作者|GUEST
編譯|VK
來源|Analytics Vidhya
介紹

目標檢測是計算機視覺中一個非常重要的領域,對于自動駕駛、視頻監控、醫療應用和許多其他領域都是必要的,
我們正在與一場規模空前的傳染病作斗爭,全世界的研究人員都在試圖開發一種疫苗或治療COVID-19的方法,而醫生們卻在努力阻止這場傳染病席卷全世界,另一方面,許多國家發現了社會距離的疏遠,使用口罩和手套可以稍微遏制這種局面,
我最近有一個想法,用我的深度學習知識來幫助目前的情況,在這篇文章中,我將向你介紹RetinaNet的實作,背景知識不多,
我們將使用RetinaNet建立一個“口罩探測器”來幫助我們應對這場持續的傳染病,你可以推斷出同樣的想法來為你的智能家居構建一個支持人工智能的解決方案,這個人工智能的解決方案只對戴著口罩和手套的人敞開大門,
隨著無人機的成本隨著時間的推移而降低,我們看到空中資料的生成出現了一個大的峰值,因此,你可以使用這個RetinaNet模型在航空影像甚至衛星影像中檢測不同的物件,如汽車(自行車、汽車等)或行人,以解決不同的業務問題,
所以,你看目標檢測模型的應用是無窮無盡的,
目錄
- 什么是RetinaNet
- RetinaNet的需求
- RetinaNet的架構
- 骨干網
- 物件分類子網
- 物件回歸子網
- Focal Loss
- 利用RetinaNet模型建立口罩檢測器
- 收集資料
- 創建資料集
- 模特訓練
- 模型測驗
- 最后說明
什么是RetinaNet
RetinaNet是一種最好的單目標檢測模型,已被證明能很好地處理密集和小尺度的物體,由于這個原因,它已經成為一個流行的目標檢測模型,
RetinaNet的需求
RetinaNet是由Facebook人工智能研究所(Facebook-AI-Research)引入的,旨在解決密集檢測問題,在處理極端前景-背景類時,需要彌補YOLO和SSD等單步目標檢測器的不平衡和不一致,
RetinaNet的架構
從本質上講,RetinaNet是一個復合網路,由以下部分組成:
-
主干網路(自底向上的路徑和具有橫向連接的自上而下的路徑)
-
目標分類子網
-
目標回歸子網
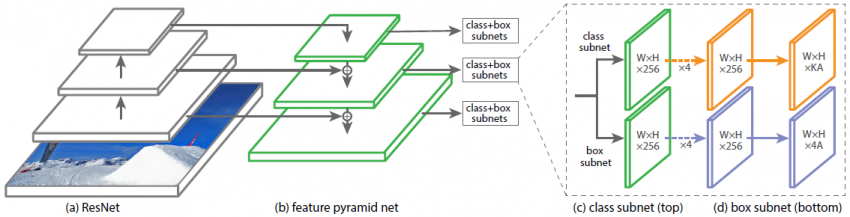
