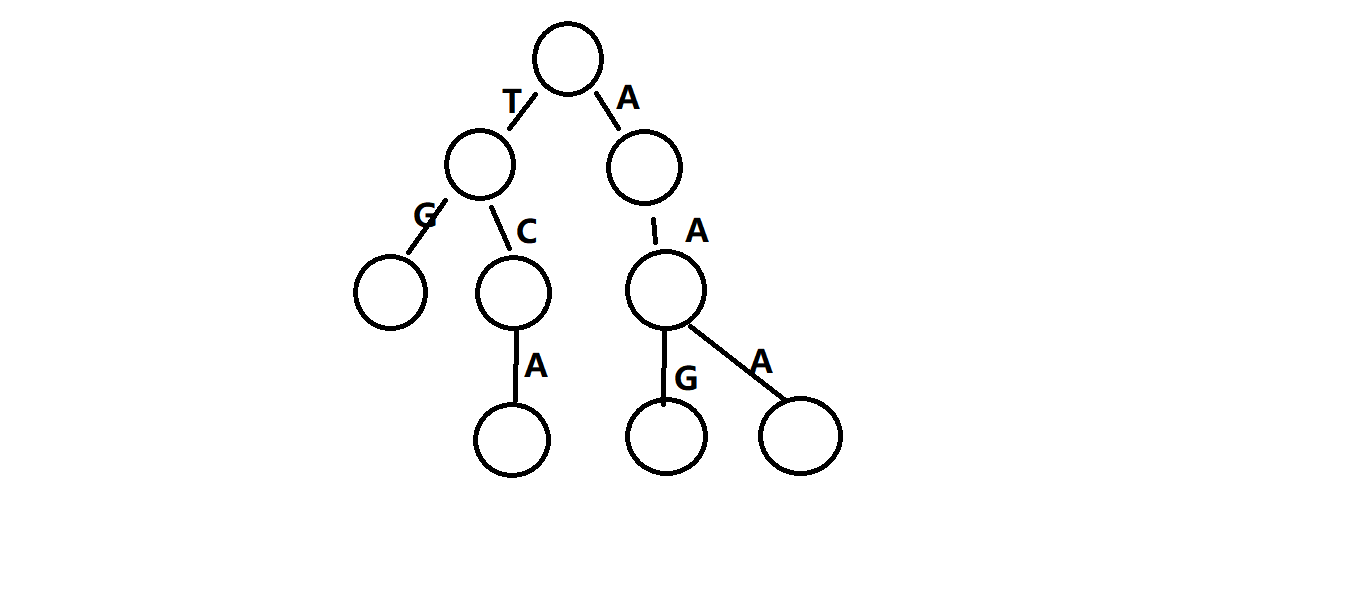
每個頂點代表從根到該節點所對應的字串,就是從根到這個節點的子符全部串在一起,
所以我們也叫Trie上的邊叫做轉移,頂點為狀態,
頂點上還能存盤額外資訊,如下
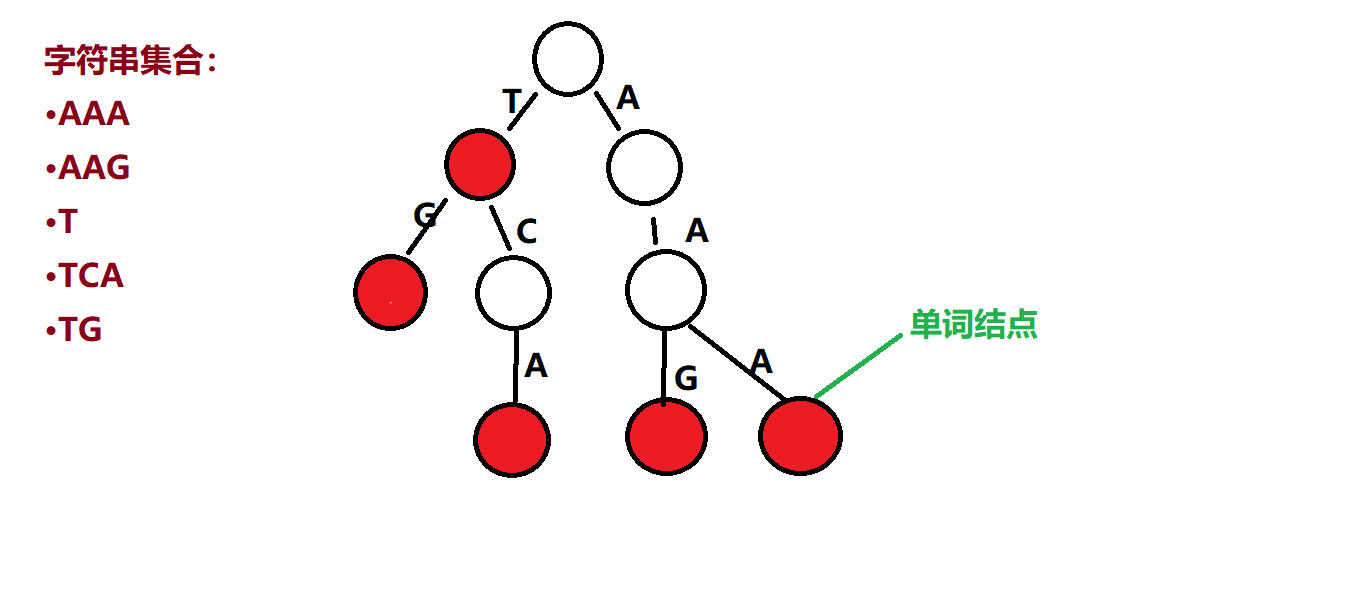
這些從根到這些標紅點組成的字串都是集合中的元素,所以叫他們為單詞節點(結==節,懶得改了)
還有,任意一個線節點代表的字串,都是這些實際字串中某些串的前綴,specially,根節點表示空串,
任意一節點,到子節點邊上字符都不同,這就是利用了串的公共前綴,如TG與TCA公共前綴為T....
