資料庫概念
一、ACID 講一下
(阿里校招)
ACID是事務的四個特性,分別是 原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、持久性(Durability) ,
- 原子性
原子性是指事務是一個不可分割的作業單位,事務中的操作要么都發生,要么都不發生,最經典的就是轉賬案例,我們把轉入和轉出當做一個事物的話,就需要在SQL中顯式指定開啟事務, - 一致性
一致性是說資料庫事務不能破壞關系資料的完整性以及業務邏輯上的一致性 ,我們可以從資料庫層面和業務層面兩方面來保證,資料庫層面我們可以設定觸發器,外鍵,表,行約束等來保證,業務層面就是我們Java工程師的作業啦 - 隔離性
隔離性指的是多個事務并發訪問時,事務之間是隔離的,一個事務不應該影響其它事務運行效果, 多個事務并發訪問時,事務之間是隔離的,一個事務不應該影響其它事務運行效果, 這個點又引申出了下面兩道題,以及后邊的加鎖和阻塞, - 持久性
持久性意味著即使出現了任何事故比如斷電等,事務一旦提交,則持久化保存在資料庫中,不會被回滾
二、說一下臟讀,不可重復讀和幻讀
- 臟讀
臟讀: 意味著一個事務讀取了另一個事務未提交的資料,而這個資料是有可能回滾的,即這個事務讀取的資料是不正確的 - 不可重復讀
不可重復讀: 在資料庫訪問中,一個事務范圍內兩個相同的查詢卻回傳了不同資料,這是由于查詢時系統中其他事務修改的提交而引起的,即這個事物在讀的程序中被修改了 - 幻讀
幻讀:當一個事務對整個table進行修改之后,第二個事物向表中插入了一行資料,此時第一個事物發現了新插入的沒有修改的資料行,好像發生了幻覺一樣,eg:本身應該是修改5行資料,但是現在有6行資料發生修改,
三、 資料庫的隔離級別
-
讀未提交(read uncommitted)
理解:一個事務還沒提交時,它做的變更就能被別的事務看到
影響:會出現幻讀,不可重復讀,臟讀
具體操作:更新資料時加上行級共享鎖,事務結束即釋放
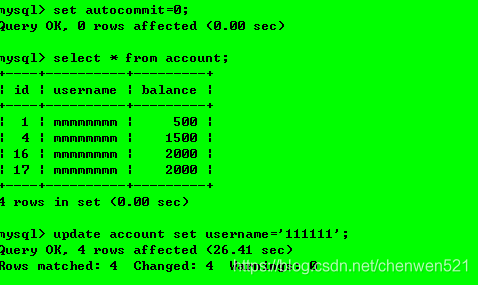
具體操作:操作1:開啟事務1和2,并設定隔離級別為未提交資料(read uncommitted)


操作2:事務1對資料庫內容進行更新,但并未提交事務;
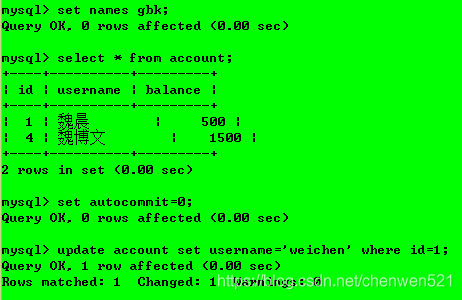
操作3:事務2查詢資料庫,查到的是事務1更改后但是還未提交的資料,故出現了“臟讀”現象,
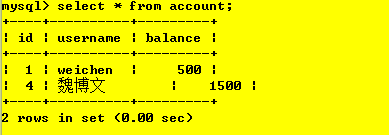
操作4:事務1對事務進行提交或者回滾;commit or rollback;
該級別問題:會出現“臟讀”現象,
解決辦法:提高隔離級別,設定為read committed; -
讀已提交(read committed)
解釋:一個事務提交之后,它做的變更才會被其他事務看到
影響:會出現幻讀,不可重復讀,不會出現臟讀
解決方法:寫資料加行級排他鎖,這樣寫程序是無法讀取的,直到事務處理完畢才釋放排他鎖,給讀的資料加行級共享鎖,這樣讀的時候也是無法寫的,但是一旦讀完該行就釋放共享鎖
MySQL會在SQL陳述句開始執行時創建一個視圖
具體操作:
操作1:給兩個事務都設定隔離級別為read committed;


操作2:事務1對第一行資料進行修改操作,但并未提交;
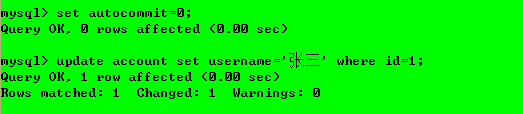
操作3:事務2對資料庫內容進行查詢;
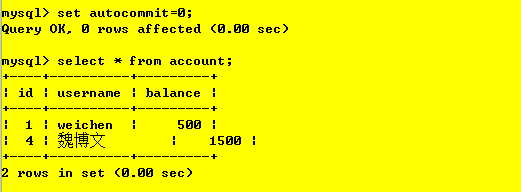
解釋:查詢到的依然是未進行更改前的內容,故解決了“臟讀”問題,
出現問題:會出現不可重復讀現象,即在一次事務中,事務2兩次查詢到的資料不一致,操作4:事務1提交更改操作;
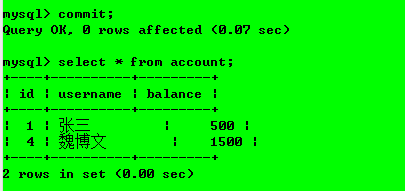
操作5:此時事務2再次對資料庫進行查詢

解釋:此時讀到的資料出現了不一致情況
解決辦法:提高隔離級別,設定為可重復讀(repeatable read)級別 -
可重復讀 (repeatable read)
解釋:一個事務執行程序中看到的資料,總是跟這個事務在啟動時看到的資料是一致的
影響:會出現幻讀,不會出現不可重復讀,臟讀
解決方法:給寫的資料加行級排他鎖,事務結束釋放,給讀的資料加行級共享鎖,事務結束后釋放
MySQL會在事務開始時創建一個一致性視圖(接下面的MVCC),事物結束時銷毀
具體操作:
操作1:更改事務1,2的隔離級別


操作2:對事務1進行更改操作
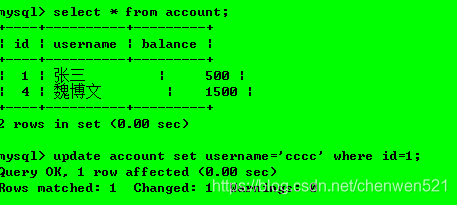
操作3:事務2查詢資料庫

操作4:事務1提交

操作5:事務2再次查詢

操作6:事務2提交,并再次讀取資料庫中的資料,
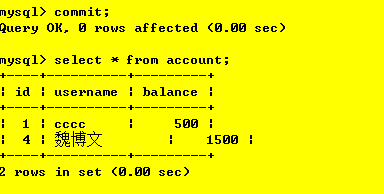
解釋:事務2提交之后,再次查詢即能查詢到最新資料,事務1進行更改操作的前后,事務2對資料庫兩次查詢操作結果一致,解決了不可重復讀問題,保證在一次事務中,事務2所讀到的內容是完全一致的,
問題:會出現“幻讀”情況,
操作1:事務1和事務2都開啟新的事務;
操作2:事務2進行插入操作并提交,

操作3:事務1對資料庫進行更新操作;
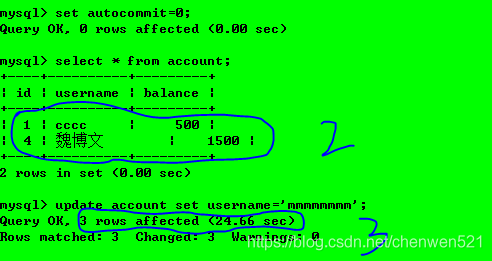
問題:“幻讀”–原本是兩行,但是卻顯示3行資料改變, -
可串行化(serializable)
解釋:當出現讀寫鎖沖突的時候,后訪問的事務必須等前一個事務執行完成,才能繼續執行
影響:不會出現幻讀,不可重復讀,臟讀
解決方法:事務讀資料則加表級共享鎖,事務寫資料則加表級排他鎖
不區分快照度與當前讀
具體操作:
操作1:設定事務1和事務2的隔離級別為可串行化,
操作2:對事務1進行更新操作
操作3:對事務2進行插入操作
解釋:此時出現錯誤
操作4:提交事務1
操作5:對事務2進行插入操作

