作者|PURVA HUILGOL
編譯|VK
來源|Analytics Vidhya
介紹
我們正站在語言和機器的交匯處,這個話題我很感興趣,機器能像莎士比亞一樣寫作嗎?機器能提高我自己的寫作能力嗎?機器人能解釋一句諷刺的話嗎?
我肯定你以前問過這些問題,自然語言處理(NLP)也致力于回答這些問題,我必須說,在這個領域已經進行了突破性的研究,促使彌合人類和機器之間的鴻溝,

文本分類是自然語言處理的核心思想之一,如果一臺機器能夠區分名詞和動詞,或者它能夠在客戶的評論中檢測到客戶對產品的滿意程度,我們可以將這種理解用于其他高級NLP任務,
這就是我們在文本分類方面看到很多研究的本質,遷移學習的出現可能促進加速研究,我們現在可以使用構建在一個巨大的資料集上的預訓練的模型,并進行優化,以在另一個資料集上實作其他任務,
遷移學習和預訓練模型有兩大優勢:
-
它降低了每次訓練一個新的深度學習模型的成本
-
這些資料集符合行業公認的標準,因此預訓練模型已經在質量方面得到了審查
你可以理解為什么經過預訓練的模特會大受歡迎,我們已經看到像谷歌的BERT和OpenAI的GPT-2這樣的模型真的很厲害,在這里中,我將介紹6種最先進的文本分類預訓練模型,
我們將介紹的預訓練模型:
-
XLNet
-
ERNIE
-
Text-to-Text Transfer Transformer(T5)
-
BPT
-
NABoE
-
Rethinking Complex Neural Network Architectures for Document Classification
預訓練模型1:XLNet
我們不能不提及XLNet!
谷歌的最新模型XLNet在文本分類,情感分析,問答,自然語言推理等主要NLP任務上取得了最先進的性能,同時還為英語提供了必要的GLUE基準,它的性能超過了BERT,現在已經鞏固了自己作為模型的優勢,既可以用于文本分類,又可以用作高級NLP任務,
XLNet背后的核心思想是:
-
語言理解的廣義自回歸預訓練
-
Transformer-XL
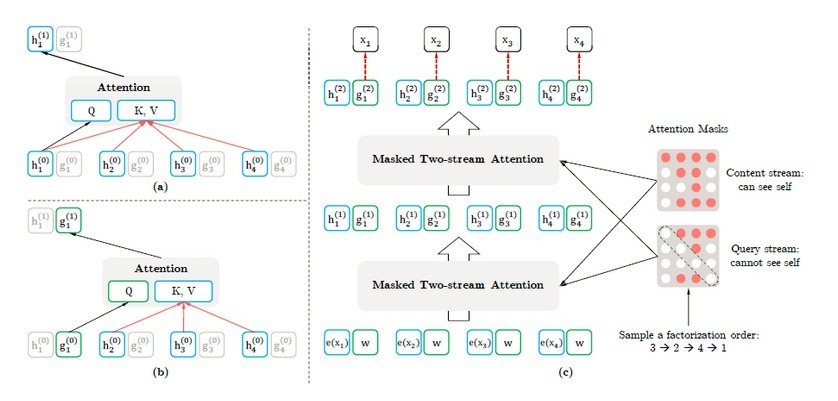
如果這聽起來很復雜,別擔心!我要把這些簡化,
自回歸模型用于預測下一個單詞,使用的單詞在已有的單詞之前或之后出現,但是,不能同時處理前面和后面的單詞,只能處理一個方向,
雖然BERT確實處理了這方面的問題,但它也有其他缺點,比如假設某些屏蔽詞之間沒有相關性,為了解決這個問題,XLNet在訓練前階段提出了一種稱為排列語言模型(Permutation Language Modeling)的技術,這項技術使用排列同時從正向和反向生成資訊,
Transformer已經不是什么秘密了,XLNet使用Transformer-XL,眾所周知,在允許不相鄰的標記也一起處理的意義上,Transformer是回圈神經網路(RNN)的替代,因為它提高了對文本中遠距離關系的理解,
Transformer-XL是BERT中使用的Transformer的增強版本,因為添加了這兩個組件,:
-
句段層級的回圈
-
相對位置編碼方案
正如我前面提到的,XLNet在幾乎所有任務上都超越BERT,包括文本分類,并且在其中18個任務上實作了SOTA性能!
