通過一個示例,來說明索引的代價,如下,給 person_info表中創建一個聯合索引 idx_name_birthday_phone_number,
CREATE TABLE person_info(
id INT NOT NULL auto_increment,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name, birthday, phone_number)
);以 idx_name_birthday_phone_number索引為例,看下邊這個查詢:
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow';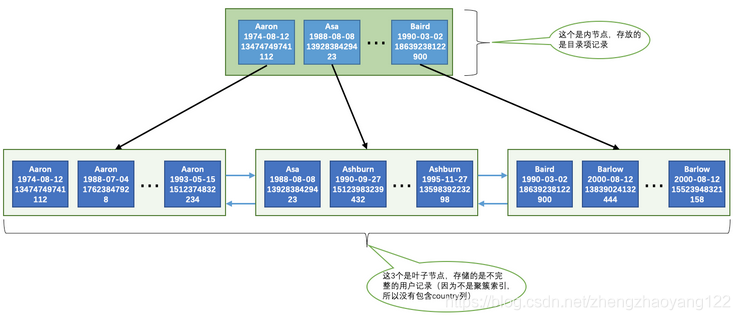
在使用 idx_name_birthday_phone_number索引進行查詢時大致可以分為這兩個步驟:
【1】索引 idx_name_birthday_phone_number對應的 B+樹中取出 name值在 Asa~Barlow之間的用戶記錄,
【2】由于索引 idx_name_birthday_phone_number對應的 B+樹用戶記錄中只包含name、birthday、phone_number、id這4個欄位,而查詢串列是*,意味著要查詢表中所有欄位,也就是還要包括 country欄位,這時需要把從上一步中獲取到的每一條記錄的 id欄位,再去聚簇索引對應的 B+樹中找到完整的用戶記錄,也就是我們通常所說的回表,然后把完整的用戶記錄回傳給查詢用戶,
讀取索引 idx_name_birthday_phone_number資料中,在Asa~Barlow之間的記錄在磁盤中的存盤是相連的,集中分布在一個或幾個資料頁中,我們可以很快的把這些連著的記錄從磁盤中讀出來,這種讀取方式我們也可以稱為順序I/O,
而獲取到的記錄的 id欄位的值可能并不相連,而在聚簇索引中記錄是根據id(也就是主鍵)的順序排列的,所以根據這些并不連續的 id值到聚簇索引中訪問完整的用戶記錄可能分布在不同的資料頁中,這樣讀取完整的用戶記錄可能要訪問更多的資料頁,這種讀取方式我們也可以稱為隨機I/O,
所以這個使用索引 idx_name_birthday_phone_number的查詢有這么兩個特點:
【1】使用到兩個 B+樹索引,一個二級索引,一個聚簇索引,
【2】訪問二級索引使用順序I/O,訪問聚簇索引使用隨機I/O,
需要回表的記錄越多,使用二級索引的性能就越低,甚至讓某些查詢寧愿使用全表掃描也不使用二級索引,比方說 name值在Asa~Barlow之間的用戶記錄數量占全部記錄數量90%以上,那么如果使用 idx_name_birthday_phone_number索引的話,有90%多的 id值需要回表,這不是吃力不討好么,還不如直接去掃描聚簇索引(也就是全表掃描),
查詢優化器做的作業,查詢優化器會事先對表中的記錄計算一些統計資料,然后再利用這些統計資料根據查詢的條件來計算一下需要回表的記錄數,需要回表的記錄數越多,就越傾向于使用全表掃描,反之傾向于使用二級索引 + 回表的方式,比方說上邊的查詢可以改寫成這樣:
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow' LIMIT 10;添加了LIMIT 10的查詢更容易讓優化器采用二級索引 + 回表的方式進行查詢,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/184960.html
標籤:其他
上一篇:三分鐘掌握ACID、臟讀、幻讀、不可重復讀、事務隔離級別
下一篇:MySQL面試題