作者|Dario Rade?i?
編譯|VK
來源|Towards Datas Science
2020年即將結束(終于),資料可視化再重要不過了,呈現一個看起來像5歲小孩的東西已經不再是一個選擇,所以資料科學家需要一個有吸引力和簡單易用的資料可視化庫,
今天我們將比較其中的兩個-Matplotlib和ggplot2,

為什么是這兩個?Matplotlib是我學習的第一個可視化庫,但最近我越來越喜歡R語言的ggplot2了,但是今天我們將在這兩個庫中重新創建五個相同的圖,看看代碼和美學方面的進展,
資料呢?我們將使用兩個著名的資料集:mtcars和航空乘客,你可以通過匯出CSV功能通過RStudio獲得第一個,第二個在這里可用:https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv
以下是R和Python的庫匯入:
R:
library(ggplot2)
Python:
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
mtcars = pd.read_csv('mtcars.csv')
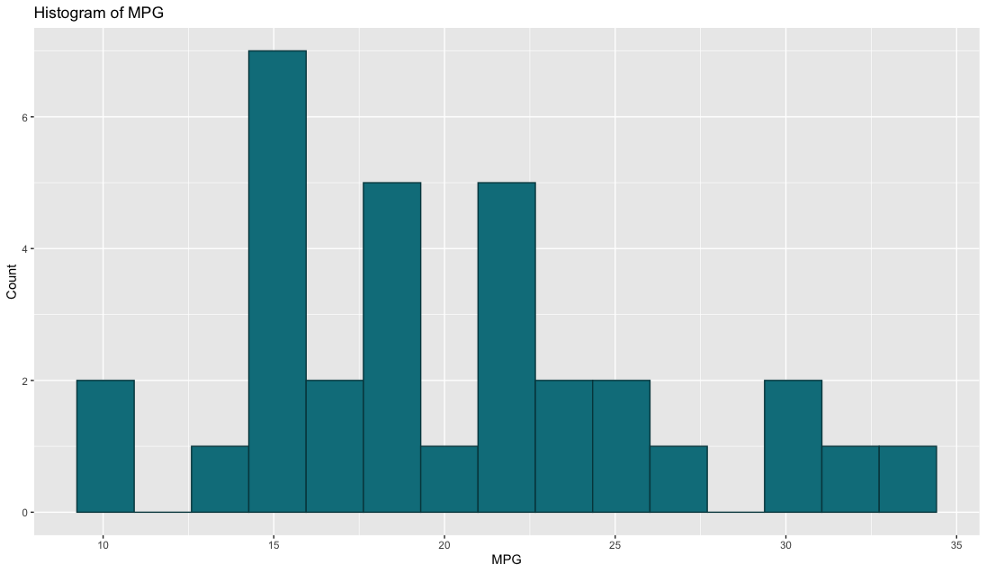
直方圖
我們使用直方圖來可視化給定變數的分布,這正是我們對mtcars資料集所做的——可視化MPG屬性的分布,
以下是R的代碼和結果:
ggplot(mtcars, aes(x=mpg)) +
geom_histogram(bins=15, fill='#087E8B', color='#02454d') +
ggtitle('Histogram of MPG') + xlab('MPG') + ylab('Count')
Python也是這樣:
plt.figure(figsize=(12, 7))
plt.hist(mtcars['mpg'], bins=15, color='#087E8B', ec='#02454d')
