作者|Cory Maklin
編譯|VK
來源|Towards Datas Science
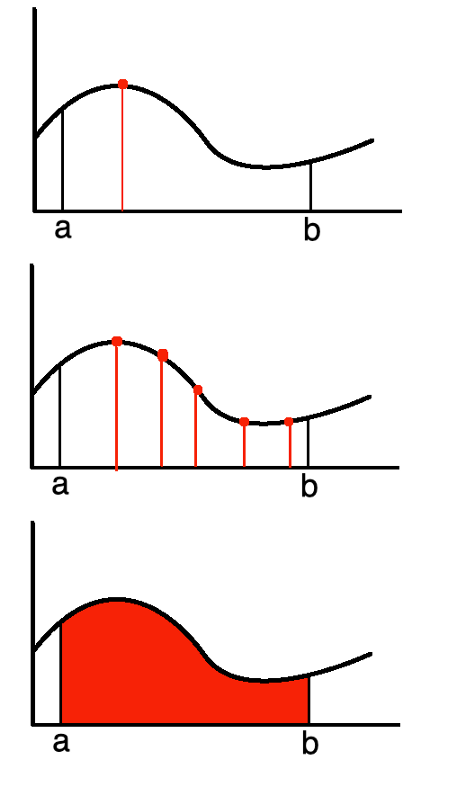
通常情況下,我們不能決議地求解積分,必須借助其他方法,其中就包括蒙特卡羅積分,你可能還記得,函式的積分可以解釋為函式曲線下的面積,
蒙特卡羅積分的作業原理是在a和b之間的不同隨機點計算一個函式,將矩形的面積相加,取和的平均值,隨著點數的增加,所得結果接近于積分的實際解,
蒙特卡羅積分用代數表示:
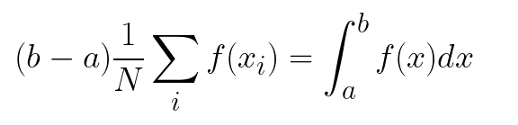
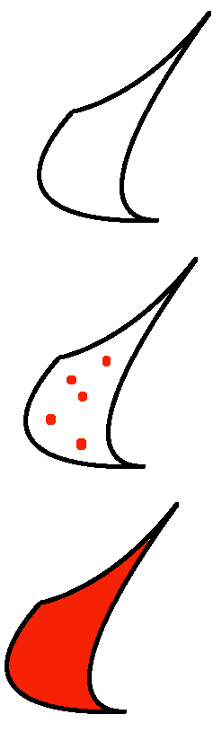
與其他數值方法相比,蒙特卡羅積分特別適合于計算奇數形狀的面積,
在上一節中,我們看到如何使用蒙特卡羅積分來確定后驗概率,當我們知道先驗和似然,但缺少規范化常數,
貝葉斯統計
后驗概率是指貝葉斯公式中的一個特定項,
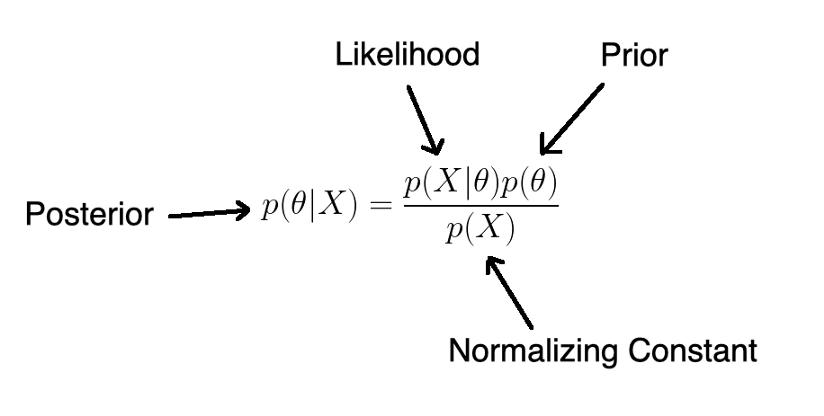
貝葉斯定理可以用來計算一個人在某一特定疾病的篩查測驗中呈陽性的人實際上患有該病的概率,
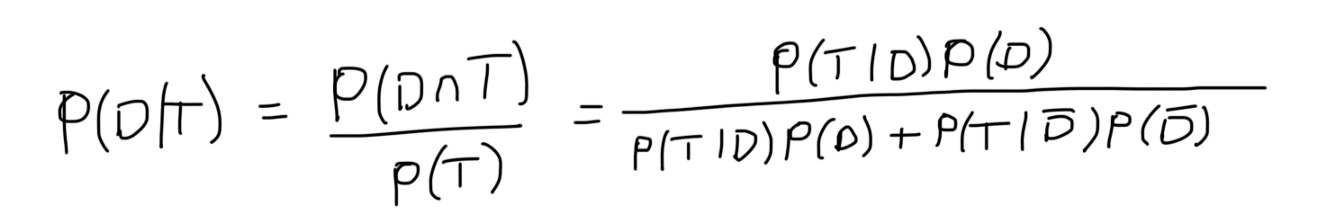
如果我們已經知道P(A),P(B)和P(B | A),但想知道P(A | B),我們就用這個公式,例如,假設我們正在檢測一種感染1%人口的罕見疾病,醫學專業人員已經開發出一種高度敏感和特異的檢測方法,但還不夠完善,
- 99%的病人檢測呈陽性
- 99%的健康患者檢測為陰性
貝葉斯定理告訴我們:
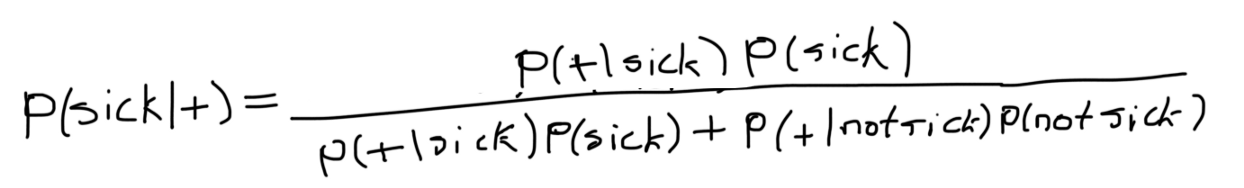
假設我們有10000人,100人生病,9900人健康,此外,在給他們所有的測驗后,我們會讓99個生病的人測驗生病,但是99個健康的人也測驗生病,因此,我們將得到以下概率,
p(sick) = 0.01
p(not sick) = 1–0.01 = 0.99
p(+|sick) = 0.99
p(+|not sick) = 0.01