為了更好地理解,讓我們分別了解架構的每個組件
1.主干網路
-
自底向上路徑:自底向上路徑(例如,ResNet)用于特征提取,因此,它計算不同比例的特征圖,而不考慮輸入影像的大小,
-
具有橫向連接的自上而下的路徑:在自上而下的路徑上,從更高的金字塔級別對空間上較粗糙的特征圖進行上采樣,橫向連接將具有相同空間大小的自頂向下和自底向上的層合并在一起,較高層次的特征圖往往具有較小的解析度,但語意上更強,因此,更適合于檢測較大的物體;相反,來自較低級特征圖的網格單元具有高解析度,因此更擅長檢測較小的物件,因此,結合自上而下的路徑及其與自底向上的路徑的橫向連接,不需要太多額外的計算,因此生成的特征圖的每個級別在語意和空間上都可以很強, 因此,該體系結構是規模不變的,并且可以在速度和準確性方面提供更好的性能,
2.目標分類子網
每個FPN層都附加一個全卷積網路(FCN)進行物件分類,如圖所示,該子網包含3*3個卷積層,256個濾波器,然后是3*3個卷積層,K*A濾波器,因此輸出的feature map大小為W*H*KA,其中W和H與輸入特征圖的寬度和高度成比例,K和A分別為物件類和錨盒的數量,
最后利用Sigmoid層(而不是softmax)進行目標分類,
而最后一個卷積層之所以有KA濾波器是因為,如果從最后一個卷積層得到的特征圖中的每個位置都有很多錨盒候選區域,那么每個錨盒都有可能被分類為K個類,所以輸出的特征圖大小將是KA通道或過濾器,
3.目標回歸子網
回歸子網與分類子網并行附著在FPN的每個特征圖上,回歸子網的設計與分類子網相同,只是最后一個卷積層大小為3*3,有4個filter,輸出的特征圖大小為W*H*4A,
最后一個卷積層有4個過濾器的原因是,為了定位類物件,回歸子網路為每個錨定盒產生4個數字,這些數字預測錨定盒和真實框錨盒之間的相對偏移量(根據中心坐標、寬度和高度),因此,回歸子網的輸出特征圖具有4A濾波器或通道,
Focal Loss
Focal Loss(FL)是Cross-Entropy Loss(CE)的改進版本,它通過為困難的或容易錯誤分類的示例(即具有嘈雜紋理或部分物件或我們感興趣的物件的背景)分配更多權重來嘗試處理類不平衡問題 ,并簡化簡單的示例(即背景物件),