plt.title('Histogram of MPG')
plt.xlabel('MPG')
plt.ylabel('Count');
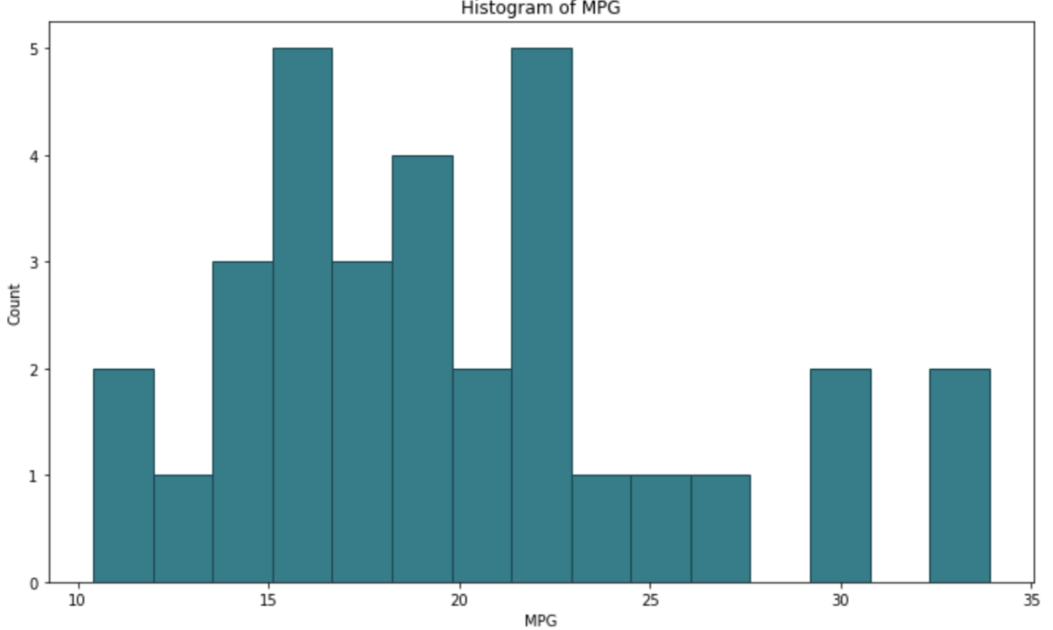
默認情況下兩者非常相似,即使我們需要撰寫的代碼量也大致相同,所以很難在這里選擇最喜歡的代碼,我喜歡Python的x軸是從0開始的,但在R中可以很容易地改變,另一方面,我喜歡R中沒有邊界,但這也是Python中易于實作的東西,
平局
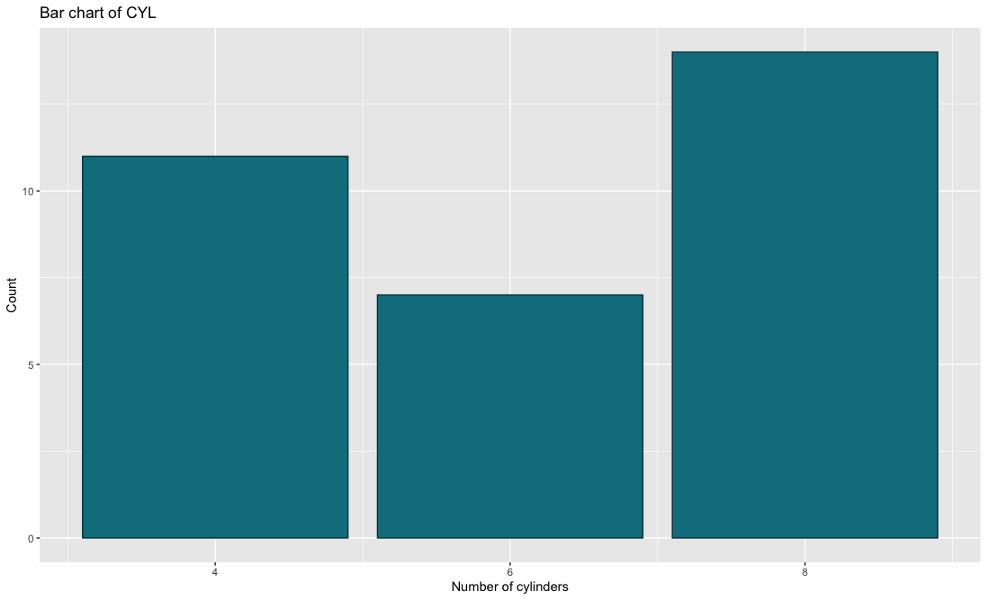
條形圖
條形圖由不同高度的矩形組成,其中高度表示給定屬性段的值,我們將使用它們來比較不同數量的圓柱體(屬性cyl)的計數,
以下是R的代碼和結果:
ggplot(mtcars, aes(x=cyl)) +
geom_bar(fill='#087E8B', color='#02454d') +
scale_x_continuous(breaks=seq(min(mtcars$cyl), max(mtcars$cyl), by=2)) +
ggtitle('Bar chart of CYL') +
xlab('Number of cylinders') + ylab('Count')
Python也是一樣:
bar_x = mtcars['cyl'].value_counts().index
bar_height = mtcars['cyl'].value_counts().values
plt.figure(figsize=(12, 7))
plt.bar(x=bar_x, height=bar_height, color='#087E8B', ec='#02454d')
plt.xticks([4, 6, 8])
plt.title('Bar chart of CYL')
plt.xlabel('Number of cylinders')