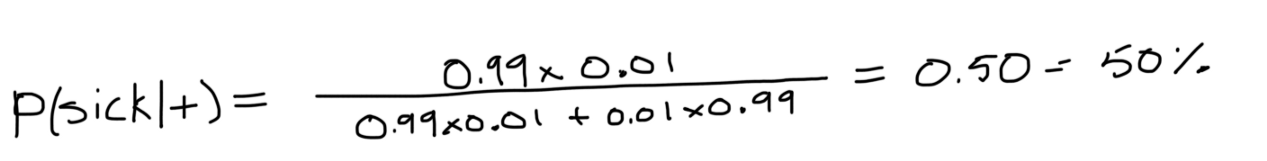
Bayes定理在概率分布中的應用
在前面的例子中,我們假設一個人患病的先驗概率是一個已知的量,精確到0.001,
然而,在現實世界中,認為0.001的概率事實上如此精確是不合理的,一個給定的人患病的概率會因其年齡、性別、體重等而有很大差異,一般來說,我們對給定先驗概率的認識還遠遠不夠完善,因為它是從以前的樣本中得出的(這意味著不同的人群可能會對先驗概率給出不同的估計),
在貝葉斯統計中,我們可以用先驗概率的分布來代替這個0.001的值,這個分布捕捉了我們關于其真實值的先驗不確定性,包含先驗概率分布最終產生的后驗概率也不再是單一數量;相反,后驗概率也變成了概率分布,這與傳統的觀點相反,后者假設引數是固定的量,
歸一化常數
正如我們在Gibbs抽樣和Metropolis-Hasting的文章中看到的,蒙特卡洛方法可以用來計算歸一化常數未知時的后驗概率分布,
讓我們來探究一下為什么我們首先需要一個標準化常數,在概率論中,規范化常數是一個函式必須乘以的常數,因此它的圖下面積為1,還是不清楚?讓我們看一個例子,
回想一下正態分布的函式可以寫成:
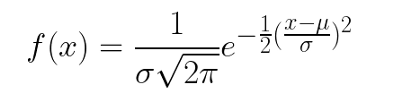
2*pi的平方根是歸一化常數,
讓我們來看看我們是如何確定它的,我們從以下函式開始(假設均值為0,方差為1):
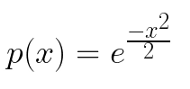
如果我們能畫出一個曲線的話,
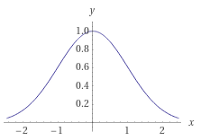
問題在于,如果我們取曲線下的面積,它不等于1,這要求它是一個概率密度函式,因此,我們將函式除以積分的結果(歸一化常數),

回到手頭的問題,即如何在沒有歸一化常數的情況下計算后驗概率……事實證明,對于連續樣本空間,規范化常數可以重寫為:
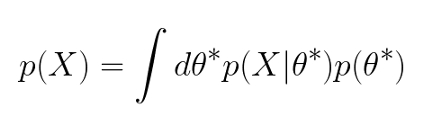
在這一點上,你應該考慮蒙特卡羅積分!