因此,“Focal Loss”減少了簡單示例帶來的損失貢獻,并提高了糾正錯誤分類的示例的重要性, 焦點損失只是交叉熵損失函式的擴展,它將降低簡單示例的權重,并將訓練重點放在困難樣本上,
所以為了實作這些研究人員提出了
1- pt代表交叉熵損失,可調聚焦引數≥0, RetinaNet物體檢測方法使用焦距損失的α平衡變體,其中α= 0.25,γ= 2效果最佳,
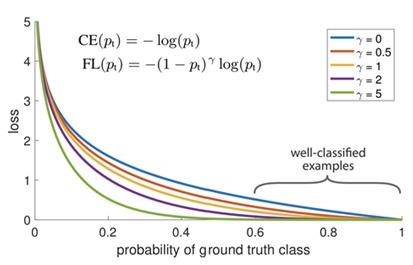
所以Focal Loss可以定義為
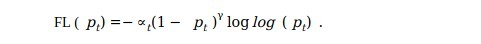
請參見圖,對于γ∈[0,5]的幾個值,我們將注意到Focal Loss的以下特性:
-
當示例分類錯誤且pt小時,調制因子接近1并且不影響損失,
-
當pt→1時,因子變為0,并且可以很好地權衡分類良好的示例的損失,
-
Focal loss γ平滑地調整了簡單示例的權重, 隨著γ的增加,調制因子的作用也同樣增加, (經過大量實驗和試驗,研究人員發現γ= 2最有效)
注:什么時候γ=0,FL相當于CE,圖中所示為藍色曲線
直觀地看,調制因子減小了簡單例的損耗貢獻,擴展了例的低損耗范圍,
現在讓我們看看用Python實作RetinaNet來構建口罩檢測器,
利用RetinaNet模型建立口罩檢測器
收集資料
任何深度學習模型都需要大量的訓練資料才能在測驗資料上產生良好的結果,
創建資料集
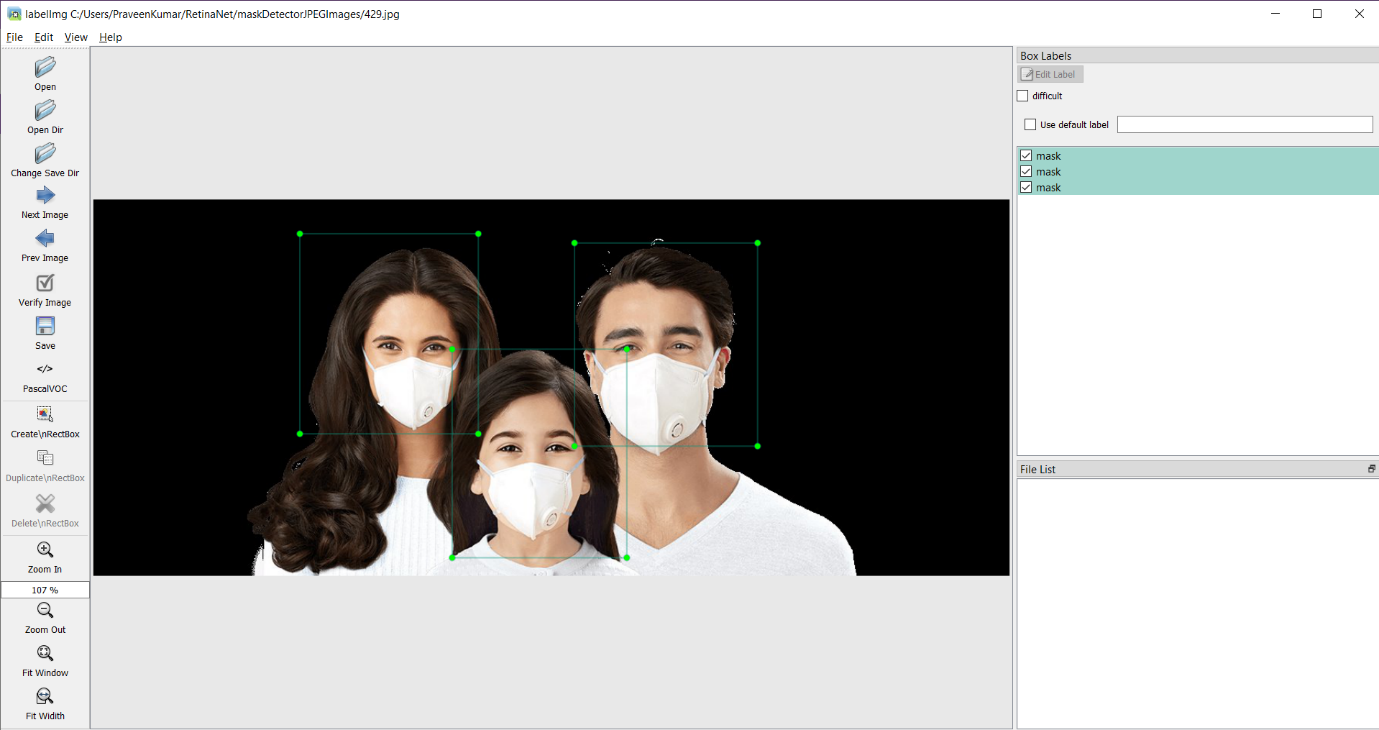
我們開始使用LabelImg工具創建資料集和驗證,這個優秀的注釋工具可以讓你快速地注釋物件的邊界框,從而訓練機器學習模型,
你可以在anaconda命令提示符下使用下面的命令安裝它
pip install labelImg
你可以使用下面的labelmg工具對每個JPEG檔案進行注釋,它將生成帶有每個邊界框坐標的XML檔案,我們將使用這些xml檔案來訓練我們的模型,
模型訓練
第1步:克隆并安裝keras-retinanet
import os
print(os.getcwd())
git clone https://github.com/fizyr/keras-retinanet.git
%cd keras-retinanet/
!pip install .
