作者|Zolzaya Luvsandorj
編譯|VK
來源|Towards Datas Science
掌握sklearn必須知道這三個強大的工具,因此,在建立機器學習模型時,學習如何有效地使用這些方法是至關重要的,
在深入討論之前,我們先從兩個方面著手:
-
Transformer:Transformer是指具有fit()和transform()方法的物件,用于清理、減少、擴展或生成特征,簡單地說,transformers幫助你將資料轉換為機器學習模型所需的格式,OneHotEncoder和MinMaxScaler就是Transformer的例子,
-
Estimator:Estimator是指機器學習模型,它是一個具有fit()和predict()方法的物件,我們將交替使用模型和Estimator這2個術語,該鏈接是一些Estimator的例子:https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html,

安裝
如果你想在你電腦上運行代碼,確保你已經安裝了pandas,seaborn和sklearn,我在Jupyter notebook中在python3.7.1中撰寫腳本,
讓我們匯入所需的庫和資料集,關于這個資料集(包括資料字典)的詳細資訊可以在這里找到(這個源實際上是針對R的,但是它似乎參考了相同的底層資料集):https://vincentarelbundock.github.io/Rdatasets/doc/reshape2/tips.html,
# 設定種子
seed = 123
# 為資料匯入包/模塊
import pandas as pd
from seaborn import load_dataset
# 為特征工程和建模匯入模塊
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.preprocessing import OneHotEncoder, MinMaxScaler
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline, FeatureUnion
from sklearn.compose import ColumnTransformer
from sklearn.linear_model import LinearRegression
# 加載資料集
df = load_dataset('tips').drop(columns=['tip', 'sex']).sample(n=5, random_state=seed)
# 添加缺失的值
df.iloc[[1, 2, 4], [2, 4]] = np.nan
df
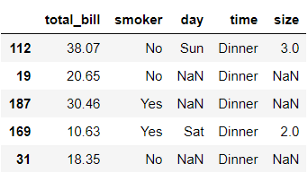
使用少量的記錄可以很容易地監控每個步驟的輸入和輸出,因此,我們將只使用資料集中5條記錄的樣本,
管道
假設我們想用smoker、day和time列來預測總的賬單,我們將先洗掉size列并對資料進行劃分:
# 劃分資料
X_train, X_test, y_train, y_test = train_test_split(df.drop(columns=['total_bill', 'size']),
df['total_bill'],
test_size=.2,
random_state=seed)
通常情況下,原始資料不是我們可以直接將其輸入機器學習模型的狀態,因此,將資料轉換為可接受且對模型有用的狀態成為建模的必要先決條件,讓我們做以下轉換作為準備:
-
用“missing”填充缺失值
-
one-hot編碼
以下完成這兩個步驟:
# 輸入訓練資料
imputer = SimpleImputer(strategy='constant', fill_value='https://www.cnblogs.com/panchuangai/p/missing')
X_train_imputed = imputer.fit_transform(X_train)
# 編碼訓練資料
encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
X_train_encoded = encoder.fit_transform(X_train_imputed)