plt.ylabel('Count');
毫無疑問,R的代碼更整潔、更簡單,因為Python需要手動計算高度,從美學角度看,它們非常相似,但代碼我更喜歡R版,
獲勝者:ggplot2
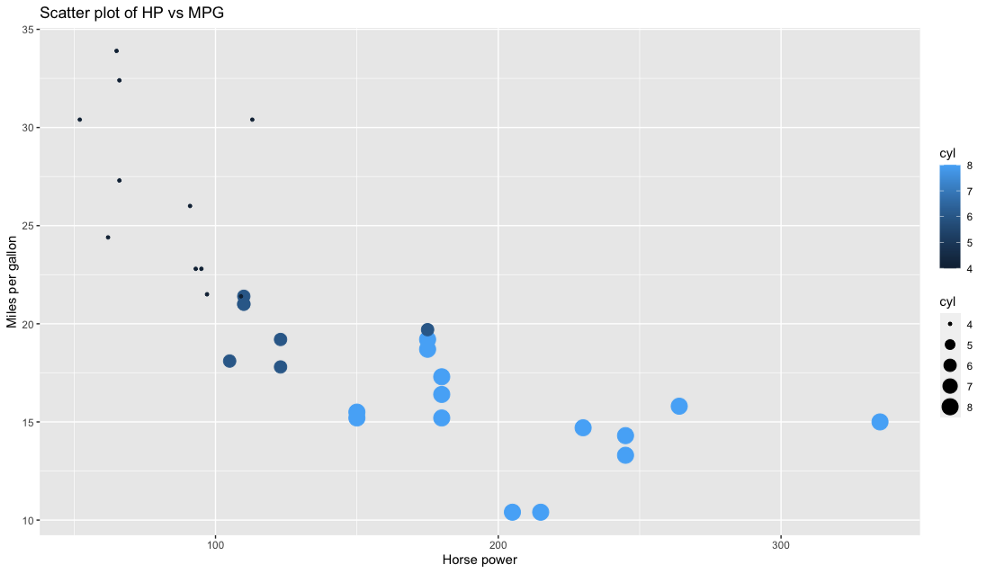
散點圖
散點圖用于可視化兩個變數之間的關系,這樣做的目的是觀察第二個變數隨著第一個變數的變化(上升或下降)會發生什么,我們還可以通過對其他屬性值的點著色來為二維圖添加另一個“維度”,
我們將使用散點圖來可視化HP和MPG屬性之間的關系,
以下是R的代碼和結果:
ggplot(mtcars, aes(x=hp, y=mpg)) +
geom_point(aes(size=cyl, color=cyl)) +
ggtitle('Scatter plot of HP vs MPG') +
xlab('Horse power') + ylab('Miles per gallon')
Python也是一樣:
colors = []
for val in mtcars['cyl']:
if val == 4: colors.append('#17314c')
elif val == 6: colors.append('#326b99')
else: colors.append('#54aef3')
plt.figure(figsize=(12, 7))
plt.scatter(x=mtcars['hp'], y=mtcars['mpg'], s=mtcars['cyl'] * 20, c=colors)
plt.title('Scatter plot of HP vs MPG')
plt.xlabel('Horse power')
plt.ylabel('Miles per gallon');
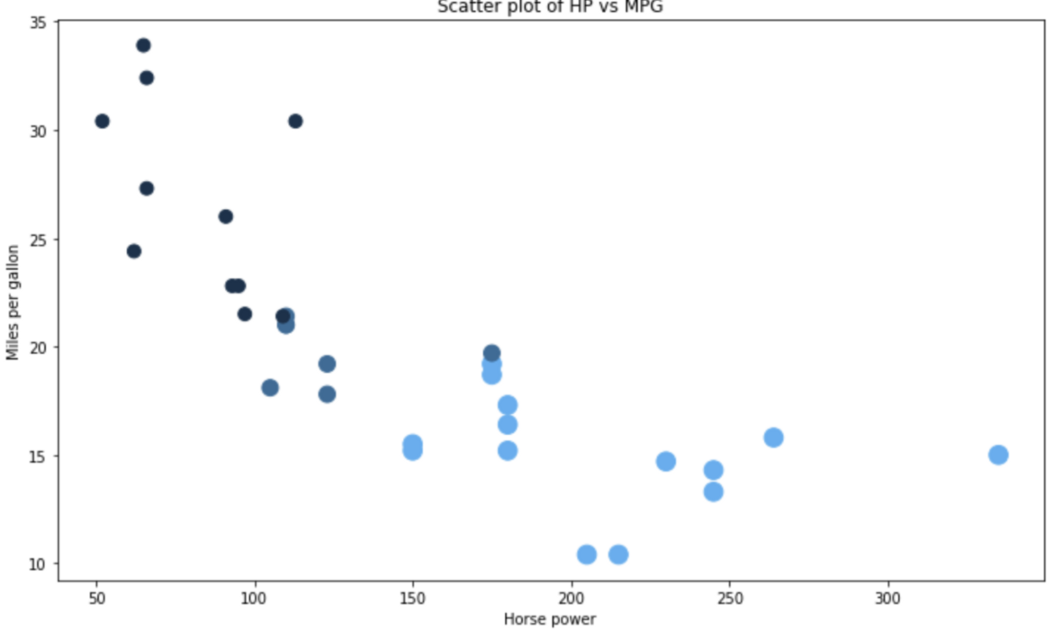
代碼方面,這是R和ggplot2的明顯勝利,Matplotlib不提供一種簡單的方法,通過第三個屬性給資料點上色,因此我們必須手動執行該步驟,尺寸也有點怪,