解釋:此時可以正常操作,相當于是加鎖,等一個事務完成后,才能進行插入操縱,
其中,Oracle和SQLServer都是讀已提交,但MySQL默認的隔離級別是可重復讀 ,這是一個MySQL5.0之前的上古遺留版本問題,當時的binlog只有STATEMENT格式,用RC會出現bug,
當面試官問我們專案用的哪個隔離級別,就我自己來說,如果看我之前的文章,我寫過我搭建了一個博客,對于博客來說,我肯定要說讀已提交,這樣的并發度更高,同時,在我們的互聯網專案中可以接受重復讀帶來的一些不便,
同時,既然問到了資料庫的隔離級別,那么離下面的鎖也不遠了
四、三大范式
- 第一范式
第一范式: 所有欄位值都是不可分解的原子值 ,例如有一個列是電話號碼一個人可能有一個辦公電話一個移動電話,第一范式就需要拆開成兩個屬性, - 第二范式
第二范式:非主屬性完全函式依賴于候選鍵,如PersonID,ProductID,ProductName,PersonName可以看到,PersonID和ProductID是聯合主鍵,但是ProductName是依賴于ProductID的,只依賴了部分主鍵,沒有依賴全部主鍵,需要拆分成三個表:PersonID、PersonName &&ProductID, ProductName&&PersonID, ProductID - 第三范式
第三范式: 每一列資料都和主鍵直接相關,而不能間接相關,即沒有傳遞依賴,
如OrderID,ProductID,ProductName,OrderID是主鍵,但是ProductID依賴了OrderID,而ProductName依賴了ProductID,等于說是間接依賴了OrderID,所以需要拆分為兩個表:OrderID, ProductID和ProductID, ProductName
這里需要指明范式不是最好的,我們需要混合使用范式和反范式 - 范式的優點
因為相對來說有較少的重復資料,范式化的更新操作要比反范式快,同時范式化需要更少的distinct和order by, - 范式的缺點
通常需要關聯,不僅代價昂貴,也可能會使的一些索引無效, - 常用的反范式方法:
復制:在兩個表中根據實際業務情況存盤部分相同的欄位列,即有利于查詢,也不會把表搞的太大
快取:對于需要多次join查詢的表,可以在一個表中加入一個快取列,用來快取所join表的部分常用資料,如count等,我們需要實時更新該快取
五、說一下內連接和外連接
- 內連接
內連接分為等值連接和自然連接,等值連接是給定條件,只要滿足條件即可連接,自然連接是要連接兩個表中具有相同屬性的資料,只有兩個表相匹配的行才能在結果集中出現,回傳的結果集選取兩個表中所匹配的資料,舍棄不匹配的資料,(此處可以再進行優化)
select fieldlist from table1 [inner] join table2 on table1.column = table2.column
- 外連接
內連接保證兩個表中的所有行都滿足條件,而外連接則不然,外連接不僅僅包含符合連接條件的行,而且還包括左表(左外連接),右表(右外連接),或者兩個邊表(全外連接)中的所有資料行 ,
select fieldlist from table1 left/ right outer join table2 on table1.column = table2.column
**目前(8.0)MySQL不支持全外連接**
MySQL索引
索引是一種排好序的資料結構,用于幫助我們在大量資料中快速定位到我們想要查找的資料,可以加快查的速度,但是會增加容量,降低增,刪,改的速度,
面試題之適合索引和不適合索引

面試題之索引失效(最左前綴)
-
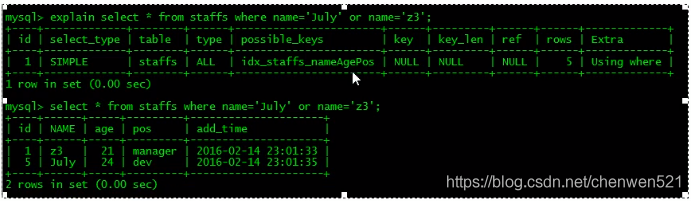
全值匹配我最愛,所建立的索引欄位個數個順序和將要查詢的完全吻合,
比如:需要查找的欄位是name,age,pos,且建立的索引也是name,age,pos,當查找的欄位是age,pos時,索引失效, -
最左前綴匹配:如果索引了多列,要遵守最左前綴法則,指的是查詢從索引的最左前列開始并且不跳過索引中的列,(說一下聯合索引的底層原理 )
-
不在索引列上做任何操作(計算、函式、(自動 or 手動)型別轉換),會導致索引失效而轉向全表掃描
eg :where left(NAME,4)='July;' -
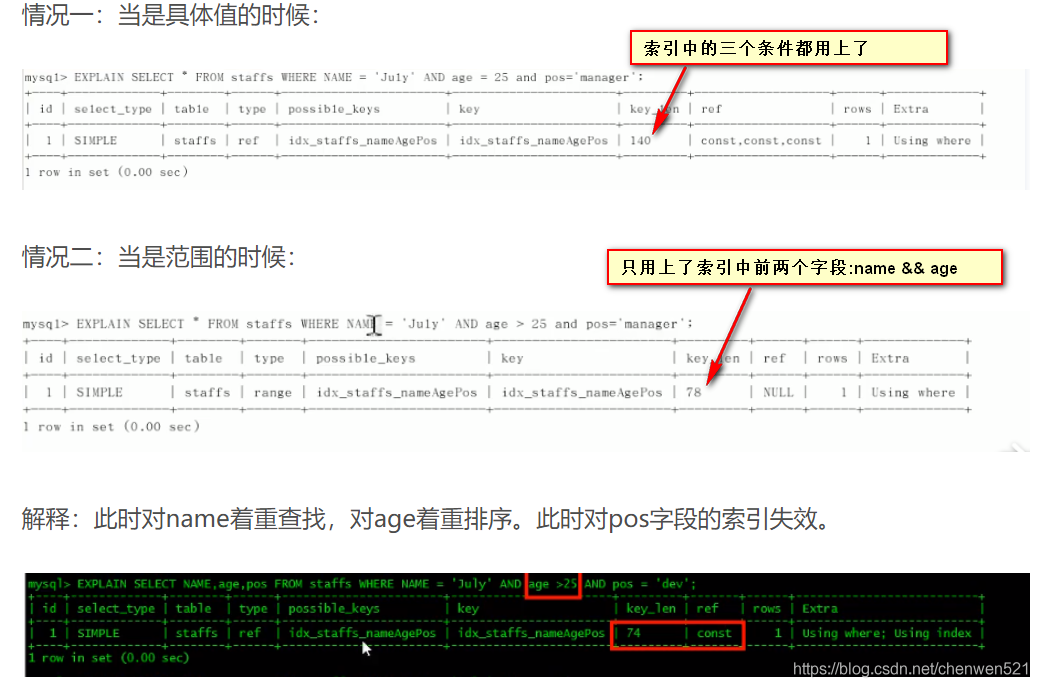
存盤引擎不能使用索引中范圍條件右邊的列:
-
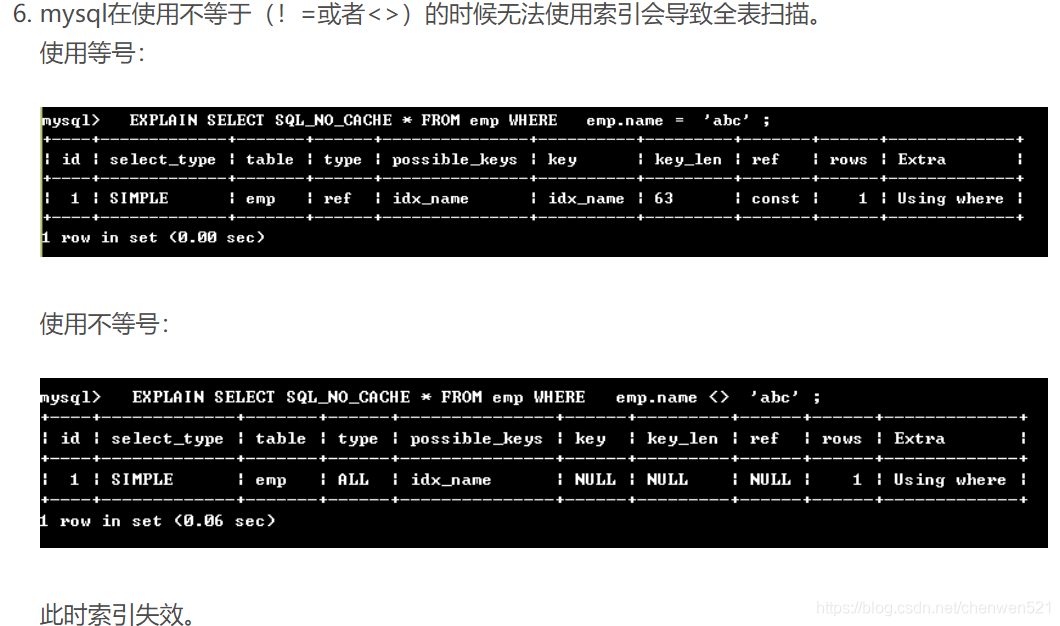
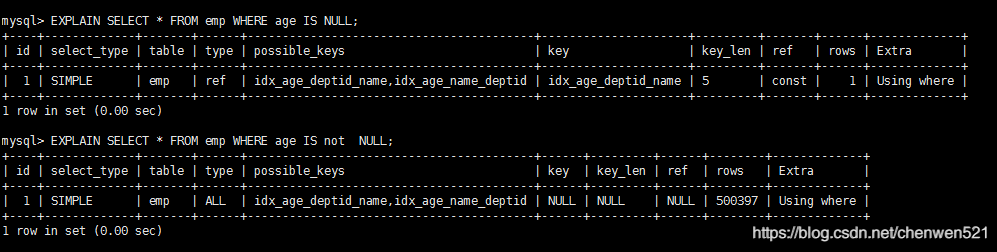
mysql在使用不等于(!=或者<>)的時候無法使用索引會導致全表掃描
-
is not null 也無法使用索引,但是is null是可以使用索引的,
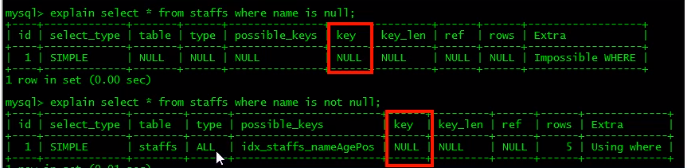
都沒有用上,impossible where,因為該欄位本不應該為null
-
like以通配符開頭(’%abc…’)mysql索引失效會變成全表掃描的操作
解決辦法:
a. 把%放在右邊,
b. 建立復合索引,
case1:%july%

case2:%july

case3:july%

面試: 解決like‘%字串%’時索引不被使用的方法,
-
建立復合索引:

case1:

case2:

case3:???有疑問,id自帶主鍵索引,為什么會用上…

case4:

case5:

總結:當建立了復合索引之后,select后面跟的欄位只要是在索引范圍內,或者是主鍵,單個或者多個都可以用上建立的索引using index,
case 6:

case 7:

case 8:

case 9:

case10:

case9和case10總結:
查詢欄位可以在索引范圍之內,但是不能超過索引范圍, -
字串不加單引號索引失效,
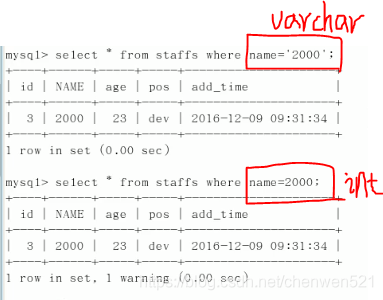
Mysql進行了自動的隱式型別轉換操作
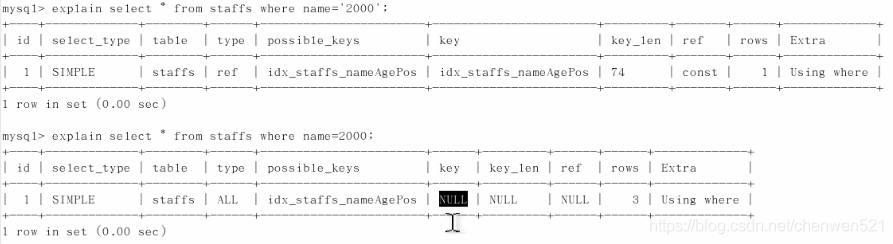
-
少用or,用它連接時會導致索引失效,但是自己試的時候沒有失效,,,