本質上它就是通過空間去換取時間,
操作
1.初始化:
一棵空的Trie只剩下一個根節點,它的字符指標指向空,顯然,
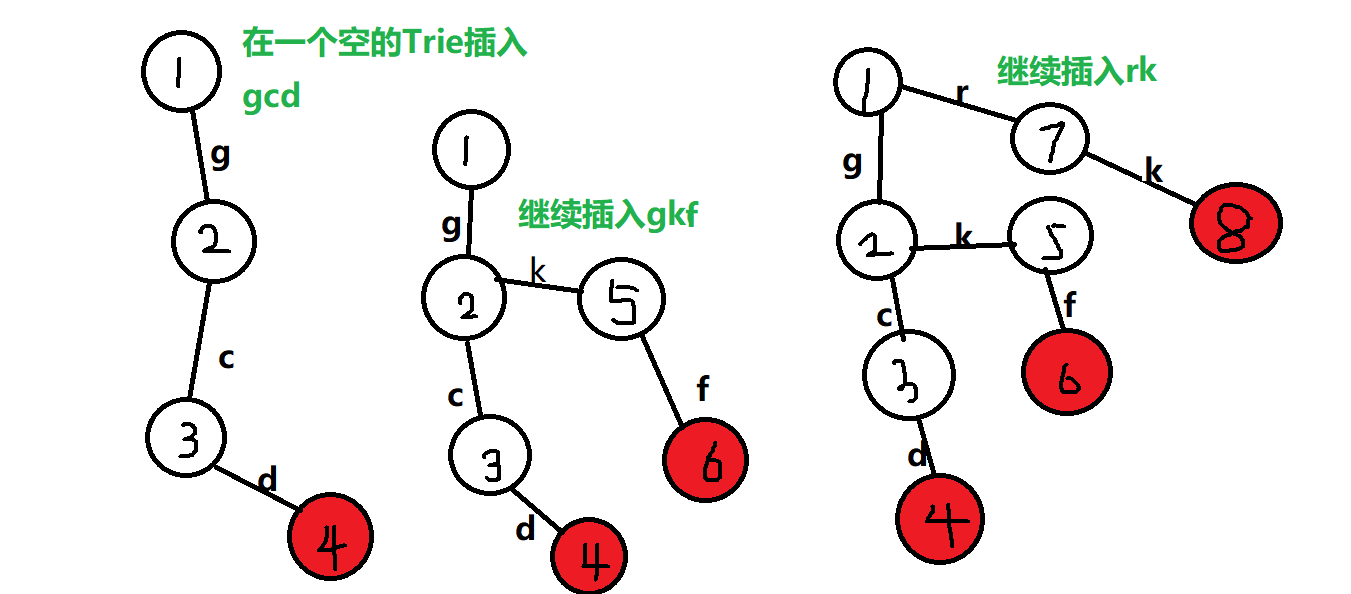
2.插入操作
當我們需要插入一個字串s時,我們讓一個指標P先指向根節點,然后依次掃描s中的每個字符x:
若P的x字符指標指向一個已經存在的節點A,則讓P = A;
若P的x字符指標指向空,就是原來不存在這個字符的連接節點,那就得給它構造一個節點,再讓P的x字符指標指向A,最后讓P=A;
當s字符全部掃描完畢,就在當前節點P標記它是末尾,
long trie[MAXN][26],tot=1;//初始化,且假定字串全
bool end[MAXN]; //由小寫字母構成
inline void insert(char* s){
long len=strlen(s),p=1;
for(long i=0;i<len;i++){
long ch=s[i]-'a';
if(trie[p][ch]==0) trie[p][ch]=++tot;
p=trie[p][ch];
}
end[p]=1;
}
3.查詢操作
當我們需要查詢時,我們就先讓一個指標P指向根結點,再依次掃描s中每一個字符x:
若P的x字符指標指向空,那就是沒找到嘛,所以就干脆不找下去了,前綴都不一樣找下去沒啥意思,
若P的x字符指標指向一個已經存在的節點A,那就是還能有,于是讓P=A;
當s掃描一遍后,若發現當前P被標記在一個字串的末尾,則說明s是在這棵字典樹是存在的,反之則說明s沒在里面,
bool search(char* s){
long len=strlen(s),p=1;
for(long i=0;i<len;i++){
p=trie[p][s[i]-'a'];
if(p==0) return 0;//只要指向下一個為空,那就是沒有了
}
reuturn end[p];//不能直接判1,因為可能這只是某個字
//符串的前綴而已
}
~~~字符資料都體現在邊上,節點只是保留額外資訊,空間復雜度為O(NC),N為節點數,C為字符集大小,
其余的只能多刷刷題
kmp和trie只是為了給AC自動機打基礎
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/17880.html
標籤:其他
上一篇:Arctan的快速近似演算法