作者|Rashida Nasrin Sucky
編譯|VK
來源|Medium

神經網路已經被開發用來模擬人腦,雖然我們還沒有做到這一點,但神經網路在機器學習方面是非常有效的,它在上世紀80年代和90年代很流行,最近越來越流行,計算機的速度足以在合理的時間內運行一個大型神經網路,在本文中,我將討論如何實作一個神經網路,
我建議你仔細閱讀“神經網路的思想”部分,但如果你不太清楚,不要擔心,可以轉到實作部分,我把它分解成更小的碎片幫助理解,
神經網路的作業原理
在一個簡單的神經網路中,神經元是基本的計算單元,它們獲取輸入特征并將其作為輸出,以下是基本神經網路的外觀:
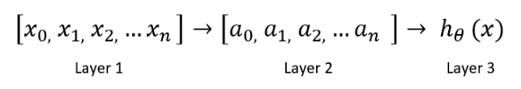
這里,“layer1”是輸入特征,“Layer1”進入另一個節點layer2,最后輸出預測的類或假設,layer2是隱藏層,可以使用多個隱藏層,
你必須根據你的資料集和精度要求來設計你的神經網路,
前向傳播
從第1層移動到第3層的程序稱為前向傳播,前向傳播的步驟:
-
為每個輸入特征初始化系數θ,比方說,我們有100個訓練例子,這意味著100行資料,在這種情況下,如果假設有10個輸入特征,我們的輸入矩陣的大小是100x10,現在確定\(θ_1\)的大小,行數需要與輸入特征的數量相同,在這個例子中,是10,列數應該是你選擇的隱藏層的大小,
-
將輸入特征X乘以相應的θ,然后添加一個偏置項,通過激活函式傳遞結果,
有幾個激活函式可用,如sigmoid,tanh,relu,softmax,swish
我將使用一個sigmoid激活函式來演示神經網路,
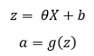
這里,“a”代表隱藏層或第2層,b表示偏置,
g(z)是sigmoid激活函式:
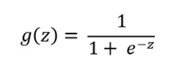
-
為隱藏層初始化\(\theta_2\),大小將是隱藏層的長度乘以輸出類的數量,在這個例子中,下一層是輸出層,因為我們沒有更多的隱藏層,
-
然后我們需要按照以前一樣的流程,將θ和隱藏層相乘,通過sigmoid激活層得到預測輸出,
反向傳播
反向傳播是從輸出層移動到第二層的程序,在這個程序中,我們計算了誤差,
- 首先,從原始輸出y減去預測輸出,這就是我們的\(\delta_3\),
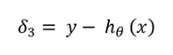
- 現在,計算\(\theta_2\)的梯度,將\(\delta_3\)乘以\(\theta_2\),乘以“\(a^2\)”乘以“\(1-a^2\)”,在下面的公式中,“a”上的上標2表示第2層,請不要把它誤解為平方,
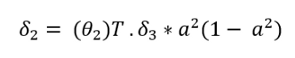
- 用訓練樣本數m計算沒有正則化版本的梯度\(\delta\),
訓練網路
修正\(\delta\),將輸入特征乘以\(\delta_2\)乘以學習速率得到\(\theta_1\),請注意\(\theta_1\)的維度,

重復前向傳播和反向傳播的程序,并不斷更新引數,直到達到最佳成本,這是成本函式的公式,只是提醒一下,成本函式表明,預測離原始輸出變數有多遠,
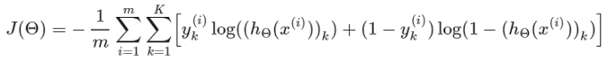
如果你注意到的話,這個成本函式公式幾乎和邏輯回歸成本函式一樣,
神經網路的實作
我將使用Andrew Ng在Coursera的機器學習課程的資料集,請從以下鏈接下載資料集:
https://github.com/rashida048/Machine-Learning-With-Python/blob/master/ex3d1.xlsx
下面是一個逐步實作的神經網路,我鼓勵你自己運行每一行代碼并列印輸出以更好地理解它,
- 首先匯入必要的包和資料集,
import pandas as pd
import numpy as np
xls = pd.ExcelFile('ex3d1.xlsx')
df = pd.read_excel(xls, 'X', header = None)
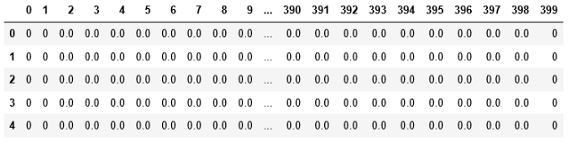
這是資料集的前五行,這些是數字的像素值,
在這個資料集中,輸入和輸出變數被組織在單獨的excel表格中,讓我們匯入輸出變數:
y = pd.read_excel(xls, 'y', header=None)

這也是資料集的前五行,輸出變數是從1到10的數字,這個專案的目標是使用存盤在'df'中的輸入變數來預測數字,
- 求輸入輸出變數的維數
df.shape
y.shape
輸入變數或df的形狀為5000 x 400,輸出變數或y的形狀為5000 x 1,
- 定義神經網路
為了簡單起見,我們將只使用一個由25個神經元組成的隱藏層,