!python setup.py build_ext --inplace
第2步:匯入所有必要庫
import numpy as np
import shutil
import pandas as pd
import os, sys, random
import xml.etree.ElementTree as ET
import pandas as pd
from os import listdir
from os.path import isfile, join
import matplotlib.pyplot as plt
from PIL import Image
import requests
import urllib
from keras_retinanet.utils.visualization import draw_box, draw_caption , label_color
from keras_retinanet.utils.image import preprocess_image, resize_image
第3步:匯入JPEG和xml資料
pngPath='C:/Users/PraveenKumar/RetinaNet//maskDetectorJPEGImages/'
annotPath='C:/Users/PraveenKumar/RetinaNet//maskDetectorXMLfiles/'
data=https://www.cnblogs.com/panchuangai/p/pd.DataFrame(columns=['fileName','xmin','ymin','xmax','ymax','class'])
os.getcwd()
##讀所有檔案
allfiles = [f for f in listdir(annotPath) if isfile(join(annotPath, f))]
#讀取所有pdf檔案的影像,然后在文本存盤在臨時檔案夾
for file in allfiles:
#print(file)
if (file.split(".")[1]=='xml'):
fileName='C:/Users/PraveenKumar/RetinaNet/maskDetectorJPEGImages/'+file.replace(".xml",'.jpg')
tree = ET.parse(annotPath+file)
root = tree.getroot()
for obj in root.iter('object'):
cls_name = obj.find('name').text
xml_box = obj.find('bndbox')
xmin = xml_box.find('xmin').text
ymin = xml_box.find('ymin').text
xmax = xml_box.find('xmax').text
ymax = xml_box.find('ymax').text
#通過添加字典在空資料框架中追加行
data = https://www.cnblogs.com/panchuangai/p/data.append({'fileName': fileName, 'xmin': xmin, 'ymin':ymin,'xmax':xmax,'ymax':ymax,'class':cls_name}, ignore_index=True)
data.shape
第4步:撰寫一個函式來顯示訓練資料集上的邊界框
# 隨機選取影像
filepath = df.sample()['fileName'].values[0]
# 獲取此影像的所有行
df2 = df[df['fileName'] == filepath]
im = np.array(Image.open(filepath))
# 如果有PNG的話,它會有alpha通道
im = im[:,:,:3]
for idx, row in df2.iterrows():
box = [
row['xmin'],
row['ymin'],
row['xmax'],
row['ymax'],
]
print(box)
draw_box(im, box, color=(255, 0, 0))
plt.axis('off')
plt.imshow(im)
plt.show()
show_image_with_boxes(data)

#檢查少量資料記錄
data.head()

#定義標簽并將其寫入檔案
classes = ['mask','noMask']
with open('../maskDetectorClasses.csv', 'w') as f:
for i, class_name in enumerate(classes):
f.write(f'{class_name},{i}\n')
if not os.path.exists('snapshots'):
os.mkdir('snapshots')
注意:最好從一個預訓練過的模型開始,而不是從頭開始訓練模型,我們將使用已經在Coco資料集上預訓練過的ResNet50模型,
URL_MODEL = 'https://github.com/fizyr/keras-retinanet/releases/download/0.5.1/resnet50_coco_best_v2.1.0.h5'
urllib.request.urlretrieve(URL_MODEL, PRETRAINED_MODEL)
第5步:訓練RetinaNet模型
注意:如果你使用google colab,你可以使用下面的代碼片段來訓練你的模型,
#把你的訓練資料路徑和檔案放在訓練資料的標簽上
!keras_retinanet/bin/train.py --freeze-backbone \ --random-transform \ --weights {PRETRAINED_MODEL} \ --batch-size 8 \ --steps 500 \ --epochs 15 \ csv maskDetectorData.csv maskDetectorClasses.csv
但若你正在使用本地Jupyter Notebook或其他IDE進行訓練,則可以在命令提示符下執行命令
python keras_retinanet/bin/train.py --freeze-backbone
--random-transform \
--weights {PRETRAINED_MODEL}
--batch-size 8
--steps 500
--epochs 15
csv maskDetectorData.csv maskDetectorClasses.csv
讓我們分析一下train.py的每個引數.
