作者|FAIZAN SHAIKH
編譯|VK
來源|Analytics Vidhya
介紹
深入學習中最具爭議的話題之一是如何解釋和理解一個經過訓練的模型——特別是在醫療等高風險行業的背景下,“黑匣子”一詞經常與深度學習演算法聯系在一起,如果我們不能解釋模型是如何作業的,我們怎么能相信模型的結果呢?這是個合理的問題,
以一個為檢測癌癥而訓練的深度學習模型為例,這個模型告訴你,它99%確定它已經檢測到癌癥,但它并沒有告訴你為什么或者如何做出這個決定,
在核磁共振掃描中找到了重要線索嗎?或者只是掃描上的污點被錯誤地檢測為腫瘤?這是病人生死攸關的問題,醫生犯了大錯后果很嚴重,
在本文中,我們將探討如何可視化卷積神經網路(CNN),這是一種深入學習的體系結構,特別用于最先進的基于影像的應用程式,我們將了解可視化CNN模型的重要性,以及可視化它們的方法,我們還將看一個用例,它將幫助你更好地理解這個概念,
目錄
- CNN模型可視化的重要性
- 可視化方法
- 基本方法
- 繪制模型架構
- 可視化濾波器
- 基于激活的方法
- 最大激活
- 影像遮擋
- 基于梯度的方法
- 顯著圖
- 基于梯度的類激活圖
- 基本方法
CNN模型可視化的重要性
正如我們在上面的癌癥腫瘤例子中所看到的,我們知道我們的模型在做什么,以及它如何對預測做出決定,這是絕對重要的,通常,下面列出的原因是一個深度學習實踐者要記住的最重要的一點:
- 了解模型的作業原理
- 超引數調整
- 找出模型的失敗之處并能夠解決失敗
- 向消費者/最終用戶或業務主管解釋決策
讓我們看一個例子,在這個例子中,可視化一個神經網路模型有助于理解模型一些不好的行為和提高性能(下面的例子來自:http://intelligence.org/files/AIPosNegFactor.pdf),
曾幾何時,美國陸軍想使用神經網路來自動檢測偽裝的敵方坦克,研究人員用50張樹木偽裝的坦克照片和50張沒有坦克的樹木的照片訓練了神經網路,使用標準技術進行監督學習,研究人員對神經網路進行了訓練,使其權重能夠正確加載訓練集:對50張偽裝坦克的照片輸出“是”,對50張樹木照片的輸出“否”,
這并不能確保,甚至暗示,新的例子將被正確分類,神經網路可能已經“學習”了100個不會泛化到任何新問題的特殊情況,聰明的是,研究人員最初拍攝了200張照片,100張坦克照片和100張樹木照片,他們在訓練場只使用了50個,研究人員在剩下的100張照片上運行了神經網路,在沒有進一步訓練的情況下,神經網路對剩下的所有照片進行了正確的分類,不錯!研究人員把完成的作業交給五角大樓,五角大樓很快就把作業交還給了他們,他們抱怨說,在他們自己的測驗中,神經網路在辨別照片方面跟隨機差不多,

結果發現,在研究人員的資料集中,偽裝坦克的照片是在陰天拍攝的,而沒有偽裝的照片是在晴天拍攝的,神經網路已經學會了區分陰天和晴天,而不是區分偽裝坦克和空曠的森林,
CNN模型的可視化方法
大體上,CNN模型的可視化方法可以根據其內部作業方式分為三個部分
- 基本方法-向我們展示訓練模型的總體架構的簡單方法
- 基于激活的方法-在這些方法中,我們破譯單個神經元或一組神經元的激活函式,以理解它們正在做什么
- 基于梯度的方法-這些方法傾向于在訓練模型時操縱由向前和反向傳播形成的梯度
我們將在下面的章節中詳細介紹它們,在這里,我們將使用keras作為我們的庫來構建深度學習模型,并使用keras-vis來可視化它們,在繼續之前,請確保你已經在系統中安裝了這些程式,
注:本文使用“Identify the Digits”競賽中給出的資料集,要運行下面提到的代碼,你必須在系統中下載它,另外,在開始下面的實作之前,請執行提供的步驟,
資料集:https://datahack.analyticsvidhya.com/contest/practice-problem-identify-the-digits/
準備步驟:https://www.analyticsvidhya.com/keras_script-py/
1.基本方法
1.1 繪制模型架構
最簡單的方法就是列印模型,在這里,你還可以列印神經網路的各個層的形狀和每個層的引數,
在keras中,可以按如下方式實作:
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