hidden_layer = 25
得到輸出類,
y_arr = y[0].unique()#輸出:
array([10, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=int64)
正如你在上面看到的,有10個輸出類,
- 初始化θ和偏置
我們將隨機初始化層1和層2的θ,因為我們有三層,所以會有\(\theta_1\)和\(\theta_2\),
\(\theta_1\)的維度:第1層的大小x第2層的大小
\(\theta_2\)的維度:第2層的大小x第3層的大小
從步驟2開始,“df”的形狀為5000 x 400,這意味著有400個輸入特征,所以,第1層的大小是400,當我們指定隱藏層大小為25時,層2的大小為25,我們有10個輸出類,所以,第3層的大小是10,
\(\theta_1\)的維度:400 x 25
\(\theta_2\)的維度:25×10
同樣,會有兩個隨機初始化的偏置b1和b2,
\(b_1\)的維度:第2層的大小(本例中為25)
\(b_1\)的維度:第3層的大小(本例中為10)
定義一個隨機初始化theta的函式:
def randInitializeWeights(Lin, Lout):
epi = (6**1/2) / (Lin + Lout)**0.5
w = np.random.rand(Lout, Lin)*(2*epi) -epi
return w
使用此函式初始化theta
hidden_layer = 25
output =10
theta1 = randInitializeWeights(len(df.T), hidden_layer)
theta2 = randInitializeWeights(hidden_layer, output)
theta = [theta1, theta2]
現在,初始化我們上面討論過的偏置項:
b1 = np.random.randn(25,)
b2 = np.random.randn(10,)
- 實作前向傳播
使用前向傳播部分中的公式,
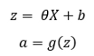
為了方便起見,定義一個函式來乘以θ和X
def z_calc(X, theta):
return np.dot(X, theta.T)
我們也將多次使用激活函式,同樣定義一個函式
def sigmoid(z):
return 1/(1+ np.exp(-z))
現在我將逐步演示正向傳播,首先,計算z項:
z1 =z_calc(df, theta1) + b1
現在通過激活函式傳遞這個z1,得到隱藏層
a1 = sigmoid(z1)
a1是隱藏層,a1的形狀是5000 x 25,重復相同的程序來計算第3層或輸出層
z2 = z_calc(a1, theta2) + b2
a2 = sigmoid(z2)
a2的形狀是5000 x 10,10列代表10個類,a2是我們的第3層或最終輸出,如果在這個例子中有更多的隱藏層,在從一個層到另一個層的程序中會有更多的重復步驟,這種利用輸入特征計算輸出層的程序稱為前向傳播,
l = 3 #層數
b = [b1, b2]
def hypothesis(df, theta):
a = []
z = []
for i in range (0, l-1):
z1 = z_calc(df, theta[i]) + b[i]
out = sigmoid(z1)
a.append(out)
z.append(z1)
df = out
return out, a, z
- 實作反向傳播
這是反向計算梯度和更新θ的程序,在此之前,我們需要修改'y',我們在“y”有10個類,但我們需要將每個類在其列中分開,例如,針對第10類的列,我們將為10替換1,為其余類替換0,這樣我們將為每個類創建一個單獨的列,
y1 = np.zeros([len(df), len(y_arr)])
y1 = pd.DataFrame(y1)
for i in range(0, len(y_arr)):
for j in range(0, len(y1)):
if y[0][j] == y_arr[i]:
y1.iloc[j, i] = 1
else:
y1.iloc[j, i] = 0
y1.head()
之前我一步一步地演示了向前傳播,然后把所有的都放在一個函式中,我將對反向傳播做同樣的事情,使用上述反向傳播部分的梯度公式,首先計算\(\delta_3\),我們將使用前向傳播實作中的z1、z2、a1和a2,
del3 = y1-a2
現在使用以下公式計算delta2:
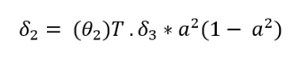
這里是delta2:
del2 = np.dot(del3, theta2) * a1*(1 - a1)