# 檢查訓練前后的資料
print("******************** Training data ********************")
display(X_train)
display(pd.DataFrame(X_train_imputed, columns=X_train.columns))
display(pd.DataFrame(X_train_encoded, columns=encoder.get_feature_names(X_train.columns)))
# 轉換測驗資料
X_test_imputed = imputer.transform(X_test)
X_test_encoded = encoder.transform(X_test_imputed)
# 檢查測驗前后的資料
print("******************** Test data ********************")
display(X_test)
display(pd.DataFrame(X_test_imputed, columns=X_train.columns))
display(pd.DataFrame(X_test_encoded, columns=encoder.get_feature_names(X_train.columns)))
你可能已經注意到,當映射回測驗資料集的列名時,我們使用了來自訓練資料集的列名,這是因為我更喜歡使用來自于訓練Transformer的資料的列名,但是,如果我們使用測驗資料集,它將給出相同的結果,
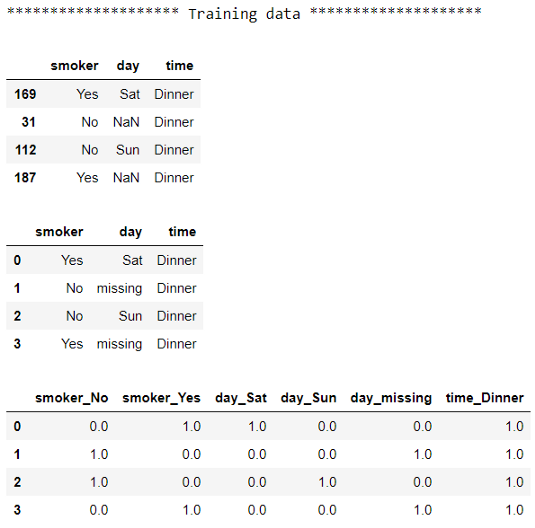
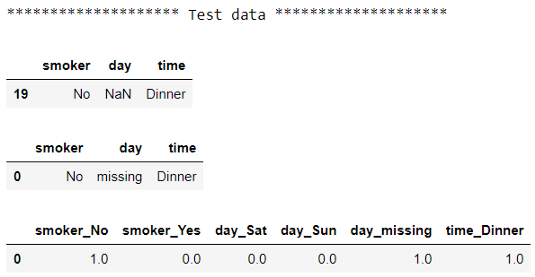
對于每個資料集,我們首先看到原始資料,然后是插補后的輸出,最后是編碼后的輸出,
這種方法可以完成任務,但是,我們將上一步的輸出作為輸入手動輸入到下一步,并且有多個臨時輸出,我們還必須在測驗資料上重復每一步,隨著步驟數的增加,維護將變得更加繁瑣,更容易出錯,
我們可以使用管道撰寫更精簡和簡潔的代碼:
# 將管道與訓練資料匹配
pipe = Pipeline([('imputer', SimpleImputer(strategy='constant', fill_value='https://www.cnblogs.com/panchuangai/p/missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False))])
pipe.fit(X_train)
# 檢查訓練前后的資料
print("******************** Training data ********************")
display(X_train)
display(pd.DataFrame(pipe.transform(X_train), columns=pipe['encoder'].get_feature_names(X_train.columns)))
# 檢查測驗前后的資料
print("******************** Test data ********************")
display(X_test)
display(pd.DataFrame(pipe.transform(X_test), columns=pipe['encoder'].get_feature_names(X_train.columns)))
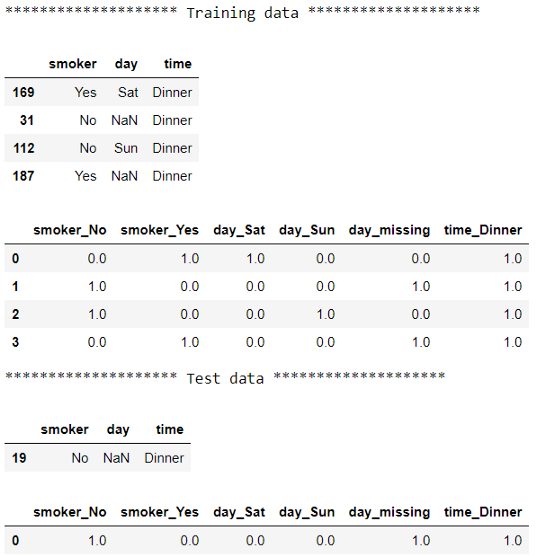
使用管道時,每個步驟都將其輸出作為輸入傳遞到下一個步驟,因此,我們不必手動跟蹤資料的不同版本,這種方法為我們提供了完全相同的最終輸出,但是使用了更優雅的代碼,
在查看了轉換后的資料之后,現在是在我們的示例中添加模型的時候了,讓我們從為第一種方法添加一個簡單模型:
# 輸入訓練資料
imputer = SimpleImputer(strategy='constant', fill_value='https://www.cnblogs.com/panchuangai/p/missing')
X_train_imputed = imputer.fit_transform(X_train)