conv2d_2 (Conv2D) (None, 24, 24, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 12, 12, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 12, 12, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 9216) 0
_________________________________________________________________
dense_1 (Dense) (None, 128) 1179776
_________________________________________________________________
dropout_2 (Dropout) (None, 128) 0
_________________________________________________________________
preds (Dense) (None, 10) 1290
=================================================================
Total params: 1,199,882
Trainable params: 1,199,882
Non-trainable params: 0
為了更具創造性和表現力,你可以繪制一個架構圖(keras.utils.vis_utils函式),
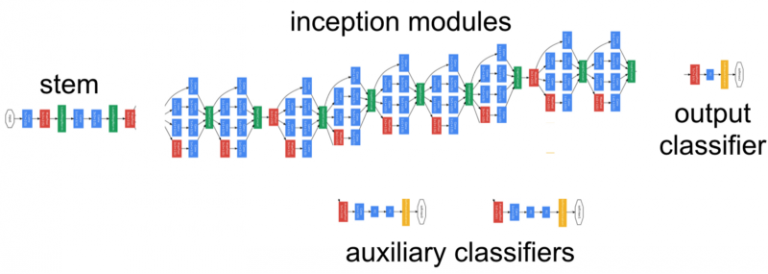
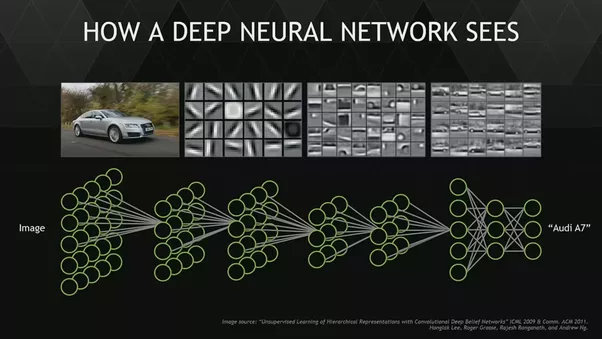
1.2 可視化濾波器
另一種方法是繪制訓練模型的濾波器,以便我們可以了解這些濾波器的行為,例如,上述模型第一層的第一個濾波器如下所示:
top_layer = model.layers[0]
plt.imshow(top_layer.get_weights()[0][:, :, :, 0].squeeze(), cmap='gray')

一般來說,我們看到低層的濾波器起到邊緣探測器的作用,當我們走得更高時,它們傾向于捕捉像物體和人臉這樣的高層概念,
2. 基于激活的方法
2.1 最大激活
為了了解我們的神經網路在做什么,我們可以對輸入影像應用濾波器,然后繪制輸出,這使我們能夠理解什么樣的輸入模式激活了一個特定的濾波器,例如,可能有一個人臉濾波器,當它在影像中出現一個人臉時會激活它,
from vis.visualization import visualize_activation
from vis.utils import utils
from keras import activations
from matplotlib import pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = (18, 6)
# 按名稱搜索圖層索引,
# 或者,我們可以將其指定為-1,因為它對應于最后一層,
layer_idx = utils.find_layer_idx(model, 'preds')
#用線性層替換softmax
model.layers[layer_idx].activation = activations.linear
model = utils.apply_modifications(model)
# 這是我們要最大化的輸出節點,
filter_idx = 0
img = visualize_activation(model, layer_idx, filter_indices=filter_idx)
plt.imshow(img[..., 0])
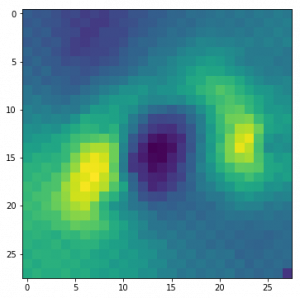
我們可以把這個想法轉移到所有的類中,并檢查每個類,
PS:運行下面的腳本來檢查它,
for output_idx in np.arange(10):
# 讓我們這次關閉詳細輸出以避免混亂
img = visualize_activation(model, layer_idx, filter_indices=output_idx, input_range=(0., 1.))