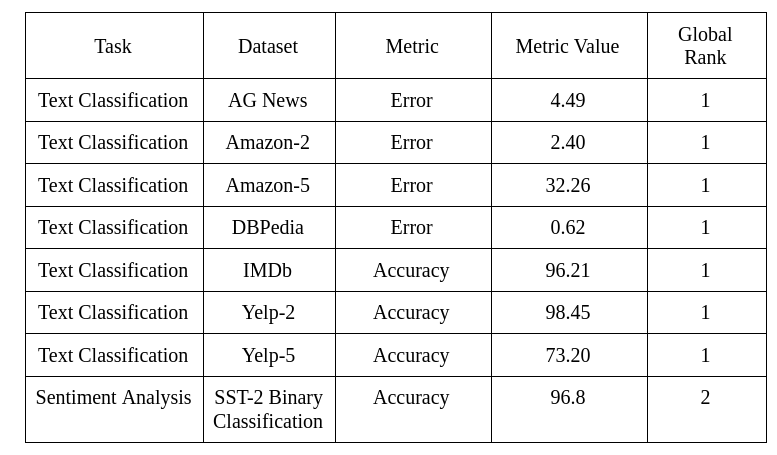
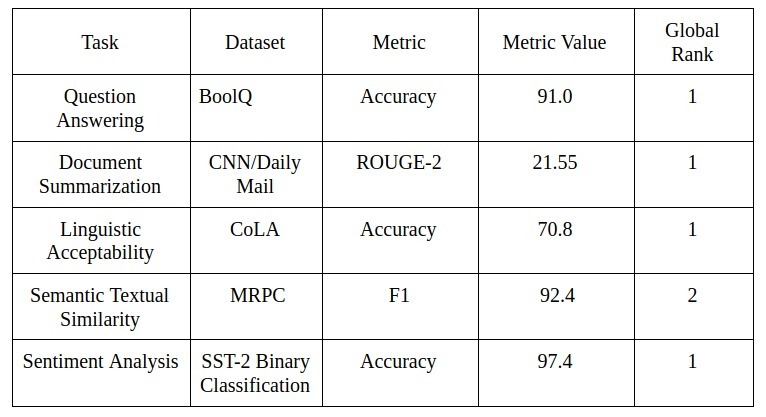
以下是文本分類任務的摘要,以及XLNet如何在這些不同的資料集上執行,以及它在這些資料集上實作的高排名:
預訓練模型2:ERNIE
盡管ERNIE 1.0(于2019年3月發布)一直是文本分類的流行模式,但在2019年下半年,ERNIE 2.0成為熱門話題,由科技巨頭百度(Baidu)開發的ERNIE在英語GLUE基準上的表現超過了Google XLNet和BERT,
ERNIE 1.0以自己的方式開辟了道路——它是最早利用知識圖的模型之一,這一合并進一步加強了對高級任務(如關系分類和名稱識別)模型的訓練,
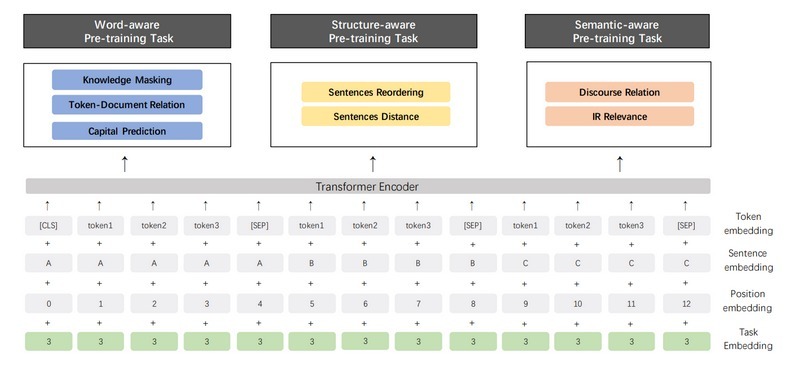
與它的前身一樣,ERNIE 2.0以連續增量多任務學習的形式帶來了另一項創新,基本上,這意味著模型定義了7個明確的任務,并且
-
可以同時生成多個任務的輸出,例如,完成“I like going to New …”->“I like going to New York”這句話,并將這句話歸類為有積極的情緒,對于合并的任務,也相應地計算損失
-
將上一個任務的輸出增量地用于下一個任務,例如,任務1的輸出用作任務1、任務2的訓練;任務1和任務2的輸出用于訓練任務1、2和3等等
我真的很喜歡這個程序,他非常直觀,因為它遵循人類理解文本的方式,我們的大腦不僅認為“I like going to New York"是一個積極的句子,它也同時理解名詞“New York”和“I”,理解動詞“like”,并推斷紐約是一個地方,
ERNIE在關系抽取任務中的 F1度量為88.32,
預訓練模型3:Text-to-Text Transfer Transformer(T5)
老實說,與其他模型相比,我在學習這個模型上獲得了最大的樂趣,Google的Text-to-Text Transfer Transformer(T5)模型將遷移學習用于各種NLP任務,
最有趣的部分是它將每個問題轉換為文本輸入—文本輸出模型,所以,即使對于分類任務,輸入是文本,輸出也將是文本而不是一個標簽,這可以歸結為所有任務的單一模型,不僅如此,一個任務的輸出可以用作下一個任務的輸入,