一、MySQL有哪幾種索引型別,各自特點
常見的MySQL索引結構有B-樹索引,B+樹索引,Hash索引和全文索引
-
B-Tree索引
(1) 因為存盤引擎不用進行全表掃描來獲取資料,直接從索引的根節點開始搜索,從而能加快訪問資料的速度
(2) B-Tree對索引是順序組織存盤的,很適合查找范圍資料,
(3) 適用于全鍵值、鍵值范圍或者鍵前綴查找(根據最左前綴查找),
(4) 限制:對于聯合索引來說,如果不是從最左列開始查找,則無法使用索引;不能跳過索引中的列 , -
B+Tree索引
(1) 是B-Tree索引的變種,現在主流的存盤引擎都不用單純的B-Tree,而是其變種B+Tree或者T-Tree等等
(2) 和B-Tree最主要的區別就是B+Tree的內節點不存盤data,只存盤key,葉子節點不存盤指標, -
Hash索引
(1) 基于Hash表實作,只有Memory存盤引擎顯式支持哈希索引 ,
(2) 適合等值查詢,如=、in()、<=>,不支持范圍查詢,
(3) 因為不是按照索引值順序存盤的,就不能像B+Tree索引一樣利用索引完成排序 ,
(4) Hash索引在查詢等值時非常快
(5) 因為Hash索引始終索引的所有列的全部內容,所以不支持部分索引列的匹配查找 ,
(6) 如果有大量重復鍵值得情況下,哈希索引的效率會很低,因為存在哈希碰撞問題,
(7) 程式員可以在B+Tree索引的基礎上創建自適應Hash索引 , -
全文索引
(1) MyISAM和InnoDB都支持全文索引
(2) 有三種模式:自然語言模式,布爾模式和查詢擴展模式 -
R-Tree索引
MyISAM支持R-Tree索引,這個和全文索引基本不問
二、 B+樹索引和hash索引的區別
- 兩者概念區別
B+樹是一個平衡的多叉樹,B+樹從根節點到葉子節點的搜索效率基本相當,不會出現大幅波動,
哈希索引采用一定的哈希演算法,把鍵值換成新的哈希值,檢索時不需要類似B+樹那樣從根節點逐級查找,只需一次哈希演算法即可立刻定位到相應的位置, - 用法區別
(1) 等值查詢,哈希索引具有絕對優勢(前提是:沒有大量重復鍵值,如果大量重復鍵值時,哈希索引的效率很低,因為存在所謂的哈希碰撞問題),但是不支持范圍查詢,B+樹索引適合回傳查找,
(2) 利用索引排序,hash索引無法利用索引完成排序,但是B+樹索引可以 ,
(3) 聯合索引最左匹配規則,hash索引不支持多了聯合索引的最左匹配規則,但是B+樹索引支持, - 引擎支持區別
MySQL中,只有HEAP/MEMORY引擎才顯示支持哈希索引,而常用的InnoDB引擎中默認使用的是B+樹索引,它會實時監控表上索引的使用情況,如果認為建立哈希索引可以提高查詢效率,則自動在記憶體中的“自適應哈希索引緩沖區”建立哈希索引(在InnoDB中默認開啟自適應哈希索引),通過觀察搜索模式,MySQL會利用index key的前綴建立哈希索引,如果一個表幾乎大部分都在緩沖池中,那么建立一個哈希索引能夠加快等值查詢,
注意:在某些作業負載下,通過哈希索引查找帶來的性能提升遠大于額外的監控索引搜索情況和保持這個哈希表結構所帶來的開銷,但某些時候,在負載高的情況下,自適應哈希索引中添加的read/write鎖也會帶來競爭,比如高并發的join操作,like操作和%的通配符操作也不適用于自適應哈希索引,可能要關閉自適應哈希索引,
三. B樹和B+樹的區別
這個題其實偏向于資料結構了,這里不多講,只說一下針對資料庫來說,面試該怎么回答,派生問題:二叉樹,二叉搜索樹,B樹,B+樹,遇到坑爹的面試官可能讓你寫一個B+樹…
-
二叉樹
任何節點的左子節點的鍵值都小于當前節點的鍵值,右子節點的鍵值都大于當前節點的鍵值 -
平衡二叉樹/AVL樹
當二叉樹非常極端,變成一個鏈表后,它就沒有了二叉樹的相關優秀性質了,所以我們在insert節點的時候,需要不斷的旋轉,來使二叉樹平衡,最終使得其查詢效率最高,調整一共分為四種情況:LL,RR,LR,RL -
B-樹
因為資料庫中大部分資料都存在于磁盤,但是IO一次磁盤的代價相對來說比較大,我們需要盡可能的減少AVL樹的深度,即增加每個節點的資料量,這便是B-樹的由來,
每一個節點稱為頁,也就是一個磁盤塊, B樹相對于平衡二叉樹,每個節點存盤了更多的鍵值(key)和資料(data),并且每個節點擁有更多的子節點, -
B+樹
是B-樹的變形,相對于B-樹來說,B+樹最主要的不同之處就是其非葉子節點上是不存盤資料的,資料全在葉子節點存盤,這就意味著B+樹比B-樹更胖
因為B+樹索引的所有資料均存盤在葉子節點,而且資料是按照順序排列的,那么B+樹使得范圍查找,排序查找,分組查找以及去重查找變得例外簡單,而B樹因為資料分散在各個節點,要實作這一點是很不容易的,
四、 InnoDB為什么要使用B+樹作為索引
這時說出B+樹索引的優點即可,同時也可能會引出Hash索引和全文索引,InnoDB中索引即資料,資料即索引
因為B+樹索引的所有資料均存盤在葉子節點,而且資料是按照順序排列的,那么B+樹使得范圍查找,排序查找,分組查找以及去重查找變得例外簡單,而B樹因為資料分散在各個節點,要實作這一點是很不容易的,
五、在mysql中為什么要用B+樹結構創建索引
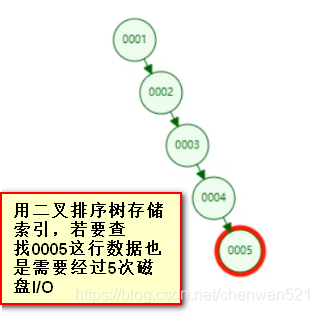
- 用二叉樹存盤
- 紅黑樹
缺點:隨著資料量的增大,樹的深度會增加
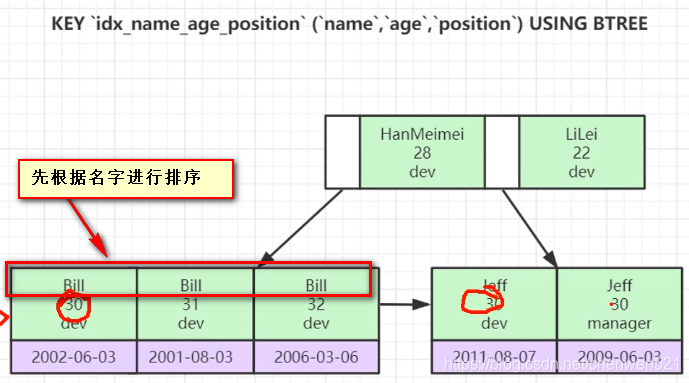
聯合索引的底層存盤結構
五、怎么查看MySQL陳述句有沒有用到索引
通過explain,如
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title='Senior Engineer' AND from_date='1986-06-26';
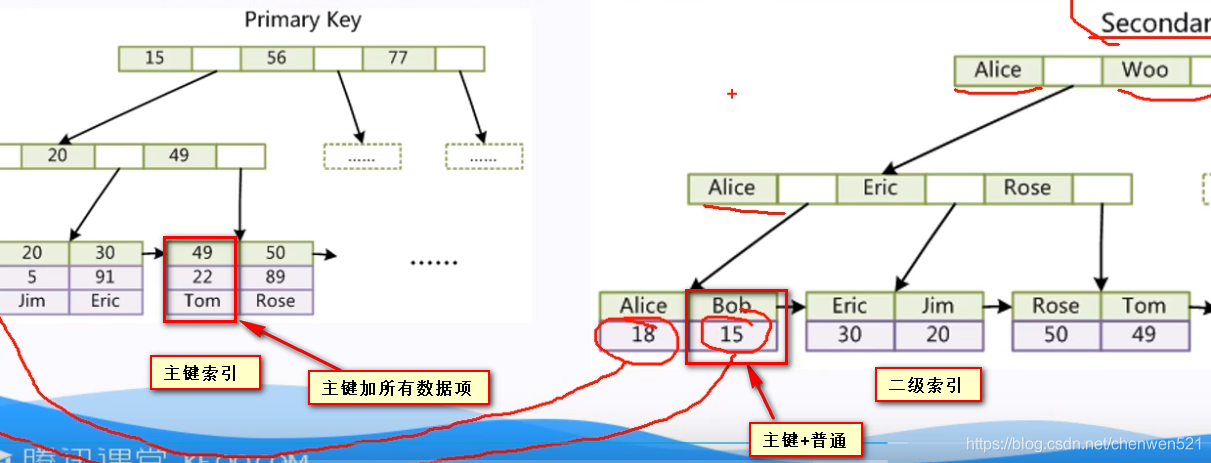
六、聚簇索引與非聚簇索引(不熟)
4. 聚簇索引和非聚簇索引是建立在B+樹的基礎上,
5. 聚簇索引:key為主鍵,value為其余列的資料,一個表只能有一個聚簇索引
6. 非聚簇索引:除了聚簇索引外的都叫非聚簇索引
7. 對于MyISAM的主鍵索引來說,它的非聚簇索引是key為主鍵,value為行號(不一定)
8. 對于MyISAM的二級索引來說,它的非聚簇索引是key為其他列,value為行號(不一定)
9. 對于InnoDB的二級索引來說,它的非聚簇索引是key為其他列,value是主鍵
10. 非聚簇索引也叫二級索引
11. 非聚集索引與聚集索引的區別在于非聚集索引的葉子節點不存盤表中的資料,而是存盤該列對應的主鍵(行號)
12. 對于InnoDB來說,想要查找資料我們還需要根據主鍵再去聚集索引中進行查找,這個再根據聚集索引查找資料的程序,我們稱為回表,第一次索引一般是順序IO,回表的操作屬于隨機IO,需要回表的次數越多,即隨機IO次數越多,我們就越傾向于使用全表掃描
通常情況下, 主鍵索引查詢只會查一次,而非主鍵索引(非聚簇索引)需要回表查詢多次,當然,如果是覆寫索引的話,查一次即可
注意:MyISAM無論主鍵索引還是二級索引都是非聚簇索引,而InnoDB的主鍵索引是聚簇索引,二級索引是非聚簇索引,我們自己建的索引基本都是非聚簇索引
七、 覆寫索引
如果一個索引包含(覆寫)所有需要查詢欄位的值,我們就稱之為"覆寫索引",如select id from tab where id = 1,并且id是tab的索引,這就是一個覆寫索引,
當非聚簇索引是覆寫索引的時候,就只用查詢一次即可??
八、 組合索引
(新浪微博)
因為每個select只能選擇一個索引,當where條件過多時,我們可以考慮建立聯合索引,即把多個列作為索引:
create index inx_col1_col2 on tab (col1,col2);
問這個問題主要是引出下面的最左前綴原則
九、 MySQL的最左前綴原則
這里主要是向面試官說明組合索引在B+樹上如何被創建的,對于索引(a,b,c),引擎會先按照a排序,當a相等時,再按照b排序,當b相等時,再按照c排序
對于索引(a,b,c)來說,能命中的where陳述句有
where a = 1,
where a = 1 and b = 1,
where a = 1 and b = 1 and c = 1.
where a like '1%',對于這個,可能會引出前綴索引
注意:
(1) 對于表tab id,name,gender來說:
- 當SQL為
select name, id from tab where name = 'stalern',索引為id, name,此時索引是有效的,走得是覆寫索引,但是命中率特別低 . - 當SQL為
select * from tab where id > 0 and id < 10 and name > 'stalern',索引為id,name,此時并不會用到id,name,而是其中的id索引,沒有name,但是當SQL為select * from tab where id = 0 and name > 'a' and name < 'c'時,這個索引是可以全部用到的,
十. 前綴索引
因為可能我們索引的欄位非常長,這既占記憶體空間,也不利于維護,所以我們就想,如果只把很長欄位的前面的公共部分作為一個索引,就會產生超級加倍的效果,但是,我們需要注意,order by不支持前綴索引
流程是:
- 先計算完整列的選擇性
select count(distinct col_1)/count(1) from table_1
- 再計算不同前綴長度的選擇性
select count(distinct left(col_1,4))/count(1) from table_1
- 找到最優長度之后,創建前綴索引
create index idx_front on table_1 (col_1(4))
十一、 索引下推
(阿里社招 )