# 編碼訓練資料
encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
X_train_encoded = encoder.fit_transform(X_train_imputed)
# 使模型擬合訓練資料
model = LinearRegression()
model.fit(X_train_encoded, y_train)
# 預測訓練資料
y_train_pred = model.predict(X_train_encoded)
print(f"Predictions on training data: {y_train_pred}")
# 轉換測驗資料
X_test_imputed = imputer.transform(X_test)
X_test_encoded = encoder.transform(X_test_imputed)
# 預測測驗資料
y_test_pred = model.predict(X_test_encoded)
print(f"Predictions on test data: {y_test_pred}")

我們將對管道方法進行同樣的處理:
# 將管道與訓練資料匹配
pipe = Pipeline([('imputer', SimpleImputer(strategy='constant', fill_value='https://www.cnblogs.com/panchuangai/p/missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False)),
('model', LinearRegression())])
pipe.fit(X_train, y_train)
# 預測訓練資料
y_train_pred = pipe.predict(X_train)
print(f"Predictions on training data: {y_train_pred}")
# 預測測驗資料
y_test_pred = pipe.predict(X_test)
print(f"Predictions on test data: {y_test_pred}")
你可能已經注意到,一旦我們訓練了一條管道,進行預測是多么簡單,pipe.predict(X)對原始資料進行轉換,然后回傳預測,也很容易看到步驟的順序,讓我們直觀地總結一下這兩種方法:
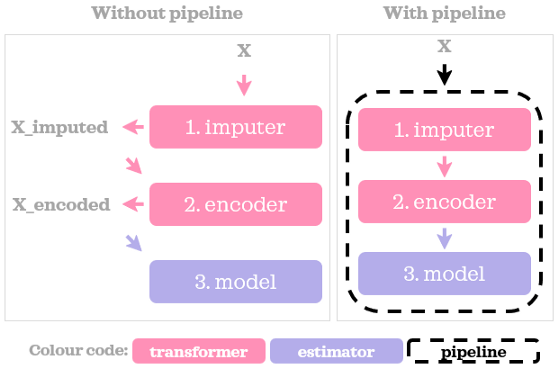
使用管道不僅可以組織和簡化代碼,而且還有許多其他好處,下面是其中一些好處:
-
微調管道的能力:當構建一個模型時,你可能需要嘗試不同的方法來預處理資料并再次運行模型,看看預處理步驟中的調整是否能提高模型的泛化能力,在優化模型時,微調不僅存在于模型的超引數中,而且存在于預處理步驟的實作中,考慮到這一點,當我們有一個統一了Transformer和Estimator的管道物件時,我們可以微調整個管道的超引數,包括使用GridSearchCV或RandomizedSearchCV的Estimator和兩個Transformer,
-
更容易部署:在訓練模型時用于準備資料的所有轉換步驟在進行預測時也可以應用于生產環境中的資料,當我們訓練管道時,我們訓練一個包含資料轉換器和模型的物件,一旦經過訓練,這個管道物件就可以用于更平滑的部署,
ColumnTransformer
在前面的例子中,我們以相同的方式對所有列進行插補和編碼,但是,我們經常需要對不同的列組應用不同的transformer,例如,我們希望將OneHotEncoder僅應用于分類列,而不應用于數值列,這就是ColumnTransformer的用武之地,
這一次,我們將對保留所有列的資料集進行磁區,以便同時具有數值和類別特征,
# 劃分資料
X_train, X_test, y_train, y_test = train_test_split(df.drop(columns=['total_bill']),
df['total_bill'],
test_size=.2,
random_state=seed)
# 定義分類列
categorical = list(X_train.select_dtypes('category').columns)