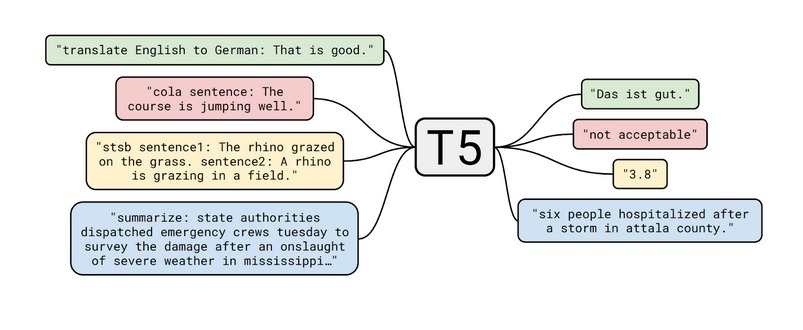
該語料庫使用了Common Crawls的增強版本,這基本上是從網上刮來的文字,本文實際上強調了清理資料的重要性,并清楚地說明了這是如何做到的,雖然收集到的資料每月產生20TB的資料,但這些資料中的大多數并不適合NLP任務,
即使只保留文本內容(包含標記、代碼內容等的頁面已被洗掉),該語料庫的大小仍高達750GB,遠遠大于大多數資料集,
注意:這已經在TensorFlow上發布了:https://www.tensorflow.org/datasets/catalog/c4,
將要執行的任務與輸入一起編碼為前綴,如上圖所示,無論是分類任務還是回歸任務,T5模型仍會生成新文本以獲取輸出,
T5在20多個已建立的NLP任務上實作了SOTA——這是很少見的,而且從度量標準來看,它盡可能接近人類的輸出,
T5模型跟蹤了最近關于未標記資料的訓練趨勢,然后在標記文本上微調該模型,可以理解的是,這個模型是巨大的,但是我們很有興趣看到進一步研究如何縮小這種模型的規模,以獲得更廣泛的使用和分布,
預訓練模型4:BPT
正如我們目前所看到的,Transformer架構在NLP研究中非常流行,BP Transformer再次使用了Transformer,或者更確切地說是它的一個增強版本,用于文本分類、機器翻譯等,
然而,使用Transformer仍然是一個昂貴的程序,因為它使用自我注意機制,自我注意只是指我們對句子本身進行注意操作,而不是兩個不同的句子,自我注意有助于識別句子中單詞之間的關系,正是這種自我關注機制導致了使用Transformer的成本,
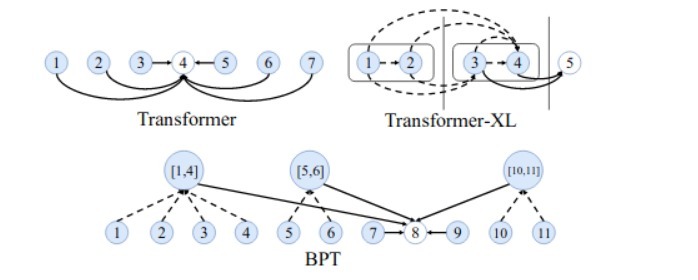
Binary-Partitioning Transformer (BPT)將Transformer看作一個圖形神經網路,旨在提高自注意力機制的效率,實際上,此圖中的每個節點都表示一個輸入標記,
BP Transformer的作業原理:
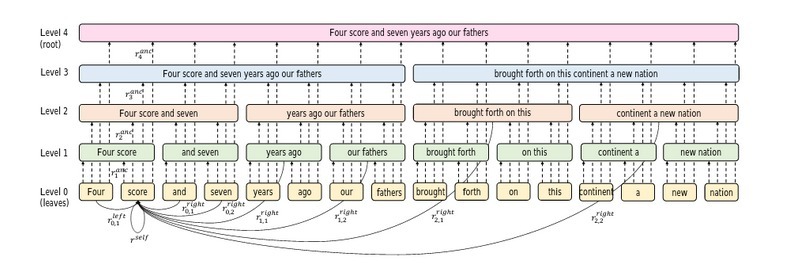