- MySQL 5.6引入了索引下推優化,默認開啟,使用
SET optimizer_switch = ‘index_condition_pushdown=off;可以將其關閉, - 主要目的:減少IO
- 索引下推優點:
A. 減少存盤引擎查詢基礎表的次數,
B. 可以減少MySQL服務器從存盤引擎接收資料的次數,
C. 在InnoDB中只針對二級索引有效 ,因為InnDB的聚簇索引會將整行資料讀到InnDB的緩沖區,這樣一來索引條件下推的主要目的減少IO次數就失去了意義,因為資料已經在記憶體中了,不再需要去讀取了, - 解釋:
譬如,在 people_table中有一個二級索引(zipcode,lastname,firstname),查詢是SELECT * FROM people WHERE zipcode=’95054′ AND lastname LIKE ‘%etrunia%’ AND address LIKE ‘%Main Street%’;
--------沒有使用索引條件下推技術:MySQL會通過zipcode=’95054’從存盤引擎中查詢對應的資料,回傳到MySQL服務端,然后MySQL服務端基于lastname LIKE ‘%etrunia%’ and address LIKE ‘%Main Street%’來判斷資料是否符合條件 ,
---------使用了索引下推技術:MYSQL首先會回傳符合zipcode=’95054’的索引,然后根據lastname LIKE ‘%etrunia%’ and address LIKE ‘%Main Street%’來判斷索引是否符合條件,如果符合條件,則根據該索引來定位對應的資料,如果不符合,則直接reject掉 ,(只有當索引符合條件時才會將資料檢索出來回傳給MySQL服務器,)
十二、 查詢在什么情況下不走索引
首先,我們可以說通過explain去排查一個慢查詢,進而找到它的索引(參看第五題),當創建索引卻不走索引時,我們就需要考慮到優化器的問題,
在一條單表查詢陳述句真正執行之前,MySQL的查詢優化器會找出執行該陳述句所有可能使用的方案,對比之后找出成本最低的方案,這個成本最低的方案就是所謂的執行計劃,
- 優化程序大致如下:
(1) 根據搜索條件,找出所有可能使用的索引
(2) 計算全表掃描的代價
(3) 計算使用不同索引執行查詢的代價
(4) 對比各種執行方案的代價,找出成本最低的那一個 - 那么,有哪幾種情況明明設了索引卻不走索引呢?
舉例:假設索引為(a,b,c)
a. ASC和DESC索引混合使用的排序:select * from tab order by a, b desc limit 10;
b. 違背最左前綴原則:select * from tab where b = ‘1’;
c. WHERE?句中出現非排序使?到的索引列:select * from tab d = ‘1’ order by a limit 10;
d. 排序列包含非同?個索引的列:select * from tab order by a, d limit 10;
e. WHERE子句中出現計算:select * from tab where a * 4 = 2;
f. WHERE子句中出現null值:select * from tab where a = null;
g. WHERE子句中使用!=或<>運算子:select * from tab where a != 1;
十三. MySQL如何為表欄位添加索引
1.添加主鍵索引
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
2.添加唯一索引
ALTER TABLE `table_name` ADD UNIQUE ( `column` )
3.添加普通索引
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
4.添加全文索引(適用于MyISAM,InnoDB 5.6+)
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
5.添加聯合索引
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
十四. 如何選擇索引
- 只為?于搜索、排序或分組的列創建索引
- 考慮列的基數 ,基數越大,創建索引的效果越好
- 索引列的型別盡量?,這樣B+樹中每個頁存盤的資料就會更多
- 可以使用倒敘索引或者hash索引
- InnoDB的主鍵盡量用MySQL的自增主鍵
十五. 唯一索引和普通索引選擇哪個
- 唯一索引和普通索引在讀取的時候效率基本差不多,普通索引差了一點點,主要是判斷和特殊情況下的一次IO ,
- 寫入的時候,普通索引可以利用change buffer,適合寫多讀少,比唯一索引要快 ,以業務為前提,如果要求唯一,就要選擇唯一索引,如果已經保證列的唯一,我們盡量選擇普通索引,然后把change buffer調大,
- 注:對change buffer 的理解:
【(現在我們看下如果要在這張表中插入一個新記錄(4,400)的話,innodb的處理流程是什么樣的:
第一種情況是,這個記錄要更新的目標頁在記憶體中,這時,innodb的處理流程如下:
—對于唯一索引來說,找到3和5之間的位置,判斷到沒有沖突,插入這個值,陳述句執行結束
—對于普通索引來說,找到3和5的位置,插入這個值,陳述句執行結束
這樣看來,普通索引和唯一索引對更新陳述句性能影響的差別,只是一個判斷,只會耗費微小的CPU時間,
但,這不是我們關注的重點
第二種情況是,這個記錄要更新的目標頁不在記憶體中,這時,流程如下:
—對于唯一索引來說,由于需要判斷唯一性,所以要從磁盤中讀取所在的資料頁到記憶體中,判斷到沒有沖突,插入值,結束
—對于普通索引來說,則是將更新記錄在change buffer,結束)】
十六、MySQL的優化
- MySQL的查詢優化
(1) 上文中的如何選擇索引
(2) 使用連接代替子查詢
(3) 盡量用IN代替OR, OR的效率是n級別,IN的效率是log(n)級別,IN的個數建議控制在200以內,
(4) 能用BETWEEN不用IN
(5) 盡量用LIMIT,同時盡量不用count *
(6) 切分一個連接時間很長的查詢,或回傳資料量很大的查詢
(7) 分解關聯查詢,在應用層做關聯,可以更容易對資料庫進行拆分,減少鎖的競爭,減少冗余記錄的查詢
十七、MySQL大資料量下的優化
(騰訊春招)
這個題可說的點實在太多了,面試官很有可能跟據下面說的優化進而來問問題
- 建表時
(1) 此處考察如何建立索引
(2) 欄位型別盡量精確,盡量小,能用int不要用bigint
(3) 盡量不要用null,宣告not null,如果是null用0代替
(4) 盡量使用TIMESTAMP而非DATETIME
(5) 用整型來存ip
(6) 注意反范式和范式的優化 - 查詢時
(1) 參考查詢優化
(2) 參考前面的查詢在什么情況下不走索引 - 加快取NoSQL
(1) Memcached
(2) Redis - 磁區
(1) MySQL內置的是水平磁區,分為range,list,hash,key
(2) 在磁區的基礎上還可以有子磁區,一個磁區創建子磁區,其他磁區也要創建子磁區;每個磁區的子磁區數必須相同;所有磁區必須使用相同的存盤引擎
(3) 磁區表的資料還可以分布在不同的物理設備上 - 分表 & 分表
(1) 垂直分表:把表中的一些欄位移到其他表或者新建表
(2) 水平分表:和磁區類似
(3) 垂直分庫:把不同資料表分到不同庫,不同服務器上
(4) 可以使用MyCat等中間件來實作 - 換Hadoop家族
十八、MySQL存盤引擎
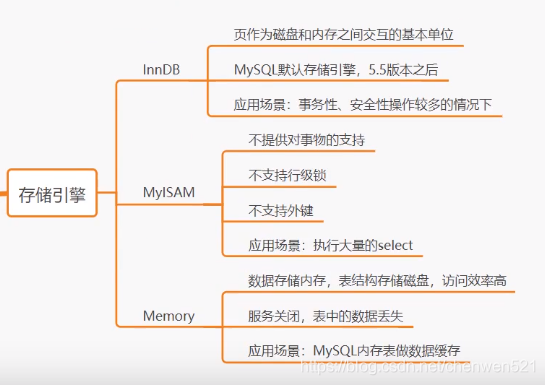
- MySQL常用的引擎
MySQL常見的存盤引擎主要有三個,分別是InnoDB,Memory和MyISAM(形容資料庫中表的)
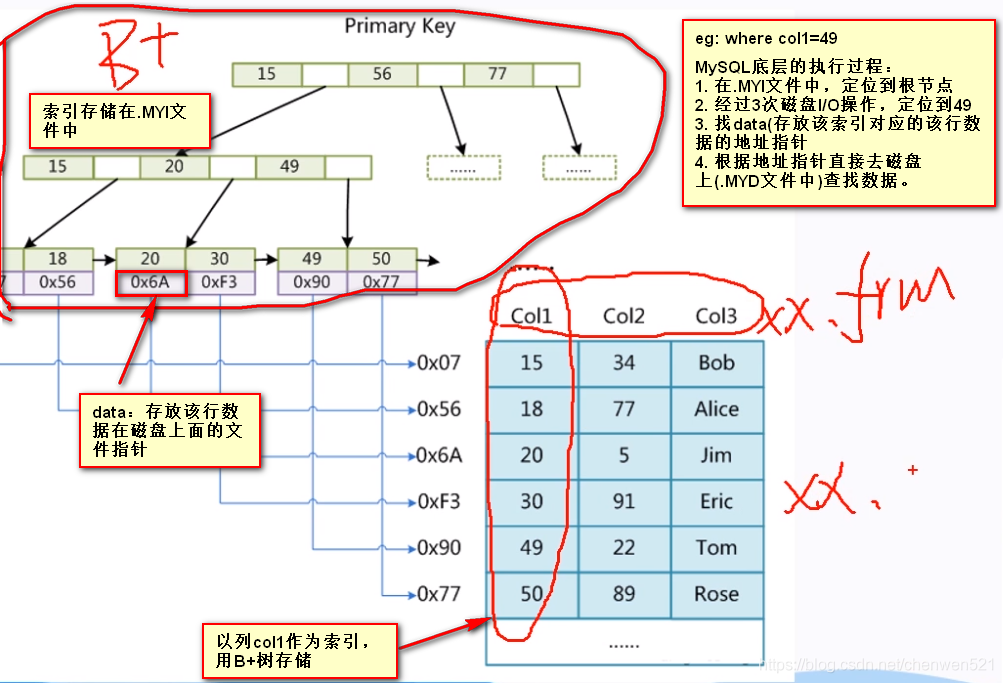
MyISAM索引(非聚集):
- .frm .MYD .MYI
(1).frm檔案:存盤表的定義,表結構
(2).MYD檔案:存盤資料
(3).MYI檔案:存盤表的索引(主鍵自帶主鍵索引)
(4) 查找資料的一次程序:
InnoDB存盤引擎(聚集):
- .frm .ibd
(1) .frm檔案:存盤表的結構
(2) .ibd檔案:存盤資料+索引
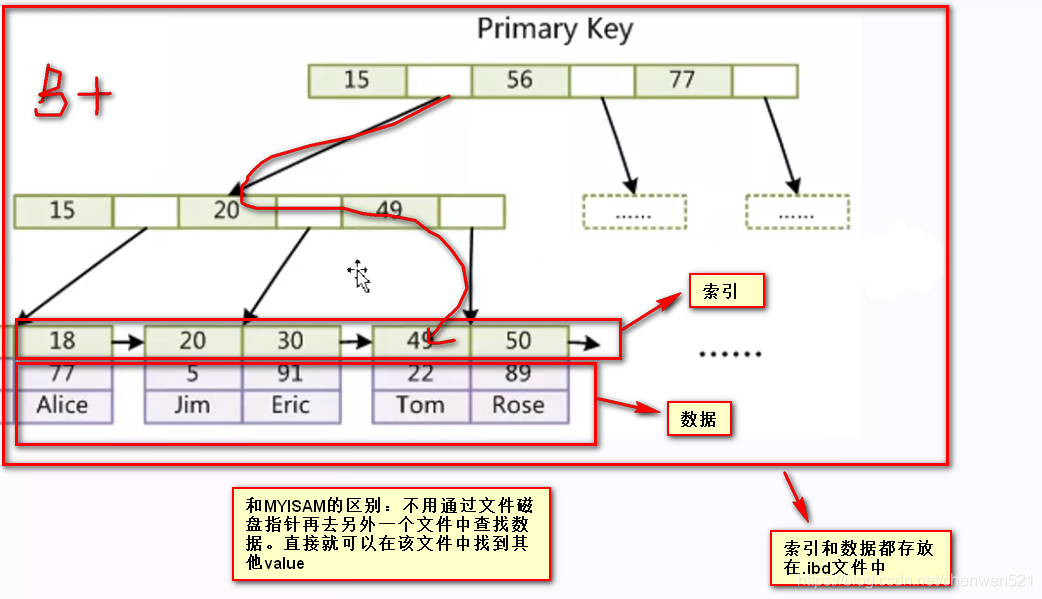
聚集索引和非聚集索引:
- 聚集索引:葉子節點包含了完整的資料結構,
eg:InnoDB索引:資料和索引在一起 - 非聚集索引:
eg:MyISAM索引:資料和索引分開
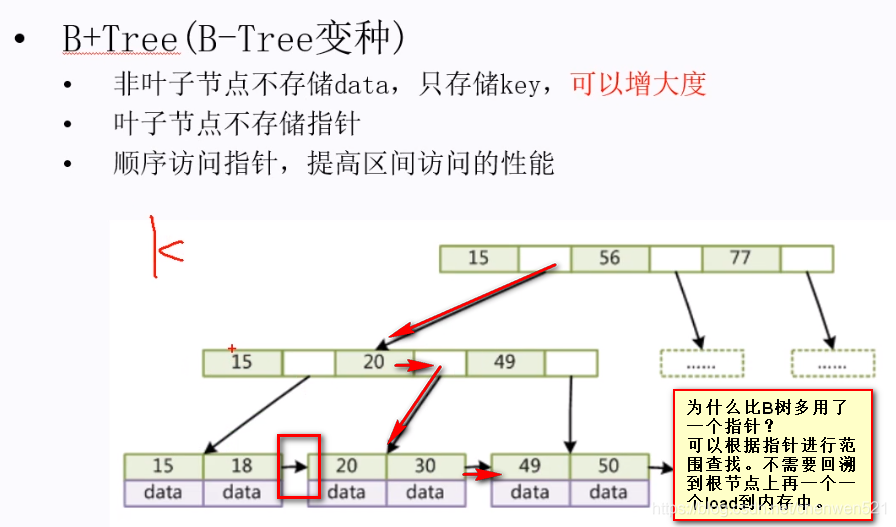
B+樹:
- 特點:
- 示意圖:
MySQL索引底層面試:
-
B+樹和B樹的區別
一共做了兩個地方的改進:
a. 把資料項從非葉子節點移到了葉子節點—>目的:騰出更多空間存放索引(非葉子節點存放的索引數目越多,則該樹能存放的資料就越多),減少層數,即減少磁盤I/O操作的次數,以提高性能,(在樹高度相等的情況下,B+樹存盤的資料比B樹要大得多)
b. 加了一個區間訪問的雙向指標 -
為什么多了一個指標?
利用該指標可以得到左右兩邊節點,提高區間訪問的性能,這也是為什么不用hash索引的原因,當進行單值查找的時候,用hash索引比較高效,但是一到范圍索引就不行了… -
Mysql中為什么用B+樹存盤索引,而不用B樹?
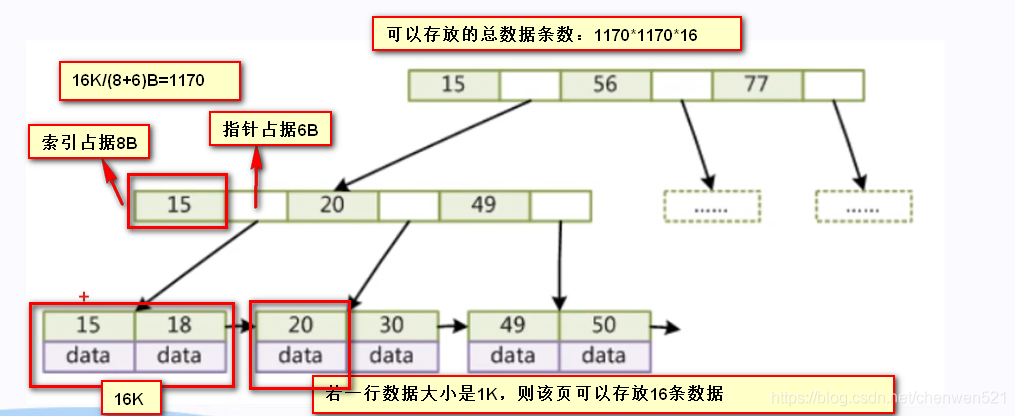
(1) 在B+樹中為什么要把data資料項移動到葉子節點中:每個節點最多放置16K大小的資料,這樣能給每個節點騰出來更多的空間存放索引,也可減少層數,提高性能, -
為什么mysql頁檔案默認為16K?