Python代碼
讓我們看看如何通過在Python中執行蒙特卡洛積分來確定后驗概率,我們從匯入所需的庫開始,并設定隨機種子以確保結果是可重復的,
import os
import sys
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import scipy.stats as st
np.random.seed(42)
然后我們設定β分布和二項分布的引數值,
a, b = 10, 10
n = 100
h = 59
thetas = np.linspace(0, 1, 200)
概率密度函式的范圍從0到1,因此,我們可以簡化方程,
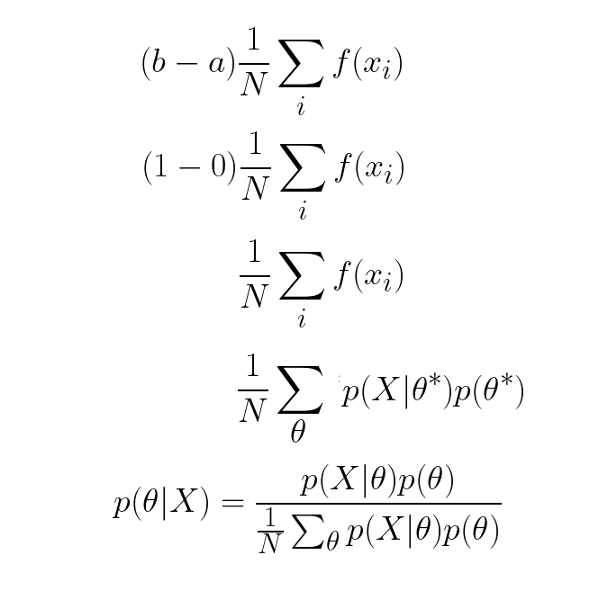
在代碼中,前面的等式寫如下:
prior = st.beta(a, b).pdf(thetas)
likelihood = st.binom(n, thetas).pmf(h)
post = prior * likelihood
post /= (post.sum() / len(thetas))
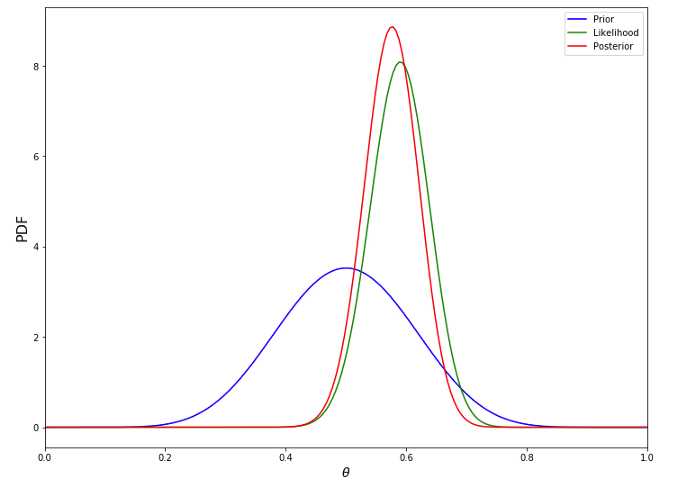
最后,我們將先驗、后驗和似然的概率密度函式可視化,
plt.figure(figsize=(12, 9))
plt.plot(thetas, prior, label='Prior', c='blue')
plt.plot(thetas, n*likelihood, label='Likelihood', c='green')
plt.plot(thetas, post, label='Posterior', c='red')
plt.xlim([0, 1])
plt.xlabel(r'$\theta$', fontsize=14)
plt.ylabel('PDF', fontsize=16)
plt.legend();
結論
蒙特卡羅積分是求解積分的一種數值方法,它的作業原理是在隨機點對函式求值,求和所述值,然后計算它們的平均值,
原文鏈接:https://towardsdatascience.com/monte-carlo-integration-db86b8d7beb3
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/183403.html
標籤:其他