第一步:遞回地把句子分成兩部分,直到達到某個停止條件為止,這稱為二元磁區,因此,例如,“I like going to New York”這句話將有以下幾個部分:
- I like going; to New York
- I like; going; to New; York
- I; like; going; to; New; York
注意:一個包含n個單詞的句子將有2*n–1個磁區,最后,你將得到一個完整的二叉樹,
第二步:現在每個磁區都是圖神經網路中的一個節點,可以有兩種型別的邊:
- 連接父節點及其子節點的邊
- 連接葉節點與其他節點的邊
第三步:對圖的每個節點及其相鄰節點執行自注意:
BPT實作了:
- 在中英機器翻譯上達到了SOTA的成績(BLEU評分:19.84)
- IMDb資料集情緒分析的準確率為92.12(結合GloVE embedding)
我很欣賞這個模型,因為它使我重新審視了圖的概念,并使我敢于研究圖神經網路,我肯定會在不久的將來探索更多的圖形神經網路!
預訓練模型 5:NABoE
神經網路一直是NLP任務最受歡迎的模型,并且其性能優于更傳統的模型,此外,在從語料庫建立知識庫的同時用單詞替換物體可以改善模型學習,
這意味著,我們不是使用語料庫中的單詞來構建詞匯表,而是使用物體鏈接來構建大量物體,雖然已有研究將語料庫表示為模型,但NABoE模型更進一步:
- 使用神經網路檢測物體
- 使用注意力機制來計算被檢測物體的權重(這決定了這些物體與檔案的相關性)
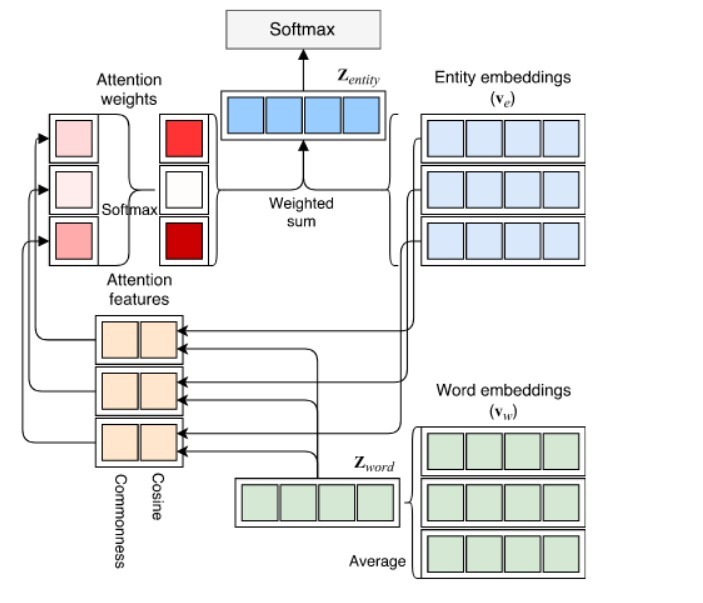
物體模型的神經注意包使用Wikipedia語料庫來檢測與單詞相關的物體,例如,單詞“Apple”可以指水果、公司和其他可能的物體,檢索所有這些物體后,使用基于softmax的注意力函式計算每個物體的權重,這提供了只與特定檔案相關的物體的一個更小的子集,
最后,通過向量嵌入和與詞相關的物體的向量嵌入,給出了詞的最終表示,
NABoE模型在文本分類任務中表現得特別好:
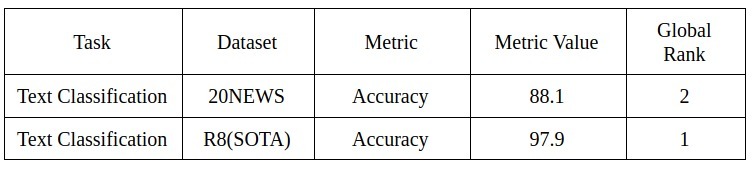
預訓練模型6:Rethinking Complex Neural Network Architectures for Document Classification