-
為什么InnoDB必須有主鍵,并且推薦使用整型的自增主鍵?
a. 因為InnoDB索引的表資料檔案本身就是按照B+樹建立的一個索引結構檔案,這種結構導致它必須要有一個索引,b. 為什么有主鍵??因為InnoDB是聚集索引,所以InnoDB表必須有主鍵,
c. 整型??整型只占據8B,UUID一長串字串不止8B,樹的高度更高,查找效率更低,比較元素是比較大小的,整型的比較大小較快,UUID是字串占地方,還要轉換成ASCII碼,所以推薦用整型,
d.自增??B+樹本質上也是二叉搜索樹,所以其葉子節點具有從左到右依次遞增的特性,插入資料較方便,最后一列是從左到右逐漸遞增的,若新插入節點需要插入到中間位置,但是該位置之前可能已經存盤滿了,為了滿足B+樹葉子節點索引從左到右遞增的特性,可能會對原有節點進行分裂,
-
為什么不用紅黑樹作為索引的資料結構?
因為索引存盤在磁盤上,每取一次索引就要進行一次磁盤I/O操作,
(1) 樹太高,增加磁盤I/O的次數
(2) 一頁可以存放6K的資料,但是現在只存放了一個int型別的資料,浪費了大量空間, -
為什么紅黑樹可以用在hashMap的查找里面?
資料有兩種存盤方式:記憶體(適用于小資料)+硬碟(大資料)mysql
因為它直接存在記憶體里面,不存在磁盤I/O操作,
面試題:
9. InnoDB和MySIAM的區別
(1) 面試官常常會問到如何選擇MyISAM和Innodb,這其實是一個早期DBA的問題,但是現在在事實上早已經不存在這個問題了,Innodb不斷完善,從各個方面趕超了MyISAM,成為了MySQL默認的存盤引擎,
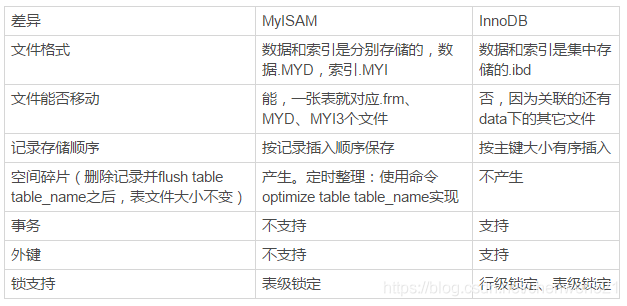
(2) 相關差異
(3) 鎖差異
- MyISAM中是不會產生死鎖的,因為MyISAM總是一次性獲得所需的全部鎖,要么全部滿足,要么全部等待
- MyISAM因為是表鎖,只有讀讀之間是并發的,寫寫之間和讀寫之間是串行的
- 而在InnoDB中,鎖是逐步獲得的,就造成了死鎖的可能
- Innodb的行級鎖不是直接鎖記錄,而是鎖索引,即行鎖是鎖索引的,如果沒有索引,InnoDB也會鎖表 .
(4) MyISAM和InnoDB的B+樹索引實作機制不一樣
1. MyISAM使用前綴壓縮技術使得索引變得更小,但InnoDB則按照原資料格式進行存盤
2. MyISAM索引通過資料的物理位置引出被索引的行,但InnoDB則根據主鍵參考被索引的行;即MyISAM索引檔案和資料檔案是分離的,但是InnoDB主鍵索引的key就是資料表的主鍵,data就是表中的資料
3. MyISAM的二級索引和主索引結構沒有區別,但是二級索引的key可以不唯一;InnoDB二級索引data域存盤相應記錄主鍵的值而不是地址
4. 對于InnoDB來說,其主鍵盡量使用MySQL自帶的與業務無關的自增主鍵
5. MyISAM引擎把一個表的總行數存在了磁盤上,因此執行count()的時候會直接回傳這個數,效率很高;而InnoDB引擎就麻煩了,它執行count()的時候,需要把資料一行一行地從引擎里面讀出來,然后累積計數,這是因為InnoDB的MVCC
6. MyISAM的一般查詢效率比InnoDB高,但是InnoDB的主鍵索引查詢除外
7. InnoDB獨有redo log,但MyISAM之后binlog,下面有詳細講這兩種log
-
如何選擇
(1) 默認Innodb
(2) MyISAM:以讀為主的應用程式,比如博客系統、新聞門戶網站
(3)Innodb:更新(洗掉)操作頻率也高,或者要保證資料的完整性;并發量高,支持事務和外鍵保證資料完整性,比如OA自動化辦公系統, -
Mysql里面的MVCC
十九、各種鎖
-
MySQL內部的鎖管理是極為透明的,
同時鎖與并發關系較大,這篇博客扯的比較少,后續的并發面經會有說到 -
樂觀、悲觀鎖,行、表鎖,讀、寫鎖,間隙鎖(重要)
-
根據加鎖范圍:
(1) 全域鎖:是對整個資料庫實體加鎖,常見的場景是全庫邏輯備份(也就是把整庫每個表都select出來存成文本),對于InnoDB可以用可重復讀這一隔離級別進行備份,但是對于MyISAM只能用全域鎖,(2) 表級鎖
–a--. 表鎖:lock tables t1 read, t2 write;那么該執行緒只能讀t1,寫t2,其他執行緒只能寫t1,讀t2
–b--元資料鎖:即MDL,MySQL5.5版本引入,當對一個表做增刪改查操作的時候,加MDL讀鎖;當要對表做結構變更操作的時候,加MDL寫鎖,讀鎖之間不互斥,讀寫鎖之間、寫鎖之間是互斥的,
–c--MySQL所有引擎都支持表鎖(3)行級鎖
–a--. 由各個引擎自己實作
–b--. 即鎖定某個表中的特定行,并發度高,鎖粒度低
在InnoDB事務中,行鎖是在需要的時候才加上的,但并不是不需要了就立刻釋放,而是要等到事務結束時才釋放,這個就是兩階段鎖協議
–c--. 行鎖容易產生死鎖,此時需要使用InnoDB的主動死鎖檢測
–d--. 在InnoDB中,行級鎖都是基于索引的,如果一條SQL陳述句用不到索引是不會使用行級鎖的,會使用表級鎖把整張表鎖住,(4) 間隙鎖(GAP)
–a--. 是一個范圍小于表鎖,大于行鎖的鎖,主要是為了防止幻讀
–b--. 如果查詢條件沒有建立索引或者不是唯一索引,則會加上間隙鎖(普通查詢是快照讀,這里不考慮)
–c--. 加鎖范圍是查詢條件的兩側 -
根據鎖的讀寫方式:
(1)共享鎖又稱為讀鎖,簡稱S鎖,共享鎖就是多個事務對于同一資料可以共享一把鎖,都能訪問到資料,但是只能讀不能修改.(2)當session 1對表admin加上了讀鎖之后,
session 1可以進行的操作:可讀admin不可寫,也不可對其他表進行操作,
session2可進行的操作:可讀admin,不可寫(當session 1將讀鎖釋放后才可寫)(3)具體操作:
-
session 1加讀鎖:

-
查看鎖


-
需要注意的操作:
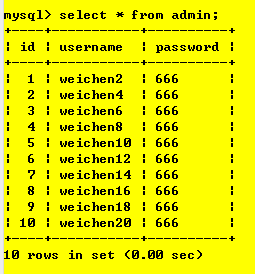
當session 1對表admin加上了讀鎖之后,
session 1可以進行的操作:可讀admin不可寫,也不可對其他表進行操作,
case 1:對表admin進行讀操作 【可】
case 2:對admin進行寫操作 【不可】

case 3:讀別的表 【不可】
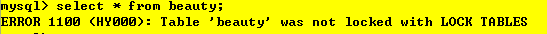
解釋:session 1已經把admin表鎖上了,需要給一個時間,得把當前的堆疊清空了才能干別的事情,把它鎖上之后要把自己要做的事情做了之后進行解鎖,然后才能繼續干別的事情,session 2執行的操作:
case 1:對admin表進行讀操作
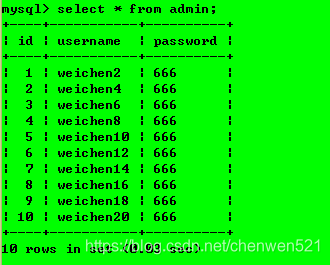
case 2:對admin表進行寫操作,

解釋:被阻塞,在等待session 1釋放鎖后執行,


(2)排他鎖又稱為寫鎖,簡稱X鎖,排他鎖就是不能與其他鎖并存,如一個事務獲取了一個資料行的排他鎖,其他事務就不能再獲取該行的其他鎖,包括共享鎖和排他鎖,但是獲取排他鎖的事務是可以對資料就行讀取和修改,(3)SS鎖不互斥,SX和XX鎖都互斥
-
-
根據鎖的特征
(1) 悲觀鎖(mysql共享鎖、排它鎖):總是假設最壞的情況,每次去拿資料的時候都認為別人會修改,所以每次在拿資料的時候都會上鎖,這樣別人想拿這個資料就會阻塞直到它拿到鎖,傳統的關系型資料庫里邊就用到了很多這種鎖機制,比如行鎖,表鎖等,讀鎖,寫鎖等,都是在做操作之前先上鎖,Java中synchronized和ReentrantLock等獨占鎖就是悲觀鎖思想的實作(2) 樂觀鎖:總是假設最好的情況,每次去拿資料的時候都認為別人不會修改,所以不會上鎖,但是在更新的時候會判斷一下在此期間別人有沒有去更新這個資料,可以使用版本號機制和CAS演算法實作,樂觀鎖適用于多讀的應用型別,這樣可以提高吞吐量,使用版本號時,可以在資料初始化時指定一個版本號,每次對資料的更新操作都對版本號執行+1操作,并判斷當前版本號是不是該資料的最新的版本號,如果不是,則重新更新,在JDK中的一些包里,如java.util.concurrent.atomic包下面的原子變數類就是使用了樂觀鎖的一種實作方式CAS實作的
(3) 樂觀鎖在不發生取鎖失敗的情況下開銷比悲觀鎖小,但是一旦發生失敗回滾開銷則比較大,因此適合用在取鎖失敗概率比較小的場景,可以提升系統并發性能
(4) 樂觀鎖還適用于一些比較特殊的場景,例如在業務操作程序中無法和資料庫保持連接等悲觀鎖無法適用的地方
二十. CAS和MVCC(重要)
(愛奇藝、阿里)
-
CAS
即compare and swap,交換比較,
(1) CAS涉及到了3個運算子:
a. 需要讀寫的記憶體值V
b. 需要比較的值A
c. 擬寫入的新值B
當且僅當 V 的值等于 A時,CAS通過原子方式用新值B來更新V的值,需要通過自旋鎖不斷重試 ,(2) 優點: 是非阻塞的輕量級樂觀鎖
(3) 缺點:會出現ABA問題,即如果一個值被修改后又被重新修改回來,我們能確定它沒有被修改過嗎?
當問到CAS的時候,基本上就轉到Java并發了 -
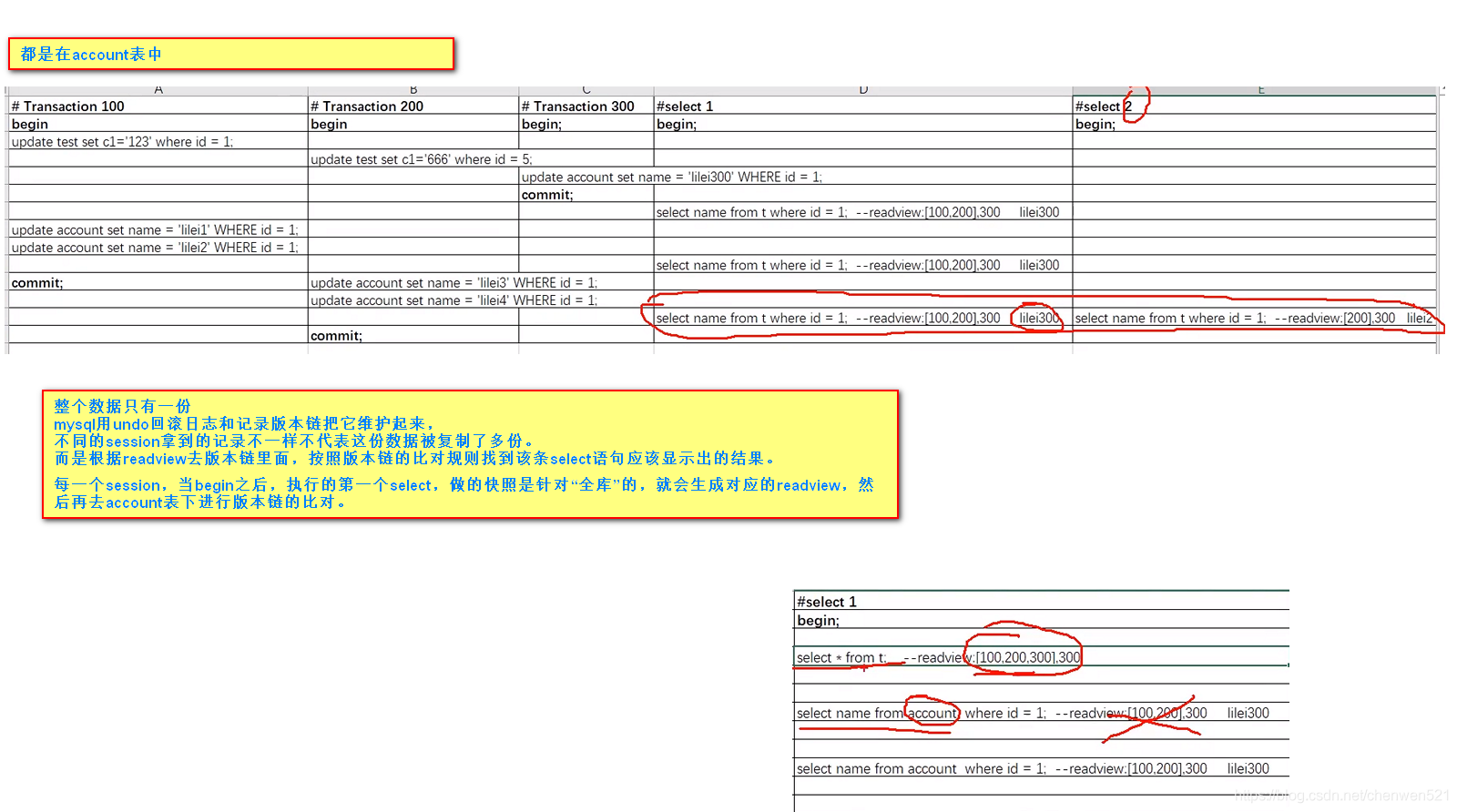
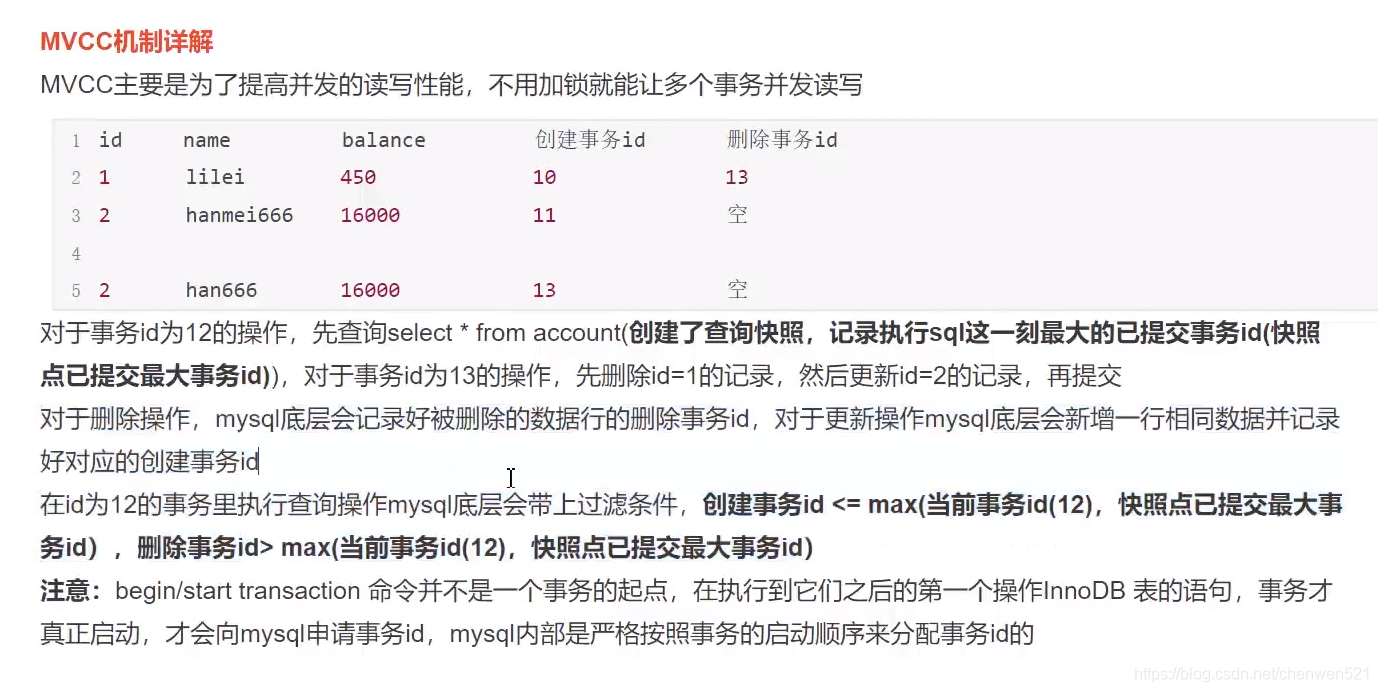
MVCC
(1) 資料庫多版本并發控制,即每一行資料都是有多個版本的,每個版本有自己的row trx_id,即當時修改該行的transaction_id(2)需要用到一致性讀視圖,即consistent read view,用于支持RC和RR隔離級別的實作,它沒有物理結構,作用是事務執行期間用來定義“我能看到什么資料”,它其實是一個視圖陣列,和資料庫中顯式創建的create view …不一樣
一個資料版本,對于一個事務視圖來說,除了自己的更新總是可見以外,有三種情況:
(1) 版本未提交,不可見;
(2) 版本已提交,但是是在一致性視圖創建后提交的,不可見;
(3) 版本已提交,而且是在一致性視圖創建前提交的,可見在MVCC中有兩種讀,上面三種是快照讀,還有一種是當前讀:
(1)當普通的select是快照讀
(2) 插入,洗掉,更新屬于當前讀,需要加鎖,遵從兩階段鎖協議
MVCC底層原理圖示