plt.figure()
plt.title('Networks perception of {}'.format(output_idx))
plt.imshow(img[..., 0])
2.2 影像遮擋
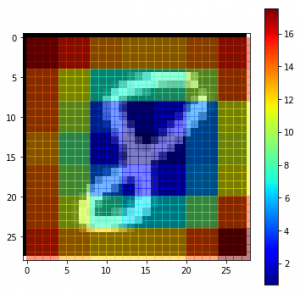
在一個影像分類問題中,一個自然的問題是模型是否真正識別了影像中物件的位置,或者僅僅使用了周圍的背景關系,我們在上面的基于梯度的方法中對此做了簡要的介紹,基于遮擋的方法試圖通過系統地用一個灰色正方形遮擋輸入影像的不同部分來回答這個問題,并監視分類器的輸出,示例清楚地表明,模型正在場景中定位物件,因為當物件被遮擋時,正確類的概率顯著降低,

為了理解這個概念,讓我們從資料集中隨機抽取一張影像,并嘗試繪制影像的熱圖,這將給我們一個直覺,圖片的哪些部分是重要的,可以明確區分類別,
def iter_occlusion(image, size=8):
occlusion = np.full((size * 5, size * 5, 1), [0.5], np.float32)
occlusion_center = np.full((size, size, 1), [0.5], np.float32)
occlusion_padding = size * 2
# print('padding...')
image_padded = np.pad(image, ( \
(occlusion_padding, occlusion_padding), (occlusion_padding, occlusion_padding), (0, 0) \
), 'constant', constant_values = 0.0)
for y in range(occlusion_padding, image.shape[0] + occlusion_padding, size):
for x in range(occlusion_padding, image.shape[1] + occlusion_padding, size):
tmp = image_padded.copy()
tmp[y - occlusion_padding:y + occlusion_center.shape[0] + occlusion_padding, \
x - occlusion_padding:x + occlusion_center.shape[1] + occlusion_padding] \
= occlusion
tmp[y:y + occlusion_center.shape[0], x:x + occlusion_center.shape[1]] = occlusion_center
yield x - occlusion_padding, y - occlusion_padding, \
tmp[occlusion_padding:tmp.shape[0] - occlusion_padding, occlusion_padding:tmp.shape[1] - occlusion_padding]
i = 23 # 例如
data = https://www.cnblogs.com/panchuangai/p/val_x[i]
correct_class = np.argmax(val_y[i])
# model.predict的輸入向量
inp = data.reshape(1, 28, 28, 1)
# matplotlib imshow函式的圖片
img = data.reshape(28, 28)
# 遮蓋
img_size = img.shape[0]
occlusion_size = 4
print('occluding...')