print(f"Categorical columns are: {categorical}")
# 定義數字列
numerical = list(X_train.select_dtypes('number').columns)
print(f"Numerical columns are: {numerical}")
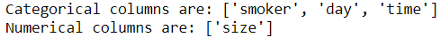
我們根據資料型別將特征分為兩組,列分組可以根據資料的適當情況進行,例如,如果不同的預處理管道更適合分類列,則可以將它們進一步拆分為多個組,
上一節的代碼現在將不再作業,因為我們有多個資料型別,讓我們看一個例子,其中我們使用ColumnTransformer和Pipeline在存在多個資料型別的情況下執行與之前相同的轉換,
# 定義分類管道
cat_pipe = Pipeline([('imputer', SimpleImputer(strategy='constant', fill_value='https://www.cnblogs.com/panchuangai/p/missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False))])
# 使ColumnTransformer擬合訓練資料
preprocessor = ColumnTransformer(transformers=[('cat', cat_pipe, categorical)],
remainder='passthrough')
preprocessor.fit(X_train)
# 準備列名
cat_columns = preprocessor.named_transformers_['cat']['encoder'].get_feature_names(categorical)
columns = np.append(cat_columns, numerical)
# 檢查訓練前后的資料
print("******************** Training data ********************")
display(X_train)
display(pd.DataFrame(preprocessor.transform(X_train), columns=columns))
# 檢查測驗前后的資料
print("******************** Test data ********************")
display(X_test)
display(pd.DataFrame(preprocessor.transform(X_test), columns=columns))
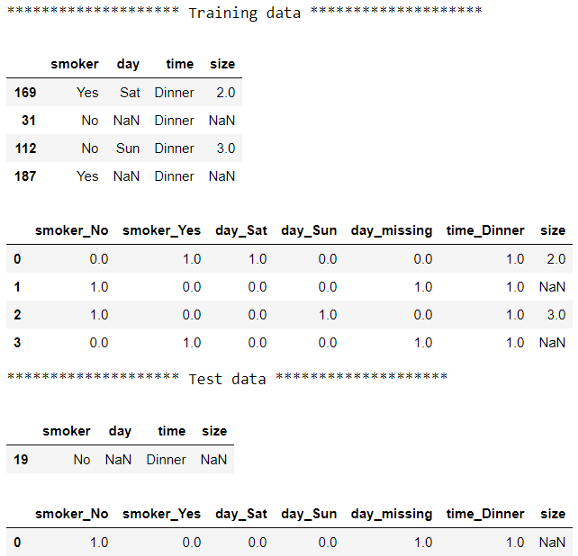
分類列的輸出與上一節的輸出相同,唯一的區別是這個版本有一個額外的列:size,我們已經將cat_pipe(在上一節中稱為pipe)傳遞給ColumnTransformer來轉換分類列,并指定remainment='passthrough'以保持其余列不變,
讓我們用中值填充缺失值,并將其縮放到0和1之間:
# 定義分類管道
cat_pipe = Pipeline([('imputer', SimpleImputer(strategy='constant', fill_value='https://www.cnblogs.com/panchuangai/p/missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False))])
# 定義數值管道
num_pipe = Pipeline([('imputer', SimpleImputer(strategy='median')),
('scaler', MinMaxScaler())])
# 使ColumnTransformer擬合訓練資料
preprocessor = ColumnTransformer(transformers=[('cat', cat_pipe, categorical),
('num', num_pipe, numerical)])
preprocessor.fit(X_train)