獲勝者:ggplot2
箱線圖
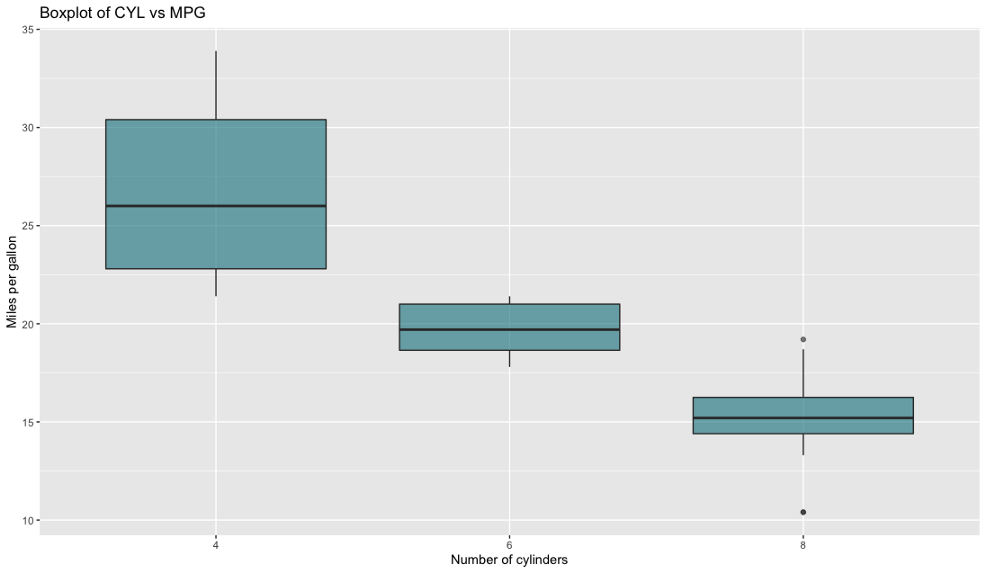
箱線圖用于通過四分位數可視化資料,它們通常會有線(胡須)從盒子里伸出來,這些線在上下四分位數之外顯示出變化,中間的線是中值,頂部或底部顯示的點被視為例外值,
我們將使用箱線圖,通過不同的CYL值來可視化MPG,
以下是R的代碼和結果:
ggplot(mtcars, aes(x=as.factor(cyl), y=mpg)) +
geom_boxplot(fill='#087E8B', alpha=0.6) +
ggtitle('Boxplot of CYL vs MPG') +
xlab('Number of cylinders') + ylab('Miles per gallon')
Python也是一樣:
boxplot_data = https://www.cnblogs.com/panchuangai/archive/2020/10/21/[
mtcars[mtcars['cyl'] == 4]['mpg'].tolist(),
mtcars[mtcars['cyl'] == 6]['mpg'].tolist(),
mtcars[mtcars['cyl'] == 8]['mpg'].tolist()
]
fig = plt.figure(1, figsize=(12, 7))
ax = fig.add_subplot(111)
bp = ax.boxplot(boxplot_data, patch_artist=True)
for box in bp['boxes']:
box.set(facecolor='#087E8B', alpha=0.6, linewidth=2)
for whisker in bp['whiskers']:
whisker.set(linewidth=2)
for median in bp['medians']:
median.set(color='black', linewidth=3)
ax.set_title('Boxplot of CYL vs MPG')
ax.set_xlabel('Number of cylinders')
ax.set_ylabel('Miles per galon')
ax.set_xticklabels([4, 6, 8]);
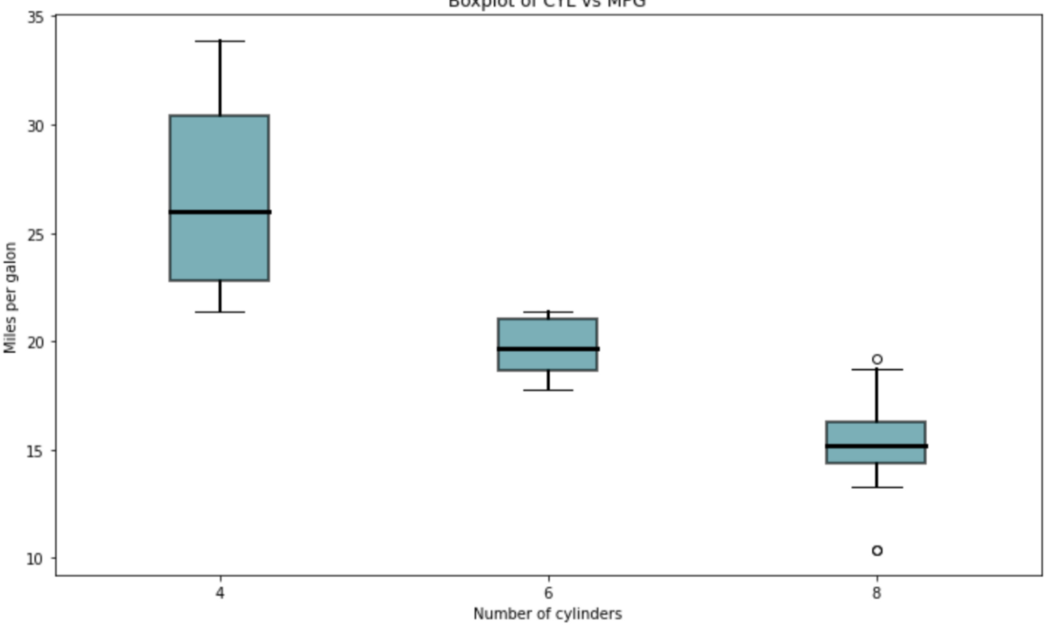
有一件事是立即可見的-Matplotlib需要大量的代碼來生成一個外觀不錯的boxplot,ggplot2不是這樣,到目前為止,R是這里明顯的贏家,
獲勝者:ggplot2
折線圖
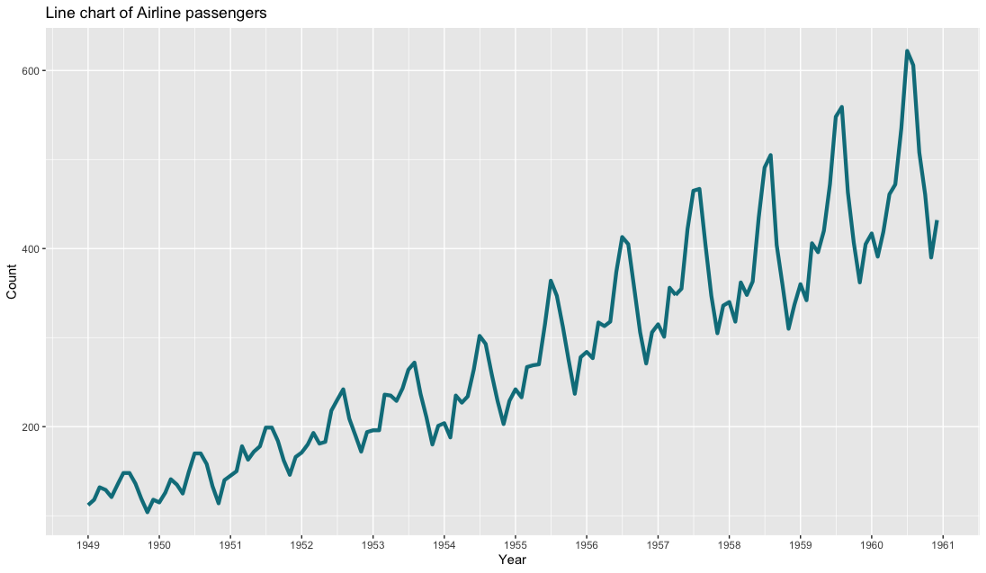
現在我們將從mtcars資料集轉移到airline passengers資料集,我們將使用它創建一個帶有日期格式的x軸的簡單折線圖,這并不像聽起來那么容易,
以下是R的代碼和結果:
ap <- read.csv('https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv')
ap$Month <- as.Date(paste(ap$Month, '-01', sep=''))
ggplot(ap, aes(x=Month, y=Passengers)) +
geom_line(size=1.5, color='#087E8B') +
scale_x_date(date_breaks='1 year', date_labels='%Y') +
ggtitle('Line chart of Airline passengers') +
xlab('Year') + ylab('Count')
Python也是一樣:
ap = pd.read_csv('https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv')