現在,在研究了這么多的高級的預訓練模型之后,我們要反其道而行之,我們要討論一個使用老的雙向LSTM的模型來實作SOTA性能,但這正是我最后決定介紹它的原因,
我們常常因為幾棵樹木而錯過森林,我們往往忘記,一個簡單的調優的模型可能會獲得與這些復雜的深度學習模型一樣好的結果,本文的目的就是要說明這一點,
雙向LSTM和正則化的組合能夠在IMDb檔案分類任務上實作SOTA的性能,
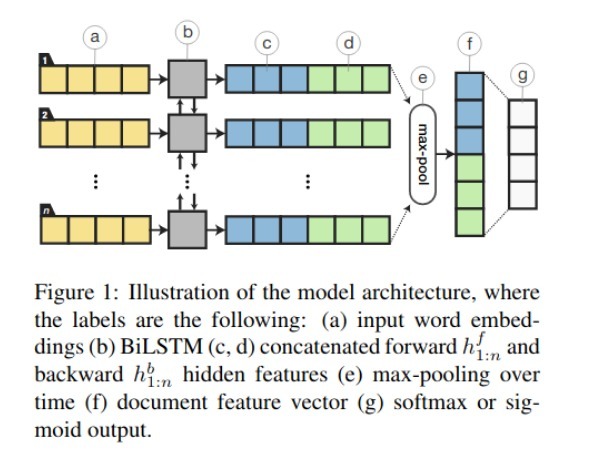
本文最有趣和值得注意的方面是:
- 它不使用注意力機制
- 這是第一篇使用LSTM +正則化技術進行檔案分類的論文
這個簡約的模型使用Adam優化器,temporal averaging和dropouts來達到這個高分,本文將這些結果與其他深度學習模型進行了實證比較,證明了該模型簡單有效,并且結果說明了一切:
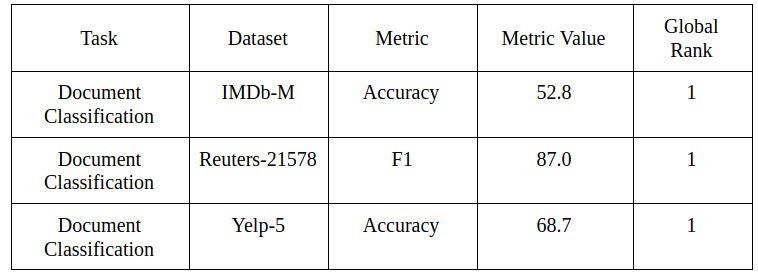
對于行業而言,這種模型可以被認為是一種新穎的方法,在該行業中,構建可用于生產的模型并且在指標上取得高分非常重要,
結尾
在這里,我們討論了最近在文本分類中達到最新基準的6種預訓練模型,這些NLP模型表明還有更多的模型,我將期待今年學習它們,
所有這些研究中的一個令人敬畏的要素是這些預訓練模型的可用性和開源性質,以上所有模型都有一個GitHub存盤庫,可以用于實作,另一個不可忽視的方面是它們在PyTorch上也可用,這強調了PyTorch正在快速取代TensorFlow作為構建深度學習模型的平臺,
我鼓勵你在各種資料集上嘗試這些模型,并進行實驗以了解它們的作業原理,
原文鏈接:https://www.analyticsvidhya.com/blog/2020/03/6-pretrained-models-text-classification/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/18184.html
標籤:其他
上一篇:安裝 hana 2.0 有沒有大神幫忙分析下,File 'SIGNATURE.SMF' cannot be found in the SAP HANA Data
下一篇:用Python可視化卷積神經網路