# 準備列名
cat_columns = preprocessor.named_transformers_['cat']['encoder'].get_feature_names(categorical)
columns = np.append(cat_columns, numerical)
# 檢查訓練前后的資料
print("******************** Training data ********************")
display(X_train)
display(pd.DataFrame(preprocessor.transform(X_train), columns=columns))
# 檢查測驗前后的資料
print("******************** Test data ********************")
display(X_test)
display(pd.DataFrame(preprocessor.transform(X_test), columns=columns))
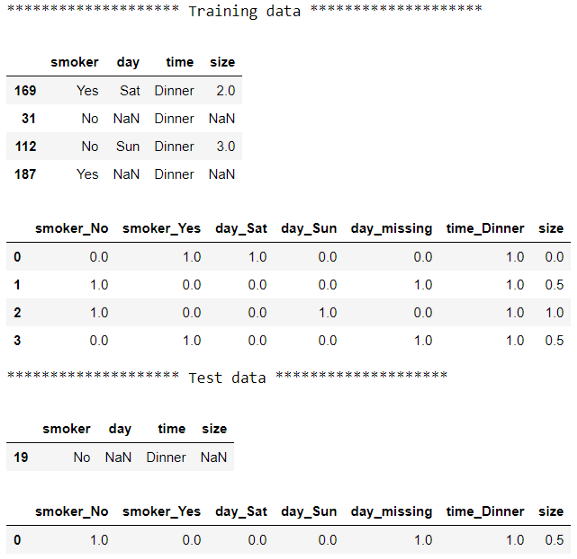
現在所有列都被插補,范圍在0到1之間,使用ColumnTransformer和Pipeline,我們將資料分成兩組,將不同的管道和不同的Transformer應用到每組,然后將結果粘貼在一起:
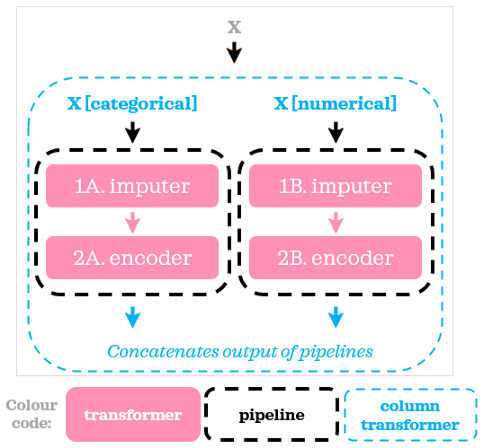
盡管在我們的示例中,數值管道和分類管道中的步驟數相同,但管道中可以有任意數量的步驟,并且不同列子集的步驟數不必相同,現在我們將一個模型添加到我們的示例中:
# 定義分類管道
cat_pipe = Pipeline([('imputer', SimpleImputer(strategy='constant', fill_value='https://www.cnblogs.com/panchuangai/p/missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False))])
# 定義數值管道
num_pipe = Pipeline([('imputer', SimpleImputer(strategy='median')),
('scaler', MinMaxScaler())])
# 組合分類管道和數值管道
preprocessor = ColumnTransformer(transformers=[('cat', cat_pipe, categorical),
('num', num_pipe, numerical)])
# 在管道上安裝transformer和訓練資料的estimator
pipe = Pipeline(steps=[('preprocessor', preprocessor),
('model', LinearRegression())])
pipe.fit(X_train, y_train)
# 預測訓練資料
y_train_pred = pipe.predict(X_train)
print(f"Predictions on training data: {y_train_pred}")
# 預測測驗資料
y_test_pred = pipe.predict(X_test)
print(f"Predictions on test data: {y_test_pred}")

為了將ColumnTransformer中指定的預處理步驟與模型結合起來,我們在外部使用了一個管道,以下是它的視覺表現:
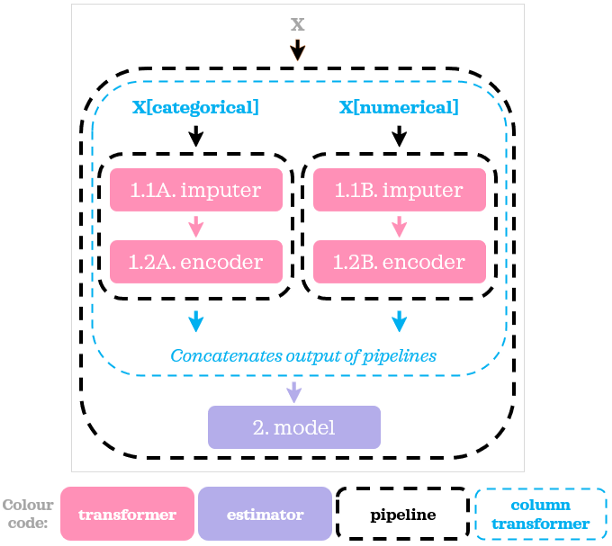
當我們需要對不同的列子集執行不同的操作時,ColumnTransformer很好地補充了管道,
FeatureUnion
以下代碼的輸出在本節中被省略,因為它們與ColumnTransformer章節的輸出相同,
FeatureUnion是另一個有用的工具,它可以做ColumnTransformer剛剛做過的事情,但要做得更遠:
# 自定義管道
class ColumnSelector(BaseEstimator, TransformerMixin):
"""Select only specified columns."""