- MySQL如何加鎖
(滴滴)
這個問題是十分的寬泛啊,如何加鎖,基本就是關于MySQL的事務,鎖,兩階段鎖協議,以及不同引擎對鎖和事務的處理,當然主要還是InnoDB,面試官會看你主要說什么東西,進而繼續往下提問,所以這個地方盡量往自己懂的地方說就完事了,
(1) MySQL普通讀和修改等讀是不一樣的,普通讀是利用了MVCC機制,而修改讀是利用鎖,
(2) 當前讀(select * from tab where a = 1 lock in share mode;)加S鎖,而insert, update, delete加排他鎖,
(3) 我們要注意,聚簇索引和非聚簇索引加鎖的次數是不一樣的,
二十一、 MySQL中一條陳述句的執行程序
- 我們首先要知道MySQL處理不同陳述句,如DDL,DML等是不一樣的
- MySQL 主要分為 Server 層和引擎層,Server 層主要包括連接器、查詢快取、分析器、優化器、執行計劃、執行器,同時還有binlog,引擎層包括了InnoDB,Memory,MyISAM等引擎插件,其中,InnoDB還有redo log
- 一條查詢陳述句的執行程序
(1) client先發送一條查詢給服務器,#連接器#(此時的通信協議的半雙工的)
(2) 服務器先檢查快取,如果命中快取,則回傳結果,如果沒有,進入下一階段(查詢快取是通過大小寫敏感的hash表實作的,但是MySQL8.0之后把快取洗掉了)
(3) 進行SQL決議#決議器#*,預處理#前處理器#,再由查詢優化器#優化器#*生成對應的查詢執行計劃
(4) 根據優化計劃來呼叫存盤引擎的API來查詢,并將結果回傳給客戶端
譬如如下查詢:
select * from tb_student A where A.age='18' and A.name=' 張三 ';
結合上面的說明,我們分析下這個陳述句的執行流程:
- 先檢查該陳述句是否有權限,如果沒有權限,直接回傳錯誤資訊,如果有權限,在 MySQL8.0 版本以前,會先查詢快取,以這條 sql 陳述句為 key 在記憶體中查詢是否有結果,如果有直接快取,如果沒有,執行下一步,
- 通過分析器進行詞法分析,提取 sql 陳述句的關鍵元素,比如提取上面這個陳述句是查詢 select,提取需要查詢的表名為 tb_student,需要查詢所有的列,查詢條件是這個表的 id=‘1’,然后判斷這個 sql 陳述句是否有語法錯誤,比如關鍵詞是否正確等等,如果檢查沒問題就執行下一步,
- 接下來就是優化器進行確定執行方案,上面的 sql 陳述句,可以有兩種執行方案:
(1)先查詢學生表中姓名為“張三”的學生,然后判斷是否年齡是 18
(2)先找出學生中年齡 18 歲的學生,然后再查詢姓名為“張三”的學生 - 優化器根據自己的優化演算法進行選擇執行效率最好的一個方案(優化器認為,有時候不一定最好)
- 進行權限校驗,如果沒有權限就會回傳錯誤資訊,如果有權限就會呼叫資料庫引擎介面,回傳引擎的執行結果
一條更新陳述句的執行程序
常考的一般是含有redo log的InnoDB引擎,所以我們主要說的是InnoDB的更新流程,這里會涉及到兩階段提交的概念
- 先按照上述步驟,分析SQL陳述句,然后拿到要修改的行執行器修改拿到的行,同時呼叫引擎把修改后的行寫入表中.
(1)引擎將這行資料更新到記憶體中,同時使redo log進入prepare狀態
(2)告知執行器執行完畢,隨時可以提交事物 - 執行器生成操作的binlog,并寫入磁盤
- 執行器呼叫引擎的提交事物介面,引擎把剛才的redo log改成提交狀態,更新完成,
二十二、 redo log和binlog的區別
- redo log是InnoDB引擎特有的;binlog是MySQL的Server層實作的,所有引擎都可以使用
- redo log是物理日志,記錄的是“在某個資料頁上做了什么修改”;binlog是邏輯日志,記錄的是這個陳述句的原始邏輯,比如“給ID=2這一行的c欄位加1 ” ,比如,redo log記錄的是結果,binlog記錄的是一個邏輯程序、
- redo log是回圈寫的,空間固定會用完;binlog是可以追加寫入的,“追加寫”是指binlog檔案寫到一定大小后會切換到下一個,并不會覆寫以前的日志
- binlog可以作為恢復資料使用,主從復制搭建,redo log作為例外宕機或者介質故障后的資料恢復使用
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/184961.html
標籤:其他
上一篇:索引的代價
下一篇:SQL函式大全匯總