heatmap = np.zeros((img_size, img_size), np.float32)
class_pixels = np.zeros((img_size, img_size), np.int16)
from collections import defaultdict
counters = defaultdict(int)
for n, (x, y, img_float) in enumerate(iter_occlusion(data, size=occlusion_size)):
X = img_float.reshape(1, 28, 28, 1)
out = model.predict(X)
#print('#{}: {} @ {} (correct class: {})'.format(n, np.argmax(out), np.amax(out), out[0][correct_class]))
#print('x {} - {} | y {} - {}'.format(x, x + occlusion_size, y, y + occlusion_size))
heatmap[y:y + occlusion_size, x:x + occlusion_size] = out[0][correct_class]
class_pixels[y:y + occlusion_size, x:x + occlusion_size] = np.argmax(out)
counters[np.argmax(out)] += 1
3. 基于梯度的方法
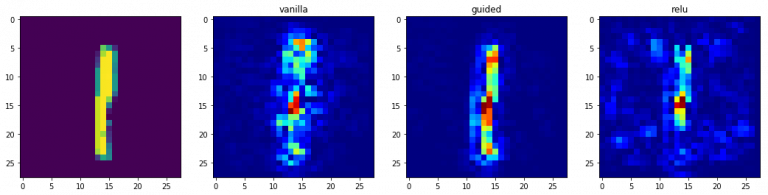
3.1 顯著性圖
正如我們在坦克的例子中所看到的,我們如何才能知道我們的模型關注哪個部分來獲得預測?為此,我們可以使用顯著性圖,
使用顯著性圖的概念是非常直接的——我們計算輸出類別相對于輸入影像的梯度,這應該告訴我們輸出類別值相對于輸入影像像素的微小變化是如何變化的,梯度中的所有正值都告訴我們,對該像素的微小更改將增加輸出值,因此,將這些與影像形狀相同的梯度可視化,應該能提供一些直覺,
直觀地,該方法突出了對輸出貢獻最大的顯著影像區域,
class_idx = 0
indices = np.where(val_y[:, class_idx] == 1.)[0]
# 從這里選取一些隨機輸入,
idx = indices[0]
# 讓sanity檢查選中的影像,
from matplotlib import pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = (18, 6)
plt.imshow(val_x[idx][..., 0])
from vis.visualization import visualize_saliency
from vis.utils import utils
from keras import activations
# 按名稱搜索圖層索引
# 或者,我們可以將其指定為-1,因為它對應于最后一層,
layer_idx = utils.find_layer_idx(model, 'preds')
# 用線性層替換softmax
model.layers[layer_idx].activation = activations.linear
model = utils.apply_modifications(model)
grads = visualize_saliency(model, layer_idx, filter_indices=class_idx, seed_input=val_x[idx])
# 可視化為熱圖,
plt.imshow(grads, cmap='jet')
# 這對應于線性層,
for class_idx in np.arange(10):
indices = np.where(val_y[:, class_idx] == 1.)[0]
idx = indices[0]
f, ax = plt.subplots(1, 4)
ax[0].imshow(val_x[idx][..., 0])
for i, modifier in enumerate([None, 'guided', 'relu']):
grads = visualize_saliency(model, layer_idx, filter_indices=class_idx,
seed_input=val_x[idx], backprop_modifier=modifier)
if modifier is None:
modifier = 'vanilla'
ax[i+1].set_title(modifier)
ax[i+1].imshow(grads, cmap='jet')
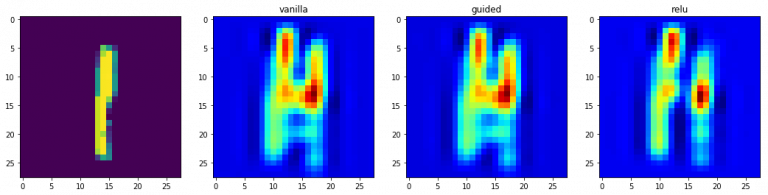
3.2 基于梯度的類激活圖
類激活圖是另一種在進行預測時可視化模型所看到的內容的方法,使用倒數第二卷積層輸出,而不是使用相對于輸出的梯度,這樣做是為了利用存盤在倒數第二層的空間資訊,
from vis.visualization import visualize_cam
# 這對應于線性層,
for class_idx in np.arange(10):
indices = np.where(val_y[:, class_idx] == 1.)[0]
idx = indices[0]
f, ax = plt.subplots(1, 4)
ax[0].imshow(val_x[idx][..., 0])
for i, modifier in enumerate([None, 'guided', 'relu']):
grads = visualize_cam(model, layer_idx, filter_indices=class_idx,
seed_input=val_x[idx], backprop_modifier=modifier)
if modifier is None:
modifier = 'vanilla'
ax[i+1].set_title(modifier)
ax[i+1].imshow(grads, cmap='jet')
結尾
在本文中,我們介紹了如何可視化CNN模型,以及為什么要可視化,我們結合一個例子來實作它,可視化有著廣泛的應用,
原文鏈接:https://www.analyticsvidhya.com/blog/2018/03/essentials-of-deep-learning-visualizing-convolutional-neural-networks/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/18185.html
標籤:其他
上一篇:六種用于文本分類的開源預訓練模型