ap['Month'] = ap['Month'].apply(lambda x: pd.to_datetime(f'{x}-01'))
fig = plt.figure(1, figsize=(12, 7))
ax = fig.add_subplot(111)
line = ax.plot(ap['Month'], ap['Passengers'], lw=2.5, color='#087E8B')
formatter = mdates.DateFormatter('%Y')
ax.xaxis.set_major_formatter(formatter)
locator = mdates.YearLocator()
ax.xaxis.set_major_locator(locator)
ax.set_title('Line chart of Airline passengers') ax.set_xlabel('Year') ax.set_ylabel('Count');
從美學角度來看,這些圖表幾乎完全相同,但在代碼量方面,ggplot2再次擊敗Matplotlib,與Python相比,R在X軸顯示日期要容易得多,
獲勝者:ggplot2
結論
在我看來,ggplot2在簡單性和資料可視化美觀方面是一個明顯的贏家,幾乎總是可以歸結為非常相似的3-5行代碼,而Python則不是這樣,
原文鏈接:https://towardsdatascience.com/matplotlib-vs-ggplot2-which-to-choose-for-2020-and-beyond-ced5e294bfdc
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/184931.html
標籤:其他
上一篇:Pipeline, ColumnTransformer和FeatureUnion
下一篇:看看哪里錯了,快崩潰了