在這里我們需要學習一個新的概念,這是一個sigmoid梯度,sigmoid梯度的公式為:
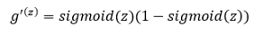
如果你注意到了,這和delta公式中的a(1-a)完全相同,因為a是sigmoid(z),我們來寫一個關于sigmoid梯度的函式:
def sigmoid_grad(z):
return sigmoid(z)*(1 - sigmoid(z))
最后,使用以下公式更新θ:
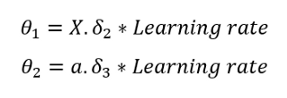
我們需要選擇一個學習率,我選了0.003,我鼓勵你嘗試使用其他學習率,看看它的表現:
theta1 = np.dot(del2.T, pd.DataFrame(a1)) * 0.003
theta2 = np.dot(del3.T, pd.DataFrame(a2)) * 0.003
這就是θ需要更新的方式,這個程序稱為反向傳播,因為它向后移動,在撰寫反向傳播函式之前,我們需要定義成本函式,因為我會把成本的計算也包括在反向傳播方法中,但它是可以添加到前向傳播中,或者可以在訓練網路時將其分開的,
def cost_function(y, y_calc, l):
return (np.sum(np.sum(-np.log(y_calc)*y - np.log(1-y_calc)*(1-y))))/m
這里m是訓練實體的數量,綜合起來的代碼:
m = len(df)
def backpropagation(df, theta, y1, alpha):
out, a, z = hypothesis(df, theta)
delta = []
delta.append(y1-a[-1])
i = l - 2
while i > 0:
delta.append(np.dot(delta[-i], theta[-i])*sigmoid_grad(z[-(i+1)]))
i -= 1
theta[0] = np.dot(delta[-1].T, df) * alpha
for i in range(1, len(theta)):
theta[i] = np.dot(delta[-(i+1)].T, pd.DataFrame(a[0])) * alpha
out, a, z = hypothesis(df, theta)
cost = cost_function(y1, a[-1], 1)
return theta, cost
- 訓練網路
我將用20個epoch訓練網路,我在這個代碼片段中再次初始化theta,
theta1 = randInitializeWeights(len(df.T), hidden_layer)
theta2 = randInitializeWeights(hidden_layer, output)
theta = [theta1, theta2]
cost_list = []
for i in range(20):
theta, cost= backpropagation(df, theta, y1, 0.003)
cost_list.append(cost)
cost_list
我使用了0.003的學習率并運行了20個epoch,但是請看文章末提供的GitHub鏈接,我有試著用不同的學習率和不同的epoch數訓練模型,
我們得到了每個epoch計算的成本,以及最終更新的θ,用最后的θ來預測輸出,
- 預測輸出并計算精度
只需使用假設函式并傳遞更新后的θ來預測輸出:
out, a, z = hypothesis(df, theta)
現在計算一下準確率,
accuracy= 0
for i in range(0, len(out)):
for j in range(0, len(out[i])):
if out[i][j] >= 0.5 and y1.iloc[i, j] == 1:
accuracy += 1
accuracy/len(df)
準確率為100%,完美,對吧?但我們并不是一直都能得到100%的準確率,有時獲得70%的準確率是很好的,這取決于資料集,
恭喜!你剛剛開發了一個完整的神經網路!
以下是完整作業代碼的GitHub鏈接:
https://github.com/rashida048/Machine-Learning-With-Python/blob/master/NeuralNetworkFinal.ipynb
原文鏈接:https://medium.com/towards-artificial-intelligence/build-a-neural-network-from-scratch-in-python-f23848b5a7c6
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/189514.html
標籤:其他
下一篇:TF2目標檢測API