def __init__(self, columns):
self.columns = columns
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.columns]
# 定義分類管道
cat_pipe = Pipeline([('selector', ColumnSelector(categorical)),
('imputer', SimpleImputer(strategy='constant', fill_value='https://www.cnblogs.com/panchuangai/p/missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False))])
# 定義數值管道
num_pipe = Pipeline([('selector', ColumnSelector(numerical)),
('imputer', SimpleImputer(strategy='median')),
('scaler', MinMaxScaler())])
# FeatureUnion擬合訓練資料
preprocessor = FeatureUnion(transformer_list=[('cat', cat_pipe),
('num', num_pipe)])
preprocessor.fit(X_train)
# 準備列名
cat_columns = preprocessor.transformer_list[0][1][2].get_feature_names(categorical)
columns = np.append(cat_columns, numerical)
# 檢查訓練前后的資料
print("******************** Training data ********************")
display(X_train)
display(pd.DataFrame(preprocessor.transform(X_train), columns=columns))
# 檢查測驗前后的資料
print("******************** Test data ********************")
display(X_test)
display(pd.DataFrame(preprocessor.transform(X_test), columns=columns))
我們可以將FeatureUnion視為創建資料的副本,并行地轉換這些副本,然后將結果粘貼在一起,這里的術語副本更像是一種輔助概念化的類比,而不是實際采用的技術,
在每個管道的開始,我們添加了一個額外的步驟,在這里我們使用一個定制的轉換器來選擇相關的列:第14行和第19行的ColumnSelector,下面是我們可視化上面的腳本的圖:
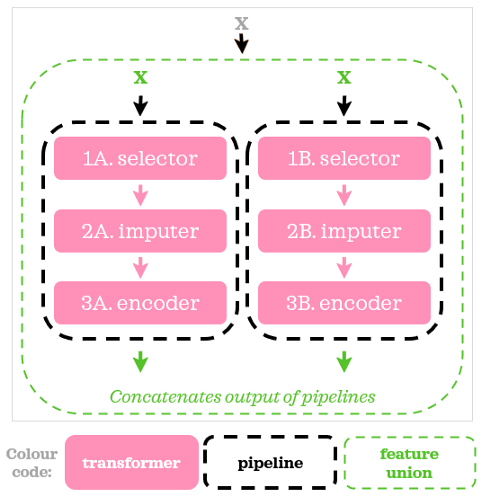
現在,是時候向腳本添加模型了:
# 定義分類管道
cat_pipe = Pipeline([('selector', ColumnSelector(categorical)),
('imputer', SimpleImputer(strategy='constant', fill_value='https://www.cnblogs.com/panchuangai/p/missing')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse=False))])
# 定義數值管道
num_pipe = Pipeline([('selector', ColumnSelector(numerical)),
('imputer', SimpleImputer(strategy='median')),
('scaler', MinMaxScaler())])
# 組合分類管道和數值管道
preprocessor = FeatureUnion(transformer_list=[('cat', cat_pipe),
('num', num_pipe)])