-
freeze-backbone:凍結主干層,當我們使用小資料集時特別有用,以避免過擬合
-
random-transform:隨機變換資料集以獲得資料增強
-
weights:使用一個預先訓練好的模型(您自己的模型或者Fizyr發布的模型)初始化模型
-
batch-size:訓練批量大小,值越高,學習曲線越平滑
-
step:迭代的步數
-
epochs:迭代的次數
-
csv:上面的腳本生成的注釋檔案
第6步:載入訓練模型
from glob import glob
model_paths = glob('snapshots/resnet50_csv_0*.h5')
latest_path = sorted(model_paths)[-1]
print("path:", latest_path)
from keras_retinanet import models
model = models.load_model(latest_path, backbone_name='resnet50')
model = models.convert_model(model)
label_map = {}
for line in open('../maskDetectorClasses.csv'):
row = line.rstrip().split(',')
label_map[int(row[1])] = row[0]
模型測驗:
第7步:利用訓練模型進行預測
#寫一個函式,從你的資料集中隨機選擇一個影像,并預測使用訓練模型,
def show_image_with_predictions(df, threshold=0.6):
# 隨機選擇一個影像
row = df.sample()
filepath = row['fileName'].values[0]
print("filepath:", filepath)
# 獲取此影像的所有行
df2 = df[df['fileName'] == filepath]
im = np.array(Image.open(filepath))
print("im.shape:", im.shape)
# 如果有一個PNG,它會有alpha通道
im = im[:,:,:3]
# 畫出真實盒子
for idx, row in df2.iterrows():
box = [
row['xmin'],
row['ymin'],
row['xmax'],
row['ymax'],
]
print(box)
draw_box(im, box, color=(255, 0, 0))
### 畫出預測 ###
# 獲取預測
imp = preprocess_image(im)
imp, scale = resize_image(im)
boxes, scores, labels = model.predict_on_batch(
np.expand_dims(imp, axis=0)
)
# 標準化框坐標
boxes /= scale
# 回圈得到每個預測
for box, score, label in zip(boxes[0], scores[0], labels[0]):
# 分數是排序的,所以一旦我們看到分數低于閾值,我們就可以退出
if score < threshold:
break
box = box.astype(np.int32)
color = label_color(label)
draw_box(im, box, color=color)
class_name = label_map
caption = f"{class_name} {score:.3f}"
draw_caption(im, box, caption)
score, label=score, label
plt.axis('off')
plt.imshow(im)
plt.show()
return score, label
plt.rcParams['figure.figsize'] = [20, 10]
#可以根據你的業務需求隨意更改閾值
label=show_image_with_predictions(data, threshold=0.6)
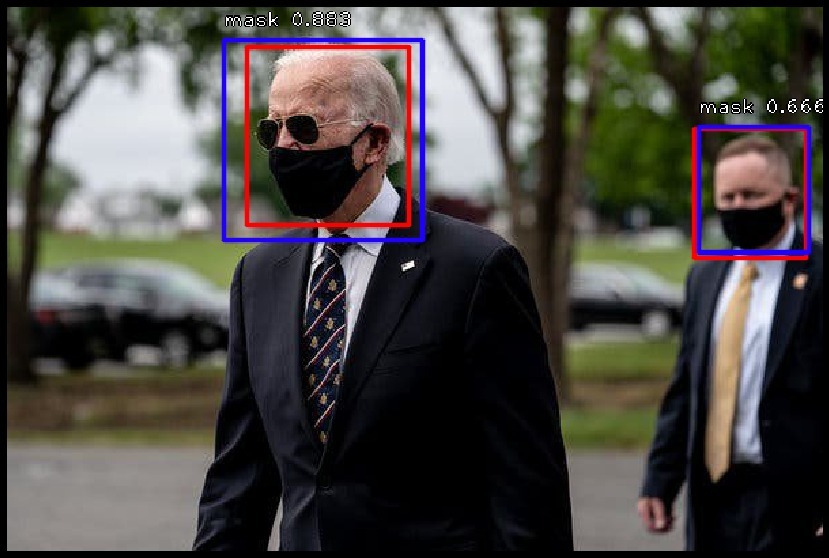
#可以根據你的業務需求隨意更改閾值
label=show_image_with_predictions(data, threshold=0.6)
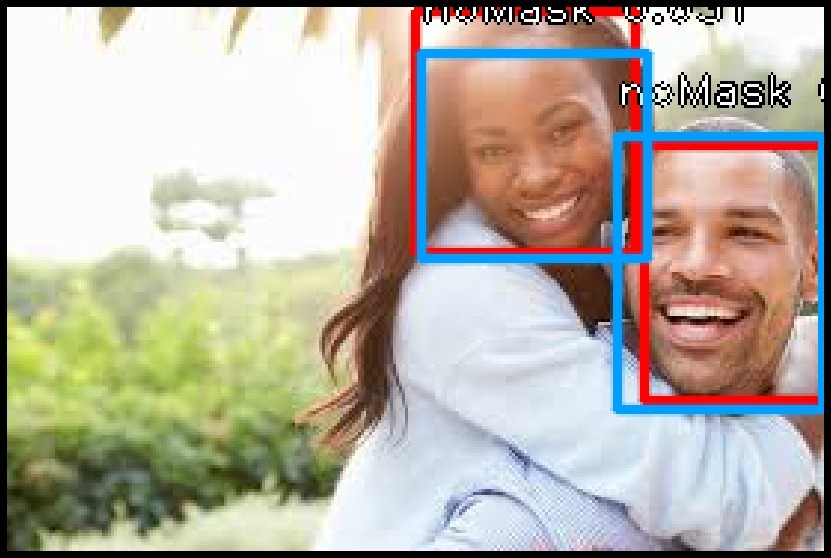
#可以根據你的業務需求隨意更改閾值
label=show_image_with_predictions(data, threshold=0.6)

#可以根據你的業務需求隨意更改閾值
label=show_image_with_predictions(data, threshold=0.6)

#可以根據你的業務需求隨意更改閾值
label=show_image_with_predictions(data, threshold=0.6)

#可以根據你的業務需求隨意更改閾值
score, label=show_image_with_predictions(data, threshold=0.6)

#可以根據你的業務需求隨意更改閾值
score, label=show_image_with_predictions(data, threshold=0.6)

#可以根據你的業務需求隨意更改閾值
score, label=show_image_with_predictions(data, threshold=0.6)

參考文獻
- http://arxiv.org/abs/1605.06409.
- https://arxiv.org/pdf/1708.02002.pdf
- https://developers.arcgis.com/python/guide/how-retinanet-works/
- https://github.com/fizyr/keras-retinanet
- https://www.freecodecamp.org/news/object-detection-in-colab-with-fizyr-retinanet-efed36ac4af3/
- https://deeplearningcourses.com/
- https://blog.zenggyu.com/en/post/2018-12-05/retinanet-explained-and-demystified/
最后說明
總而言之,我們完成了使用RetinaNet制作口罩檢測器的整個程序, 我們創建了一個資料集,訓練了一個模型并進行了測驗(這是我的Notebook和資料集的Github存盤庫):https://github.com/Praveen76/Face-mask-detector-using-RetinaNet-model
RetinaNet是一個功能強大的模型,使用Feature Pyramid Networks&ResNet作為其骨干, 我能夠通過非常有限的資料集和極少的迭代(每個迭代有500個步長,共6次迭代)獲得口罩檢測器的良好結果,當然你也可以更改閾值,
注意:
-
確保你訓練你的模型至少20次迭代,以獲得好的結果,
-
一個好的想法是提交使用RetinaNet模型構建口罩檢測器的方法, 人們總是可以根據業務需求調整模型,資料和方法,
一般來說,RetinaNet是開始目標檢測專案的一個很好的選擇,特別是如果你需要快速獲得良好的結果,
原文鏈接:https://www.analyticsvidhya.com/blog/2020/08/how-to-build-a-face-mask-detector-using-retinanet-model/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/189513.html
標籤:其他