# 組合分類管道和數值管道
pipe = Pipeline(steps=[('preprocessor', preprocessor),
('model', LinearRegression())])
pipe.fit(X_train, y_train)
# 預測訓練資料
y_train_pred = pipe.predict(X_train)
print(f"Predictions on training data: {y_train_pred}")
# 預測測驗資料
y_test_pred = pipe.predict(X_test)
print(f"Predictions on test data: {y_test_pred}")
它看起來很像我們用ColumnTransformer做的,
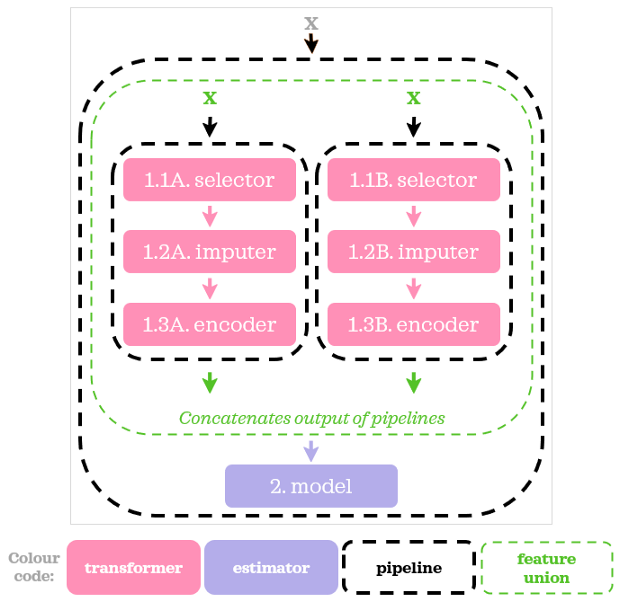
如本例所示,使用FeatureUnion比使用ColumnTransformer要復雜得多,因此,在我看來,在類似的情況下最好使用ColumnTransformer,
然而,FeatureUnion肯定有它的位置,如果你需要以不同的方式轉換相同的輸入資料并將它們用作特征,FeatureUnion就是其中之一,例如,如果你正在處理一個文本資料,并且希望對資料進行tf-idf矢量化以及提取文本長度,FeatureUnion是一個完美的工具,
總結
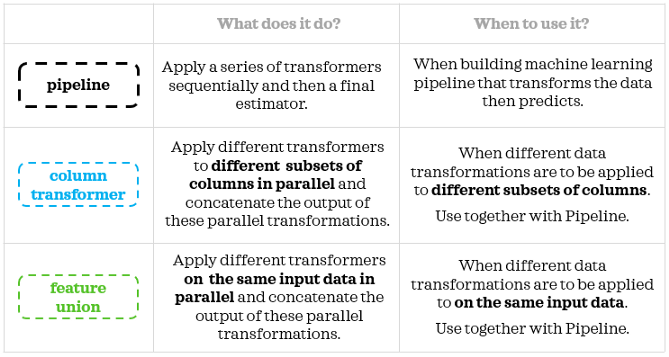
你可能已經注意到,Pipeline是超級明星,ColumnTransformer和FeatureUnion是用于管道的附加工具,ColumnTransformer更適合于并行劃分,而FeatureUnion允許我們在同一個輸入資料上并行應用多個轉換器,下面是一個簡單的總結:
謝謝你閱讀我的帖子,希望這篇文章能幫助你更多地了解這些有用的工具,我希望你能在你的資料科學專案中使用它們,如果你感興趣,以下是我的一些帖子的鏈接:
- Exploratory text analysis in Python(https://towardsdatascience.com/exploratory-text-analysis-in-python-8cf42b758d9e)
- Preprocessing text in Python(https://towardsdatascience.com/preprocessing-text-in-python-923828c4114f)
Sentiment classification in Python(https://towardsdatascience.com/sentiment-classification-in-python-da31833da01b) - 5 tips for pandas users(https://towardsdatascience.com/5-tips-for-pandas-users-e73681d16d17)
- 5 tips for data aggregation in pandas(https://towardsdatascience.com/writing-5-common-sql-queries-in-pandas-90b52f17ad76)
- Writing 5 common SQL queries in pandas(https://towardsdatascience.com/writing-5-common-sql-queries-in-pandas-90b52f17ad76)
- Writing advanced SQL queries in pandas(https://towardsdatascience.com/writing-advanced-sql-queries-in-pandas-1dc494a17afe)
原文鏈接:https://towardsdatascience.com/vectorizing-code-matters-66c5f95ddfd5
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/184930.html
標籤:其他
上一篇:python,請高手,求解~!